邮件伪造
入门指南 (An Introductory Guide)
Although many are familiar with the incredible results produced by deepfakes, most people find it hard to understand how the deepfakes actually work. Hopefully, this article will demystify some of the math that goes into creating a deepfake.
尽管许多人熟悉Deepfake产生的令人难以置信的结果,但大多数人发现很难理解Deepfake的实际工作原理。 希望本文能使创建Deepfake的一些数学方法神秘化。
Deepfake generally refers to videos in which the face and/or voice of a person, usually a public figure, has been manipulated using artificial intelligence software in a way that makes the altered video look authentic. — Dictionary.com
Deepfake通常是指使用人工智能软件以某种方式使人(通常是公众人物)的脸部和/或声音被操纵过的视频,以使更改后的视频看起来真实。 — Dictionary.com
It turns that deepfake is a sort of umbrella term, with no definitive way to create. However, most deepfakes are created with a deep learning framework known as generative adversarial nets, or GANs, so that will be the main focus of this article.
事实证明,deepfake是一种笼统的术语,没有确定的创建方式。 但是,大多数Deepfake都是使用称为生成对抗网络(GAN)的深度学习框架创建的,因此这将是本文的重点。
什么是GAN? (What is a GAN?)
Generative adversarial nets — or GANs for short —are a deep learning model that was first proposed in a 2014 paper by Ian Goodfellow and his colleagues. The model operates by simultaneously training two neural networks in an adversarial game.
生成对抗网络 (简称GAN)是一种深度学习模型,由Ian Goodfellow及其同事在2014年的论文中首次提出。 该模型通过在对抗游戏中同时训练两个神经网络来运行。
Abstractly, we would have generative model G, that is trying to learn a distribution p_g which replicates p_data, the distribution of the data set, while a discriminative model D tries to determine whether or not a piece of data came from the data set or the generator. Although seeing this for the first time may be intimidating, that math becomes relatively straightforward when looking at an example.
抽象,我们必须生成模型G,即试图了解它复制P_DATA,该数据集的分布进行分布P_G,而判别模型d试图确定一个数据是否从数据集或来发电机。 尽管第一次看到这个可能会令人生畏,但是在看一个例子时,数学变得相对简单。
Classically, GANs are explained are explained using the analogy of producing counterfeit money. To set up the situation, there is an organization of counterfeiters who try to produce counterfeit money, while the police are trying to detect whether or not money is counterfeited. Here, our counterfeiters can be treated as the generative model G that produces fake money with the distribution p_g. A distribution is essentially a “map” of characteristics that describes the features of money. Basically, the counterfeiters are producing money with some set of characteristics described by the distribution p_g. Furthermore, the role of the police is the discriminate between real and counterfeited money, so they play the part of the discriminative model D. In practice, these models are often multi-layer perceptrons, but there is no need to specify the type of neural network when only discussing theory.
传统上,使用产生假币的类比解释GAN。 为了解决这种情况,有一个伪造者组织,他们试图生产伪造的钱,而警察则试图查明是否伪造了金钱。 在这里,我们的造假者可以被视为生成模型g的生成模型G ,该假模型的分布为p_g 。 分配实质上是描述货币特征的特征“图”。 伪造者基本上是在生产具有分布p_g描述的某些特征的货币 。 此外,警察的作用是区分真钱和假币,因此,他们扮演了区分模型D的角色。 实际上,这些模型通常是多层感知器 ,但是仅在讨论理论时就无需指定神经网络的类型。

Initially, the money produced by the counterfeiters might have many flaws, so the police can easily detect that the money is produced by the counterfeiters; in other words, the police know when money comes from the distribution p_g. As time progresses, both the police and counterfeiters become more proficient in their work. For the counterfeiters, this means that the money they produce will better resemble real money; mathematically, this is shown when the distribution of counterfeit money, p_g, approaches the distribution of real money, p_data. On the other hand, the police become more accurate at detecting whether or not money comes from p_data or p_g. However, the counterfeiters will eventually reach a point where the counterfeited money can pass for real money and fool the police. This occurs when the distributions p_g and p_data are the same; simply put, the features of the counterfeit money match those of real money. It turns out that this measure of “distance” can be calculated in many ways, each working in slightly different ways. With this knowledge in hand, we can set a goal for the counterfeiters: learn the distribution p_g, such that it equals the distribution of data p_data. Similarly, we set a goal for the police: maximize the accuracy of detecting counterfeit money.
最初,伪造者产生的金钱可能有很多缺陷,因此警察可以轻松地检测到伪造者产生的金钱; 换句话说,警察知道何时金钱来自分配p_g 。 随着时间的流逝,警察和造假者都变得更加精通他们的工作。 对于造假者而言,这意味着他们产生的货币将更好地类似于真实货币; 数学上,这是所示,当假币分布,P_G,接近的真金白银,P_DATA分布。 在另一方面,警方成为检测的钱是否来自P_DATA或P_G更准确。 但是,伪造者最终将达到使伪造货币可以用来赚取真钱并欺骗警察的地步。 当分布P_G和P_DATA是相同的这种情况发生时; 简而言之,假币的特征与真实货币的特征相匹配。 事实证明,这种“距离”度量可以通过多种方式计算,每种方式的工作方式略有不同。 有了这些知识在手,我们可以设置一个目标造假:学习分布P_G,使得它等于数据P_DATA的分布。 同样,我们为警察设定了一个目标:最大程度地提高发现假币的准确性。

Up until now, we have largely neglected the specifics of how these models actually operate, so we will begin with describing the generator G. Going back to the previous example with counterfeiting money, our generator needs to take in some input that specifies what kind of money is being created. This means that input corresponding to creating a one dollar bill will differ from the input corresponding to creating a ten dollar bill. For consistency, we will define this input using the variable z that comes from the distribution p_z. The distribution p_z gives a rough idea of what kinds of money can be counterfeited. Furthermore, the outputs of the generator, expressed as G(z), can be described with the distribution p_g. Shifting our focus to the discriminator, we begin by examining the role it plays. Namely, our discriminator should tell us whether or not some piece data is from our data set or the generator. It turns out that probabilities are perfectly suited for this! Specifically, when our discriminator takes in some input x, D(x) should return a number between 0 and 1 representing the probability that x is from the data set. To see why our discriminator does is allowed to return values between 0 and 1, we will examine the case where our input somewhat resembles something from the data set. Revisiting our previous example, say we had a US dollar with small scuff marks in the corner and another US dollar with a figure of Putin printed on it. Without a doubt, the second bill is much more suspicious compared to first, so it is easily classified as fake (discriminator returns 0). However, our first bill still has the chance of being genuine, and classifying it with a 0 would mean is looks just as bad as bill number two. Obviously, we are losing some information regarding bill one, and it might be best to classify it with a number like 0.5, where our discriminator has some doubts that is genuine but is not certain that it is a fake. Simply put, our discriminator returns a number that represents its confidence level that an input comes from the data set.
到现在为止,我们在很大程度上都忽略了这些模型实际运行方式的细节,因此我们将从描述生成器G开始。 回到前面关于伪造货币的示例,我们的生成器需要输入一些输入来指定要创建哪种货币。 这意味着对应于创建一美元钞票的输入将不同于对应于创建十美元钞票的输入。 为了保持一致性,我们将使用来自分布p_z的变量z定义此输入。 分布p_z给出了可以伪造哪种货币的粗略概念。 此外,可以用分布p_g描述发电机的输出,表示为G ( z )。 将重点转移到歧视者上,我们首先研究其所扮演的角色。 也就是说,我们的鉴别器应该告诉我们一些片段数据是否来自我们的数据集或生成器。 事实证明,概率完全适合于此! 具体来说,当我们的鉴别器接受某些输入x时 , D ( x )应该返回一个介于0和1之间的数字,表示x来自数据集的概率。 要了解为什么允许我们的鉴别器返回0到1之间的值,我们将研究输入与数据集中的情况有点相似的情况。 再看前面的例子,假设我们在角落里有一小划痕的美元,在上面印有普京的数字。 毫无疑问,第二张钞票比第一张钞票更具可疑性,因此很容易将其分类为伪造的(鉴别符返回0)。 但是,我们的第一张钞票仍然有可能是真实的,并且将其分类为0意味着看起来和第二张钞票一样糟糕。 显然,我们正在丢失一些有关法案一的信息,最好将其分类为0.5之类的数字,我们的判别器会怀疑是真实的,但不确定是假的。 简而言之,我们的鉴别器将返回一个数字,该数字表示其输入来自数据集的置信度。
推导误差函数 (Deriving an Error Function)
Now that we have a rough understanding of what our models G and D should be doing, we still need a way to evaluate their performances; this is where error functions come into play. Basically, an error function, E, tells us how poorly our model is performing given a its current set of parameters. For example, say we had a model that was being trained to recognize various objects. If we showed the model a bicycle, and the model sees a tricycle, the error function would return a relatively small error since the two are so similar. However, if the model saw the bicycle as a truck or school building, the error function would return a much larger number as there is little to no similarity in between these. In other words, error is low if the predictions of our model closely match the actual data, and error is large when the predictions do not match the actual data at all.
既然我们对G和D模型应该做的事情有了一个大概的了解,我们仍然需要一种评估它们性能的方法。 这就是错误功能发挥作用的地方。 基本上,误差函数E告诉我们,在给定其当前参数集的情况下,模型的执行效果如何。 例如,假设我们有一个正在接受训练以识别各种物体的模型。 如果我们向模型显示自行车,并且模型看到三轮车,则误差函数将返回相对较小的误差,因为两者是如此相似。 但是,如果模型将自行车视为卡车或学校建筑物,则误差函数将返回更大的数字,因为两者之间几乎没有相似性。 换句话说,如果我们模型的预测与实际数据紧密匹配,则误差较小;而当预测与实际数据完全不匹配时,误差较大。
Armed with this knowledge, we begin laying out some desired characteristics that our error function should have. First of all, the error function should return a large number when our discriminator misclassifies data, and a small number when data is classified correctly. In order to understand what this means, we begin by defining classifications. Essentially, a classification is a label for some piece of data. For a example, a red robin would be put under the classification of birds, while tuna would be put under the classification of fish. In our case, an input to our discriminator can come from two places, the data set or the generator. For convenience which we will see later on, we classify data that comes the generator by giving it a label of 0, while data that comes from the data set will be given the label 1. Using this, we can further elaborate on our error function. For example, say we have some piece of data, x, with the label 1. If our discriminator predicts that x is from the data set (D(x) returns a number close to 1), then our discriminator would have correctly predicted the classification of x and the error would be low. However, if our discriminator predicted that x was from the generator (D(x) returns a number close to 0), then our discriminator would have incorrectly classified our data and error would be high.
掌握了这些知识之后,我们便开始列出错误函数应具有的一些所需特征。 首先,当我们的鉴别器对数据进行错误分类时,错误函数应该返回一个大数字,而当数据正确分类时,错误函数应该返回一个小数字。 为了理解这意味着什么,我们首先定义分类 。 本质上,分类是某些数据的标签。 例如,将红知更鸟放在鸟的分类下,而金枪鱼则放在鱼的分类下。 在我们的例子中,鉴别器的输入可以来自两个地方,即数据集或生成器。 为了方便起见,我们将在后面看到,我们通过将生成器中的数据标记为0来对生成器中的数据进行分类,而将数据集中的数据标记为1。使用此标记,我们可以进一步详细说明错误函数。 例如,假设我们有一些数据x带有标签1。如果我们的鉴别器预测x来自数据集( D ( x )返回接近1的数字),那么我们的鉴别器将正确预测x的分类,误差很小。 但是,如果我们的鉴别器预测x来自生成器( D ( x )返回接近0的数字),那么我们的鉴别器将错误地对我们的数据进行分类,并且误差会很大。


As we look for an ideal function, we notice that the graph of y = log(x) on the interval [0,1] matches our specification after some manipulation.
当我们寻找理想函数时,我们注意到间隔[0,1]上的y = log( x )的图经过一些操作后符合我们的规范。

In particular, flipping the graph around the x-axis results results in the error function where our label is 1. Reflecting this new graph across the line y=0.5, then reveals the error function for when our label is 0. The equations for these are y = -log(x) and y = -log(1-x) respectively, and can be seen below.
特别是,将图形绕x轴翻转会导致我们的标签为1的误差函数。在y = 0.5线上反映此新图形,然后揭示标签为0时的误差函数。这些方程式分别为y = -log( x )和y = -log(1- x ),如下所示。


Putting these two functions together, we can create the following “piece-wise” function.
将这两个函数放在一起,我们可以创建以下“逐段”函数。

Unfortunately, this formula is a little cumbersome to write out, so want to find a way to reduce down to one line. We begin by giving our error function a proper name, like E. Additionally, we will also want to create a variable to represent our label, since writing out label is inefficient; we will call this new variable y. Here is where a little bit of genius comes into play. When we treat y not only as a label, but also as a number, we can actually reduce this formula into the following:
不幸的是,这个公式写起来有点麻烦,所以想找到一种减少到一行的方法。 我们首先给错误函数起一个适当的名称,例如E。 另外,由于写标签效率低下,我们还希望创建一个变量来表示标签。 我们将这个新变量称为y 。 这是一些天才发挥作用的地方。 当我们不仅将y视为标签,而且将其视为数字时,我们实际上可以将该公式简化为以下形式:

Notice, that when y = 0 (label is 0), the (1 - y) coefficient turns into 1, while the term y(log(D(x)) turns into 0. When y = 1 (label is 1), something similar occurs. The first term reduces to 0 leaving us with -log(D(x)). It turns out that these results exactly equal our “piece-wise” function. On an unrelated note, this error function is also known as binary cross entropy.
请注意,当y = 0(标号为0)时,(1- y )系数变为1,而项y (log( D ( x ( x )))变为0。当y = 1(标号为1)时,类似的情况发生了,第一项减少到0,剩下-log( D ( x ( x ))。结果证明,这些结果与我们的“逐段”函数完全相同。在一个不相关的注释中,该误差函数也称为二元交叉熵 。
One quick thing to note is that the paper which introduces GANs uses the error function -E instead. Therefore, in order to stay consistent with the original paper, we will redefine our error function to -E.
值得注意的一件事是,介绍GAN的论文使用了误差函数-E 。 因此,为了与原始论文保持一致,我们将误差函数重新定义为-E 。

This change in the formula means an incorrect prediction (i.e. — y = 0 but D outputs 1) will result in an error of -∞ as opposed to ∞.
公式中的这一变化意味着错误的预测(即y = 0但D输出1)将导致-∞的误差,而不是∞的误差。
应用误差函数 (Applying the Error Function)
After deriving a suitable error function for our GAN, the next reasonable step is to apply it to the current setup.
在为我们的GAN导出合适的误差函数之后,下一步是将其应用于当前设置。
The first step in this process is to set some goals for our models. Essentially, our discriminator, D, should aim to classify all of its inputs correctly, while the generator, G, should try to trick the discriminator by making it misclassify as much data as possible. With these two goals in mind, we now begin to analyze the behavior of our error function. Right away, it is easy to see that the error function attains a maximum value of 0, which only occurs when the discriminator perfectly classifies everything with 100% confidence (this is especially easy to see using the definition of our error function). Additionally, our error function attains a minimum at -∞, which only occurs when the discriminator is 100% confident in its predictions, but is always wrong (this may occur if D(x) is 0 but y = 1).
此过程的第一步是为我们的模型设定一些目标。 本质上,我们的鉴别器D应该旨在正确地对其所有输入进行分类,而生成器G则应尝试通过使分类器对尽可能多的数据进行错误分类来欺骗鉴别器。 考虑到这两个目标,我们现在开始分析误差函数的行为。 马上就可以看出,误差函数的最大值为0,只有当鉴别器以100%的置信度对所有事物进行完美分类时,才会出现该最大值(使用误差函数的定义尤其容易看出这一点)。 此外,我们的误差函数在-∞处达到最小值,仅当鉴别器对其预测具有100%的置信度时才会发生,但始终是错误的(如果D ( x )为0但y = 1可能会发生)。
Combining these two insights, we are able to mathematically formulate a competition between the two models G and D. Namely, G is attempting to minimize our error function (G wants the error to be -∞), while D is trying to maximize it (D wants to error to be 0). This sort of adversarial competition is also known as a mini-max game, where the models G and D are competing against each other like players. As a result, we find it more intuitive to call E a value function, V(G,D), where G’s goal is the minimize the value of V(G,D), while D’s goal is to maximize the value function. This can be described with the following expression:
结合这两种见解,我们可以在数学上公式化两个模型G和D之间的竞争。 即, G试图使误差函数最小化( G希望误差为-∞),而D试图使误差函数最大化( D希望误差为0)。 这种对抗性竞争也称为迷你-最大 游戏 ,其中模型G和D像玩家一样相互竞争。 结果,我们发现将E称为值函数 V ( G , D )更直观,其中G的目标是最小化V ( G , D )的值,而D的目标是最大化V ( G , D )的值。值函数。 这可以用以下表达式来描述:
However, the above formula has a critical flaw: it only takes in a single input at a time. In order to improve the utility of this function, it would be best for it to calculate the error over all of our data (this includes both the data set and everything generated by the generator). This is where it becomes more useful to find the aggregate or total error that the models have over the entire data set. In fact, we can find this total error by just summing up the error for each individual input. To see where this will lead us, we must examine now examine the cases where an input to our discriminator comes from the data set and the cases where an input comes from the generator.
但是,上面的公式有一个严重的缺陷:一次只能输入一个输入。 为了提高此功能的实用性,最好对所有数据(包括数据集和生成器生成的所有数据)计算误差。 在这里,找到模型在整个数据集上的汇总误差或总误差变得更加有用。 实际上,我们可以通过对每个单独输入的误差求和来找到总误差。 为了了解这将导致我们什么,我们现在必须检查判别器输入来自数据集的情况以及输入来自生成器的情况。
When an input to the discriminator comes from the data set, y will be equal to 1. This means that the value function for that single instance of data becomes log(D(x)). Consequently, if we were to find the error for every piece of data from our data set, the total error for these data entries would be the number of entries in the data multiplied with the error for a single entry in the data set. Of course, this is assuming that the error is roughly the same for each entry in the data set. Additionally, we can mathematically describe the number data entries in our data set using _(x ∈ p_data), where represent expected value. Essentially, this expression returns the expected number of entries that are in the distribution p_data, which is the distribution describing our data set.
当鉴别符的输入来自数据集时, y将等于1。这意味着该单个数据实例的值函数变为log( D ( x ))。 因此,如果我们要从数据集中找到每个数据的错误,则这些数据条目的总错误将是数据中条目的数目乘以数据集中单个条目的错误。 当然,这是假设数据集中每个条目的错误大致相同。 此外,我们可以用数学描述我们的数据集采用_(X∈P_DATA)数的数据项,其中表示期望值。 本质上,该表达式返回分布p_data中的预期条目数,分布p_data是描述我们的数据集的分布。
Similarly, when an input to the discriminator comes from the generator, y will be equal to 0, so the value function reduces to log(1-D(G(z))). As a result, finding the total error for everything produced by the generator is equal to the number of items produced by the generator multiplied by the error for a single item produced by the generator (this assumes the error is roughly the same for each item). Once again, we represent the number of items produced by the generator with _(z ∈ p_z). The reason we use z instead is because we are trying to find error when the input to the discriminator comes from the generator, and items produced by the generator are defined by the input z. Essentially, _(z ∈ p_z) gives us a good idea of the number of items produced by the generator.
同样,当鉴别器的输入来自生成器时, y将等于0,因此值函数减小为log(1- D ( G ( z )))。 结果,找到生成器产生的所有事物的总误差等于生成器产生的事物的数量乘以生成器产生的单个事物的误差(假定每个物件的误差大致相同) 。 再次,我们表示由所述发电机与_(Z∈p_z)生产的物品的数量。 我们改用z的原因是因为当鉴别符的输入来自生成器,并且生成器生成的项由输入z定义时,我们试图查找错误。 从本质上讲,_(Z∈p_z)为我们提供了发电机所产生的项目数的一个不错的主意。
Putting our last two insights together, we can achieve a suitable value function:
综合我们的最后两个见解,我们可以实现合适的价值函数:

训练GAN (Training the GAN)
Recall our end goal for the training: the generator must be able to fool the discriminator. This means that the generator’s distribution of outputs, p_g, must equal the distribution of the data set, p_data. However, this we may not want the p_g to exactly equal p_data. To see why this is, think about the case where there are outliers in the data set. If we trained our generator to produce outputs with the exact distribution p_data, our generator will inevitably produce some faulty outputs due to these outliers. This is why we want our distributions to approximately equal other.
回顾我们训练的最终目标:生成器必须能够欺骗鉴别器。 这意味着,输出发电机的分布,P_G,必须等于数据集的分布,P_DATA。 然而,这一点,我们可能不希望P_G恰好等于P_DATA。 要了解为什么会出现这种情况,请考虑数据集中存在异常值的情况。 如果我们训练生成器以产生具有精确分布p_data的输出,由于这些异常值,我们的生成器将不可避免地产生一些错误的输出。 这就是为什么我们希望我们的分布近似相等。

分布之间的距离 (Distances between distributions)
Now that we know what we are aiming for in our training procedure, we still lack a way to rigorously define what it means for two distributions to approximate each other. This is math comes up with a notion of distance between distributions. Essentially, the distance between distributions gives us a measure of how similar two distribution are to each other. This is easily visualized in the figure below.
既然我们知道了训练过程中要达到的目标,我们仍然缺乏一种方法来严格定义两种分布相互近似的含义。 这是数学中分布之间的距离的概念。 本质上,分布之间的距离使我们可以衡量两个分布之间的相似程度。 在下图中很容易看到这一点。
It turns out that, depending on how our distance function is defined, the results of training will vary. This will be covered in further reading.
事实证明,根据我们的距离函数的定义方式,训练的结果会有所不同。 这将在进一步的阅读中介绍。
草绘算法 (Sketching the Algorithm)
With this rough understanding of distances, we now have sufficient knowledge to build the framework for an algorithm that trains these models (it turns out that different ways of defining distance will lead to different results, this is seen in the further reading). At its core, our training algorithm will rely on stochastic gradient descent to update the model parameters (gradient descent will not be covered in this article as there many other resources covering the topic). However, training a GAN is unique in that the algorithm must alternate between the models G and D. This is because if all the focus is put on training the discriminator, D will become too good at prevent our generator from learning. Additionally, if we only focus on training the generator, D will be unable to learn properly and also provide useless feedback to the generator. Consequently, our algorithm will continue to repeat the following cycle until our end goal is met:
通过对距离的这种粗略了解,我们现在已经拥有足够的知识来构建用于训练这些模型的算法的框架(事实证明,定义距离的不同方法将导致不同的结果,这在进一步的阅读中将会看到)。 从根本上讲,我们的训练算法将依赖于随机梯度下降来更新模型参数(本文将不涉及梯度下降,因为还有许多其他资源涉及该主题)。 但是,训练GAN的独特之处在于算法必须在模型G和D之间交替。 这是因为,如果将所有精力都放在训练判别器上, D就会变得太擅长阻止我们的生成器学习。 此外,如果我们仅专注于训练生成器,则D将无法正确学习,也无法向生成器提供无用的反馈。 因此,我们的算法将继续重复以下循环,直到达到最终目标为止:
Update the discriminator’s parameters k times (k is an arbitrary constant)
更新鉴别器的参数k次( k是任意常数)
- Update the generator’s parameters one time 一次更新发生器的参数
Unfortunately, at the beginning of our training, the gradient of our value function may not provide a large enough gradient; this prevents G from learning effectively. Notice that changes to G only affect the term log(1-D(G(z))), so this becomes what G wants to minimize. Plotting this out, we see minimizing this expression is equal to maximizing the expression log(D(G(z))). Training our model in this way is much more efficient as the gradients it provides are larger in the early stages of learning.
不幸的是,在我们开始训练时,我们的价值函数的梯度可能无法提供足够大的梯度。 这会阻止G有效学习。 请注意,对G的更改仅影响项log(1- D ( G ( z ))),因此这成为G想要最小化的项。 对此进行规划,我们看到最小化此表达式等于最大化表达式log( D ( G ( z ())))。 以这种方式训练我们的模型效率更高,因为它在学习的早期阶段提供的梯度更大。
Eventually, this method of training is guaranteed to converge at the optimal discriminator, denoted D*. The proof that this optimal discriminator exists will be shown in further reading.
最终,保证了这种训练方法收敛于最佳区分符,表示为D *。 在进一步的阅读中将显示存在这种最佳鉴别器的证据。
进一步阅读 (Further Reading)
距离 (Distances)
Although distance is easy enough to eyeball, we need a concrete formula if we are to incorporate distance into our training process. As a result, we must find a suitable distance function.
尽管距离很容易使人眼球,但是如果要将距离纳入训练过程中,我们需要一个具体的公式。 结果,我们必须找到合适的距离函数。
We begin our search with Kullback-Leibler divergence and Jensen-Shannon divergence, the same place where Goodfellow and his colleages started.
我们从Kullback-Leibler分歧和Jensen-Shannon分歧开始搜索,这是Goodfellow及其同事开始的地方。
Kullback-Leibler分歧(KL分歧) (Kullback-Leibler Divergence (KL Divergence))
This article will only aim to give a general grasp on what KL divergence accomplishes. To start off, it is important to note that KL divergence is not a distance metric, because it is asymmetrical and does not satisfy the triangle inequality. This means that, given two probability distributions P and Q, the KL divergence from P to Q is different than the KL divergence from Q to P. Below, we see the the mathematical formula that gives the KL divergence from the distribution P to Q.
本文仅旨在大致了解KL差异实现的内容。 首先,重要的是要注意,KL散度不是距离 度量 ,因为它是不对称的并且不满足三角形不等式。 这意味着,给定两个概率分布P和Q ,从P到Q的KL发散不同于从Q到P的KL发散。 在下面,我们看到了给出从分布P到Q的KL发散的数学公式。

Notice that there are two ways to calculate KL divergence. The first way is used when P and Q are discrete distributions. The second formula is used when P and Q are continuous distributions, while p(x) and q(x) are the probability densities of P and Q respectively. With these basic definitions, we can further “classify” KL divergence into two categories: forward KL divergence and reverse KL divergence. For two distributions P and Q, forward KL is defined as KL(P||Q) while reverse KL is defined as KL(Q||P).
请注意,有两种方法可以计算KL散度。 当P和Q是离散分布时,使用第一种方法。 当P和Q是连续分布时,使用第二个公式,而p ( x )和q ( x )分别是P和Q的概率密度。 利用这些基本定义,我们可以将KL散度进一步“分类”为两类: 正向KL散度和反向KL散度 。 对于两个分布P和Q ,正向KL定义为KL( P || Q ),反向KL定义为KL( Q || P )。
As a result, when we are trying the minimize the distance between p_g and p_data in training our GAN, we are essentially minimizing the KL divergence between the distributions; mathematically, this is expressed as min(KL(p_g||p_data)).
其结果是,当我们试图最小化在训练我们的GAN,我们基本上最小化分布之间的KL发散P_G和P_DATA之间的距离; 在数学上,这表示为min(KL( p_g || p_data ))。
Now, we can begin to analyze what happens when we use forward and reverse KL to train our GAN. When using forward KL, we aim to minimize KL(p_data||p_g), so the distribution p_g will essentially spread out across p_data in order to minimize KL divergence. This can be seen below where p_g is plotted in red and p_data is plotted in blue.
现在,我们可以开始分析当使用正向和反向KL训练GAN时会发生什么。 当使用前KL,我们的目标是尽量减少KL(P_DATA || P_G),所以分配P_G将主要以尽量减少KL散铺开P_DATA。 这可以看到下面其中P_G以红色绘制并P_DATA以蓝色绘制。

When p_g is initialized as seen in the left, we that there are certain places along the plot where p_g is near 0 while p_data is not. Plugging these into our formula for forward KL divergence, we see that there will be terms where log(p_data(x) / p_g(x)) will approach infinity. In order to prevent this from occurring, p_g is essentially stretched out such that forward KL divergence no longer blows up. This is known as mean-seeking or zero-avoidance behavior.
当在左视图中P_G被初始化,我们有一起其中P_G接近0,而P_DATA不是剧情某些地方。 这些堵到我们向前KL散度公式,我们看到会有方面,其中log(P_DATA(X)/ P_G(X))将接近无穷大。 为了防止这种情况发生, p_g基本上被拉伸,使得向前的KL散度不再爆炸。 这被称为均值搜寻或零回避行为。
Applying reverse KL, our goal becomes minimizing the KL(p_g||p_data). Here, p_g will end up covering a single mode if the distribution p_data. This can be visualized below:
应用反向KL,我们的目标是使KL( p_g || p_data )最小。 在这里,P_G最终将覆盖如果分发P_DATA单一模式。 可以在下面看到:

In order to minimize the reverse KL divergence, we want to maximize the number of terms in the summation that go to 0. This means that we want p_g to have many points where p_g is near 0 but p_data is not (places like this have a KL divergence of 0 — this can be verified by plugging numbers into our formula). Additionally, the mode under which p_g lies will also have a KL divergence near 0. This is because the expression log(p_g / p_data) will evaluate near log(1), which reduces to 0. This sort of “shrinking” behavior is known as mode-seeking behavior.
为了尽量减少反向KL分歧,我们希望以最大化总和即变为0,这意味着我们要P_G有多少分,其中P_G接近0,但P_DATA不是项数(这样的地方有一个KL散度为0,这可以通过在公式中插入数字来验证)。 此外, p_g所处的模式也将使 KL散度接近0。这是因为表达式log( p_g / p_data )的计算结果接近log(1),减小到0。这种“收缩”行为是已知的作为寻求模式的行为。
Unfortunately, when we look at the case where we have two discrete distributions that do not overlap, the KL divergence will blow up to infinity. This is undesirable and will lead to issues in training. This is where Jensen-Shannon Divergence comes into play.
不幸的是,当我们看到有两个不重叠的离散分布的情况时,KL散度将爆炸到无穷大。 这是不希望的,并且会导致培训问题。 这就是詹森-香农分歧(Jensen-Shannon Divergence)发挥作用的地方。
詹森·香农散度(JSD) (Jensen-Shannon Divergence (JSD))
Jensen-Shannon Divergence or JSD is an alternative method of measuring distance. It uses elements of KL divergence but can combat the case where the distributions do not overlap. The formula for calculating JSD is shown below:
Jensen-Shannon发散或JSD是另一种测量距离的方法。 它使用KL散度的元素,但可以解决分布不重叠的情况。 JSD的计算公式如下所示:

It turns out that when our distributions do not overlap, the JSD actually converges to log(2). This means that we now have a way to effectively measure the distance between distribution without having to worry about divergence going to infinity; consequently, JSD is superior to KL divergence.
事实证明,当我们的分布不重叠时,JSD实际上收敛到log(2)。 这意味着我们现在有一种方法可以有效地测量分布之间的距离,而不必担心发散会达到无穷大。 因此,JSD优于KL分歧。
this video gives a deeper dive into KL divergence and JSD (video credits: Ahlad Kumar) 该视频深入探讨了KL分歧和JSD(视频来源:Ahlad Kumar)This concludes an introductory glimpse into distance functions and how they can be used to train GANs. However, even JSD is not without its flaws. As a result, researchers may choose to use a variation on GAN, such as the Wasserstein GAN (this uses Wasserstein distance) or Info GAN.
到此,我们将对距离函数以及如何将其用于训练GAN进行简要介绍。 但是,即使JSD也并非没有缺陷。 结果,研究人员可能选择在GAN上使用变体,例如Wasserstein GAN (使用Wasserstein距离)或Info GAN 。
最优鉴别器存在的证明 (Proof that the Optimal Discriminator Exists)
Once our algorithm has been sketched out, we still need to prove that it accomplishes what it sets out to do. Namely, we want to prove that our algorithm produces the optimal discriminator, denoted D*.
勾勒出我们的算法后,我们仍然需要证明它能够完成其设定的工作。 即,我们想证明我们的算法产生了最优的鉴别器,记为D *。
I will begin by making a proposition: when G is fixed, the optimal discriminator D is given by the following.
我将提出一个命题:当G固定时,最优判别器D由下式给出。
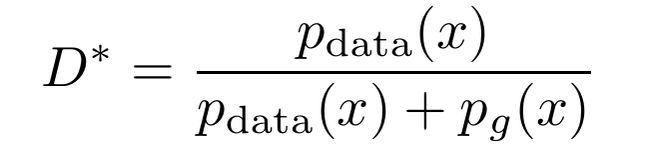
Proof: The goal of the generator is to maximize the value function V(G,D). Notice that the expected value for data set can instead be written as an integral over the distribution of data; similar rules apply for the generator. This leaves us with:
证明:生成器的目标是使值函数V ( G , D )最大化。 注意,数据集的期望值可以写为数据分布上的整数。 类似的规则也适用于发电机。 这给我们留下了:

From here, we can then make a “change of a variable.” Namely, we replace G(z) with x and change our distribution from p_z to p_g. This is essentially rewriting the second term in terms of the output that is produced by G.
然后,我们可以从此处进行“变量的更改”。 即,我们用x替换G ( z )并将分布从p_z更改为p_g 。 这实际上是根据G产生的输出来重写第二项。

Now, maximizing the V becomes a matter of maximizing the integrand. From basic calculus, we know that the maximum value of the expression a⋅log(x)+b⋅log(1-x) will attain its maximum on the interval [0,1] at (a)/(a+b). Plugging this into our value function, we get that the discriminator which maximizes the integrand will be what we proposed above. This concludes our proof.
现在,最大化V成为最大化被积数的问题。 从基本的演算,我们知道,表达的 ⋅log(X)+b⋅log(1-X)的最大值将达到其最大值在区间[0,1]的(A)/(A + B) 。 将其插入到我们的值函数中,我们可以得出使被积数最大化的鉴别器将是我们上面提出的。 这证明了我们的证明。
结论 (Conclusion)
In summary, this article aimed to cover the math that goes into creating deepfakes, particularly GANs. This introductory look into GANs should provide you with enough information to get a general understanding of how a deepfake might have been created using artificial intelligence. All images except the one in the title where created by the author and equations were rendered using LaTex in TexStudio. If you have any questions or just want to talk, feel free to reach out to me at [email protected].
总而言之,本文旨在介绍创建深层伪造(尤其是GAN)时所采用的数学方法。 对GAN的介绍性介绍应为您提供足够的信息,以使您对使用人工智能如何创建Deepfake产生大致了解。 除标题中由作者和方程式创建的图像外,所有图像均使用TexStudio中的LaTex渲染。 如果您有任何疑问或想聊天,请随时通过[email protected]与我联系 。
翻译自: https://towardsdatascience.com/the-math-behind-deepfakes-b9ef8621541f
邮件伪造