(系列更新完毕)深度学习零基础使用 PyTorch 框架跑 MNIST 数据集的第一天:LeNet 网络的搭建
1. Introduction
今天是尝试用 PyTorch 框架来跑 MNIST 手写数字数据集的第一天,主要学习 LeNet 网络结构的定义。本 blog 主要记录一个学习的路径以及学习资料的汇总。
注意:这是用 Python 2.7 版本写的代码
第一天(LeNet 网络的搭建):https://blog.csdn.net/qq_36627158/article/details/108098147
第二天(加载 MNIST 数据集):https://blog.csdn.net/qq_36627158/article/details/108119048
第三天(训练模型):https://blog.csdn.net/qq_36627158/article/details/108163693
第四天(单例测试):https://blog.csdn.net/qq_36627158/article/details/108183655
2. Code(lenet.py)
感谢 凯神 提供的代码与耐心指导!
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# C1: input: 1*28*28 output: 6*28*28 (32-5+1)
self.conv1 = nn.Conv2d(
in_channels=1,
out_channels=6,
kernel_size=5,
padding=2
)
# S2: input: 6*28*28 output: 6*14*14
self.max_pooling1 = nn.MaxPool2d(
kernel_size=2,
stride=2
)
# C3: input: 6*14*14 output: 16*10*10 (14-5+1)
self.conv2 = nn.Conv2d(
in_channels=6,
out_channels=16,
kernel_size=5
)
# S4: input: 16*10*10 output: 16*5*5
self.max_pooling2 = nn.MaxPool2d(
kernel_size=2,
stride=2
)
# C5: input: 16*5*5 output: 1*120*1
self.conv3 = nn.Linear(
in_features=16 * 5 * 5,
out_features=120
)
# F6: input: 1*120*1 output: 1*84*1
self.fc1 = nn.Linear(
in_features=120,
out_features=84
)
# F7(OutPut): input: 1*84*1 output: 1*10*1
self.fc2 = nn.Linear(
in_features=84,
out_features=10
)
def forward(self, x):
# C1:
x = self.conv1(x)
x = F.relu(x)
# S2:
x = self.max_pooling1(x)
# C3:
x = self.conv2(x)
x = F.relu(x)
# S4:
x = self.max_pooling2(x)
# num_flat_features(x): get a flatten vector's size
# view(): 16*5*5 -> 400*1
x = x.view(-1, self.num_flat_features(x))
# C5:
x = self.conv3(x)
x = F.relu(x)
# F6:
x = self.fc1(x)
x = F.relu(x)
# F7:
x = self.fc2(x)
x = F.relu(x)
return x
def num_flat_features(self, x):
# x.size() = [b, c, h, w]
# size = [c, h, w] [16*5*5]
size = x.size()[1:]
# c * h * w
num_features = 1
for s in size:
num_features *= s
return num_features
3. Materials
1、LeNet 网络的介绍以及框架的详细解释:
https://blog.csdn.net/qq_42570457/article/details/81460807
2、数据集下载(里面的图片已经是 png 的格式):
https://www.kaggle.com/jidhumohan/mnist-png?
3、PyTorch 官方文档
- torch.nn:https://ptorch.com/docs/1/torch-nn
- torch.nn.functional:https://ptorch.com/docs/1/functional
4. Details
1、Python 类的定义以及初始化函数函数:
https://www.runoob.com/python3/python3-class.html
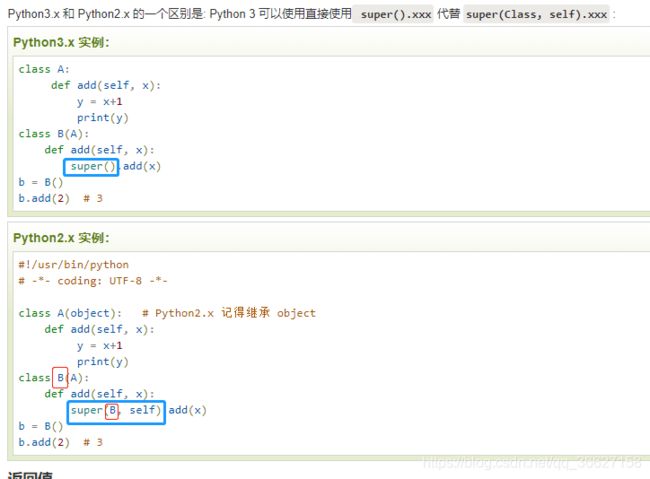
2、Python 2.x 继承父类的 __init__() 与 Python 3.x 不一样。
https://www.runoob.com/python/python-func-super.html
3、torch.nn 与 torch.nn.functional 的区别:
最开始是因为看到了池化层既可以写成:self.max_pooling1 = nn.MaxPool2d() ;也可以写成:self.max_pooling1 = F.maxpool2d()。就产生了疑问:既然都有每一层的实现方法,为什么不只使用 torch.nn ?或者为什么不只使用 torch.nn.functional ?为什么要两个混在一起写?有什么区别吗?
后来找到了一篇不错的解释:https://blog.csdn.net/GZHermit/article/details/78730856
4、代码中的 [1:] 是什么意思?
表示去掉列表中第一个元素(下标为0),对后面的元素进行操作。
https://blog.csdn.net/gaofengyan/article/details/90697743
5、代码中的 view() 函数是干什么用的?其中的参数 -1 又是什么意思?
https://blog.csdn.net/zkq_1986/article/details/100319146
6、数据在 PyTorch 框架下的神经网络里流动时,有时候是四维张量,哪四维?
四维指的是:【b,c,h,w】:b:图片的张数 c:通道数 h:高 w:宽
7、forward() 函数
一开始以为代码里的forward() 函数是自己写的 /(ㄒoㄒ)/~~ 不对!是 重写 父类 nn.Module 里的 forward() 函数
注意:定义神经网络, 需要继承 nn.Moudle, 并重载 __init__ 和 forward 方法
forward() 函数使用我们在构造函数(初始化函数)内部定义的所有层,其实就是实际的网络转换
https://cloud.tencent.com/developer/article/1639430
forward 的使用:https://blog.csdn.net/xu380393916/article/details/97280035