知识图谱的学习网站
知识图谱
知识图谱,简单理解就是一个知识库,我们能利用这个知识库,给定你要查询的内容,然后到知识库中去进行关联分析和推理,试图让机器了解你的意图,反馈和你查询相关内容的更多关联信息。举一个简单例子,我们用所有的菜谱构建知识图谱,然后问“夏天西红柿怎么做汤”,知识图谱会查询“夏天”、“‘西红柿”和“汤”在所有菜谱中的直接和间接关系,进而推荐给你几个最匹配的菜谱。就我的总结,知识图谱有两大类主要应用:a) 搜索和问答类型的场景;b)自然语言理解类的场景。
知识图谱,是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是『实体-关系-实体』三元组,以及实体及其相关属性-值对,实体之间通过关系相互联结,构成网状的知识结构。
知识图谱给一个这样的定义:“知识图谱本质上是语义网络(Semantic Network)的知识库”。但这有点抽象,所以换个角度,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图(Multi-relational Graph)
大多数知识图谱用RDF(Resource Description Framework)资源描述框架表示,RDF表征了实体和实体的关系,这种关系有两种:一种是属性关系,即一个实体是另一个实体的属性;另一种是外部关系,表明两个实体之间存在外部关联。
其本质是一个数据模型(Data Model)。它提供了一个统一的标准,用于描述实体/资源。简单来说,就是表示事物的一种方法和手段。

RDF形式上表示为SPO(Subject Predicate Object)三元组,所以实体通过关系链接成无向的网络。例如:
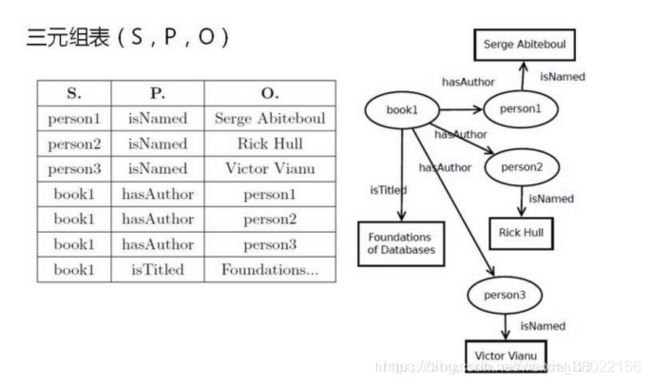
在各种辅助信息中,知识图谱作为一种新兴类型的辅助信息近几年逐渐引起了研究人员的关注。知识图谱(knowledge graph)是一种语义网络,其结点(node)代表实体(entity)或者概念(concept),边(edge)代表实体/概念之间的各种语义关系(relation)。一个知识图谱由若干个三元组(h、r、t)组成,其中h和t代表一条关系的头结点和尾节点,r代表关系。实体-关系-实体或者实体-属性-属性。
知识图谱有自顶向下和自底向上2种构建方式。采用自底向上的方式构建知识图谱的过程是一个迭代更新的过程,每一轮更新包括3个步骤:
- 信息抽取,即从各种类型的数据源中提取出实体(概念)、属性以及实体捡的相互关系,在此基础上形成本体化的知识表达
- 知识融合,在获得新知识后,需要对其进行整合,以消除矛盾和歧义,比如某些实体可能有多种表达,某个特定称谓也许对应于多个不同的实体等
- 知识加工,对于经过融合的新知识,需要经过质量评估之后(部分需要人工参与甄别),才能将合格的部分加入到知识库中,以确保知识库的质量,新增数据之后,可以进行知识推理、拓展现有知识、得到新知识。
数据源主要来自两种渠道:一种是业务本身的数据,这部分数据通常包含在公司内的数据库表并以结构化的方式存储;另一种是网络上公开、抓取的数据,这些数据通常是以网页的形式存在所以是非结构化的数据。
知识图谱主要有两种存储方式:一种是基于RDF的存储;另一种是基于图数据库的存储。

一个完整的知识图谱的构建包含以下几个步骤:1. 定义具体的业务问题 2. 数据的收集 & 预处理 3. 知识图谱的设计 4. 把数据存入知识图谱 5. 上层应用的开发,以及系统的评估。
知识领域示意图
这里我们主要从知识图谱的生命周期作为切入点,讲讲在其形成和使用过程中用到的原理和方法。
①知识体系构建。根据分类,可以把知识图谱分为通用型和领域型。无论是什么类型的知识图谱都需要对其服务的领域进行知识建模。也就是说,采用什么样的方式来表达知识。
②知识融合。一个知识库可以和其他知识库进行融合。在不同领域知识图库进行融合时,会发现来自不同领域,不同语言,甚至不同结构的知识需要做“补充,更新和去重的操作”。
这就是知识融合,一般分为:知识体系融合和实例融合。这部分的操作也可以在构建知识体系的时候统筹考虑。
③知识获取。知识获取的目的是从海量的信息(文本)中抽取知识。本文中提到的“获取信息”多为文本信息,因此这里的“获取信息”也是从文本中获取信息的过程。
获取信息结构上划分为三类,分别是结构化信息,半结构化信息和非结构化信息。
从获取信息内容上又分为,实体识别,实体消歧,关系抽取和事件抽取。知识存储在完成了知识抽取和融合之后,就需要将知识存储下来了。
有 RDF(Resource Description Framework,资源描述框架)格式和图数据库两种方式。
因为图数据库对于查询友好,因此被广泛使用,例如:Neo4j。
④知识推理。识别并抽取知识以及存储知识以后,我们会试图挖掘实体(知识)之间隐含的语义关系。
这个过程就是知识推理。例如:已知 A 是 B 的儿子,又知道 B 是 C 的儿子。那么可以推理出 A 是 C 的孙子。
⑤知识应用。识别,抽取,存储和推理的最终目的还是为了应用。知识图谱在搜索,问答,推荐,决策方面被广泛应用。
知识库推理可以粗略地分为基于符号的推理和基于统计的推理。在人工智能的研究中,基于符号的推理一般是基于经典逻辑(一阶谓词逻辑或者命题逻辑)或者经典逻辑的变异(比如说缺省逻辑)。基于符号的推理可以从一个已有的知识图谱,利用规则,推理出新的实体间关系,还可以对知识图谱进行逻辑的冲突检测。基于统计的方法一般指关系机器学习方法,通过统计规律从知识图谱中学习到新的实体间关系。
在知识图谱构建过程中,还存在很多关系补全问题。虽然一个普通的知识图谱可能存在数百万的实体和数亿的关系事实,但相距补全还差很远。知识图谱的补全是通过现有知识图谱来预测实体之间的关系,是对关系抽取的重要补充。
因此我们尝试用TransR来分别将实体和关系投影到不同的空间中,在实体空间和关系空间构建实体和关系嵌入。对于每个元组(h,r,t),首先将实体空间中的实体通过Mr向关系r投影得到hr和tr,然后是hr+r ≈tr。特定的关系投影能够使得两个实体在这个关系下真实地靠近彼此,使得不具有此关系的实体彼此远离。

知识图谱的体系分成4个过程:数据采集、知识抽取、知识链接和融合、知识的应用。
首先说数据采集,构建知识图谱是以大量的数据为基础的,需要进行大规模的数据采集,采集的数据来源一般是:网络上的公开数据、学术领域的已整理的开放数据、商业领域的共享和合作数据,这些数据可能是结构化的、半结构化的或者非结构化的,数据采集器要适应不同类型的数据。
知识抽取是对数据进行粗加工,将数据提取成实体-关系三元组,根据数据所在的问题领域,抽取方法分成开放支持抽取和专有领域知识抽取。
知识链接和融合,由于表征知识的实体-关系三元组抽取自不同来源的数据,可能不同的实体可以进一步融合成新的实体,实现在抽象层面的融合;根据融合之后的新实体,三元组集合可以进一步学习和推理,将表达相同或相似含义的不同关系合并成相同关系,检测相同实体对之间的关系冲突等。
知识图谱构建完成之后,形成了一个无向图网络,可以运用一些图论方法进行网络关联分析,将其用于文档、检索以及智能决策等领域。例如,阿里的知识图谱以商品、标准产品、 标准品牌、 标准条码、标准分类为核心, 利用实体识别、实体链指和语义分析技术,整合关联了例如舆情、百科、国家行业标准等9大类一级本体,包含了百亿级别的三元组,形成了巨大的知识网,然后将商品知识图谱广泛地应用于搜索、前端导购、平台治理、智能问答、品牌商运营等核心、创新业务。
知识图谱要经历:数据收集、信息抽取、链接和融合数据、数据可视化以及分析等过程。
数据集可以帮助我们建立一个知识图谱的初始版本,即从里面获得初始的知识表示:SPO三元组,然后根据我们收集的真实业务数据再进行知识抽取和知识推理。构建知识图谱的前提是收集数据,收集的数据越全面,则可供提取的知识表示越丰富,知识图谱的用处越大。
收集数据之后需要对数据进行处理,这里面最有价值的首先是文本数据,因此要用到自然语言处理,基本的过程是:语言分词、词性标注、命名实体识别、句法分析,更高级写的应用还包括语义依存分析。对于构建知识库而言,自然语言处理的目的是获取命名实体,再根据命名实体和句法分析抽取知识三元组SPO。
以上全为链接,如果需要可自行查找。
https://www.jiqizhixin.com/articles/2018-06-06-5
https://www.zhihu.com/question/345256389/answer/820820329
https://www.cnblogs.com/niuxichuan/p/9317711.html
https://www.jianshu.com/p/0a79ccd2ef8d
https://www.jianshu.com/p/2e3cade31098
https://www.cnblogs.com/small-k/p/10189165.html
https://www.jiqizhixin.com/articles/2018-06-20-4
https://baijiahao.baidu.com/s?id=1655209325546882849&wfr=spider&for=pc
https://www.jianshu.com/p/2a38bdcc4e3f
https://zhuanlan.zhihu.com/p/71128505
数据集:
http://www.openkg.cn/dataset?sort=score+desc%2C+metadata_modified+desc&groups=education&q=&_groups_limit=0
论文:
http://blog.openkg.cn/
我们整理了2005年-2019年ACL、COLING、EMNLP等顶级会议上知识图谱领域的80篇经典论文:
综述类(3篇)、知识表示(10篇)、命名实体识别(19篇)、实体消歧(12篇)、关系抽取(10篇)、事件抽取(8篇)、问答系统(17篇)。
可以添加深蓝学院-子书(微信:shenlan-zishu),备注“简书”,直接领取论文集。