RocketMQ-Streams 聚焦「大数据量->高过滤->轻窗口计算」场景,核心打造轻资源,高性能优势,在资源敏感场景有很大优势,最低 1Core,1G 可部署。通过大量过滤优化,性能比其他大数据提升 2-5 倍性能。广泛应用于安全,风控,边缘计算,消息队列流计算。
RocketMQ-Streams 兼容 Flink 的 SQL,udf/udtf/udaf,将来我们会和 Flink 生态做深度融合,即可以独立运行,也可发布成 Flink 任务,跑在 Flink 集群,对于有 Flink 集群的场景,即能享有轻资源优势,可以做到统一部署和运维。
RocketMQ-Streams 特点及应用场景
RocketMQ-Streams 应用场景
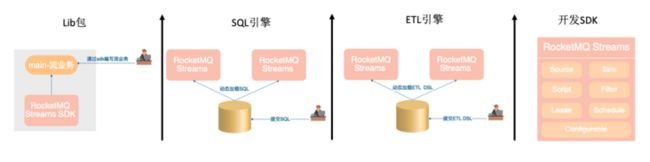
• 计算场景: 适合大数据量->高过滤->轻窗口计算的场景。不同于主流计算引擎,需要先部署集群,写任务,发布,调优,运行这么复杂的过程。RocketMQ-Streams 本身就是一个 lib 包,基于 SDK 写完流任务,可以直接运行。支持大数据开发需要的计算特性:Exactly-ONCE,灵活窗口(滚动、滑动、会话),双流Join,高吞吐、低延迟、高性能。最低 1Core,1G 可以运行。
• SQL引擎 : RocketMQ-Streams 可视作一个 SQL 引擎,兼容 Flink SQL 语法,支持 Flink udf/udtf/udaf 的扩展。支持 SQL 热升级,写完 SQL,通过 SDK 提交 SQL,就可以完成 SQL 的热发布。
• ETL引擎: RocketMQ-Streams 还可视作 ETL 引擎,在很多大数据场景,需要完成数据从一个源经过 ETl,汇聚到统一存储,里面内置了 grok,正则解析等函数,可以结合 SQL 一块完成数据 ETL 。
• 开发 SDK,它也是一个数据开发 SDK 包,里面的大多数组件都可以单独使用,如 Source/sink,它屏蔽了数据源,数据存储细节,提供统一编程接口,一套代码,切换输入输出,不需要改变代码。
RocketMQ-Streams 设计思路
设计目标
• 依赖少,部署简单,1Core,1G 单实例可部署,可随意扩展规模。
• 实现需要的大数据特性:Exactly-ONCE,灵活窗口(滚动、滑动、会话),双流 Join,高吞吐、低延迟、高性能。
• 实现成本可控,实现低资源,高性能。
• 兼容 Flink SQL,UDF/UDTF,让非技术人员更易上手。
设计思路
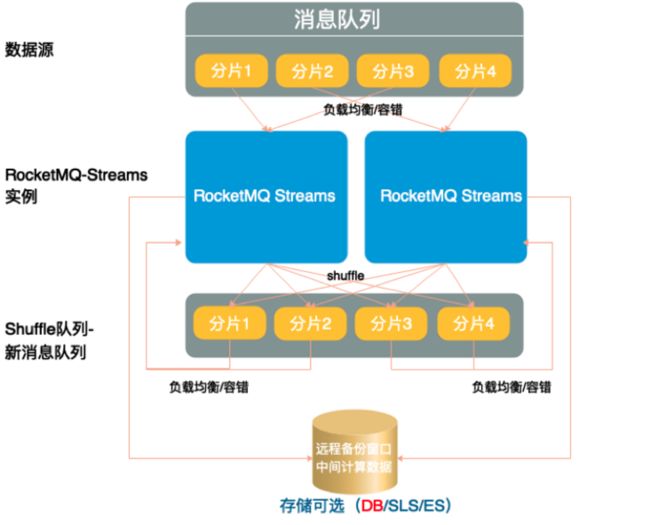
• 采用 shared-nothing 的分布式架构设计,依赖消息队列做负载均衡和容错机制,单实例可启动,增加实例实现能力扩展。并发能力取决于分片数。
• 利用消息队列的分片做 shuffle,利用消息队列负载均衡实现容错。
• 利用存储实现状态备份,实现 Exactly-ONCE 的语义。用结构化远程存储实现快速启动,不必等本地存储恢复。
RocketMQ-Streams 特点和创新

RocketMQ-Streams SDK 详解
Hello World
按照惯例,我们先从一个例子来了解 RocketMQ-Streams
• namespace:相同 namespace 的任务可以跑在一个进程里,可以共享配置
• pipelineName:job name
• DataStreamSource:创建 source 节点
• map:用户函数,可以通过实现 MapFunction 扩展功能
• toPrint:结果打印出来
• start:启动任务
• 运行上面代码就会启动一个实例。如果想多实例并发,可以启动多个实例,每个实例消费部分 RocketMQ 的数据。
• 运行结果:把原始消息拼接上“—”,并打印出来
RocketMQ-Streams SDK
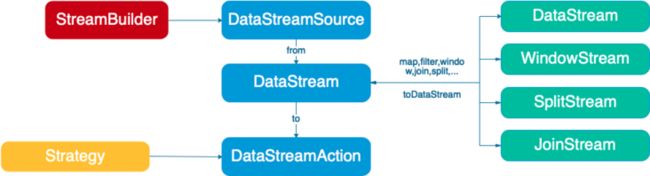
• StreamBuilder 做为起点,通过设置 namespace,jobName 创建一个 DataStreamSource 。
• DataStreamSource 通过 from 方法,设置 source,创建 DataStream 对象。
• DataStream 提供多种操作,会产生不同的流:
• to 操作产生 DataStreamAction
• window 操作产生 WindowStream 配置 window 参数
• join 操作产生 JoinStream 配置 join 条件
• Split 操作产生 SplitStream 配置 split 条件
• 其他操作产生 DataStream
• DataStreamAction 启动整个任务,也可以配置任务的各种策略参数。支持异步启动和同步启动。
RocketMQ-Streams 算子

RocketMQ-Streams 算子
SQL 有两种部署模式,1 是直接运行 client 启动 SQL,见第一个红框;2 是搭建 server 集群,通过 client 提交 SQL 实现热部署,见第二个红框。
RocketMQ-Streams SQL 扩展,支持多种扩展方式:
• 通过 FlinkUDF,UDTF,UDAF 扩展 SQL 能力,在 SQL 中通过 create function 引入,有个限制条件,即 UDF 在 open 时未用到 Flink FunctionContext 的内容。
• 通过内置函数扩展 SQL 的函数,语法同 Flink 语法,函数名是内置函数的名称,类名是固定的。如下图,引入了一个 now 的函数,输出当前时间。系统内置了 200 多个函数,可按需引入。
![]()
• 通过扩展函数实现,实现一个函数很简单,只需要在 class 上标注 Function,在需要发布成函数的方法上标注 FunctionMethod,并设置需要发布的函数名即可,如果需要系统信息,前面两个函数可以是 IMessage 和 Abstract,如果不需要,直接写参数即可,参数无格式要求。如下图,创建了一个 now 的函数,两种写法都可以。可以通过 currentTime=now()来调用,会在 Message 中增加一个 key=currentTime,value=当前时间的变量。

• 把现有 java 代码发布成函数,通过策略配置,把 java 代码的类名,方法名,期望用到的函数名,配置进去,把 java 的 jar 包 copy 到 jar 包目录即可。下图是几种扩展的应用实例。
RocketMQ-Streams 架构及原理实现
整体架构
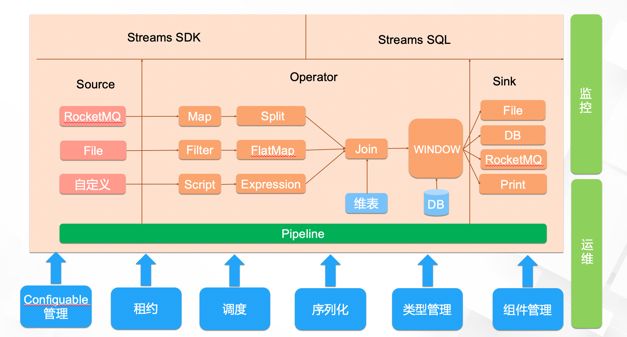
Source 实现
• Source 要求实现最少消费一次的语义,系统通过 checkpoint 系统消息实现,在提交 offset 前发送 checkpoint 消息,通知所有算子刷新内存。
• Source 支持分片的自动负载均衡和容错。
• 数据源在分片移除时,发送移除系统消息,让算子完成分片清理工作。
• 当有新分片时, 发送新增分片消息,让算子完成分片的初始化。
• 数据源通过 start 方法,启动 consuemr 获取消息。
• 原始消息经过编码,附加头部信息包装成 Message 投递给后续算子。
Sink 实现
• Sink 是实时性和吞吐的一个结合。
• 实现一个 Sink 只要继承 AbstractSink 类实现 batchInsert 方法即可。batchInsert 的含义是一批数据写入存储,需要子类调用存储接口实现,尽量应用存储的批处理接口,提高吞吐。
• 常规的使用方式是写 Message->cache->flush->存储的方式,系统会严格保证,每次批次写入存储的量不超过 batchsize 的量,如果超了,会拆分成多批写入。
• Sink 有一个 cache,数据默认写 cache,批次写入存储,提高吞吐量。(一个分片一个 cache)。
• 可以开启自动刷新,每个分片会有一个线程,定时刷新 cache 数据到存储,提高实时性。实现类:DataSourceAutoFlushTask 。
• 也可以通过调用 flush 方法刷新 cache 到存储。
• Sink 的 cache 会有内存保护,当 cache 的消息条数>batchSize,会强制刷新,释放内存。
RocketMQ-Streams Exactly-ONCE
• Source 确保在 commit offset 时,会发送 checkpoint 系统消息,收到消息的组件会完成存盘操作。消息至少消费一次。
• 每条消息会有消息头部,里面封装了 QueueId 和 offset 。
• 组件在存储数据时,会把 QueueId 和处理的最大 offset 存储下来,当有消息重复时,根据 maxoffset 去重。
• 内存保护,一个 checkpoint 周期可能有多次 flush(条数触发),保障内存占用可控。

RocketMQ-Streams Window
• 支持滚动,滑动和会话窗口。支持事件时间和自然时间(消息进入算子的时间)。
• 支持高性能模式和高可靠模式,高性能模式不依赖远程存储,但在分片切换时的窗口数据会有丢失。
• 快速启动,无需等本地存储恢复,在发生错误或分片切换时,异步从远程存储恢复数据,同时直接访问远程存储计算。
• 利用消息队列负载均衡,实现扩容缩容,每个 Queue 是一个分组,一个分组同一刻只被一台机器消费。
• 正常计算依赖本地存储,具备 Flink 相似的计算性能。
支持三种触发模式,可以均衡 watermark 延迟和实时性要求

RocketMQ-Streams 在云安全的应用
在安全应用的背景
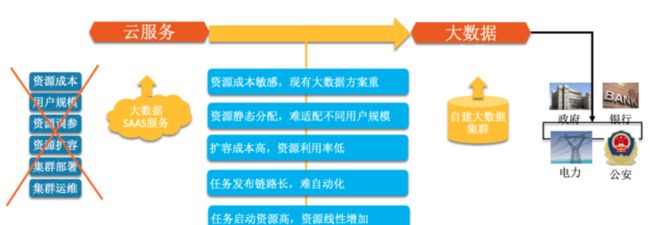
• 公共云转战专有云,在入侵检测计算方面遇到了资源问题,大数据集群默认不输出,输出最低 6 台高配机器,用户很难接受因为买云盾增配一套大数据集群。
• 专有云用户升级,运维困难,无法快速升级能力和修复 bug。
流计算在安全的应用
• 基于安全特点(大数据->高过滤->轻窗口计算)打造轻量级计算引擎:经过分析所有的规则都会做前置过滤,然后才会做较重的统计,窗口,join 操作,且过滤率比较高,基于此特点,可以用更轻的方案实现统计,join 操作。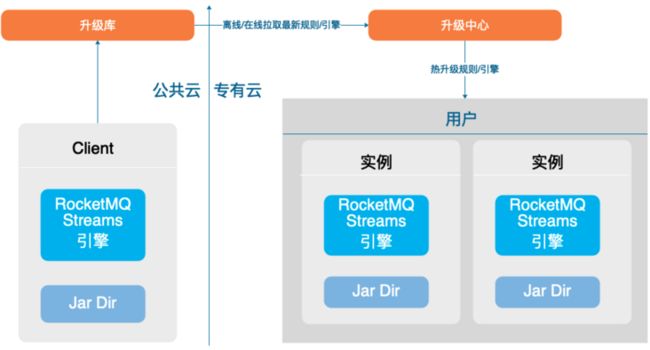
• 通过 RocketMQ-Streams,覆盖 100%专有云规则(正则,join,统计)。
• 轻资源,内存是公共云引擎的 1/70,CPU 是 1/6,通过指纹过滤优化,性能提升 5 倍以上,且资源不随规则线性增加,新增规则无资源压力。复用以前的正则引擎资源,可支持 95%以上局点,不需要增加额外物理资源。
• 通过高压缩维表,支持千万情报。1000 W 数据只需要 330 M 内存。
• 通过 C/S 部署模式,SQL 和引擎可热发布,尤其护网场景,可快速上线规则。
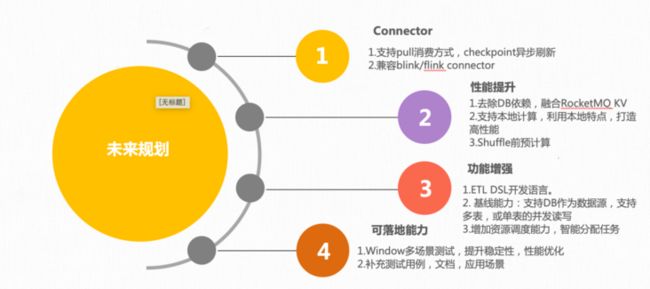
RocketMQ-Streams 未来规划
新版本下载地址:https://github.com/apache/roc...