redis数据,编码和数据结构关系
Redis构建的类型系统
Redis构建了自己的类型系统,主要包括
- redisObject对象
- 基于redisObject对象的类型检查
- 基于redisObject对象的显示多态函数
- 对redisObject进行分配、共享和销毁的机制
C语言不是面向对象语言,这里将redisObject称呼为对象是为了讲述方便,让里面的内容更容易被理解,redisObject其实是一个结构体。
redisObject对象
Redis内部使用一个redisObject对象来表示所有的key和value,每次在Redis数据块中创建一个键值对时,一个是键对象,一个是值对象,而Redis中的每个对象都是由redisObject结构来表示。
在Redis中,键总是一个字符串对象,而值可以是字符串、列表、集合等对象,所以我们通常说键为字符串键,表示这个键对应的值为字符串对象,我们说一个键为集合键时,表示这个键对应的值为集合对象
redisobject最主要的信息:
redisobject源码
typedef struct redisObject{
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层数据结构的指针
void *ptr;
//引用计数
int refcount;
//记录最后一次被程序访问的时间
unsigned lru:22;
}robj
-
type代表一个value对象具体是何种数据类型
- type key :判断对象的数据类型
-
encoding属性和*prt指针
-
prt指针指向对象底层的数据结构,而数据结构由encoding属性来决定
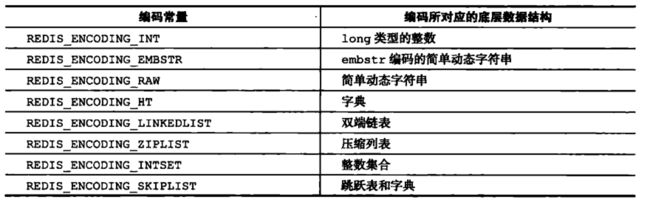
-
每种类型的对象至少使用了两种不同的编码,而这些编码对用户是完全透明的。

-
object encoding key命令可以查看值对象的编码
-
命令的类型检查和多态
Redis命令分类
- 一种是只能用于对应数据类型的命令,例如LPUSH和LLEN只能用于列表键, SADD 和 SRANDMEMBER只能用于集合键。
- 另一种是可以用于任何类型键的命令。比如TTL。
当执行一个处理数据类型的命令时,Redis执行以下步骤:
- 根据给定
key,在数据库字典中查找和它相对应的redisObject,如果没找到,就返回NULL。 - 检查
redisObject的type属性和执行命令所需的类型是否相符,如果不相符,返回类型错误。 - 根据
redisObject的encoding属性所指定的编码,选择合适的操作函数来处理底层的数据结构。 - 返回数据结构的操作结果作为命令的返回值。
5种数据类型对应的编码和数据结构
string
string 是最常用的一种数据类型,普通的key/value存储都可以归结为string类型,value不仅是string,也可以是数字。其他几种数据类型的构成元素也都是字符串,注意Redis规定字符串的长度不能超过512M
- 编码
字符串对象的编码可以是int raw embstr- int编码
- 保存的是可以用long类型表示的整数值
- raw编码
- 保存长度大于44字节的字符串
- embstr编码
- 保存长度小于44字节的字符串
- int编码
int用来保存整数值,raw用来保存长字符串,embstr用来保存短字符串。embstr编码是用来专门保存短字符串的一种优化编码。
Redis中对于浮点型也是作为字符串保存的,在需要时再将其转换成浮点数类型
-
编码的转换
- 当 int 编码保存的值不再是整数,或大小超过了long的范围时,自动转化为raw
- 对于 embstr 编码,由于 Redis 没有对其编写任何的修改程序(embstr 是只读的),在对embstr对象进行修改时,都会先转化为raw再进行修改,因此,只要是修改embstr对象,修改后的对象一定是raw的,无论是否达到了44个字节。
-
常用命令
-
set/get
- set:设置key对应的值为string类型的value (多次set name会覆盖)
- get:获取key对应的值
-
mset /mget
- mset 批量设置多个key的值,如果成功表示所有值都被设置,否则返回0表示没有任何值被设置
- mget批量获取多个key的值,如果不存在则返回null
127.0.0.1:6379> mset user1:name redis user1:age 22 OK 127.0.0.1:6379> mget user1:name user1:age 1) "redis" 2) "22"- 应用场景
- 类似于哈希操作,存储对象
-
incr && incrby<原子操作>
- incr对key对应的值进行加加操作,并返回新的值,incrby加指定的值
-
decr && decrby<原子操作>
- decr对key对应的值进行减减操做,并返回新的值,decrby减指定的值
-
setnx <小小体验一把分布式锁,真香>
- 设置Key对应的值为string类型的值,如果已经存在则返回0
-
setex
- 设置key对应的值为string类型的value,并设定有效期
-
setrange/getrange
- setrange从指定位置替换字符串
- getrange获取key对应value子字符串
-
-
其他命令
- msetnx 同mset,不存在就设置,不会覆盖已有的key
- getset 设置key的值,并返回key旧的值
- append 给指定的key的value追加字符串,并返回新字符串的长度
- strlen 返回key对应的value字符串的长度
-
应用场景
- 因为string类型是二进制安全的,可以用来存放图片,视频等内容。
- 由于redis的高性能的读写功能,而string类型的value也可以是数字,可以用做计数器(使用INCR,DECR指令)。比如分布式环境中统计系统的在线人数,秒杀等。
- 除了上面提到的,还有用于SpringSession实现分布式session
- 分布式系统全局序列号
list
list列表,它是简单的字符串列表,你可以添加一个元素到列表的头部,或者尾部。
-
编码
- 列表对象的编码可以是ziplist(压缩列表)和linkedlist(双端链表)。
- 编码转换
- 同时满足下面两个条件时使用压缩列表:
- 列表保存元素个数小于512个
- 每个元素长度小于64字节
- 不能满足上面两个条件使用linkedlist(双端列表)编码
- 同时满足下面两个条件时使用压缩列表:
-
常用命令
- lpush: 从头部加入元素
127.0.0.1:6379> lpush list1 hello (integer) 1 127.0.0.1:637 9> lpush list1 world (integer) 2 127.0.0.1:6379> lrange list1 0 -1 1) "world" 2) "hello"- rpush:从尾部加入元素
127.0.0.1:6379> rpush list2 world (integer) 1 127.0.0.1:6379> rpush list2 hello (integer) 2 127.0.0.1:6379> lrange list2 0 -1 1) "world" 2) "hello"- lpop: 从list的头部删除元素,并返回删除的元素
127.0.0.1:6379> lrange list1 0 -1 1) "world" 2) "hello" 127.0.0.1:6379> lpop list1 "world" 127.0.0.1:6379> lrange list1 0 -1 1) "hello"- rpop:从list的尾部删除元素,并返回删除的元素
127.0.0.1:6379> lrange list2 0 -1 1) "hello" 2) "world" 127.0.0.1:6379> rpop list2 "world" 127.0.0.1:6379> lrange list2 0 -1 1) "hello"- rpoplpush: 第一步从尾部删除元素,第二步从首部插入元素 结合着使用
- linsert :插入方法 linsert listname before [集合的元素] [插入的元素]
127.0.0.1:6379> lpush list3 hello (integer) 1 127.0.0.1:6379> lpush list3 world (integer) 2 127.0.0.1:6379> linsert list3 before hello start (integer) 3 127.0.0.1:6379> lrange list3 0 -1 1) "world" 2) "start" 3) "hello"- lset :替换指定下标的元素
127.0.0.1:6379> lrange list1 0 -1 1) "a" 2) "b" 127.0.0.1:6379> lset list1 0 v OK 127.0.0.1:6379> lrange list1 0 -1 1) "v" 2) "b"- lrm : 删除元素,返回删除的个数
127.0.0.1:6379> lrange list1 0 -1 1) "b" 2) "b" 3) "a" 4) "b" 127.0.0.1:6379> lrange list1 0 -1 1) "a" 2) "b"- lindex: 返回list中指定位置的元素
- llen: 返回list中的元素的个数
-
实现数据结构
- Stack(栈)
- LPUSH+LPOP
- Queue(队列)
- LPUSH + RPOP
- Blocking MQ(阻塞队列)
- LPUSH+BRPOP
- Stack(栈)
-
应用场景
- 实现简单的消息队列
- 利用LRANGE命令,实现基于Redis的分页功能
set
集合对象set是string类型(整数也会转成string类型进行存储)的无序集合。注意集合和列表的区别:集合中的元素是无序的,因此不能通过索引来操作元素;集合中的元素不能有重复。
-
编码
-
集合对象的编码可以是intset或者hashtable
- intset编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合中。
- hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是一个字符串对象,这里的每个字符串对象就是一个集合中的元素,而字典的值全部设置为null。当使用HT编码时,Redis中的集合SET相当于Java中的HashSet,内部的键值对是无序的,唯一的。内部实现相当于一个特殊的字典,字典中所有value都是NULL。
-
编码转换
- 当集合满足下列两个条件时,使用intset编码:
- 集合对象中的所有元素都是整数
- 集合对象所有元素数量不超过512
- 当集合满足下列两个条件时,使用intset编码:
-
-
常用命令
- sadd: 向集合中添加元素 (set不允许元素重复)
- smembers: 查看集合中的元素
127.0.0.1:6379> sadd set1 aaa (integer) 1 127.0.0.1:6379> sadd set1 bbb (integer) 1 127.0.0.1:6379> sadd set1 ccc (integer) 1 127.0.0.1:6379> smembers set1 1) "aaa" 2) "ccc" 3) "bbb"-
srem: 删除集合元素
-
spop: 随机返回删除的key
-
sdiff :返回两个集合的不同元素 (哪个集合在前就以哪个集合为标准)
127.0.0.1:6379> smembers set1 1) "ccc" 2) "bbb" 127.0.0.1:6379> smembers set2 1) "fff" 2) "rrr" 3) "bbb" 127.0.0.1:6379> sdiff set1 set2 1) "ccc" 127.0.0.1:6379> sdiff set2 set1 1) "fff" 2) "rrr"- sinter: 返回两个集合的交集
- sinterstore: 返回交集结果,存入目标集合
127.0.0.1:6379> sinterstore set3 set1 set2 (integer) 1 127.0.0.1:6379> smembers set3 1) "bbb"-
sunion: 取两个集合的并集
-
sunionstore: 取两个集合的并集,并存入目标集合
-
smove: 将一个集合中的元素移动到另一个集合中
-
scard: 返回集合中的元素个数
-
sismember: 判断某元素是否存在某集合中,0代表否 1代表是
-
srandmember: 随机返回一个元素
127.0.0.1:6379> srandmember set1 1 1) "bbb" 127.0.0.1:6379> srandmember set1 2 1) "ccc" 2) "bbb" -
应用场景
- 对于 set 数据类型,由于底层是字典实现的,查找元素特别快,另外set 数据类型不允许重复,利用这两个特性我们可以进行全局去重,比如在用户注册模块,判断用户名是否注册;微信点赞,微信抽奖小程序
- 另外就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好,可能认识的人等功能。
zset
和集合对象相比,有序集合对象是有序的。与列表使用索引下表作为排序依据不同,有序集合为每一个元素设置一个分数(score)作为排序依据。
-
编码
-
有序集合的编码可以使ziplist或者skiplist
- ziplist编码的有序集合对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个节点保存元素的分值。并且压缩列表内的集合元素按分值从小到大的顺序进行排列,小的放置在靠近表头的位置,大的放置在靠近表尾的位置。
- skiplist编码的依序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表
typedef struct zset{ //跳跃表 zskiplist *zsl; //字典 dict *dice; }zset 字典的键保存元素的值,字典的值保存元素的分值,跳跃表节点的object属性保存元素的成员,跳跃表节点的score属性保存元素的分值。这两种数据结构会通过指针来共享相同元素的成员和分值,所以不会产生重复成员和分值,造成内存的浪费。 -
编码转换
- 当有序结合对象同时满足以下两个条件时,对象使用ziplist编码,否则使用skiplist编码
- 保存的元素数量小于128
- 保存的所有元素长度都小于64字节
- 当有序结合对象同时满足以下两个条件时,对象使用ziplist编码,否则使用skiplist编码
-
-
常用命令
- zrem: 删除集合中名称为key的元素member
- zincrby: 以指定值去自动递增
- zcard: 查看元素集合的个数
- zcount: 返回score在给定区间中的数量
127.0.0.1:6379> zrange zset 0 -1 1) "one" 2) "three" 3) "two" 4) "four" 5) "five" 6) "six" 127.0.0.1:6379> zcard zset (integer) 6 127.0.0.1:6379> zcount zset 1 4 (integer) 4- zrangebyscore: 找到指定区间范围的数据进行返回
127.0.0.1:6379> zrangebyscore zset 0 4 withscores 1) "one" 2) "1" 3) "three" 4) "2" 5) "two" 6) "2" 7) "four" 8) "4"- zremrangebyrank zset from to: 删除索引
127.0.0.1:6379> zrange zset 0 -1 1) "one" 2) "three" 3) "two" 4) "four" 5) "five" 6) "six" 127.0.0.1:6379> zremrangebyrank zset 1 3 (integer) 3 127.0.0.1:6379> zrange zset 0 -1 1) "one" 2) "five" 3) "six"- zremrangebyscore zset from to: 删除指定序号
127.0.0.1:6379> zrange zset 0 -1 withscores 1) "one" 2) "1" 3) "five" 4) "5" 5) "six" 6) "6" 127.0.0.1:6379> zremrangebyscore zset 3 6 (integer) 2 127.0.0.1:6379> zrange zset 0 -1 withscores 1) "one" 2) "1"- zrank: 返回排序索引 (升序之后再找索引)
- zrevrank: 返回排序索引 (降序之后再找索引)
-
应用场景
- 对于 zset 数据类型,有序的集合,可以做范围查找,排行榜应用,取 TOP N 操作等。
hash
hash对象的键是一个字符串类型,值是一个键值对集合
-
编码
-
hash对象的编码可以是ziplist或者hashtable
- 当使用ziplist,也就是压缩列表作为底层实现时,新增的键值是保存到压缩列表的表尾。
- hashtable 编码的hash表对象底层使用字典数据结构,哈希对象中的每个键值对都使用一个字典键值对。Redis中的字典相当于Java里面的HashMap,内部实现也差不多类似,都是通过“数组+链表”的链地址法来解决哈希冲突的,这样的结构吸收了两种不同数据结构的优点。
-
编码转换
- 当同时满足下面两个条件使用ziplist编码,否则使用hashtable编码
- 列表保存元素个数小于512个
- 每个元素长度小于64字节
- 当同时满足下面两个条件使用ziplist编码,否则使用hashtable编码
-
-
hash是一个String类型的field和value之间的映射表
-
Hash特别适合存储对象
-
所存储的成员较少时数据存储为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht
-
Hash命令详解
-
hset/hget
- hset hashname hashkey hashvalue
- hget hashname hashkey
127.0.0.1:6379> hset user id 1 (integer) 1 127.0.0.1:6379> hset user name z3 (integer) 1 127.0.0.1:6379> hset user add shanxi (integer) 1 127.0.0.1:6379> hget user id "1" 127.0.0.1:6379> hget user name "z3" 127.0.0.1:6379> hget user add "shanxi" -
hmset/hmget
- hmset hashname hashkey1hashvalue1 hashkey2 hashvalue2 hashkey3 hashvalue3
- hget hashname hashkey1 hashkey2 hashkey3
127.0.0.1:6379> hmset user id 1 name z3 add shanxi OK 127.0.0.1:6379> hmget user id name add 1) "1" 2) "z3" 3) "shanxi" -
hsetnx/hgetnx
-
hincrby/hdecrby
127.0.0.1:6379> hincrby user2 id 3 (integer) 6 127.0.0.1:6379> hget user2 id "6"- hexist 判断是否存在key,不存在返回0
127.0.0.1:6379> hget user2 id "6"- hlen 返回hash集合里所有的键值数
127.0.0.1:6379> hmset user3 id 3 name w5 OK 127.0.0.1:6379> hlen user3 (integer) 2- hdel :删除指定的hash的key
- hkeys 返回hash里所有的字段
- hvals 返回hash里所有的value
- hgetall:返回hash集合里所有的key和value
127.0.0.1:6379> hgetall user3 1) "id" 2) "3" 3) "name" 4) "w3" 5) "add" 6) "beijing" -
-
优点
- 同类数据归类整合存储,方便数据管理,比如单个用户的所有商品都放在一个hash表里面。
- 相比string操作消耗内存cpu更小
-
缺点
- hash结构的存储消耗要高于单个字符串
- 过期功能不能使用在field上,只能用在key上
- redis集群架构不适合大规模使用
-
应用场景
- 对于 hash 数据类型,value 存放的是键值对,比如可以做单点登录存放用户信息。
- 存放商品信息,实现购物车
内存回收和内存共享
typedef struct redisObject{
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层数据结构的指针
void *ptr;
//引用计数
int refcount;
//记录最后一次被程序访问的时间
unsigned lru:22;
}robj
- 内存回收
因为c语言不具备自动内存回收功能,当将redisObject对象作为数据库的键或值而不是作为参数存储时其生命周期是非常长的,为了解决这个问题,Redis自己构建了一个内存回收机制,通过redisobject结构中的refcount实现.这个属性会随着对象的使用状态而不断变化。- 创建一个新对象,属性初始化为1
- 对象被一个新程序使用,属性refcount加1
- 对象不再被一个程序使用,属性refcount减1
- 当对象的引用计数值变为0时,对象所占用的内存就会被释放
- 内存共享
refcount属性除了能实现内存回收以外,还能实现内存共享- 将数据块的键的值指针指向一个现有值的对象
- 将被共享的值对象引用refcount加1
Redis的共享对象目前只支持整数值的字符串对象。之所以如此,实际上是对内存和CPU(时间)的平衡:共享对象虽然会降低内存消耗,但是判断两个对象是否相等却需要消耗额外的时间。对于整数值,判断操作复杂度为o(1),对于普通字符串,判断复杂度为o(n);而对于哈希,列表,集合和有序集合,判断的复杂度为o(n^2).虽然共享的对象只能是整数值的字符串对象,但是5种类型都可能使用共享对象。