算法笔记(一)——KMP算法
目录
暴力匹配(BF)算法
基本概念
分析BF算法
代码实现
牛刀小试
BF算法的时间复杂度
KMP算法
基本概念
分析KMP算法
引出next数组
代码实现
关键代码讲解
牛刀小试
KMP算法的时间复杂度
暴力匹配(BF)算法
基本概念
BF算法,即暴力(Brute Force)算法,是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符;若不相等,则比较S的第二个字符T的第一个字符,依次比较下去,直到得出最后的匹配结果。BF算法是一种蛮力算法。
分析BF算法
光看定义晦涩难懂,接下来我将举例子与大家一起学习:
假定我们给出字符串"ababcabcdabcde"做为主串,然后给出子串"abcd",现在我们需要查找子串是否在主串中出现,出现返回主串中第一个匹配的下标,失败返回-1.

对于这个问题我们很容易想到:从左到右依次匹配,如果字符相等,都向后移一位,如不相等, 子串从0下标重新开始,主串向右移动一位(假设原来从0下标开始,下次从1下标开始)
我们可以这样初始化:

根据我们的想法,之后我们就需要比较i指针和j指针指向的数字是否一致,如果一致都向后移动,如果不一致,如下图:
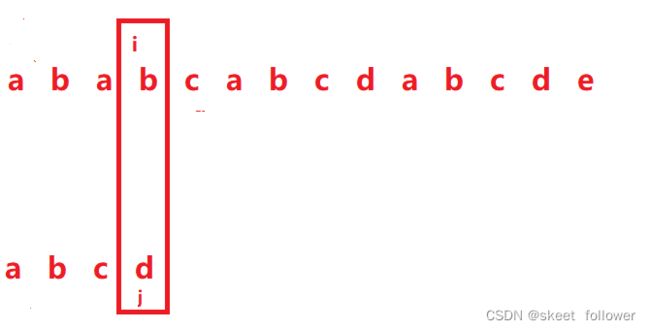
b和d不相等,那就把i指针回退到刚刚指针的下一个位置(刚刚指针是从0下标开始的),j指针退回到0下标重新开始。
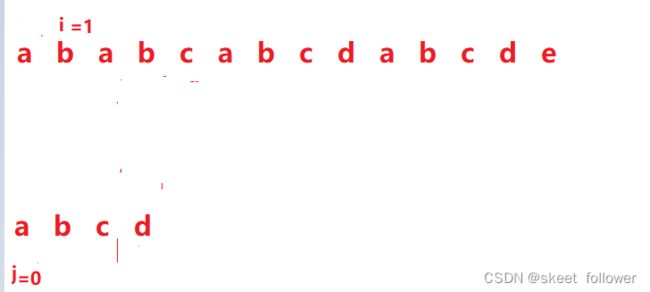
代码实现
根据以上的分析,下面我们开始写代码:
C代码:
#include
#include
#include
int BF(char* str1, char* str2)
{
assert(str1 != NULL && str2 != NULL);
int len1 = strlen(str1);//主串的长度
int len2 = strlen(str2);//子串的长度
int i = 0;//主串的起始位置
int j = 0;//子串的起始位置
while (i < len1 && j < len2)
{
if (str1[i] == str2[j])
{
i++;//相等i和j都向后移动一位
j++;
}
else {//不相等
i = i - j + 1;//i回退
j = 0;//j回到0位置
}
}
if (j >= len2) {//子串遍历玩了说明已经找到与其匹配的子串
return i - j;
}
else {
return -1;
}
}
int main()
{
printf("%d\n", BF("ababcabcdabcde", "abcd"));//测试,为了验证代码是否正确尽量多举几个例子
printf("%d\n", BF("ababcabcdabcde", "abcde"));
return 0;
}
java代码:
public class Test {
public static int BF(String str,String sub) {
if(str == null || sub == null) return -1;
int strLen = str.length();
int subLen = sub.length();
int i = 0;
int j = 0;
while (i < strLen && j < subLen) {
if(str.charAt(i) == sub.charAt(j)) {
i++;
j++;
}else {
i = i-j+1;
j = 0;
}
} i
f(j >= subLen) {
return i-j;
} r
eturn -1;
}
public static void main(String[] args) {
System.out.println(BF("ababcabcdabcde","abcd"));
System.out.println(BF("ababcabcdabcde","abcde"));
}
}牛刀小试
通过上面的学习,对BF算法有了初步的认识,为了更深刻的了解和运用,下面和大家一起完成以下试题:
试题在这里>>实现strStr()
感兴趣的伙伴可以去做试试,下一章我们进行共同探讨;
BF算法的时间复杂度
最好的情况就是从第一次开始就匹配成功时间复杂度为O(1);

最坏的情况就是每次都匹配到最后一个才发现与主串不相同,比如"aaaaab",子串”aab"




看上图,除了最后一次,其余的都是每次匹配到最后,才发现,啊,我们不一样。
这种情况下,上图中,模式串在前 3 次,每次都要匹配 3 次,并且不匹配,直到第 4 次,全部匹配,不需要继续移动,所以匹配的次数为(6 - 3 + 1)* 3 = 12 次。
由此可知,对于主串长度为 n,模式串长度为 m ,最坏情况下的时间复杂度为 O((n - m + 1) * m) = O(n * m)。
相信善于思考的小伙伴会发现,如果是为了寻找的话,根本不需要将i移动到1的位置,因为前面几个字符都是匹配的,再将i移动到1的位置,j移动到0位置,位置错开了,显然也不会匹配,那么我们能不能丢掉以上没必要的步骤,减少指针回溯进行算法简化囊,有一个想法,i位置不动,只需要移动j位置,由此引出我们今天的主人公kmp算法.
KMP算法
基本概念
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。KMP算法的时间复杂度O(m+n)。
区别:KMP 和 BF 唯一不一样的地方在,我主串的 i 并不会回退,并且 j 也不会移动到 0 号位置
分析KMP算法
假定我们给出字符串"ababcabcdabcde"做为主串,然后给出子串"abcd",现在我们需要查找子串是否在主串中出现,出现返回主串中第一个匹配的下标,失败返回-1.
1.首先举例说明,为什么主串不回退

2.j的回退的位置
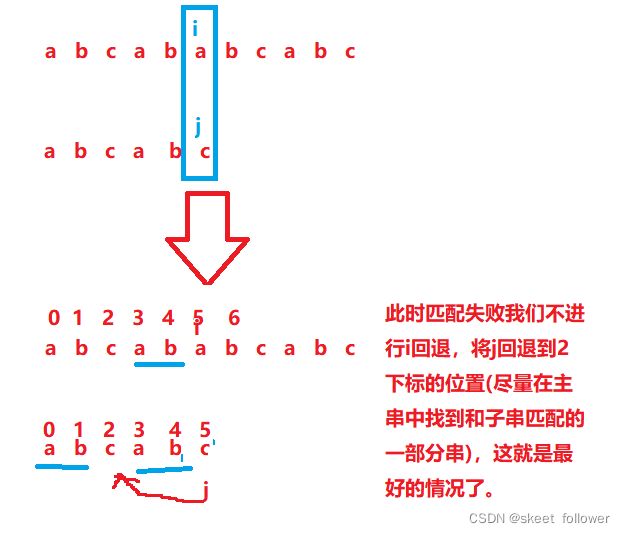
那么j是怎么回退到下标2的位置的囊?下面我们引出next数组
引出next数组
KMP 的精髓就是 next 数组:也就是用 next[j] = k;来表示,不同的 j 来对应一个 K 值,这个 K 就是你将来要移动的 j要移动的位置。而 K 的值是这样求的:
- 规则:找到匹配成功部分的两个相等的真子串(不包含本身),一个以下标 0 字符开始,另一个以 j-1 下标字符结尾。
- 不管什么数据 next[0] = -1;next[1] = 0;在这里,我们以下标来开始,而说到的第几个第几个是从 1 开始;
求next数组的练习:
练习一:举例对于”ababcabcdabcde”, 求其的 next 数组?
-1 0 0 1 2 0 1 2 0 0 1 2 0 0

练习 2: 再对”abcabcabcabcdabcde”,求其的 next 数组? "
-1 0 0 0 1 2 3 4 5 6 7 8 9 0 1 2 3 0
核心的东西来了:
到这里大家对如何求next数组应该问题不大了,接下来的问题就是,已知next[i] = k;怎么求next[i+1] = ?
如果我们能够通过 next[i]的值,通过一系列转换得到 next[i+1]得值,那么我们就能够实现这部分。
那该怎么做呢?
首先假设: next[i] = k 成立,那么,就有这个式子成立:P0...Pk-1 = Px...Pi-1,得到: P0...Pk-1 = Pi-k..Pi-1;如下图分析:

然后我们假设如果 Pk = Pi;我们可以得到 P0...Pk = Pi-k..Pi;那这个就是 next[i+1] = k+1;

那么: Pk != Pi 呢?

代码实现
C代码:
#include
#include
#include
void GetNext(int* next, char* sub, int len2)
{
next[0] = -1;//规定第一个为-1,第二个为0,则直接这样定义就好了;
next[1] = 0;
int k =0;//前一项的k
int j = 2;//下一项
while (j < len2)
{
if (k==-1||sub[j-1] == sub[k])
{
next[j] = k + 1;
j++;
k++;
}
else
{
k = next[k];
}
}
}
int KMP(char* str, char* sub, int pos)
{
assert(str != NULL && sub != NULL);
int len1 = strlen(str);
int len2 = strlen(sub);
assert(pos >= 0 && pos < len1);
int i = pos;//i从指定下标开始遍历
int j = 0;
int* next = (int*)malloc(sizeof(int) * len2);//动态开辟next和子串一样长
assert(next != NULL);
GetNext(next, sub, len2);
while (i < len1 && j < len2)
{
if (j == -1||str[i] == sub[j])//j==-1是防止next[k]回退到-1的情况
{
i++;
j++;
}
else {
j = next[j];//如果不相等,则用next数组找到j的下个位置
}
}
if (j >= len2)
{
return i - j;
}
else {
return -1;
}
}
int main()
{
char* str = "ababcabcdabcde";
char* sub = "abcd";
printf("%d\n", KMP(str, sub, 0));
return 0;
} java代码:
public static void getNext(int[] next, String sub){
next[0] = -1;
next[1] = 0;
int i = 2;//下一项
int k = 0;//前一项的K
while(i < sub.length()){//next数组还没有遍历完
if((k == -1) || sub.charAt(k) == sub.charAt(i-1)) {
next[i] = k+1;
i++;
k++;
}else{
k = next[k];
}
}
}
public static int KMP(String s,String sub,int pos) {
int i = pos;
int j = 0;
int lens = s.length();
int lensub = sub.length();
int[] next= new int[sub.length()];
getNext(next,sub);
while(i < lens && j < lensub){
if((j == -1) || (s.charAt(i) == sub.charAt(j))){
i++;
j++;
}else{
j = next[j];
}
}
if(j >= lensub) {
return i-j;
}else {
return -1;
}
}
public static void main(String[] args) {
System.out.println(KMP("ababcabcdabcde","abcd",0));
System.out.println(KMP("ababcabcdabcde","abcde",0));
System.out.println(KMP("ababcabcdabcde","abcdef",0));
}关键代码讲解
else{
j=next[j]
}

if (j == -1||str[i] == sub[j])
{
i++;
j++;
}
问题:为啥还有个j==-1?
如下图所示:当第一个字符就不匹配,i,j此时都是0,j=next[j] >> j=next[0] >> j=-1; 此时j是-1,如果不添加j==-1这种情况,那么这个程序将结束返回没有匹配,但你仔细观察下图,P[5]~P[8]与子串相匹配,故答案显然错误.所以我们应该加上j==-1这种情况,让其从头再遍历;
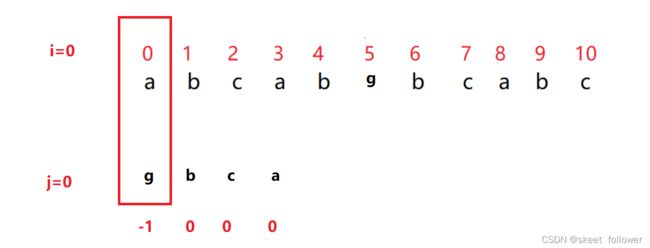
next[0] = -1;
next[1] = 0;
int k =0;//前一项的k
int j = 2;//下一项
根据我们的规定next数组第一个和第二个数为-1和0,故没啥问题。k=0是前一项k的值,j=2是下一项.
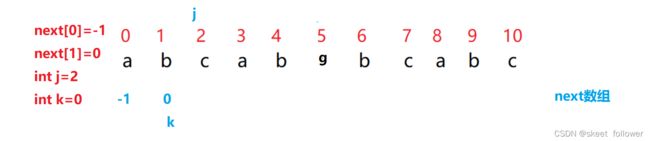
if (k==-1||sub[j-1] == sub[k])
{
next[j] = k + 1;
j++;
k++;
}
根据上面的内容我们可知,p[j]==p[k],next[i]=k;则能推出next[i+1]=k+1;如下图所示,不过这里i是j-1,大家要注意这一点, p[j]==p[k]>>sub[j-1]==sub[k];next[i+1]=k+1>>next[j]=k+1;

else
{
k = next[k];
}
这个知识点上面讲过,当p[j]!=p[k]时候,k回退,一直找到p[j]==p[k]然后用这个next[i+1]=k+1;
牛刀小试
题目在这里>>重复的子字符串
感兴趣的伙伴可以去做试试,下一章我们进行共同探讨;
KMP算法的时间复杂度
假设在M字符串中找N字符串的起始位置,长度分别为m和n,使用KMP算法,一般认为时间复杂度是O(m+n),也就是计算next数组的时间复杂度是O(n),而匹配的时候是O(m).
以上是KMP算法的讲解,有不足的地方或者对代码有更好的见解,欢迎评论区留言共同商讨,共同进步!!
