AI 赋能安全技术总结与展望
大家好,我是 herosunly。985 院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池安全恶意程序检测第一名,科大讯飞恶意软件分类挑战赛第三名,CCF 恶意软件家族分类第四名,科大讯飞阿尔茨海默综合症预测挑战赛第四名,科大讯飞事件抽取挑战赛第七名,Datacon 大数据安全分析比赛第五名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。今天给大家分享的是 AI 赋能安全技术总结与展望,欢迎大家在评论区留言,和大家一起成长进步。
文章目录
- 1. 背景
- 2. 恶意样本检测
- 3. 基于UEBA的异常检测
- 4. 总结与展望
1. 背景
伴随着人工智能技术的蓬勃发展,当前网络空间已经迈进到人工智能时代。人工智能对网络空间产生了变革性的影响,如何使用人工智能技术构建更可靠的网络安全系统就变得至关重要。具体来说,人工智能赋能安全,是指基于海量数据的基础上利用人工智能来自动识别或响应潜在网络威胁的工具和技术。
伴随着人工智能技术的蓬勃发展,在网络空间安全中的很多细分领域涌现出与人工智能相关的新应用,比如恶意样本检测、恶意流量检测、恶意域名检测、异常检测、网络钓鱼检测与防护、威胁情报构建等。在人工智能赋能安全蓬勃发展浪潮中,机器学习技术(包括深度学习技术)在应对网络空间威胁方面起着至关重要的作用。
为了帮助初学者少走弯路以及更多人了解AI赋能安全,笔者总结了2021年AI赋能安全的一些经典案例(AI比赛和论文),希望能够启发大家的思维,最终推动AI赋能安全的发展与进步。由于AI赋能安全的细分领域较多,鉴于篇幅和时间的原因,以下主要介绍其中的两大方面:恶意样本检测、基于UEBA的异常检测。为了让大家能够深刻理解其中的要点,笔者提炼出相应的核心方法论。希望读者能够举一反三,灵活应用到自己的工作生活中。
2. 恶意样本检测
从检测方法上来说,恶意样本检测包括静态检测、动态检测、混合态检测。其中静态检测是指在不运行恶意样本的条件下,进行程序分析的检测方法。而动态检测是指将样本放在隔离环境(沙箱)中自动地动态执行,然后提取其运行过程中的进程操作行为、网络操作行为、文件操作行为等动态行为。而混合态检测指的是综合静态检测与动态检测的检测方法。简单说明下,静态检测与动态检测的主要区别在于是否运行恶意样本。在静态检测中往往是对二进制文件或者反汇编后的 ASM 文件进行检测(后续提到的 CCF 恶意软件检测即基于二进制文件与 ASM 文件进行检测);而动态检测往往是对沙箱运行出的 API 序列进行检测;除此之外,两者的主要区别在于,静态检测的执行效率远远高于动态检测。但动态检测往往能够获得更加完整的信息,即动态检测的漏报率往往低于静态检测。
近年来,不同家族的恶意文件如勒索软件、 木马、 病毒、 挖矿程序等恶意软件不断涌现, 对用户和机构带来了很多麻烦和经济的损失。为了提升海量恶意软件分析的高效性, 需要对恶意软件的家族进行区分。考虑到在很多场景中算力较为有限,无法提供GPU计算资源,在此条件下使用传统机器学习方法更为恰当。在传统机器学习方法中,如何进行有效的特征工程,往往是工作中的重中之重。接下来将会分享一种核心方法论:小颗粒度分析法。
主要内容来自于2021年12月份的论文:Malware Classification Using Static Disassembly and Machine Learning。本论文提出了四大类特征:PE section对应的大小(虚拟大小、原始大小、两者比例)、PE section中不同权限section的大小(可读、可写、可执行段对应的虚拟大小之和、原始大小之和、两者比例)、内容复杂度(PE和ASM文件原始大小、使用zlib对PE和ASM文件进行压缩后的文件大小、压缩前后PE和ASM文件的比例)和导入库。
&emsp什么是细颗粒度分析法呢?对应到上述的文章中,一般来说往往只会考虑到 PE section 中的原始大小,而忽略其虚拟大小,也就是说在大小这个维度上将其细分考虑,即同时考虑到原始大小和虚拟大小则为细颗粒度分析。另外,将 PE section 按照不同权限进行划分,划分后再进行 PE section 对应的大小的建模,本质上是将整个文件的建模细分为不同的 section 进行建模,我们可以将其理解为二层的细颗粒度分析法。当然,颗粒度也并非越小越好(即层数越高越好),需要根据实际数据、具体场景、模型效果来综合判定。
为了提高模型的运行效率,往往会使用特征筛选的方法来减少无效特征,具体来说是使用随机森林模型并通过基尼系数进行特征筛选得到 40 维特征,其维度数远远小于常用的 N-gram 特征,提高了模型的运行效率。实验任务为恶意样本家族九分类,总数据量为 10868 个。其中 80%作为训练集(使用 auto-sklearn 和 5 折交叉经验确定模型及其超参数),20%作为测试集。实验结果表明:使用论文提出的四大类特征的效果较好,位于实验结果第二名(准确率为 0.994)。而第一名(0.9948)是采用了所有特征(特征选择后为 10343 维度)。
为了帮助大家更好的理解细颗粒度分析法,再对大家较为常用的特征之一:熵进行细颗粒度分析法进行分析。在2021年CCF基于人工智能的恶意软件家族分类比赛中,前几名的队伍都构建了熵直方图作为其中一部分特征。具体来说,在二进制文件上滑动一个固定字节长度的窗口,步长也为固定字节长度,通过计算在该窗口中每个字节的出现次数,并计算每个窗口上的以2为底的熵,使用计算出的熵值作为下标,将窗口中每个字节的出现次数自增到特征矩阵相应下标所对应的向量上。随后滑动窗口继续计算对应字节窗口的熵值。在生成特征时,展开该特征矩阵为一维特征向量。计算字节熵时滑动窗口示意图如下图所示。在实际比赛过程中,我们通过上述方法提取的字节统计值特征维数为256。
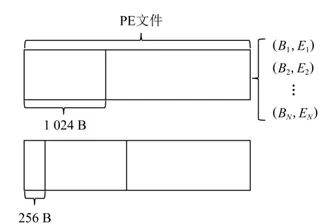
为了方便大家对此特征进行理解,特意进行更加细致的讲解:
原本的信息熵是对每个字节求信息熵,由于字节大小范围为[0, 255],所以一共是256个bins,每个bin内仅仅包含一个字节。不同滑窗但位于相同bin的数据会进行相加。
同时我们将熵的值进行细粒度划分,其中信息熵的最大值为 l o g 2 ( n ) log_2(n) log2(n),n为bin的个数。原本bin的个数为256个,所以最大值为8。如果熵每隔1作为其间隔,那么最终的维度数为256*8=2048维。
如果我们只考虑高4位对应的熵值,然后再乘以2就能近似得到8位对应的熵值。本质是是将ASCII码对应的字符(0~127)一视同仁处理。
由于高4位总共只有16个取值,所以将原有的n从256转换成了16。此时熵的最大值即为 l o g 2 16 = 4 log_2{16}=4 log216=4。同样,我们在熵的维度上进行细粒度的划分,将熵乘以4以后每个bin的距离为1。那么熵这一维的维度数为16。
那么最终的维度数为16*16=256。简单总结下就是把熵值进行了小颗粒度划分,从而将一维特征表示成了二维特征。
顺便提一句,个人也在该比赛中使用了上述特征,并最终取得了第四名的优异成绩。也欢迎大家报名参加各项AI比赛,说不定会找到属于自己的一片天地。

3. 基于UEBA的异常检测
用户与实体行为分析系统采用的UEBA 技术( User and Entity Behaviours Analytics),是网络安全领域里进行异常检测的重要手段之一。在传统检测设备(如 IDS、 IPS、 NGIPS、 NGIDS、FW、 NGFW )中,需要根据专家经验来构建规则,然后通过检索匹配的方法来进行威胁检测。但在部分实际场景中,由于威胁不断演变,所以往往需要灵活的对规则中的部分阈值进行及时调整,从而达到较好的检测效果。
而所谓的UEBA手段不仅是从数据分析的视角去发现关键问题,从聚焦数据内容本身到内容上下文关系、行为分析等,从单点单条检测到多维度大数据分析来发现更多更准确的有价值信息。
2021年的CCF举办了基于UEBA的用户上网异常行为分析比赛,该比赛是基于无标签的用户日常上网日志数据,从而构建用户上网行为基线和上网行为评价模型,依据上网行为与基线的距离确定偏离程度,从而评价上网行为与基线的偏离程度。
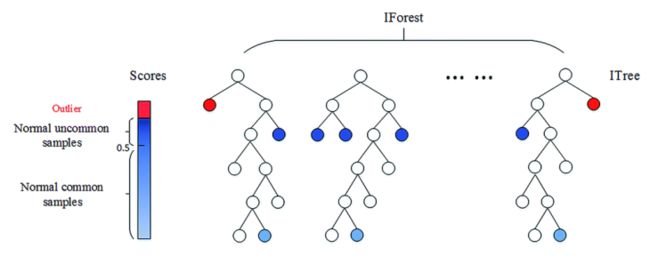
其中第一名使用了将全局语义和局部语义相结合的核心方法论。其中全局指的是基于全部数据构建模型。而局部指的是用户和部门来构建模型,其中每个用户建立一个模型,每个部门建立一个模型。然后对上述三大模型进行集成。其中模型均采用的是孤立森林。
孤立森林具有检测效果好,并且时间复杂度低(时间复杂度)的特点,模型结构如下图所示:
4. 总结与展望
本文主要介绍了AI赋能安全的两大应用场景:恶意样本检测与基于UEBA的异常检测。同时也分享了两大核心方法论:细粒度分析法和全局语义和局部语义相结合的方法。
随着深度学习技术在NLP、CV、推荐系统等领域的蓬勃发展,笔者很看好Transformer等预训练模型、对比学习、Prompt Learning等技术能够成功应用于网络空间安全中。让我们一起努力,为AI赋能安全尽出自己的一份力量。