Redis 通常是我们业务系统中一个重要的组件,比如:缓存、账号登录信息、排行榜等。
一旦 Redis 请求延迟增加,可能就会导致业务系统“雪崩”。
我在单身红娘婚恋类型互联网公司工作,在双十一推出下单就送女朋友的活动。
谁曾想,凌晨 12 点之后,用户量暴增,出现了一个技术故障,用户无法下单,当时老大火冒三丈!
经过查找发现 Redis 报 Could not get a resource from the pool。
获取不到连接资源,并且集群中的单台 Redis 连接量很高。
大量的流量没了 Redis 的缓存响应,直接打到了 MySQL,最后数据库也宕机了……
于是各种更改最大连接数、连接等待数,虽然报错信息频率有所缓解,但还是持续报错。
后来经过线下测试,发现存放 Redis 中的字符数据很大,平均 1s 返回数据。
可以发现,一旦 Redis 延迟过高,会引发各种问题。
今天「码哥」跟大家一起来分析下如何确定 Redis 有性能问题和解决方案。
- Redis 性能出问题了么?
- 延迟基线测量
- 慢指令监控
- 慢日志功能
- Latency Monitoring
- 如何解决 Redis 变慢?
- 网络通信导致的延迟
- 慢指令导致的延迟
- Fork 生成 RDB 导致的延迟
- 内存大页(transparent huge pages)
- swap:操作系统分页
- 获取 Redis 实例 pid
- 解决方案
- AOF 和磁盘 I/O 导致的延迟
- expires 淘汰过期数据
- 解决方案
- bigkey
- 查找 bigkey
- 解决方案
- 对大 key 拆分
- 异步清理大 key
- 总结
Redis 性能出问题了么?
最大延迟是客户端发出命令到客户端收到命令的响应的时间,正常情况下 Redis 处理的时间极短,在微秒级别。
当 Redis 出现性能波动的时候,比如达到几秒到十几秒,这个很明显我们可以认定 Redis 性能变慢了。
有的硬件配置比较高,当延迟 0.6ms,我们可能就认定变慢了。硬件比较差的可能 3 ms 我们才认为出现问题。
那我们该如何定义 Redis 真的变慢了呢?
所以,我们需要对当前环境的 Redis 基线性能做测量,也就是在一个系统在低压力、无干扰情况下的基本性能。
当你发现 Redis 运行时时的延迟是基线性能的 2 倍以上,就可以判定 Redis 性能变慢了。
延迟基线测量
redis-cli 命令提供了–intrinsic-latency 选项,用来监测和统计测试期间内的最大延迟(以毫秒为单位),这个延迟可以作为 Redis 的基线性能。
redis-cli --latency -h `host` -p `port`
比如执行如下指令:
redis-cli --intrinsic-latency 100
Max latency so far: 4 microseconds.
Max latency so far: 18 microseconds.
Max latency so far: 41 microseconds.
Max latency so far: 57 microseconds.
Max latency so far: 78 microseconds.
Max latency so far: 170 microseconds.
Max latency so far: 342 microseconds.
Max latency so far: 3079 microseconds.
45026981 total runs (avg latency: 2.2209 microseconds / 2220.89 nanoseconds per run).
Worst run took 1386x longer than the average latency.
注意:参数
100是测试将执行的秒数。我们运行测试的时间越长,我们就越有可能发现延迟峰值。通常运行 100 秒通常是合适的,足以发现延迟问题了,当然我们可以选择不同时间运行几次,避免误差。
「码哥」运行的最大延迟是 3079 微秒,所以基线性能是 3079 (3 毫秒)微秒。
需要注意的是,我们要在 Redis 的服务端运行,而不是客户端。这样,可以避免网络对基线性能的影响。
可以通过 -h host -p port 来连接服务端,如果想监测网络对 Redis 的性能影响,可以使用 Iperf 测量客户端到服务端的网络延迟。
如果网络延迟几百毫秒,说明网络可能有其他大流量的程序在运行导致网络拥塞,需要找运维协调网络的流量分配。
慢指令监控
如何判断是否是慢指令呢?
看操作复杂度是否是O(N)。官方文档对每个命令的复杂度都有介绍,尽可能使用O(1) 和 O(log N)命令。
涉及到集合操作的复杂度一般为O(N),比如集合全量查询HGETALL、SMEMBERS,以及集合的聚合操作:SORT、LREM、 SUNION等。
有监控数据可以观测呢?代码不是我写的,不知道有没有人用了慢指令。
有两种方式可以排查到:
- 使用 Redis 慢日志功能查出慢命令;
- latency-monitor(延迟监控)工具。
此外,可以使用自己(top、htop、prstat 等)快速检查 Redis 主进程的 CPU 消耗。如果 CPU 使用率很高而流量不高,通常表明使用了慢速命令。
慢日志功能
Redis 中的 slowlog 命令可以让我们快速定位到那些超出指定执行时间的慢命令,默认情况下命令若是执行时间超过 10ms 就会被记录到日志。
slowlog 只会记录其命令执行的时间,不包含 io 往返操作,也不记录单由网络延迟引起的响应慢。
我们可以根据基线性能来自定义慢命令的标准(配置成基线性能最大延迟的 2 倍),调整触发记录慢命令的阈值。
可以在 redis-cli 中输入以下命令配置记录 6 毫秒以上的指令:
redis-cli CONFIG SET slowlog-log-slower-than 6000
也可以在 Redis.config 配置文件中设置,以微秒为单位。
想要查看所有执行时间比较慢的命令,可以通过使用 Redis-cli 工具,输入 slowlog get 命令查看,返回结果的第三个字段以微秒位单位显示命令的执行时间。
假如只需要查看最后 2 个慢命令,输入 slowlog get 2 即可。
示例:获取最近2个慢查询命令
127.0.0.1:6381> SLOWLOG get 2
1) 1) (integer) 6
2) (integer) 1458734263
3) (integer) 74372
4) 1) "hgetall"
2) "max.dsp.blacklist"
2) 1) (integer) 5
2) (integer) 1458734258
3) (integer) 5411075
4) 1) "keys"
2) "max.dsp.blacklist"
以第一个 HGET 命令为例分析,每个 slowlog 实体共 4 个字段:
- 字段 1:1 个整数,表示这个 slowlog 出现的序号,server 启动后递增,当前为 6。
- 字段 2:表示查询执行时的 Unix 时间戳。
- 字段 3:表示查询执行微秒数,当前是 74372 微秒,约 74ms。
- 字段 4: 表示查询的命令和参数,如果参数很多或很大,只会显示部分并给数参数个数。
当前命令是hgetall max.dsp.blacklist。
Latency Monitoring
Redis 在 2.8.13 版本引入了 Latency Monitoring 功能,用于以秒为粒度监控各种事件的发生频率。
启用延迟监视器的第一步是设置延迟阈值(单位毫秒)。只有超过该阈值的时间才会被记录,比如我们根据基线性能(3ms)的 3 倍设置阈值为 9 ms。
可以用 redis-cli 设置也可以在 Redis.config 中设置;
CONFIG SET latency-monitor-threshold 9
工具记录的相关事件的详情可查看官方文档:https://redis.io/topics/latency-monitor
如获取最近的 latency
127.0.0.1:6379> debug sleep 2
OK
(2.00s)
127.0.0.1:6379> latency latest
1) 1) "command"
2) (integer) 1645330616
3) (integer) 2003
4) (integer) 2003
- 事件的名称;
- 事件发生的最新延迟的 Unix 时间戳;
- 毫秒为单位的时间延迟;
- 该事件的最大延迟。
如何解决 Redis 变慢?
Redis 的数据读写由单线程执行,如果主线程执行的操作时间太长,就会导致主线程阻塞。
一起分析下都有哪些操作会阻塞主线程,我们又该如何解决?
网络通信导致的延迟
客户端使用 TCP/IP 连接或 Unix 域连接连接到 Redis。1 Gbit/s 网络的典型延迟约为 200 us。
redis 客户端执行一条命令分 4 个过程:
发送命令-〉 命令排队 -〉 命令执行-〉 返回结果
这个过程称为 Round trip time(简称 RTT, 往返时间),mget mset 有效节约了 RTT,但大部分命令(如 hgetall,并没有 mhgetall)不支持批量操作,需要消耗 N 次 RTT ,这个时候需要 pipeline 来解决这个问题。
Redis pipeline 将多个命令连接在一起来减少网络响应往返次数。

慢指令导致的延迟
根据上文的慢指令监控查询文档,查询到慢查询指令。可以通过以下两种方式解决:
- 比如在 Cluster 集群中,将聚合运算等 O(N) 操作运行在 slave 上,或者在客户端完成。
- 使用高效的命令代替。使用增量迭代的方式,避免一次查询大量数据,具体请查看SCAN、SSCAN、HSCAN和ZSCAN命令。
除此之外,生产中禁用KEYS 命令,它只适用于调试。因为它会遍历所有的键值对,所以操作延时高。
Fork 生成 RDB 导致的延迟
生成 RDB 快照,Redis 必须 fork 后台进程。fork 操作(在主线程中运行)本身会导致延迟。
Redis 使用操作系统的多进程写时复制技术 COW(Copy On Write) 来实现快照持久化,减少内存占用。
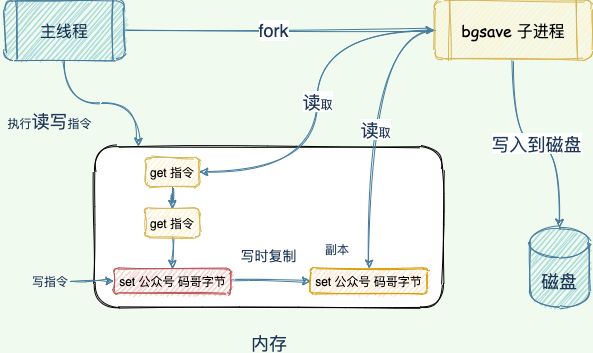
但 fork 会涉及到复制大量链接对象,一个 24 GB 的大型 Redis 实例需要 24 GB / 4 kB * 8 = 48 MB 的页表。
执行 bgsave 时,这将涉及分配和复制 48 MB 内存。
此外,从库加载 RDB 期间无法提供读写服务,所以主库的数据量大小控制在 2~4G 左右,让从库快速的加载完成。
内存大页(transparent huge pages)
常规的内存页是按照 4 KB 来分配,Linux 内核从 2.6.38 开始支持内存大页机制,该机制支持 2MB 大小的内存页分配。
Redis 使用了 fork 生成 RDB 做持久化提供了数据可靠性保证。
当生成 RDB 快照的过程中,Redis 采用写时复制技术使得主线程依然可以接收客户端的写请求。
也就是当数据被修改的时候,Redis 会复制一份这个数据,再进行修改。
采用了内存大页,生成 RDB 期间,即使客户端修改的数据只有 50B 的数据,Redis 需要复制 2MB 的大页。当写的指令比较多的时候就会导致大量的拷贝,导致性能变慢。
使用以下指令禁用 Linux 内存大页即可:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
swap:操作系统分页
当物理内存(内存条)不够用的时候,将部分内存上的数据交换到 swap 空间上,以便让系统不会因内存不够用而导致 oom 或者更致命的情况出现。
当某进程向 OS 请求内存发现不足时,OS 会把内存中暂时不用的数据交换出去,放在 SWAP 分区中,这个过程称为 SWAP OUT。
当某进程又需要这些数据且 OS 发现还有空闲物理内存时,又会把 SWAP 分区中的数据交换回物理内存中,这个过程称为 SWAP IN。
内存 swap 是操作系统里将内存数据在内存和磁盘间来回换入和换出的机制,涉及到磁盘的读写。
触发 swap 的情况有哪些呢?
对于 Redis 而言,有两种常见的情况:
- Redis 使用了比可用内存更多的内存;
- 与 Redis 在同一机器运行的其他进程在执行大量的文件读写 I/O 操作(包括生成大文件的 RDB 文件和 AOF 后台线程),文件读写占用内存,导致 Redis 获得的内存减少,触发了 swap。
码哥,我要如何排查是否因为 swap 导致的性能变慢呢?
Linux 提供了很好的工具来排查这个问题,所以当怀疑由于交换导致的延迟时,只需按照以下步骤排查。
获取 Redis 实例 pid
$ redis-cli info | grep process_id
process_id:13160
进入此进程的 /proc 文件系统目录:
cd /proc/13160
在这里有一个 smaps 的文件,该文件描述了 Redis 进程的内存布局,运行以下指令,用 grep 查找所有文件中的 Swap 字段。
$ cat smaps | egrep '^(Swap|Size)'
Size: 316 kB
Swap: 0 kB
Size: 4 kB
Swap: 0 kB
Size: 8 kB
Swap: 0 kB
Size: 40 kB
Swap: 0 kB
Size: 132 kB
Swap: 0 kB
Size: 720896 kB
Swap: 12 kB
每行 Size 表示 Redis 实例所用的一块内存大小,和 Size 下方的 Swap 对应这块 Size 大小的内存区域有多少数据已经被换出到磁盘上了。
如果 Size == Swap 则说明数据被完全换出了。
可以看到有一个 720896 kB 的内存大小有 12 kb 被换出到了磁盘上(仅交换了 12 kB),这就没什么问题。
Redis 本身会使用很多大小不一的内存块,所以,你可以看到有很多 Size 行,有的很小,就是 4KB,而有的很大,例如 720896KB。不同内存块被换出到磁盘上的大小也不一样。
敲重点了
如果 Swap 一切都是 0 kb,或者零星的 4k ,那么一切正常。
当出现百 MB,甚至 GB 级别的 swap 大小时,就表明,此时,Redis 实例的内存压力很大,很有可能会变慢。
解决方案
- 增加机器内存;
- 将 Redis 放在单独的机器上运行,避免在同一机器上运行需要大量内存的进程,从而满足 Redis 的内存需求;
- 增加 Cluster 集群的数量分担数据量,减少每个实例所需的内存。
AOF 和磁盘 I/O 导致的延迟
为了保证数据可靠性,Redis 使用 AOF 和 RDB 快照实现当即快速恢复和持久化。
**可以使用 appendfsync **配置将 AOF 配置为以三种不同的方式在磁盘上执行 write 或者 fsync (可以在运行时使用 CONFIG SET命令修改此设置,比如:redis-cli CONFIG SET appendfsync no)。
- no:Redis 不执行 fsync,唯一的延迟来自于 write 调用,write 只需要把日志记录写到内核缓冲区就可以返回。
- everysec:Redis 每秒执行一次 fsync。使用后台子线程异步完成 fsync 操作。最多丢失 1s 的数据。
- always:每次写入操作都会执行 fsync,然后用 OK 代码回复客户端(实际上 Redis 会尝试将同时执行的许多命令聚集到单个 fsync 中),没有数据丢失。在这种模式下,性能通常非常低,强烈建议使用快速磁盘和可以在短时间内执行 fsync 的文件系统实现。
我们通常将 Redis 用于缓存,数据丢失完全恶意从数据获取,并不需要很高的数据可靠性,建议设置成 no 或者 everysec。
除此之外,避免 AOF 文件过大, Redis 会进行 AOF 重写,生成缩小的 AOF 文件。
可以把配置项 no-appendfsync-on-rewrite设置为 yes,表示在 AOF 重写时,不进行 fsync 操作。
也就是说,Redis 实例把写命令写到内存后,不调用后台线程进行 fsync 操作,就直接返回了。
expires 淘汰过期数据
Redis 有两种方式淘汰过期数据:
- 惰性删除:当接收请求的时候发现 key 已经过期,才执行删除;
- 定时删除:每 100 毫秒删除一些过期的 key。
定时删除的算法如下:
-
随机采样 A
CTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP个数的 key,删除所有过期的 key; -
如果发现还有超过 25% 的 key 已过期,则执行步骤一。
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP默认设置为 20,每秒执行 10 次,删除 200 个 key 问题不大主。
如果触发了第二条,就会导致 Redis 一致在删除过期数据取释放内存。而删除是阻塞的。
码哥,触发条件是什么呀?
也就是大量的 key 设置了相同的时间参数。同一秒内,大量 key 过期,需要重复删除多次才能降低到 25% 以下。
简而言之:大量同时到期的 key 可能会导致性能波动。
解决方案
如果一批 key 的确是同时过期,可以在 EXPIREAT 和 EXPIRE 的过期时间参数上,加上一个一定大小范围内的随机数,这样,既保证了 key 在一个邻近时间范围内被删除,又避免了同时过期造成的压力。
bigkey
通常我们会将含有较大数据或含有大量成员、列表数的 Key 称之为大 Key,下面我们将用几个实际的例子对大 Key 的特征进行描述:
-
一个 STRING 类型的 Key,它的值为 5MB(数据过大)
-
一个 LIST 类型的 Key,它的列表数量为 10000 个(列表数量过多)
-
一个 ZSET 类型的 Key,它的成员数量为 10000 个(成员数量过多)
-
一个 HASH 格式的 Key,它的成员数量虽然只有 1000 个但这些成员的 value 总大小为 10MB(成员体积过大)
bigkey 带来一问题如下:
- Redis 内存不断变大引发 OOM,或者达到 maxmemory 设 置值引发写阻塞或重要 Key 被逐出;
- Redis Cluster 中的某个 node 内存远超其余 node,但因 Redis Cluster 的数据迁移最小粒度为 Key 而无法将 node 上的内存均衡化;
- bigkey 的读请求占用过大带宽,自身变慢的同时影响到该服务器上的其它服务;
- 删除一个 bigkey 造成主库较长时间的阻塞并引发同步中断或主从切换;
查找 bigkey
使用 redis-rdb-tools 工具以定制化方式找出大 Key。
解决方案
对大 key 拆分
如将一个含有数万成员的 HASH Key 拆分为多个 HASH Key,并确保每个 Key 的成员数量在合理范围,在 Redis Cluster 结构中,大 Key 的拆分对 node 间的内存平衡能够起到显著作用。
异步清理大 key
Redis 自 4.0 起提供了 UNLINK 命令,该命令能够以非阻塞的方式缓慢逐步的清理传入的 Key,通过 UNLINK,你可以安全的删除大 Key 甚至特大 Key。
总结
如下检查清单,帮助你在遇到 Redis 性能变慢的时候能高效解决问题。
- 获取当前 Redis 的基线性能;
- 开启慢指令监控,定位慢指令导致的问题;
- 找到慢指令,使用 scan 的方式;
- 将实例的数据大小控制在 2-4GB,避免主从复制加载过大 RDB 文件而阻塞;
- 禁用内存大页,采用了内存大页,生成 RDB 期间,即使客户端修改的数据只有 50B 的数据,Redis 需要复制 2MB 的大页。当写的指令比较多的时候就会导致大量的拷贝,导致性能变慢。
- Redis 使用的内存是否过大导致 swap;
- AOF 配置是否合理,可以将配置项 no-appendfsync-on-rewrite 设置为 yes,避免 AOF 重写和 fsync 竞争磁盘 IO 资源,导致 Redis 延迟增加。
- bigkey 会带来一些列问题,我们需要进行拆分防止出现 bigkey,并通过 UNLINK 异步删除。