数仓OLAP(一)--即席查询 Kylin
一、Kylin
Apache Kylin 是一个开源的分布式分析引擎,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据。它能在亚秒内查询巨大的 Hive 表,可以做到在 TB 级的数据量上实现亚秒级的查询响应。
核心思想
Apache Kylin的核心思想是利用空间换时间,它主要是通过预计算的方式将用户设定的多维立方体缓存到HBase中(目前还仅支持hbase),同时由于Apache Kylin在查询方面制定了多种灵活的策略,进一步提高空间的利用率,使得这样的平衡策略在应用中值得采用。
kylin主要是对hive中的数据进行预计算,利用hadoop的mapreduce框架实现。
kylin的出现就是为了解决大数据系统中TB级别数据的数据分析需求,而对于关系数据库中的数据分析进行预计算可能有点不合适了。
1、Kylin优点
Kylin 的主要特点包括支持 SQL 接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI 工具集成等。
- 标准 SQL 接口:Kylin 是以标准的 SQL 作为对外服务的接口。
- 支持超大数据集:Kylin 对于大数据的支撑能力可能是目前所有技术中最为领先的。早在 2015 年 eBay 的生产环境中就能支持百亿记录的秒级查询,之后在移动的应用场景中又有了千亿记录秒级查询的案例。
- 亚秒级响应:Kylin 拥有优异的查询相应速度,这点得益于预计算,很多复杂的计算,比如连接、聚合,在离线的预计算过程中就已经完成,这大大降低了查询时刻所需的计算量,提高了响应速度。
- 可伸缩性和高吞吐率:单节点 Kylin 可实现每秒 70 个查询,还可以搭建 Kylin 的集群。
- BI 工具集成
Kylin 可以与现有的 BI 工具集成,具体包括如下内容。
ODBC:与 Tableau、Excel、PowerBI 等工具集成
JDBC:与 Saiku、BIRT 等 Java 工具集成
RestAPI:与 JavaScript、Web 网页集成
Kylin 开发团队还贡献了 Zepplin 的插件,也可以使用 Zepplin 来访问 Kylin 服务。
2、Kylin的缺点
- 集群依赖较多,如HBase和Hive等,属于重量级方案,因此运维成本也较高。
- 查询的维度组合数量需要提前确定好,不适合即席查询分析。
- 预计算量大,资源消耗多。
3、使用场景
(1) 假如你的数据存在于Hadoop的HDFS分布式文件系统中,并且你使用Hive来基于HDFS构建数据仓库系统,并进行数据分析,但是数据量巨大,比如TB级别。
(2) 同时你的Hadoop平台也使用HBase来进行数据存储和利用HBase的行键实现数据的快速查询等应用
(3) 你的Hadoop平台的数据量逐日累增
(4) 对于数据分析的维度大概10个左右
二、Kylin 架构
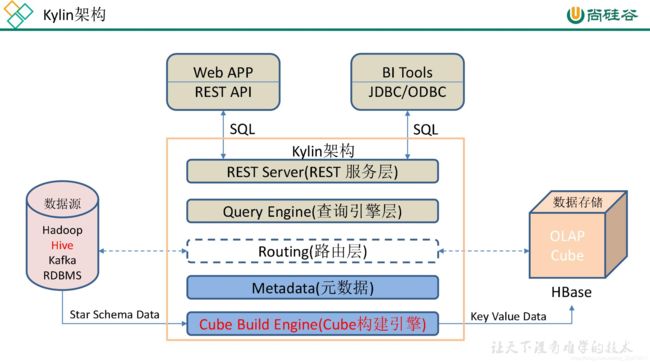
上图是 Kylin 的架构图,从图中可以看出,Kylin 利用 MapReduce/Spark 将原始数据进行聚合计算,转成了 OLAP Cube 并加载到 HBase 中,以 Key-Value 的形式存储。Cube 按照时间范围划分为多个 segment,每个 segment 是一张 HBase 表,每张表会根据数据大小切分成多个 region。Kylin 选择 HBase 作为存储引擎,是因为 HBase 具有延迟低,容量大,使用广泛,API完备等特性,此外它的 Hadoop 接口完善,用户社区也十分活跃。
1)REST Server
REST Server 是一套面向应用程序开发的入口点,旨在实现针对 Kylin 平台的应用开发工作。 此类应用程序可以提供查询、获取结果、触发 cube 构建任务、获取元数据以及获取用户权限等等。另外可以通过 Restful 接口实现 SQL 查询。
2)查询引擎(Query Engine)
当 cube 准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。
3)路由器(Routing)
在最初设计时曾考虑过将 Kylin 不能执行的查询引导去 Hive 中继续执行,但在实践后发现 Hive 与 Kylin 的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。最后这个路由功能在发行版中默认关闭。
4)元数据管理工具(Metadata)
Kylin 是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存在 Kylin 当中的所有元数据进行管理,其中包括最为重要的 cube 元数据。其它全部组件的正常运作都需以元数据管理工具为基础。 Kylin 的元数据存储在 hbase 中。
5)任务引擎(Cube Build Engine)
这套引擎的设计目的在于处理所有离线任务,其中包括 shell 脚本、Java API 以MapReduce 任务等等。任务引擎对 Kylin 当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障
三、Kylin 使用
- 新建model
- 新建cube
- build cube
- 内连接查询测试
1)每日全量维度表及拉链维度表重复 Key 问题如何处理
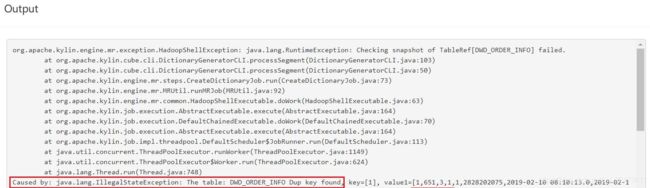
错误原因分析:
上述错误原因是 model 中的维度表 dwd_dim_user_info_his 为拉链表、dwd_dim_sku_info为每日全量表,故使用整张表作为维度表,必然会出现订单表中同一个 user_id 或者 sku_id对应多条数据的问题,针对上述问题,有以下两种解决方案
- 方案一:在 hive 中创建维度表的临时表,该临时表中只存放维度表最新的一份完整的数据,在 kylin 中创建模型时选择该临时表作为维度表。
- 方案二:与方案一思路相同,但不使用物理临时表,而选用视图(view)实现相同的功能。
此处采用方案二:
1)创建维度表视图
--拉链维度表视图
create view dwd_dim_user_info_his_view as select * from
dwd_dim_user_info_his where end_date='9999-99-99';
--全量维度表视图
create view dwd_dim_sku_info_view as select * from
dwd_dim_sku_info where dt=date_add(current_date,-1);
--当前情形我们先创建一个 2020-03-10 的视图
create view dwd_dim_sku_info_view as select * from
dwd_dim_sku_info where dt='2020-03-10';2)在 DataSource 中导入新创建的视图,之前的维度表,可选择性删除。
3)重新创建 model、cube
3.1、构建Cube的2种途径:
方式一:Kylin Web:
Apache Kylin | Kylin Cube 创建教程
这是常用的一种方法,比较便捷、可视化。
需要强调的是,不管是哪种方式submit的build任务,都可通过Web监控。
当build成功以后就能够在Insight进行sql查询数据(查询的表仍是hive的表名称,只是要使用cube里面的维度以后,这样才是对Hbase的预计算结果进行查询,否则就是直接使用MapReduce查询hive的原数据,速度很是慢)。
接下来咱们要处理上线以后定时任务,由于hive是以时间做为分区,天天有增量数据,因此须要再kylin天天增量写入数据:
方式二:命令行工具:RESTful API
在Kylin服务器上用命令行工具时,不需要再进行进行权限认证。
| api | 返回值 | 描述 |
| http://ip:7070/kylin/api/models | json数组 | 查看所有model元数据 |
| http://ip:7070/kylin/api/cubes | json数组 | 查看所有cube元数据 |
| http://ip:7070/kylin/api/jobs/xxx | json数组 | 查看单个cube提交后的任务 |
主要分为两步:认证、提交构建cube任务。kylin使用basic authentication进行认证,在post请求上加上用于认证的 Authorization 头部:
POST http://localhost:7070/kylin/api/user/authentication完成认证后就可以提交cube任务:
PUT http://localhost:7070/kylin/api/cubes/{cube_name}/rebuild关于 put请求体的参数:
startTime : 作增量时,startTime 为上一次build的endTime。
endTime:时间精确到毫秒。
buildType:可选BUILD,MERGE,REDRESH
。 BUILD用于构建一个新的segment,REFRESH用于刷新一个已有的segment,MERGE用于合并多个已有的segment生成一个较大的segment。Postman简化了http请求调用方式,请求时的头部信息:
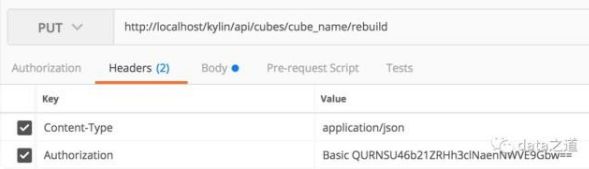
Body带上参数,指定build、refresh、merger,以及时间范围:

2、submit cube
1:用户认证:Kylin的认证是basic authentication,加密算法是Base64,加密的明文为username:password;在POST的header进行用户认证:
curl -X POST -H "Authorization: Basic xxxxxxxx=" -H 'Content-Type: application/json' http://hostname:port/kylin/api/user/authentication
2:在认证完成以后,能够复用cookie文件(再也不须要从新认证),向Kylin发送GET或POST请求,好比,查询cube的信息:
curl -b cookiefile.txt -H 'Content-Type: application/json' http://hostname:port/kylin/api/cubes/cube_name
返回信息:
{"uuid":"xxxxxxxxxxxx","last_modified":1540804968611,"version":"2.5.0.20500","name":"cube_name","owner":"username","descriptor":"cube_name","display_name":"cube_name",
"cost":50,"status":"DISABLED","segments":[],"create_time_utc":1540535981140,"cuboid_bytes":null,"cuboid_bytes_recommend":null,"cuboid_last_optimized":0,"snapshots":{}}
经过RESTful API查询SQL:
curl -b cookiefile.txt --user username:password -X POST -H 'Content-Type: application/json' -d '{"sql":"select count(1) from table_name group by partition_name", "offset":0, "limit":10, "acceptPartial":false, "project":"project_name"}' http://hostname:port/kylin/api/query
其中,offset为sql中相对记录首行的偏移量,limit为限制记录条数;两者在后台处理时都会拼接到sql中去。发送sql query的curl命令:
二)如何实现每日自动构建 cube
熟悉了curlful API以后,而后进行sh的定时:
Kylin 提供了 Restful API,因次我们可以将构建 cube 的命令写到脚本中,将脚本交给
azkaban 或者 oozie 这样的调度工具,以实现定时调度的功能
#!/bin/bash
cube_name=order_cube
do_date=`date -d '-1 day' +%F`
#获取 00:00 时间戳
start_date_unix=`date -d "$do_date 08:00:00" +%s`
start_date=$(($start_date_unix*1000))
#获取 24:00 的时间戳
stop_date=$(($start_date+86400000))
curl -X PUT -H "Authorization: Basic QURNSU46S1lMSU4="
-H 'Content-Type: application/json'
-d '{"startTime":'$start_date',"endTime":'$stop_date', "buildType":"BUILD"}'
http://hadoop102:7070/kylin/api/cubes/$cube_name/build“QURNSU46S1lMSU4=”是 “ADMIN:KYLIN”的base64编码
#! /bin/bash
# cubeName cube的名称
# endTime 执行build cube的结束时间
# (命令传给Kylin的kylinEndTime = realEndTime + (8小时,转化为毫秒)。
# 只需要给Kylin传入build cube的结束时间即可。)
# buildType BUILD 构建cube操作(还有Refresh、Merge等操作,增量构建为BUILD)
kylinMinusTime=$((8 * 60 * 60 * 1000)) #8小时对应的毫秒时间,这里是UTC时间,需要加8个小时
#today=`date -d now +%Y-%m-%d`
today="2020-11-14"
todayTimeStamp=`date -d "$today 00:00:00" +%s`
errorTimeStamp=`date "+%N"`
res=`echo $errorTimeStamp |grep '^0'`
if [ -z $res ];then
echo $res
else
errorTimeStamp=`echo $errorTimeStamp |cut -c2-10`
fi
todayTimeStampMs=$(($todayTimeStamp*1000 + $errorTimeStamp/1000000)) #将current转换为时间戳,精确到毫秒
endTime=$(($todayTimeStampMs + $kylinMinusTime))
cubeName=xxx_cube
curl -X PUT -H "Authorization: Basic QURNSU46S1lMSU4=" -H 'Content-Type: application/json' -d '{"endTime":'$endTime', "buildType":"BUILD"}' http://ip:7070/kylin/api/cubes/$cubeName/rebuild1、调度cube任务的关键元数据配置:
{"startTime":"2019-02-01", // 构建cube的数据起始时间
"endTime":"2019-02-02", // 构建cube的数据结束时间
"buildType":"BUILD", // 构建类型:BUILD|MERGE|REFRESH
"cube":"KYLIN_HIVE_METRICS_JOB_QA" // CUBE名
#可选
"project":"test_project",
"cubeName":"test_cube5",
"cubeDescData":”cube描述的字符串”
}
注意事项:经过RESTful API向kylin进行build和rebuild的时候必定要观察kylin的web界面下面的Montior进程,否知一不当心运行太多进程致使服务器崩掉。
3.2、kylin使用Restful API 创建 cube和model
公司最近需要自动化创建kylin cube和model,便不得不放弃使用web端的方式,而用REST API的方式,找了各种方案,终于找到了可行的。大家可能会问道,代码中定义的cubeDescData 字符串是从哪取的,你可以在web端在创建model和cube时按下F12,查看rest的request请求json串,然后,需要稍微改一下变成我下面代码中这种即可。数据使用的是kylin官方自带的sales数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
public class KylinRestAPI2 {
public static void main(String[] args) {
try {
createModel();
System.out.println("创建model中.....");
Thread.sleep(10000);
createCube();
System.out.println("创建cube中.....");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private static final String baseURL = "http://192.168.xxx.xxx:7070/kylin/api";
public static String createCube() {
String method = "POST";
String para = "/cubes";
String cubeDescData = "{\"name\":\"cube_test\",\"model_name\":\"model_test\",\"description\":\"\",\"dimensions\":" +
"[ {\"name\":\"TRANS_ID\",\"table\": \"KYLIN_SALES\",\"column\": \"TRANS_ID\" }, {\"name\": \"PART_DT\",\"table\": " +
"\"KYLIN_SALES\",\"column\":\"PART_DT\"},{\"name\":\"LSTG_FORMAT_NAME\",\"table\":\"KYLIN_SALES\",\"column\":" +
"\"LSTG_FORMAT_NAME\"},{\"name\":\"CAL_DT\",\"table\":\"KYLIN_CAL_DT\",\"derived\":[\"CAL_DT\"]},{\"name\":" +
"\"YEAR_BEG_DT\",\"table\":\"KYLIN_CAL_DT\",\"derived\":[\"YEAR_BEG_DT\"]},{\"name\":\"QTR_BEG_DT\",\"table\":" +
"\"KYLIN_CAL_DT\",\"derived\":[\"QTR_BEG_DT\"]}],\"measures\":[{\"name\":\"_COUNT_\",\"function\":{\"expression\":" +
"\"COUNT\",\"returntype\":\"bigint\",\"parameter\":{\"type\":\"constant\",\"value\":\"1\"},\"configuration\":{}}}]," +
"\"dictionaries\":[],\"rowkey\":{\"rowkey_columns\":[{\"column\":\"KYLIN_SALES.TRANS_ID\",\"encoding\":\"dict\",\"isShardBy\":" +
"\"false\",\"encoding_version\":1},{\"column\":\"KYLIN_SALES.PART_DT\",\"encoding\":\"dict\",\"isShardBy\":\"false\"," +
"\"encoding_version\":1},{\"column\":\"KYLIN_SALES.LSTG_FORMAT_NAME\",\"encoding\":\"dict\",\"isShardBy\":\"false\"," +
"\"encoding_version\":1}]},\"aggregation_groups\":[{\"includes\":[\"KYLIN_SALES.TRANS_ID\",\"KYLIN_SALES.PART_DT\"," +
"\"KYLIN_SALES.LSTG_FORMAT_NAME\"],\"select_rule\":{\"hierarchy_dims\":[],\"mandatory_dims\":[],\"joint_dims\":[]}}]," +
"\"partition_date_start\":0,\"notify_list\":[],\"hbase_mapping\":{\"column_family\":[{\"name\":\"F1\",\"columns\":" +
"[{\"qualifier\":\"M\",\"measure_refs\":[\"_COUNT_\"]}]}]},\"retention_range\":\"0\",\"status_need_notify\":" +
"[\"ERROR\",\"DISCARDED\",\"SUCCEED\"],\"auto_merge_time_ranges\":[],\"engine_type\":2,\"storage_type\":2,\"override_kylin_properties\":{}}";
cubeDescData = cubeDescData.replaceAll("\"", "\\\\\"");
cubeDescData = cubeDescData.replaceAll("[\r\n]", "");
cubeDescData = cubeDescData.trim();
String body = "{" + "\"cubeDescData\":" + "\"" + cubeDescData + "\"" +
",\"cubeName\" : \"cube_test\"" +
",\"project\" : \"kylin_test\"" +
"}";
return excute(para, method, body);
}
public static String createModel() {
String method = "POST";
String para = "/models";
String modelDescData = "{\"name\": \"model_test\", \"description\": \"\",\"fact_table\": \"DEFAULT.KYLIN_SALES\",\"lookups\": [{\"table\": " +
"\"DEFAULT.KYLIN_CAL_DT\",\"alias\": \"KYLIN_CAL_DT\",\"joinTable\": \"KYLIN_SALES\",\"kind\": \"LOOKUP\",\"join\": " +
"{\"type\": \"inner\",\"primary_key\": [\"KYLIN_CAL_DT.CAL_DT\"],\"foreign_key\": [" +
"\"KYLIN_SALES.PART_DT\"],\"isCompatible\": [true],\"pk_type\": [\"date\"]," +
"\"fk_type\": [\"date\"]}}],\"filter_condition\": \"\",\"dimensions\": [{\"table\": \"KYLIN_SALES\"," +
"\"columns\": [\"TRANS_ID\",\"PART_DT\",\"LSTG_FORMAT_NAME\"]},{\"table\": \"KYLIN_CAL_DT\"," +
"\"columns\": [\"YEAR_BEG_DT\",\"QTR_BEG_DT\",\"CAL_DT\"]}],\"metrics\": [],\"partition_desc\": { " +
" \"partition_type\": \"APPEND\",\"partition_date_format\": \"yyyy-MM-dd\"},\"last_modified\": 0}";
modelDescData = modelDescData.replaceAll("\"", "\\\\\"");
modelDescData = modelDescData.replaceAll("[\r\n]", " ");
modelDescData = modelDescData.trim();
String body = "{" + "\"modelDescData\":" + "\"" + modelDescData + "\"" +
",\"modelName\" : \"model_test\"" +
",\"project\" : \"kylin_test\"" +
"}";
return excute(para, method, body);
}
private static String excute(String para, String method, String body) {
StringBuilder out = new StringBuilder();
try {
URL url = new URL(baseURL + para);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod(method);
connection.setDoOutput(true);
connection.setRequestProperty("Authorization", "Basic QURNSU46S1lMSU4=");
connection.setRequestProperty("Content-Type", "application/json");
if (body != null) {
byte[] outputInBytes = body.getBytes("UTF-8");
OutputStream os = connection.getOutputStream();
os.write(outputInBytes);
os.close();
}
InputStream content = (InputStream) connection.getInputStream();
BufferedReader in = new BufferedReader(new InputStreamReader(content));
String line;
while ((line = in.readLine()) != null) {
out.append(line);
}
in.close();
connection.disconnect();
} catch (Exception e) {
e.printStackTrace();
}
return out.toString();
}
}
四、Kylin Cube 构建原理
2.4.1 维度和度量
维度:即观察数据的角度。比如员工数据,可以从性别角度来分析,也可以更加细化,从入职时间或者地区的维度来观察。维度是一组离散的值,比如说性别中的男和女,或者时间维度上的每一个独立的日期。因此在统计时可以将维度值相同的记录聚合在一起,然后应用聚合函数做累加、平均、最大和最小值等聚合计算。
度量:即被聚合(观察)的统计值,也就是聚合运算的结果。比如说员工数据中不同性别员工的人数,又或者说在同一年入职的员工有多少。
2.4.2 Cube 和 和 Cuboid
有了维度跟度量,一个数据表或者数据模型上的所有字段就可以分类了,它们要么是维度,要么是度量(可以被聚合)。于是就有了根据维度和度量做预计算的 Cube 理论。给定一个数据模型,我们可以对其上的所有维度进行聚合,对于 N 个维度来说,组合`的所有可能性共有 2 n 种。对于每一种维度的组合,将度量值做聚合计算,然后将结果保存为一个物化视图,称为 Cuboid。所有维度组合的 Cuboid 作为一个整体,称为 Cube。
下面举一个简单的例子说明,假设有一个电商的销售数据集,其中维度包括时间[time]、商品[item]、地区[location]和供应商[supplier],度量为销售额。那么所有维度的组合就有 2 4 =16 种,如下图所示:
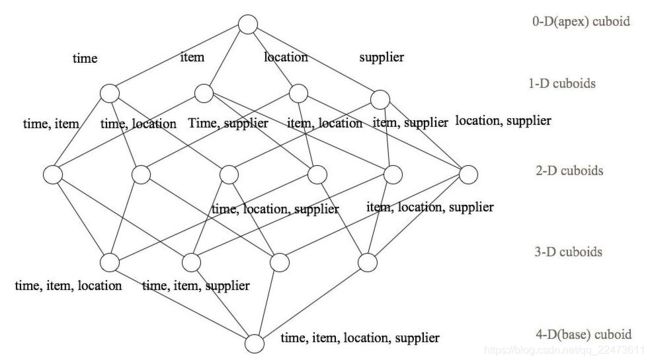
一维度(1D)的组合有:[time]、[item]、[location]和[supplier] 4 种
二维度(2D)的组合有:[time, item]、[time, location]、[time, supplier]、[item, location]、
[item, supplier]、[location, supplier]3 种;
三维度(3D)的组合也有 4 种;
最后还有零维度(0D)和四维度(4D)各有一种,总共 16 种。
注意:每一种维度组合就是一个 Cuboid,16 个 Cuboid 整体就是一个 Cube。
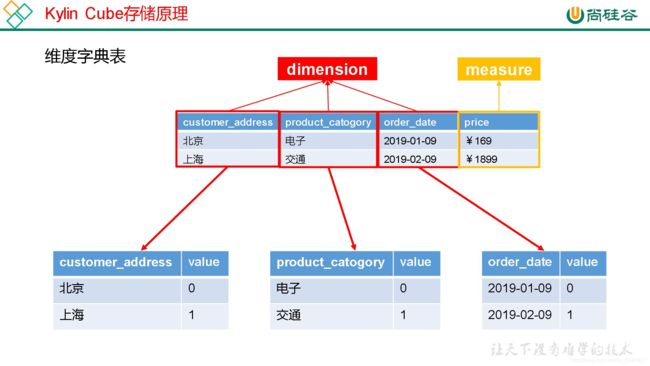
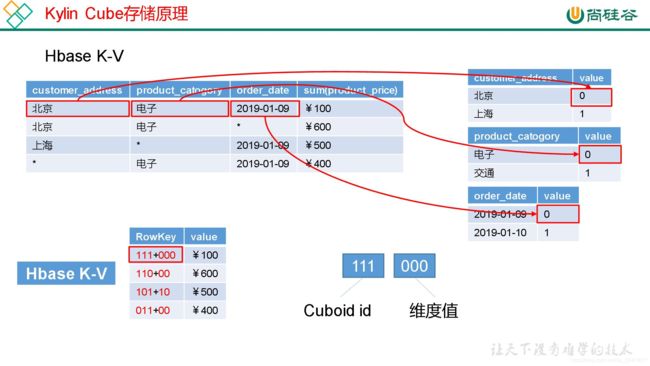
2.4.4 Cube 存储原理
2.4.3 Cube 构建算法
1、 快速构建算法(inmem)
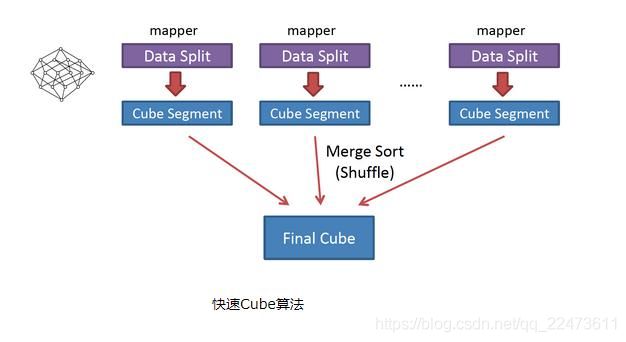
也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法,从 1.5.x 开始引入该算法,该算
法的主要思想是,每个 Mapper 将其所分配到的数据块,计算成一个完整的小 Cube 段(包
含所有 Cuboid)。每个 Mapper 将计算完的 Cube 段输出给 Reducer 做合并,生成大 Cube,
也就是最终结果。如图所示解释了此流程。
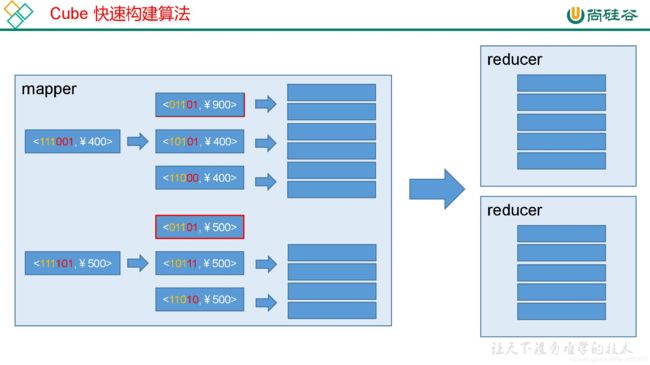
与旧算法相比,快速算法主要有两点不同:
1) Mapper 会利用内存做预聚合,算出所有组合;Mapper 输出的每个 Key 都是不同的,
这样会减少输出到 Hadoop MapReduce 的数据量,Combiner 也不再需要;
2)一轮 MapReduce 便会完成所有层次的计算,减少 Hadoop 任务的调配。
5 Kylin Cube 构建优化
1 使用衍生维度(derived dimension)
2 使用聚合组(Aggregation group)
3 Row Key 优化

2 )基数大的维度放在基数小的维度前边
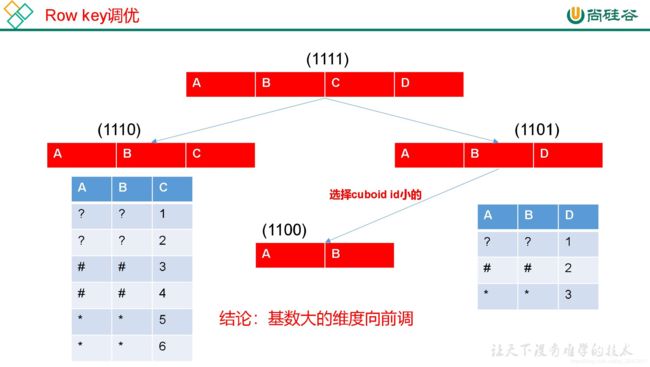 4 并发粒度优化(分区)
4 并发粒度优化(分区)
当 Segment 中某一个 Cuboid 的大小超出一定的阈值时,系统会将该 Cuboid 的数据分片到多个分区中,以实现 Cuboid 数据读取的并行化,从而优化 Cube 的查询速度。具体的实现方式如下:构建引擎根据 Segment 估计的大小,以及参数“kylin.hbase.region.cut”的设置决定 Segment 在存储引擎中总共需要几个分区来存储,如果存储引擎是 HBase,那么分区的数量就对应于 HBase 中的 Region 数量。kylin.hbase.region.cut 的默认值是 5.0,单位是 GB,也就是说对于一个大小估计是 50GB 的 Segment,构建引擎会给它分配 10 个分区。用户还可以通过设置 kylin.hbase.region.count.min(默认为 1)和 kylin.hbase.region.count.max(默认为500)两个配置来决定每个 Segment 最少或最多被划分成多少个分区
由于每个 Cube 的并发粒度控制不尽相同,因此建议在 Cube Designer 的 ConfigurationOverwrites(上图所示)中为每个 Cube 量身定制控制并发粒度的参数。假设将把当前 Cube的 kylin.hbase.region.count.min 设置为 2,kylin.hbase.region.count.max 设置为 100。这样无论Segment 的大小如何变化,它的分区数量最小都不会低于 2,最大都不会超过 100。相应地,这个 Segment 背后的存储引擎(HBase)为了存储这个 Segment,也不会使用小于两个或超过 100 个的分区。我们还调整了默认的 kylin.hbase.region.cut,这样 50GB 的 Segment 基本上会被分配到 50 个分区,相比默认设置,我们的 Cuboid 可能最多会获得 5 倍的并发量
六、Kylin BI 工具集成
可以与 Kylin 结合使用的可视化工具很多,例如:
ODBC:与 Tableau、Excel、PowerBI 等工具集成
JDBC:与 Saiku、BIRT 等 Java 工具集成
RestAPI:与 JavaScript、Web 网页集成
Kylin 开发团队还贡献了 Zepplin 的插件,也可以使用 Zepplin 来访问 Kylin 服务。
1 JDBC
org.apache.kylin
kylin-jdbc
2.5.1
public class TestKylin {
public static void main(String[] args) throws Exception {
//Kylin_JDBC 驱动
String KYLIN_DRIVER = "org.apache.kylin.jdbc.Driver";
//Kylin_URL
String KYLIN_URL = "jdbc:kylin://hadoop102:7070/FirstProject";
//Kylin 的用户名
String KYLIN_USER = "ADMIN";
//Kylin 的密码
String KYLIN_PASSWD = "KYLIN";
//添加驱动信息
Class.forName(KYLIN_DRIVER);
//获取连接
Connection connection = DriverManager.getConnection(KYLIN_URL, KYLIN_USER, KYLIN_PASSWD);
//预编译 SQL
PreparedStatement ps = connection.prepareStatement("SELECT
sum(sal) FROM emp group by deptno");
//执行查询
ResultSet resultSet = ps.executeQuery();
//遍历打印
while (resultSet.next()) {
System.out.println(resultSet.getInt(1));
}
}
}
2、JDBC RESTFUL API
public class kylinPost {
private String encoding = "UTF-8";
static String ACCOUNT = "ADMIN";
static String PWD = "KYLIN";
/**
* 使用httpcline 进行post访问
* @throws IOException
*/
public void requestByPostMethod() throws IOException{
CloseableHttpClient httpClient = this.getHttpClient();
try {
//创建post方式请求对象
String url ="http://10.104.111.36:7070/kylin/api/query";
HttpPost httpPost = new HttpPost(url);
//,max(a.price) as max_price,count(*) as cnt
String sql = "select a.part_dt ,sum(a.price) as sum_price,count(distinct a.seller_id) as sellerid,count(*) as cnt from kylin_sales a "
+ " inner join kylin_cal_dt b on a.part_dt = b.cal_dt "
+ " inner join kylin_category_groupings c on a.lstg_site_id = c.site_id and a.leaf_categ_id = c.leaf_categ_id "
+ " group by a.part_dt ;";
// 接收参数json列表 (kylin 只接受json格式数据)
JSONObject jsonParam = new JSONObject();
jsonParam.put("sql", sql);
jsonParam.put("limit", "20");
jsonParam.put("project","learn_kylin");
StringEntity sentity = new StringEntity(jsonParam.toString(),encoding);//解决中文乱码问题
sentity.setContentEncoding(encoding);
sentity.setContentType("application/json");
httpPost.setEntity(sentity);
//设置header信息
//指定报文头【Content-type】、【User-Agent】
httpPost.setHeader("Content-type", "application/json;charset=utf-8");
httpPost.setHeader("Authorization", this.authCode());//
System.out.println("POST 请求...." + httpPost.getURI());
//执行请求
CloseableHttpResponse httpResponse = httpClient.execute(httpPost);
try{
HttpEntity entity = httpResponse.getEntity();
if (null != entity){
//按指定编码转换结果实体为String类型
String body = EntityUtils.toString(entity, encoding);
JSONObject obj = JSONObject.fromObject(body);
System.out.println(body);
System.out.println(obj.get("results"));
}
} finally{
httpResponse.close();
}
} catch( UnsupportedEncodingException e){
e.printStackTrace();
}
catch (IOException e) {
e.printStackTrace();
}finally{
this.closeHttpClient(httpClient);
} }
/**
* kylin 是base64加密的,访问时候需要加上加密码
* @return
*/
private String authCode(){
String auth = ACCOUNT + ":" + PWD;
String code = "Basic "+new String(new Base64().encode(auth.getBytes()));
return code;
}
/**
* 创建httpclient对象
* @return
*/
private CloseableHttpClient getHttpClient(){
return HttpClients.createDefault();
}
/**
* 关闭链接
* @param client
* @throws IOException
*/
private void closeHttpClient(CloseableHttpClient client) throws IOException{
if (client != null){
client.close();
}
}
public static void main(String[] args) throws IOException{
kylinPost ky = new kylinPost();
ky.requestByPostMethod();
}
}}2 Zepplin
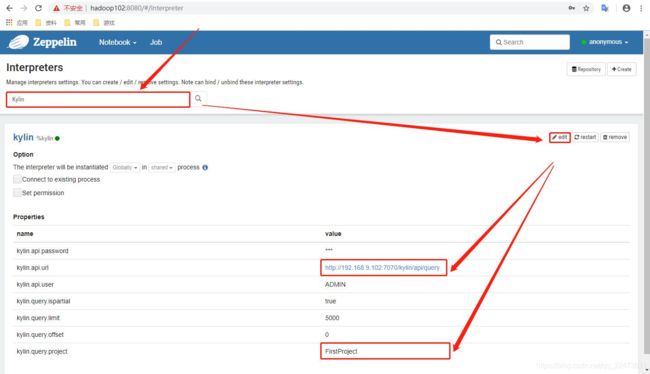
可登录网页查看,web 默认端口号为 8080
配置 Zepplin 支持 Kylin
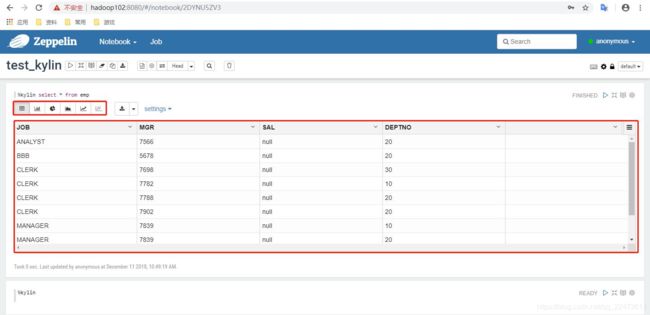
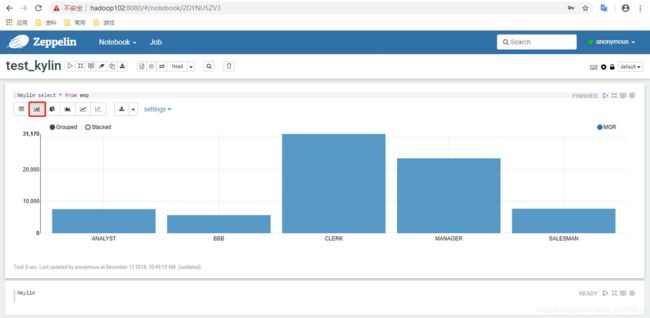
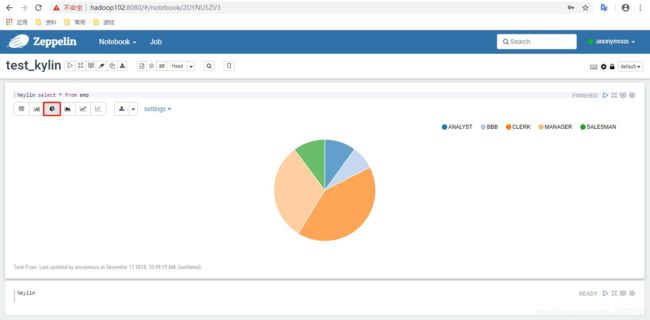
查询员工详细信息,并使用各种图表进行展示
3)执行查询
 4)结果展示
4)结果展示
六、Kylin 和 ClickHouse区别
OLAP到现在也都是两个套路:一个用空间换时间,一个充分利用所有资源快速计算。
前者就是MOLAP(多维在线分析),后者就是ROLAP(关系型在线分析),当然还有一个混合的,那个不管。
Kylin和Druid都是MOLAP的典范,ClickHouse则是ROLAP的佼佼者。kudu是一个支持OLAP的大数据存储引擎,也能用来做OLAP。
相同点: Kylin 和 ClickHouse 都能通过 SQL 的方式在 PB 数据量级下,亚秒级(95%查询 2s内返回)返回 OLAP(在线分析查询) 查询结果
不同应用场景:
Kylin 适合高并发,固定模式查询场景,例如: 报表分析,留存分析,用户标签画像分析,用户行为漏斗分析,归因分析等.
ClickHouse 适合低并发,灵活即席查询场景,也支持例如:报表分析,留存分析,用户标签画像分析,用户行为漏斗分析,归因分析等.
如果你的业务部门要求高并发高性能,那就可以用Kylin和Druid,这两个都是预计算的套路,你给他设定好分析路线,kylin建CUBE,Druid做各种group by的计算,业务部门分析的时候就等于是直接查询已经计算好的结果。速度和并发量的表现都非常棒。缺点是吃存储,分析路径比较死,加一个维度得改模型。
如果你的业务部门人不多,就内部用,但是比较挑剔,要非常高的自由度,那就可以用ClickHouse。这个你建各种表就好了。业务部门基于数据关系自己选择,CK现算,给答案。这个单表查询效率超高,join的话不太满意。而且因为都是现算的,并发量上不去。最关键的是CK所在的服务器基本干不了别的,查几条数据都有可能吃掉50%以上的CPU。
原理不同:
Kylin 是基于Hadoop平台,通过预计算, 通过定义cube模型,将结果预计算保存,之后当 SQL 请求过来直接可以以查表的方式获取结果, 使用预计算的一个形象的类比就是 九九乘法表, 大家都知道,乘法是加法的简化版本, 如果你背熟了九九乘法表, 下一次做乘法的时候,就可以直接得到结果. kylin 就是一个帮你记住 "九九乘法表" 的工具, 让你在使用 SQL 查询的时候,能够直接拿到结果,能够在O(1) 复杂度下得到计算结果.
ClickHouse 是 MPP 架构的列式存储 RDBMS (关系型数据库),通过极致使用 CPU 的性能达到高性能的 OLAP 分析.