Python数据爬取——获取国家社科基金
案例任务: 1. 把[‘文学’,‘历史’,‘哲学’,‘艺术学’,‘语言’,‘考古’]去掉,就光看社会科学类的,数据有一些重的,需要把项目批准编号相同的清洗一下,经管的老师一般不会申请人文、历史哲学这类人文项目,分析一下社会科学的即可。2. 再重点分析管理学、经济学(理论经济和应用经济)、图情学科。3. 需要十八大和十九大两个阶段的对比分析。4. 对十九大以来,管理学、经济学、图情学科,逐年的词条分析,看变化情况。
获取国家社科基金数据
- 一、Python获取数据
- 二、Python连接MSSQL数据库服务器并上传数据
一、Python获取数据

# 导入库
import pandas as pd
import urllib
import requests
from lxml import etree
import urllib.request as req
import re
import requests
from lxml import etree
from bs4 import BeautifulSoup
import urllib.request as req
import requests
import time
import numpy as np
import urllib
import os
国家社科基金数据库网址:http://fz.people.com.cn/skygb/sk/index.php/index/seach/
headers={'User-Agent':'ozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56'}
url='http://fz.people.com.cn/skygb/sk/index.php/index/seach/' # 该地址是第一页的数据
for ski in range(0,10):
reuqest=urllib.request.Request(url,headers=headers) # 向服务器请求(包括握手动作)
content=urllib.request.urlopen(reuqest).read()
content # 通过国家社科基金的页面获取内容(HTML)
content的内容:

soup=BeautifulSoup(content,'lxml') # 通过美汤方式获取页面
soup
soup的内容:
发现要获取的内容都在table之中:
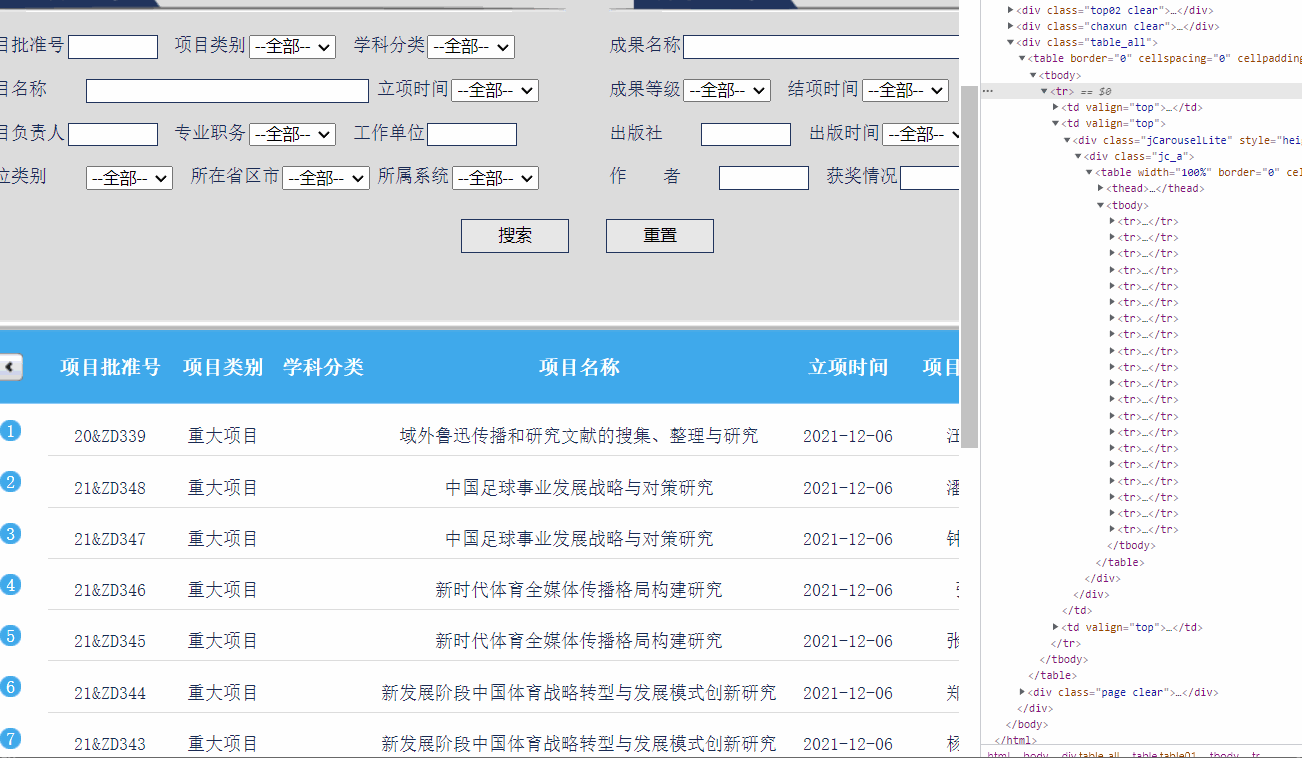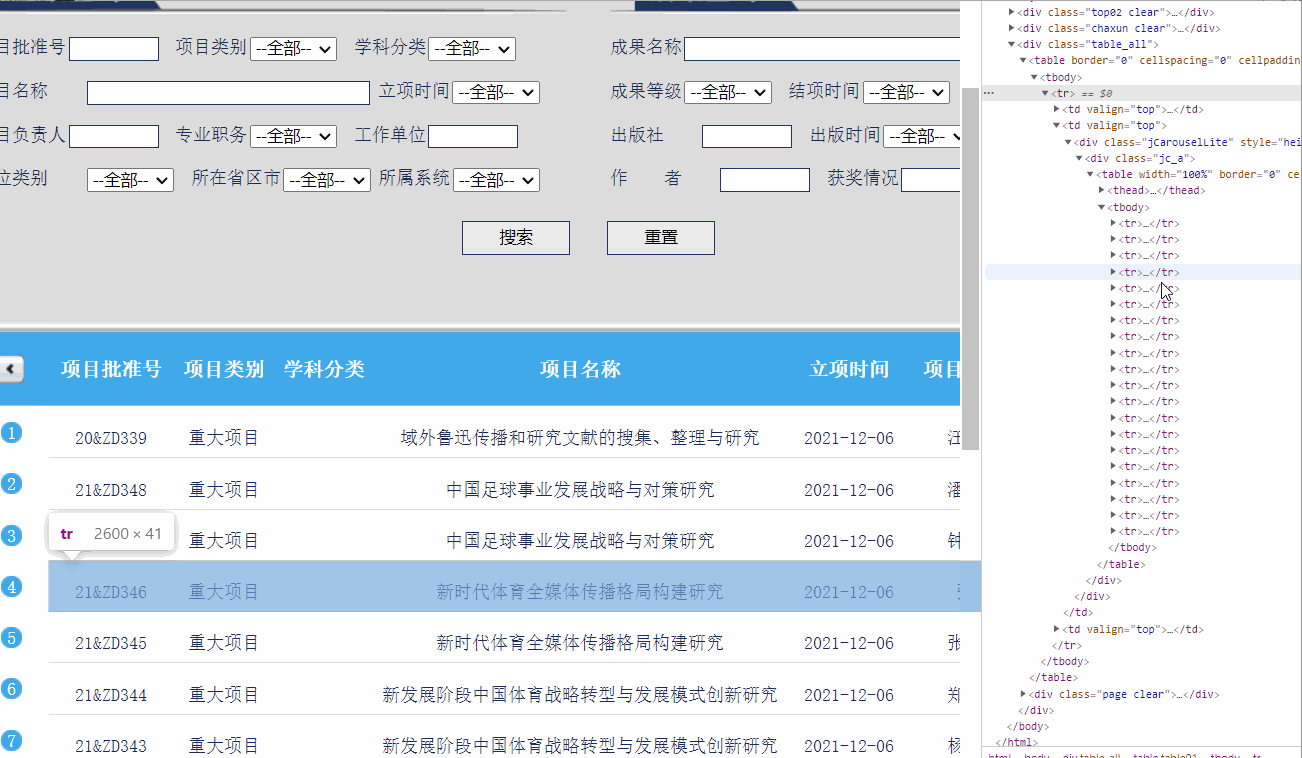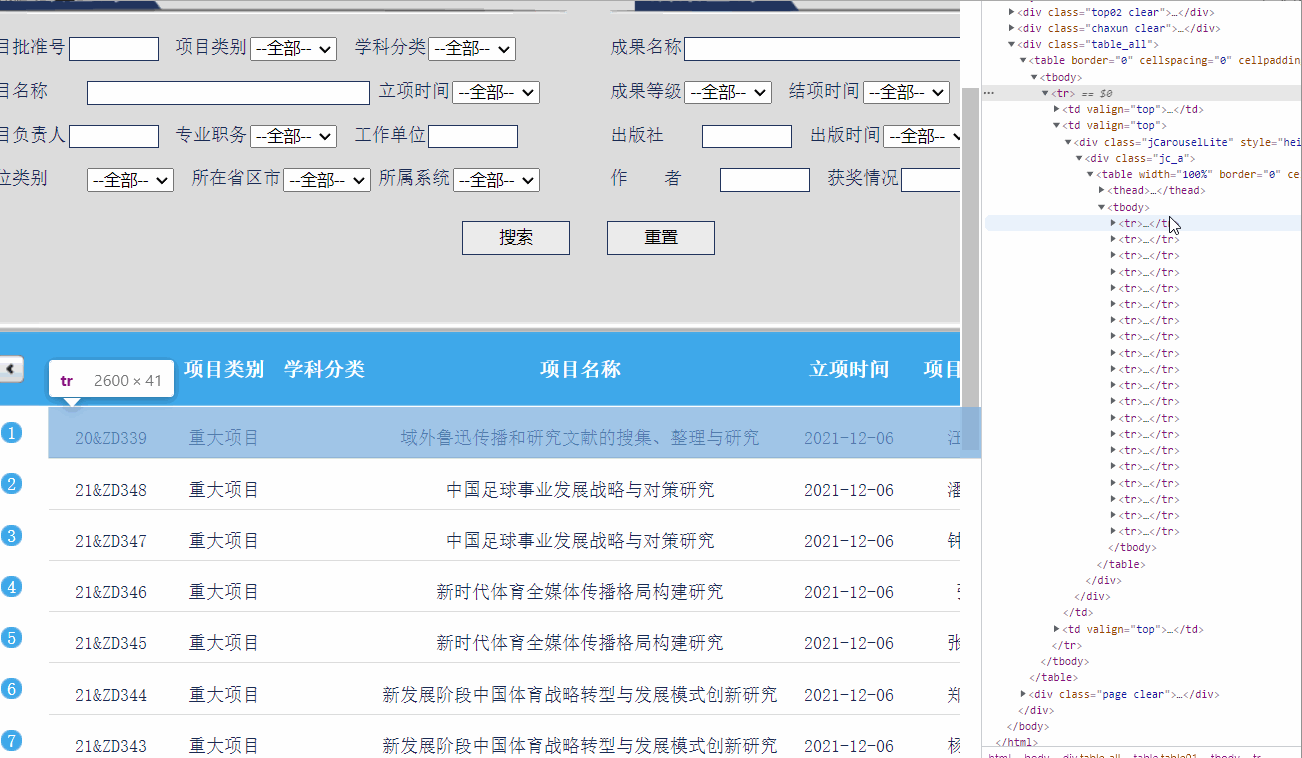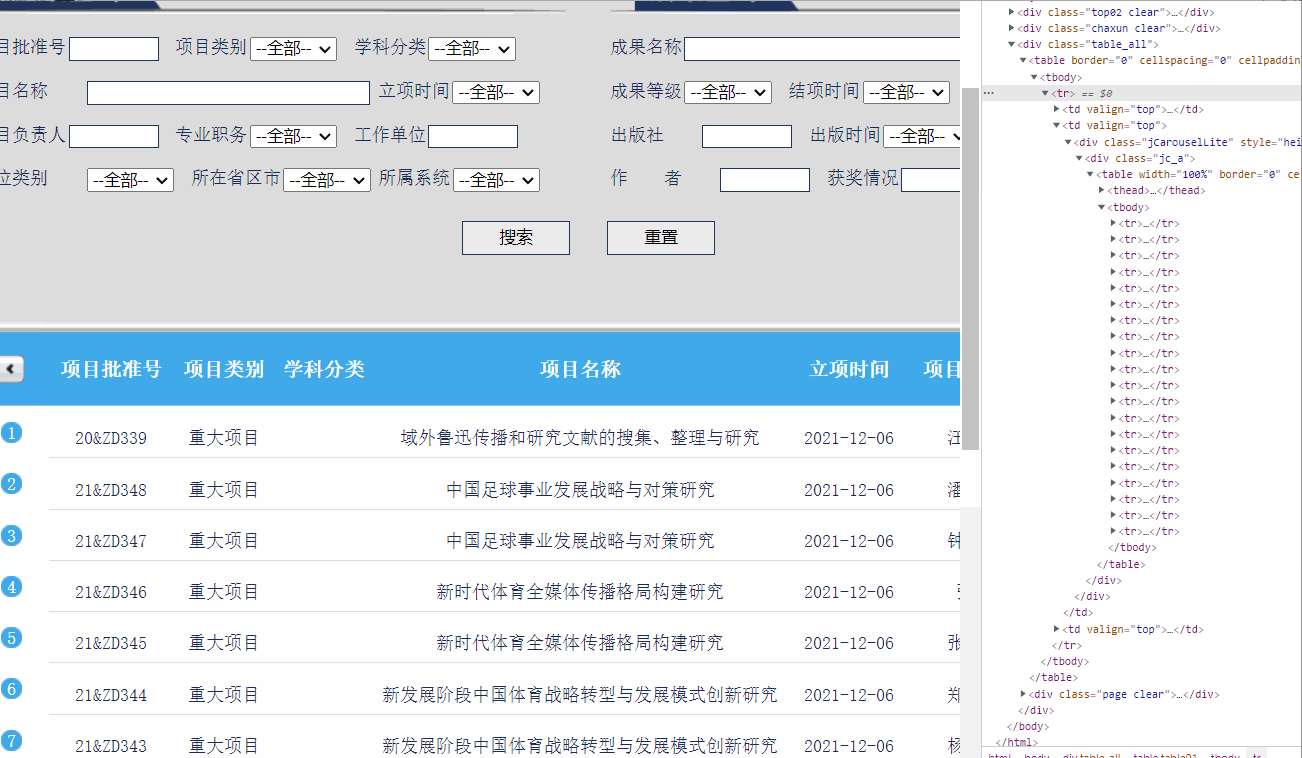
tables=soup.findAll('table') # 找到所有的table结点
tables
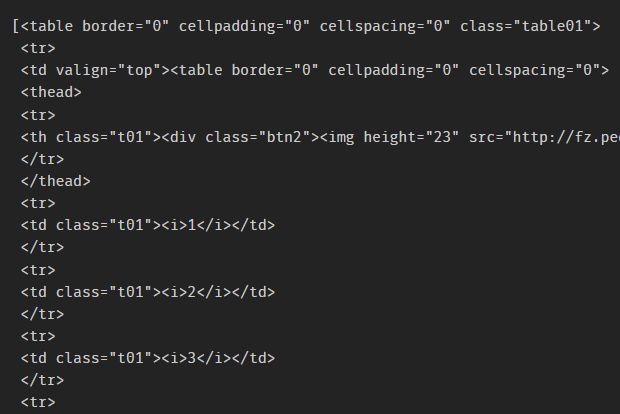
print(type(tables)) # 结果为: 因此: tables是set(数据集)类型
知道tables是数据集类型,发现tables[2]就是我们所需的内容:
tables[2]
soup=BeautifulSoup(content,'lxml')
tab=tables[2] # 查找发现tables[2]是我们要的数据
skdata=pd.read_html(tab.prettify()) # prettify()方法:让页面更友好的显示
skdata
skdata的内容:

skdf=pd.DataFrame(skdata[0])
skdf
skdf的内容:
headers={'User-Agent':'ozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56'}
skdfs=pd.DataFrame()
for ski in range(0,10):
skdf=pd.DataFrame()
url='http://fz.people.com.cn/skygb/sk/index.php/index/seach/'+str(ski)
reuqest=urllib.request.Request(url,headers=headers) # 向服务器请求(包括握手动作)
content=urllib.request.urlopen(reuqest).read()
soup=BeautifulSoup(content,'lxml')
tables=soup.findAll('table')
tab=tables[2]
skdfdata=pd.read_html(tab.prettify())
skdf=pd.DataFrame(skdata[0])
skdfs=skdfs.append(skdf)
print('已经完成第'+str(ski)+'页')
time.sleep(np.random.randint(3)) # 加上这个语句减少爬取网页的负担,每爬取一页数据就休息3秒
# time.sleep给出一个假象,即让服务器认为是不同的人在访问数据
skdfs.to_excel("skfiles.xlsx",encoding='utf-8-sig') # 生成一份excel文件
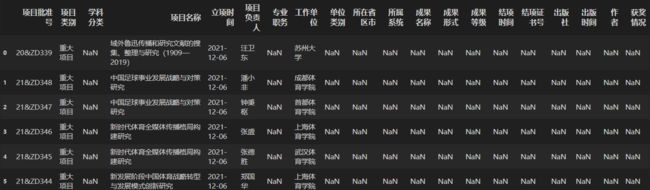
结果如下:

找到生成的skfiles.xlsx文件:
![]()
如下图就是爬取的数据:
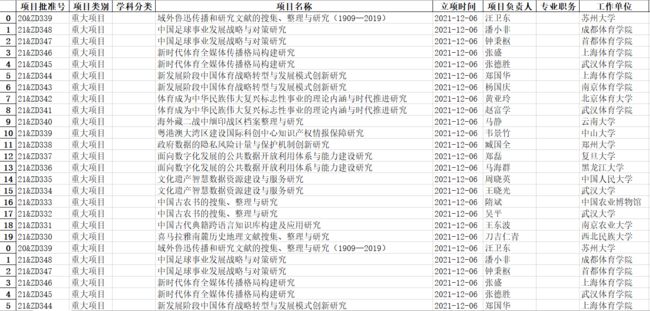
二、Python连接MSSQL数据库服务器并上传数据
把获取的内容放入数据库当中:
import pymssql # 引入库
conn=pymssql.connect("127.0.0.1","sa","123456","PyDatas") # 连接本地数据库服务器
c=conn.cursor()
c.execute("select*from covid19data")
row01=c.fetchone()
print(row01)
conn=pymssql.connect("1**.17.2**.29","s072*03***","*03***","pydatas")
c=conn.cursor()
c.execute('''
IF OBJECT_ID('sktable', 'U') IS NOT NULL DROP TABLE persons
create table sktable
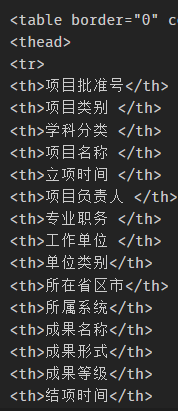
(
项目批准号 nvarchar(100),
项目类别 nvarchar(100),
学科分类 nvarchar(100),
项目名称 nvarchar(100),
立项时间 nvarchar(100),
项目负责人 nvarchar(100),
专业职务 nvarchar(100),
工作单位 nvarchar(100),
单位类别 nvarchar(100),
所在省区市 nvarchar(100),
所属系统 nvarchar(100),
成果名称 nvarchar(100),
成果形式 nvarchar(100),
成果等级 nvarchar(100),
结项时间 nvarchar(100),
结项证书号 nvarchar(100),
出版社 nvarchar(100),
出版时间 nvarchar(100),
作者 nvarchar(100),
获奖情况 nvarchar(100)
)
''')
conn.commit()
conn.close()
# 利用create_engine创建数据库的连接
import pandas as pd
from sqlalchemy import create_engine
import sqlalchemy
# 将dataframe导入数据库当中
engine = create_engine('mssql+pymssql://sa:[email protected]/PyDatas')
c.execute("select * from sktable")
row01=c.fetchall()
print(row01)