这一部分打算从头记录一下CUDA的编程方法和一些物理架构上的特点;从硬件入手,写一下包括线程束的划分、流水线的调度等等微结构的问题,以及这些物理设备是如何与软件对应的。下一部分会写一下cuda中的几种内存划分,进行数据同步,以及优化cuda运行效率的几种方法。
1 硬件架构
1.1 Tesla : G80
不同厂家、版本的GPU内容差别可能会比较大,因此挑出几款比较经典的GPU,写一些通用的部分。
GPU最重要的一点是可以并行的实现数据处理。这一点在数据量大、运算复杂度不高的条件下极为适用。可以简单地把一块GPU想象成一个超多核的CPU运算部件。这些CPU有自己的寄存器,还有供数据交换用的共享内存、缓存,同时周围还有取指部件和相应的调度机制,保证指令能够在之上执行。
G80 在 2006年发布,是Telsa架构下的一块早期显卡,拥有现在GPU中一些非常重要的特点,比如SM/SP的划分、多级内存结构、线程束等等,在后文会一一展开。
一块G80内,设计了多个SM(stream Multiprocessor: 流多处理器), 每个SM内又包括了多个SP(streaming processor)。而SP正是实现算数功能的核心部件,可以类比CPU之中的ALU单元,只不过其计算能力要差很多。G80中计算单元甚至只有24位,做32位整形数运算的时候需要使用算法模拟。

上图为一块G80的架构。L1、L2是两级缓存,还有一些用于顶点处理等图形功能的部件;其中拿出这样的一条来,即为一块SM:
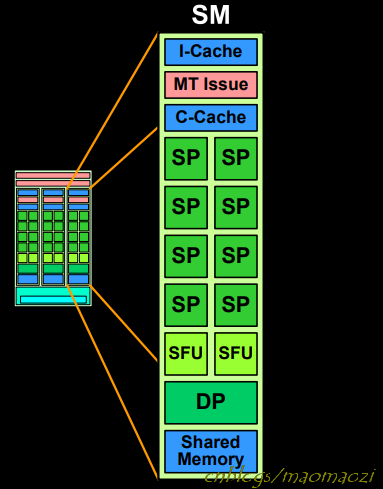
可以看到,一块G80上面设计了16块SM, 其中每个SM上又有8个SP,一共是128个SP。
除了这些计算单元之外,处理器上还有许多其他的部件。每个SM内部的SP之间,可以共享一块shared memory, 以及一块指令缓存用于存放指令、一块常量缓存(c-cache)用来存放常量数据,两个SFU(特殊运算单元,special function unit)用来做三角函数等较复杂运算,MT issue用来实现多线程下的取指,以及DP(Double Precision Unit)用来做双精度数。 除去一些运算单元之外,最重要的就是c-cache与shared memory(在G80上为16KB)两块数据存储区。注意这两个位置的数据只能由SM内部的SP进行访问,这也是将SP划分在多个SM内的意义所在,后面还会进一步展开。另外注意,如同cpu边上的cache一样,cache被故意设计成对程序员透明的,并不能主动控制一个数据存放于cache还是存放于内存。
当然,SM之间也有用于数据交换的区域。最主要的是global memory,可以供所有的SM共享,同时有通向CPU上内存的数据总线,which means 通过这里可以从cpu那里获得数据。容量更大,访存速度也更慢。
1.2 CPU & GPU
初学CUDA的人可能会对多种不同层次的内存感到困惑。个人理解,多核处理器中一个很重要的问题就是数据的统一。冯诺依曼结构中规定了多级速度不同的存储器部件,使得访存可以更快更高效的进行,但多核处理器中还需要维护不同数据间的一致性,不然就会带来脏读等问题。这样一来,把线程划分到不同的层次,有的变量归为线程私有,有的变量归为整个block上共享,有的可以全局共享,就可以很方便的提升算法的效率。几种数据并不互通,当用户需要的时候可以主动的将一种变量复制到另一个区域,也有利于减少不一致性。
GPU和一个多核cpu很像,主要区别除了存储部件,还在于指令的调度方式,会在后文线程部分展开。
1.3 other GPU architect
Fermi
fermi 是NVIDIA推出的另一款经典架构,从整体结构上看仍遵从SM--Sp的划分,增加了一些SP数量。注意下图中的是一块SM,从前的SM上只有8块Sp(G80、GT200),而现在增加到了32个;特殊运算单元、缓存的数量也有所增加。
此外还设计了16个LD/ST单元。LD/ST意思就是load & store, 每次可以同时为block内的16个线程(block~线程的关系后面展开)计算目标地址和源地址,加快访存速度。
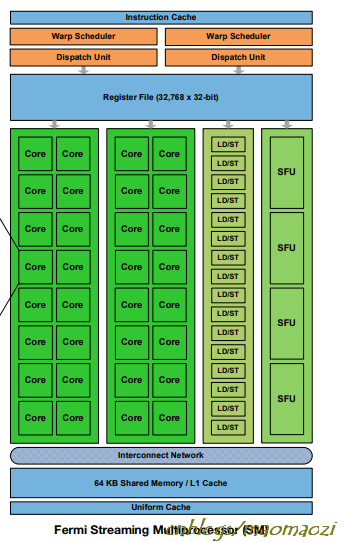
SP也有了新的名字--core。其实Core内部已经有不小的变化,每一个Core内部都有一个全流水的整形单元和一个浮点数运算单元,对计算模式下的GPU运行效率有很大改进。在Fermi中,ALU和FPU也支持了32位的运算操作;同时提出了dual scheduler 的设计,两个线程束可以并行计算。

双精度数的计算效率提升很大:

Maxwell
maxwell比fermi更晚一些,在2014年发布,其中的一些重要变化如 Core、LD\ST都已经在Fermi中介绍过了。
比较大的变化是Maxwell里面提出了SMM( Maxwell Streaming Multiprocessors)的概念,把四个fermi中的SM拼在一起,SMM一共有5组。同时也优化了流水线结构,减少了STALL数量等等。

有兴趣的同学可以在这几种架构白皮书中找到更多信息。
- Fermi
- kepler
- maxwell
2 helloworld与软件结构
2.1 helloworld
先看一段最基本的CUDA程序:
void CPUFunction()
{
printf("This function is defined to run on the CPU.\n");
}
__global__ void GPUFunction()
{
printf("This function is defined to run on the GPU.\n");
}
int main()
{
CPUFunction();
GPUFunction<<<1, 1>>>();
cudaDeviceSynchronize();
}
CUDA程序可以分成两部分。一部分和C一样,运行在CPU上;另一部分会单独编译,运行在“device”, 也就是GPU上。程序入口仍旧是 int main(),主要语法与C无异。
其中,__global__ void GPUFunction() 被称作核函数(kernel function),是cuda核心程序的入口部分。程序执行至这里时,将代码段交由GPU执行。
- 注意要加上
__global__关键字,表示这是运行在GPU上的函数。 - 核函数在调用时,使用三对尖括号,里面的两个变量分别对应block数量与thread数量,引出下面的内容:
2.2 软件结构
硬件上,运算单元被划分成了SM-->SP的层次,而相对应的在软件上也划分了grid-->block-->thread这样的结构:其中,block、 grid 都可以设计为三维,拥有x、y、z三个维度的信息。

软件和硬件之间有着对应关系:
在一个核函数的运行过程当中,调度器会把Block整个地放在SM上进行运算,同时Block上的线程会运行在SM上的SP内。也就是说SM和block有对应关系,SP和thread有对应关系。但是这种映射关系并不是满射,只能说有关联:
首先:一个BLOCK不能分到多个SM上执行,但是不同的Block有可能会分到相同的SM(这个是调度器控制的,对用户不可见)。既然sharedmemory在sm上,这样就解释了为什么Block之间没有办法共享shared memory,也不能够进行同步,否则会产生死锁。当然,根据GPU的物理结构, 还有DRAM可以共享。
block被调度至sm上后,相应的,thread与SP相对应。当然很明显thread数量要远远大于SM内的Sp数量(G80内为8个),所以多个线程并不是真正的全部并行执行的,而是依靠类似操作系统中的作业调度系统,在时间片上轮转。同一时间内,在SM上运行的thread数量就是sp数量。
grid的概念是相对于核函数来说的。由一个单独的kernel启动的所有线程组成一个grid,grid中所有线程共享global memory。kernel function之间也可以并行执行甚至递归执行,在后面会介绍。
上面的helloworld程度段只包含了一个核函数,这个核函数内只有一个block,每个block内1个thread。当然可以这样设计:
someKernel<<<10, 1>>()配置为在 10 个线程块(每个均具有单线程)中运行后,将运行 10 次。someKernel<<<1, 10>>()配置为在具有 10 线程的单个线程块中运行后,将运行 10 次。someKernel<<<10, 10>>()配置为在 10 个线程块(每个均具有 10 线程)中运行后,将运行 100 次。
2.3 SIMT
现在回头看下前面的hello world程序段。如果把核函数的入口改成GPUFunction<<<10, 10>>>();,那么就会打印100次GPU的输出。只编写一行代码,但这100个线程全部运行一段相同的程序段,这种就是CUDA的编程模型:SIMT(Single Instruction Multiple Thread)
SIMT和SIMD的概念有些容易混淆。SIMD(multiple data)指的是单指令多数据,把一个运算指令交由多个运算部件,强调使用运算部件和向量操作,来批量的对数据做处理和提升数据层面的并行性。

比如上图的第三列。一条加法指令同时分配给4个ALU(或者是FPU, whatever)。

而SIMT强调的是线程级别,使用一条指令,运行在不同线程上,来处理不同的数据集。个人理解两者并不是非此即彼的关系,关注的重点不太一样。
2.3 使用自己的threadid、blockid
之前说CUDA的编程思想是SIMT,即使用一段相同的程序段(指令),为每个线程分配不同的任务。这样就需要类似循环一样,每一个线程都需要一个id来标识自己的唯一性。
这些变量在CUDA之中已经预先赋值,用户可以直接调用,分别是:threadIdx blockIdx blockDim GridDim四个。其中,blockDim表示每个block中有多少个thread, gridDim表示grid之中有多少个block;剩下两个变量标志了某一线程所处的线程号、块号。
每一个grid、block、thread都有自己的索引(从0开始)通过将此变量与 blockIdx.x 和 threadIdx.x 变量结合使用,并借助惯用表达式 threadIdx.x + blockIdx.x * blockDim.x 在包含多个线程的多个线程块之间组织并行执行,并行性将得以提升。
eg:
执行配置 <<<10, 10>>> 将启动共计拥有 100 个线程的网格,这些线程均包含在由 10 个线程组成的 10 个线程块中。因此,我们希望每个线程(0 至 99 之间)都能计算该线程的某个唯一索引。
- 如果线程块
blockIdx.x等于0,则blockIdx.x * blockDim.x为0。向0添加可能的threadIdx.x值(0至9),之后便可在包含 100 个线程的网格内生成索引0至9。 - 如果线程块
blockIdx.x等于1,则blockIdx.x * blockDim.x为10。向10添加可能的threadIdx.x值(0至9),之后便可在包含 100 个线程的网格内生成索引10至19。 - 如果线程块
blockIdx.x等于5,则blockIdx.x * blockDim.x为50。向50添加可能的threadIdx.x值(0至9),之后便可在包含 100 个线程的网格内生成索引50至59。 - 如果线程块
blockIdx.x等于9,则blockIdx.x * blockDim.x为90。向90添加可能的threadIdx.x值(0至9),之后便可在包含 100 个线程的网格内生成索引90至99。‘
当然,任务数量不可能永远和线程数量正好匹配。(很多时候任务数量更大),这时:
-
首先需要保证线程数量>=任务数。然后可以使用if判断条件,只给部分线程分配任务。
-
情景是,线程数往往比对应的数据数量要少,这时候就必须给每个线程分配多余1个任务。为了使得每个线程的任务尽享公平,这里采用这种跨网格的算法来实现。

具体到代码,是这么实现的:
__global void kernel(int *a, int N)
{
int indexWithinTheGrid = threadIdx.x + blockIdx.x * blockDim.x;
int gridStride = gridDim.x * blockDim.x;
//index很好理解。就是线程号加上block号(像二维数组
//此处的步长,其实就是所有的线程数量(?)例如上图的步长应该为8;blockdim为block内线程数量(4),griddim为grid内block数量(2)
for (int i = indexWithinTheGrid; i < N; i += gridStride)
{
// do work on a[i];
}
}
即使待处理任务数量不是总线程数的整数倍也可以完备的执行。
2.4高维度的网格、块
可以将网格和线程块定义为最多具有 3 个维度。使用多个维度定义网格和线程块绝不会对其性能造成任何影响,但这在处理具有多个维度的数据时可能非常有用,例如 2D 矩阵。如要定义二维或三维网格或线程块,可以使用 CUDA 的 dim3 类型,即如下所示:
dim3 threads_per_block(16, 16, 1);
dim3 number_of_blocks(16, 16, 1);
someKernel<<>>();
鉴于以上示例,someKernel 内部的变量 gridDim.x、gridDim.y、blockDim.x 和 blockDim.y 均将等于 16。
2.5 查询设备信息
跟warp、deviceid等等有关的信息,被放在一个结构体prop之中(类似于句柄)。使用如下方法可以进行访问:
int deviceId;
cudaGetDevice(&deviceId);
cudaDeviceProp props;
cudaGetDeviceProperties(&props, deviceId);
int computeCapabilityMajor = props.major;
int computeCapabilityMinor = props.minor;
int multiProcessorCount = props.multiProcessorCount;
int warpSize = props.warpSize;
printf("Device ID: %d\nNumber of SMs: %d\nCompute Capability Major: %d\nCompute Capability Minor: %d\nWarp Size: %d\n", deviceId, multiProcessorCount, computeCapabilityMajor, computeCapabilityMinor, warpSize);
3 编译
CUDA在编译时使用编译器nvcc,作为一个C的扩展,nvcc的编译方法和gcc/g++类似。
在编译时,nvcc会用g++对其中cpu部分的代码编译,余下gpu的部分使用cudacc进行编译,首先生成一个虚拟环境下的.ptx文件,之后再根据具体GPU类型生成不同的二进制码。
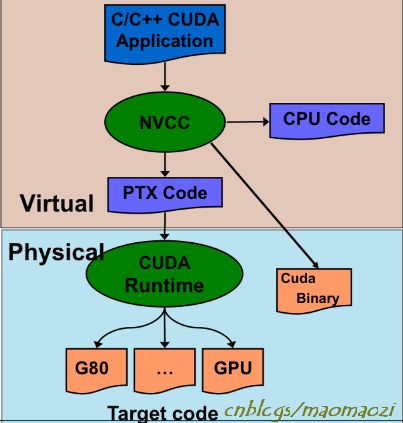
使用nvcc -o指令可以直接获得可执行文件。
4 同步问题
上面的代码中有一行还没有提及,即cudaDeviceSynchronize() ,用来控制CUDA上设备进行同步。
“同步”时,所有的对象会再执行到这条语句的时候进入阻塞状态,等到其他对象都运行到了这里,再一同运行下面的指令(“对象”可以是线程、block等等)。同步在CUDA中是一个很关键的概念,因为如果不使用同步会导致很多意外错误,仍旧以上面的helloworld为例子:
void helloCPU()
{
printf("Hello from the CPU.\n");
}
__global__ void helloGPU()
{
printf("Hello also from the CPU.\n");
}
int main()
{
helloCPU();
helloGPU<<<1,1>>>();
//cudaDeviceSynchronize();
}
如果把最后的cudaDeviceSynchronize注释掉,来自GPU的信息就不会被打印。总这里可以看出进行同步的作用:
- cudaDeviceSynchronize():
在CPU端调用,阻塞CPU端线程的执行,一直到GPU完成之前CUDA的任务,包括kernel函数、数据拷贝等。
- _syncthreads():block内的线程同步。
因为所有线程并不是完全并行的,有的在片上,有的在片下,因为不能保证全部线程都运行速度一样。例如,一个很简单的规约操作: n个数两两相加,最后求总和。这个过程中就需要注意线程的同步问题。
_syncthreads()和cudaThreadSynchronize() 是有区别的。_syncthreads()控制的是块内线程,在cuda程序段内调用,而cudaThreadSynchronize() 在cpu内调用。
5 线程的调度与线程束
5.1 线程束
GPU虽然标榜自己是多线程并行,但用户声明的几千个线程可能并不会完全并行化,因为一个block上的线程数量通常远大于SM内的SP数量。
这就说到了CUDA的另一个名词,即线程束(warps)。这个名词可以直接望文生义:就是一把线程,一个小的线程集合,通常为32个。GPU在线程调度的时候,会由调度器(global block scheduler)每次选择一个线程束分配到SM上。例如一个核函数定义了128个线程,那么就会划分为4个warps。只有被选择到的线程有资格访问运算单元,其余的线程都将处于挂起状态,等待访存延迟或者在就绪队列中等待。

Warp是很重要的概念,因为一个warp是一个GPU内的基本执行单元。在代码运行的时候,同一个warp内的32个线程都会执行相同的指令,这对访存、分支跳转语句等指令来说都是很关键的,这一部分后面再展开。
线程束的划分是固定的。假设一个block上定义了128个线程,0-31号线程一定会分配到warp1, 32-63被分配到warp2,以此类推。如果用户声明的线程数量并不是32的整数倍,如一个block内有100个线程,那么就会有32-(100 mod 32) 个线程处于未激活状态,仍然会被分配到warp上。
但线程束在调度的时候没有太大规律,其调度不是按照顺序的,只要有处于Ready Queue的warps,且当前的运算单元没被占用时,warp调度器就会调用Ready Queue的warps去执行指令。直到warps都挂起。所以,warp1 并不是一定再warps 2 后执行。在编写程序的时候不要依赖于线程束调度顺序来编写程序,记得使用_syncthreads()来控制线程的同步,不要自行判断线程执行的先后顺序。
5.2 控制流语句
先写下CPU中怎么处理分支跳转语句。
为了加快CPU的运行速度,人们设计了5级的静态流水线,分为取指(IF)、译码(ID)、执行(EXE)、访存(MEM)、写回(WB)五个阶段。IF阶段,CPU从指令寄存器IR中读出下一条指令的首地址,并交给译码器将操作数、指令编码进行翻译。各操作数都准备就绪后根据操作码送入运算单元执行,运算完成后如果是一个访存操作需要按照地址访问存储器,最后再把运算结果或者访存结果写回寄存器。
绝大部分指令下,这个流水线是可以不间断的执行的(遇到RAW、WAW等相关性问题需要通过重命名寄存器等方法消除,此处不再展开)。一个例外是跳转语句。以一条misp指令BENZ R1, # 100为例,如果r1寄存器的值不为0,那么程序就会以100为偏移量进行跳转。当流水线遇到这条指令时,需要译码结束,操作数都准备完成的EXE阶段,才能得知这条语句是否需要跳转以及跳转到哪里,可问题是这时候下一条语句已经完成取指了,到底取的是哪一条指令?
早期的架构中,CPU会使用一条空转指令NOP来填充延迟槽,遇到这条指令CPU不做任何操作,空转一个时钟周期等待跳转判断完成。可以使用其他指令填充延迟槽,但这些都需要指令调度。当然也可以使用分支预测技术。简单来讲,就是通过维持一个跳转转移表,来对当前语句的跳转行为进行预测。不论最后的跳转结果,先预判一条指令到流水线上,如果预测对了就顺序执行,如果预测失败就先把流水线全部 flush 清空,再取新的指令。
GPU的运行逻辑中也常常会遇到分支跳转指令,然而并没有足够资源为每一个SP都进行分支预测,所以GPU的处理十分简单粗暴:同一warp内所有的线程,都执行同一条指令:
1 if( threadId.x < 4) {
2 a = 0
}
3 else{
4 b= 0;
}
1 - 4 这几行代码,在CPU中只会执行一部分,但是GPU中会顺序的执行。对于Warp1,共 0到3 号线程在逻辑上满足if条件,4 到31号线程满足else条件。但是warp是作为一个整体进行取指操作的,整个warp都会从1-4顺序执行,只不过在运行到第二行、第四行的时候只有部分线程会执行,剩下的处于停用状态。
5.3 线程的选择和切换
下面写一些流水线上的细节,因为这一部分不同架构的区别较大,优先写一些通用的部分。
CPU上拥有5级流水线,早期的流水线是顺序执行的,也叫静态流水。但是后来人们发现指令的执行不一定要按照顺序,可以乱序发射,甚至乱序执行,再顺序提交(写回原寄存器)即可。为了实现乱序,这种动态流水线在5级流水的基础上有了一些变化:
在取指和译码完成后,指令会首先进行寄存器重命名来消除之间存在的 WAW、WAR伪相关(例如: add r0, r0, r1; add r0, r2, r3 两条指令间存在写后写相关。理论上第二条需要第一条写回后才能写回。但是通过寄存器重命名,可以先把指令1 的值存在 r5, 这样两条指令可以乱序执行,只要最后再按顺序提交即可 );之后,指令被送至发射队列中(dispatch),由发射站(dispatch port)选择合适的指令发射出去;发射后的指令读寄存器、执行、写回、最后提交。
尽管目前为止,GPU上还没有乱序的流水线,但是GPU仍有发射等等概念。指令和warp是绑定的,warp的执行要经过如下步骤:
首先, warp scheduler 会花一个时钟周期从指令缓存中取出下一条指令(load from L1 cache , store into cache buffer)
warp scheduler很好理解,作用在于管理warp。每次warp切换时,warp scheduler会从位于就绪队列的warp中选择一个发射。会有一个计分板(score boarding)来实现这些功能,决定选择哪个warp,类似于操作系统的作业调度。
导致warp处于stall 状态的因素会有很多,其中最常见的就是Memory Dependency:之前说过,global memory距离很远,每次取数都要花费很长时间。访问一次global memory 大概需要等待200个时钟周期,在这段时间整个warp都必须进入stall状态;除此之外warp也有可能因为别的原因阻塞,例如用户主动控制的_syncthreads()指令;或者cache miss 导致的延迟(Instruction Fetch、Constant),等等。
指令到达发射站后,根据自身内容选择合适的发射端口(dispatch port)。例如如果是整形数字会正常进入ALU;如果是cos、sin等三角函数,则会被发射到SFU,浮点数则进入FPU,等等。
从上述过程可以看到,指令的发射存在不少瓶颈:首先遇到的瓶颈是warp stall,之后是发射站:指令在发射站上等待,有的复杂函数指令可能还需要发射多次;然后功能部件也会阻塞,G80为例,一个SM上只有2块SFU,如果设计大量的三角函数就只能等待。
CUDA上很有意思的一点是,warp在片上的切换时间基本可以忽略不计。CPU中,进行进程切换需要先保存上下文、处理好寄存器和程序执行信息。但GPU上这一过程几乎不需要等待。主要的原因是线程的寄存器都是私有的(关于存储器下一次再写),只要分配到了某个线程,其生命周期与对应线程相同。所以位于片上的warp移至STALL状态后并不需要做中断和恢复。
5.4 多Block 下的 warp
讨论一个特殊情况帮助理解warp的调度:
假设一个核函数定义为:someKernel<<,拥有n个block,每个block下有256个线程。在CUDA调度时,正好有3块block被分配到了同一块SM上,意味着这块SM上需要运行3*256 = 768 个线程。某一时刻内,一块SM上有几个warp呢?
Sm下共有 768/32 = 24 个warps,但是任意时刻只会执行24中的一个warp。也就是说不同block下的warp如果被分配到了同一块SM,也会相互等待,不能并行工作
5.5 不同GPU架构上的线程调度
随着GPU的发展,有的GPU提供了更多的core和运算能力,不再是8个sp的结构。这种情况下前面的数字会有所不同,调度方法也会有区别。
Tesla 的 线程切换是一来SM上的MT issue部件实现的(每个warp都有自己的指令), 同时在G80中,还有一块4KiB 的Register File (RF)用来存放线程状态。

Fermi下更加清晰一些:每个SM上设计了2个warp schedulers,且每个warp scheduler 对应一个发射站,每次都可以选择一个warp,完成2条指令;在 core内有dispatch port,且浮点运算器放在了core里面。warp scheduler一个周期选择一个warp,dispatch unit一个周期可以发射一条指令,因此只要不在其它地方阻塞,一个SM内每个周期都可以处理两个warp。
fermi已经设计了32个core,正好和一个warp数量内thread相同。但是却又设计了两个warp并行执行,称 dual scheduler,平均下来每个时钟都可以处理一个warp。个人猜测这样做也是为了提升并行效率,nvidia自己写:“Using this elegant model of dual-issue, Fermi achieves near peak hardware performance.”, hhhh。
Maxwell提出了SMM概念,把四块从前的SM拼在了一起。但是四块小的SM仍然在资源上是有分区的,warp会属于其中某个分区,分区之间的部分功能部件不进行共享。每一个小SM上只有一个warp scheduler,但还是保留了两个发射单元, 这样一来如果是普通的ALU运算指令,每个时钟周期的warp就可以填满整个128个core,额外的一个发射单元可以减少发射时的阻塞。
(可以翻回去看上文的图)
6 并发CUDA流
在 CUDA 编程中,流是由按顺序执行的一系列命令构成。在 CUDA 应用程序中,核函数的执行以及一些内存传输均在 CUDA 流中进行。一直到目前为止,还没有直接与 CUDA 流打交道;但实际上您的 CUDA 代码已在名为默认流的流中执行了其核函数。
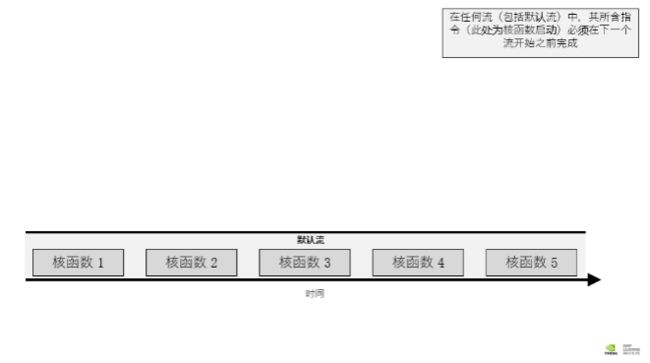
这种模式下,每个核函数必须在上一个完成后才能开始。
当然也可以使用多个流。除默认流以外,CUDA 程序员还可创建并使用非默认 CUDA 流,此举可支持执行多个操作,例如在不同的流中并发执行多个核函数。多流的使用可以为加速应用程序带来另外一个层次的并行,并能提供更多应用程序的优化机会。

注意:
- 给定流中的所有操作会按序执行。
- 就不同非默认流中的操作而言,无法保证其会按彼此之间的任何特定顺序执行。
- 默认流具有阻断能力,即,它会等待其它已在运行的所有流完成当前操作之后才运行,但在其自身运行完毕之前亦会阻碍其它流的运行。
6.1 创建和销毁流
注意这核函数是四个参数。而不是两个
要在非默认CUDA流中启动CUDA核函数,必须将流作为执行配置的第4个可选参数传递给该核函数。
#include
cudaStream_t stream; // CUDA流的类型为 `cudaStream_t`
cudaStreamCreate(&stream); // 注意,必须将一个指针传递给 `cudaCreateStream`
someKernel<<>>(); // `stream` 作为第4个EC参数传递
cudaStreamDestroy(stream); // 注意,将值(而不是指针)传递给 `cudaDestroyStream`
第三个参数的含义目前为止并不涉及。此参数允许程序员提供共享内存中为每个内核启动动态分配的字节数,每个块分配给共享内存的默认字节数为“0”。
5-2 实现并发流
例如上面的for例子,可以写成:
#include
#include
__global__ void printNumber(int number)
{
printf("%d\n", number);
}
int main()
{
for (int i = 0; i < 5; ++i)
{
cudaStream_t stream;
cudaStreamCreate(&stream);
printNumber<<<1, 1, 0, stream>>>(i);
cudaStreamDestroy(stream);
}
cudaDeviceSynchronize();
}

可以看到,现在流已经变成了并行执行。
参考文献
https://www.hardwaretimes.com/simd-vs-simt-vs-smt-whats-the-difference-between-parallel-processing-models/#:~:text=SIMT%3A Single Instruction Multiple Threads. SIMT is the,reduces the latency that comes with instruction
https://fabiensanglard.net/cuda/index.html