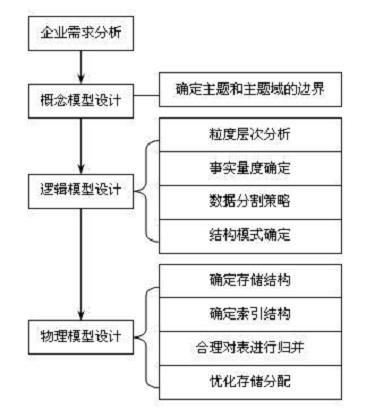
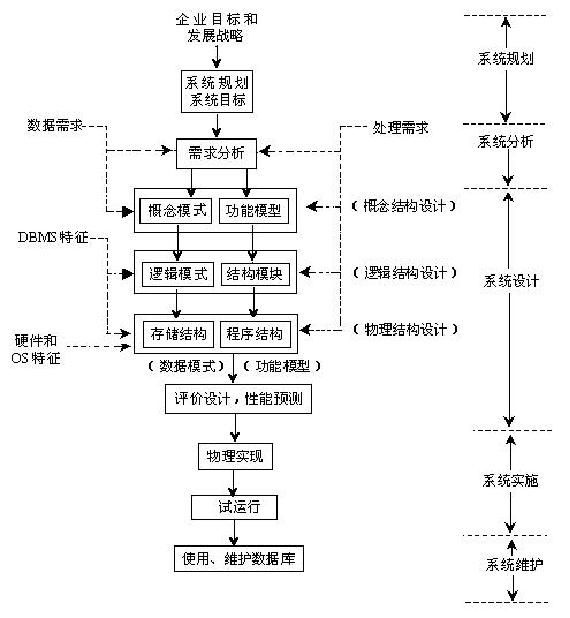
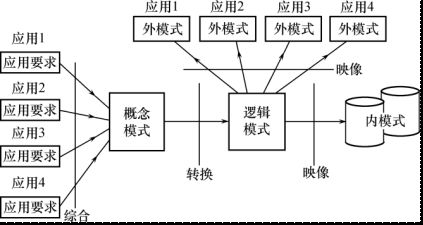
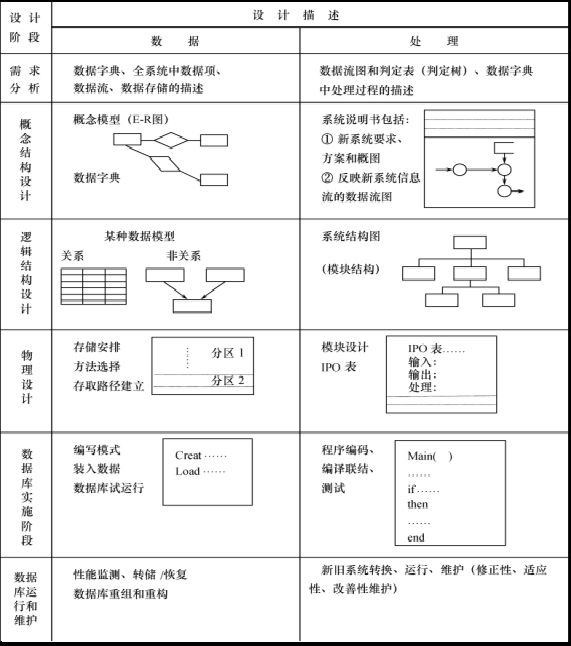
- java技术专家 【数据库专题】【关系型数据库(mysql)-- MySQL体系架构】
不走小道
Java技术专家数据库javamysql
文章目录1.MySQL体系架构1.1.MySQL的分支与变种1.1.1.Drizzle1.1.2.MariaDB1.1.3.PerconaServer1.2.MySQL的替代1.2.1.PostgreSQL1.2.2.SQLite2.MySql基础2.1.MySQL体系架构2.1.1.连接层2.1.2.Server层(SQL处理层)2.1.2.1.缓存(了解即可)
- 数据库专题 神州通用数据库适配基础适配问题
极光雨雨
数据库数据库
数据库链接spring.datasource.driver-class-name=com.oscar.Driverspring.datasource.url=jdbc:oscar://192.168.***.***:2004/dbnamespring.datasource.username=testspring.datasource.password=testpagehelper.helper-d
- 数据库专题 to_number()函数创建,nvl()函数创建还原
极光雨雨
数据库sql
to_number()(psql)使用sql输入并执行创建CREATEORREPLACEFUNCTIONpublic.to_number(inputcharactervarying)RETURNSnumericLANGUAGEplpgsqlAS$function$BEGINRETURNCAST(inputasNUMERIC);END$function$;nvl()(psql)类似于java方法重载
- Mongo
錦魚
q启动mongo展示db查看showdbs使用或创建use查看数据库专题db.stats()查看数据库下集合数showcollections删除数据库db.dropdatabase()创建集合db.create删除集合db.集合名.drop()添加数据insert(键:值,desc:'描述内容')添加多个insert([信息],[信息],[信息],[信息])查询db.set.find()db.se
- 数据库专题训练大作业 互联网出行
wenj1997
问题描述给定10w辆出租车的经纬度和车厢乘客终点,并给定一个乘客的起止位置,找出绕路不超过10km且距离乘客不超过10km的最多五辆车。方法实现分成三步:预处理阶段:预处理出一辆车上任意两人距离,以及每辆车将乘客依次送达目的地的路程D1;遍历出租车,筛去离乘客距离超过10km的出租车;剩下的出租车,计算接乘客路程D2,、接到乘客后依次送达的距离D3、待接乘客离自己目的地的最短距离D4。然后计算绕路
- [Golang数据库专题2]Golang操作Mysql进行增删改查
风间净琉璃
golang语言编程系列mysql数据库sql
目录一、驱动介绍二、go-sql-driver/mysql介绍与应用2.1采用理由2.2实践与应用建表语句增删改查运行结果三、补充说明3.1sql.Open函数3.2db.Prepare()函数3.3db.Query()函数3.4stmt.Exec()一、驱动介绍目前Go语言中支持MySQL的驱动较多,部分是支持database/sql标准,部分是采用自己实现的接口。常用的驱动有如下几种:GitH
- 数据库专题 一次性写入大量数据解决方案浅析以及大量数据对数据库性能影响的学习总结
极光雨雨
数据库数据库database
原因以Mysql为例插入大量数据导致越来越慢甚至崩溃越来越慢说明执行当前的操作可能已经占用了你大量的内存,数据库本身执行操作越来越费力,电脑是在被搞得太忙了处理的事情太多,几乎处理不过来了,这个时候显然如果能释放不需要的内存资源,或者提高数据库本身处理数据的性能自然是最有效的提升方式。大批量的数据操作一方面是我们的代码对数据库数据的操作逻辑有直接的影响,因为我们直接决定了数据库操作数据的方式。一方
- 数据库专题 链接各种数据库的可视化工具,方便操作
极光雨雨
数据库可视化数据库
可视化工具一直在cmd中操作数据库和软件显然并不合适,可能有些人比较习惯于命令行操作,但是有了可视化工具的话,看起来就更方便一些,同时也不需要看个表都要写SQL语句。目前我所知道的比较常用的数据库可视化工具有如下几种:1.NavicatPremium可以直接搜到官方的下载包,是相当好用的,目前我主要用的也是这个,大部分数据库都可以链接上2.Sqlyog有看到一些前辈在用,可视化工具其实界面和使用方
- 数据库专题 MySQL SQL练习综合使用,聚合函数 + 完整案例
极光雨雨
数据库数据库mysqlsql
数据库表创建以及数据准备CREATETABLEDEPT(DEPTNOINT(2)NOTNULL,DNAMEVARCHAR(14),LOCVARCHAR(13),PRIMARYKEY(DEPTNO));CREATETABLEEMP(EMPNOINT(4)NOTNULL,ENAMEVARCHAR(10),JOBVARCHAR(9),MGRINT(4),HIREDATEDATEDEFAULTNULL,S
- 数据库专题 数据库适配--瀚高数据库4.3-4.5.5适配基本适配问题
极光雨雨
数据库数据库
数据库链接配置均已springboot配置文件说明,内容基本一致4.3.x版本spring.datasource.driver-class-name=org.postgresql.Driverspring.datasource.url=jdbc:postgresql://192.168.***.***:5866/dbnamespring.datasource.username=highgospri
- [Golang数据库专题4]Golang语言操作PostgreSQL进行增删改查
风间净琉璃
golang语言编程系列数据库postgresqlgolang
目录一、引言1.1PostgreSQL与MYSQL1.2Golang支持PostgreSQl驱动二、编码实践2.1建表语句2.2CRUD代码2.3验证结果三、结语一、引言1.1PostgreSQL与MYSQLPostgreSQl是一个自由的对象——关系型数据库服务器(数据库管理系统)。同时,它也是除了开源数据库系统(如Mysql和Firebird)和专有系统(如Oracle、Sybase、IBM的
- ArcGIS、ENVI、InVEST、FRAGSTATS技术教程
asyxchenchong888
土地利用生态arcgis
专题一空间数据获取与制图1.1软件安装与应用讲解1.2空间数据介绍1.3海量空间数据下载1.4ArcGIS软件快速入门1.5Geodatabase地理数据库专题二ArcGIS专题地图制作2.1专题地图制作规范2.2空间数据的准备与处理2.3空间数据可视化:地图符号与注记2.4研究区示意图制作2.5专题地图绘制与效果提升2.6空间底图的绘制专题三空间数据采集与处理3.1地图地理配准与数字化3.2空间
- ArcGIS、ENVI、InVEST、FRAGSTATS技术教程
Teacher.chenchong
生态arcgis
专题一空间数据获取与制图1.1软件安装与应用讲解1.2空间数据介绍1.3海量空间数据下载1.4ArcGIS软件快速入门1.5Geodatabase地理数据库专题二ArcGIS专题地图制作2.1专题地图制作规范2.2空间数据的准备与处理2.3空间数据可视化:地图符号与注记2.4研究区示意图制作2.5专题地图绘制与效果提升2.6空间底图的绘制专题三空间数据采集与处理3.1地图地理配准与数字化3.2空间
- 如何提升环境、生态、水文、土地、土壤、农业、大气等领域的数据分析能力
思考的小猴子
生态水文环境信息可视化ArcGISENVIInVEST
专题一、空间数据获取与制图1.1软件安装与应用讲解1.2空间数据介绍1.3海量空间数据下载1.4ArcGIS软件快速入门1.5Geodatabase地理数据库专题二、ArcGIS专题地图制作2.1专题地图制作规范2.2空间数据的准备与处理2.3空间数据可视化:地图符号与注记2.4研究区示意图制作2.5专题地图绘制与效果提升2.6空间底图的绘制专题三、空间数据采集与处理3.1地图地理配准与数字化3.
- 基于ArcGIS、ENVI、InVEST、FRAGSTATS等多技术融合提升
高-老师
ENVI景观格局空间分析温室气体数据处理
时间、地点7月22日-28日【乌鲁木齐】8月12日-18日【福建*泉州】专题一空间数据获取与制图1.1软件安装与应用讲解1.2空间数据介绍1.3海量空间数据下载1.4ArcGIS软件快速入门1.5Geodatabase地理数据库专题二ArcGIS专题地图制作2.1专题地图制作规范2.2空间数据的准备与处理2.3空间数据可视化:地图符号与注记2.4研究区示意图制作2.5专题地图绘制与效果提升2.6空
- ArcGIS、ENVI、InVEST、FRAGSTATS等多技术提升数据分析能力
思考的小猴子
水文大气农业ArcGIS生态水文
专题一、空间数据获取与制图1.1软件安装与应用讲解1.2空间数据介绍1.3海量空间数据下载1.4ArcGIS软件快速入门1.5Geodatabase地理数据库专题二、ArcGIS专题地图制作2.1专题地图制作规范2.2空间数据的准备与处理2.3空间数据可视化:地图符号与注记2.4研究区示意图制作2.5专题地图绘制与效果提升2.6空间底图的绘制专题三、空间数据采集与处理3.1地图地理配准与数字化3.
- ArcGIS、ENVI、InVEST、FRAGSTATS等多技术融合提升
asyxchenchong888
生态经验分享
专题一空间数据获取与制图1.1软件安装与应用讲解1.2空间数据介绍1.3海量空间数据下载1.4ArcGIS软件快速入门1.5Geodatabase地理数据库专题二ArcGIS专题地图制作2.1专题地图制作规范2.2空间数据的准备与处理2.3空间数据可视化:地图符号与注记2.4研究区示意图制作2.5专题地图绘制与效果提升2.6空间底图的绘制专题三空间数据采集与处理3.1地图地理配准与数字化3.2空间
- ArcGIS、ENVI、InVEST、FRAGSTATS等多技术融合提升
Teacher.chenchong
生态环境土壤经验分享
专题一空间数据获取与制图1.1软件安装与应用讲解1.2空间数据介绍1.3海量空间数据下载1.4ArcGIS软件快速入门1.5Geodatabase地理数据库专题二ArcGIS专题地图制作2.1专题地图制作规范2.2空间数据的准备与处理2.3空间数据可视化:地图符号与注记2.4研究区示意图制作2.5专题地图绘制与效果提升2.6空间底图的绘制专题三空间数据采集与处理3.1地图地理配准与数字化3.2空间
- ArcGIS、ENVI、InVEST、FRAGSTATS等多技术融合提升环境、生态、水文、土地、土壤、农业、大气等领域
思考的小猴子
arcgis水文土壤大气农业
专题一、空间数据获取与制图1.1软件安装与应用讲解1.2空间数据介绍1.3海量空间数据下载1.4ArcGIS软件快速入门1.5Geodatabase地理数据库专题二、ArcGIS专题地图制作2.1专题地图制作规范2.2空间数据的准备与处理2.3空间数据可视化:地图符号与注记2.4研究区示意图制作2.5专题地图绘制与效果提升2.6空间底图的绘制专题三、空间数据采集与处理3.1地图地理配准与数字化3.
- 【无标题】
Teacher.chenchong
生态生态环境经验分享
专题一空间数据获取与制图1.1软件安装与应用讲解1.2空间数据介绍1.3海量空间数据下载1.4ArcGIS软件快速入门1.5Geodatabase地理数据库专题二ArcGIS专题地图制作2.1专题地图制作规范2.2空间数据的准备与处理2.3空间数据可视化:地图符号与注记2.4研究区示意图制作2.5专题地图绘制与效果提升2.6空间底图的绘制专题三空间数据采集与处理3.1地图地理配准与数字化3.2空间
- 基于ArcGIS、ENVI、InVEST、FRAGSTATS等多技术融合提升
cyd20161117
生态arcgis经验分享
专题一空间数据获取与制图1.1软件安装与应用讲解1.2空间数据介绍1.3海量空间数据下载1.4ArcGIS软件快速入门1.5Geodatabase地理数据库专题二ArcGIS专题地图制作2.1专题地图制作规范2.2空间数据的准备与处理2.3空间数据可视化:地图符号与注记2.4研究区示意图制作2.5专题地图绘制与效果提升2.6空间底图的绘制专题三空间数据采集与处理3.1地图地理配准与数字化3.2空间
- 基于ArcGIS、ENVI、InVEST、FRAGSTATS等多技术融合提升环境、生态、水文、土地、土壤、农业、大气等领域应用
Mr.靳靳477302280
arcgis土地利用土壤水文遥感
【自选】时间地点:2023年7月22日-28日【乌鲁木齐】时间地点:2023年8月12日-18日【福建泉州】【六天实践教学、提供全部资料】专题一、空间数据获取与制图1.1软件安装与应用讲解1.2空间数据介绍1.3海量空间数据下载1.4ArcGIS软件快速入门1.5Geodatabase地理数据库专题二、ArcGIS专题地图制作2.1专题地图制作规范2.2空间数据的准备与处理2.3空间数据可视化:地
- 速成Spring Boot:#3 创建Layers(2) : Data Access Layer
哈利宇轩张
javamysqlspring数据库springboot
源码链接,建议使用VSCode的Gitlens或其它可视化软件(如SourceTree)查看GitLog,有助于理解说明三秋的数据库、LeetCode数据库专题都是用MySQL,干脆直接一周速成MySQL拿来用吧(•̀ω•́)y文档https://spring.io/guides/gs/accessing-data-mysql/关联到本地数据库首先配置src/main/resources/下的ap
- 我与阿里巴巴集团副总裁、阿里云智能数据库事业部总负责人在阿里云官网同框啦
冰 河
程序人生数据库阿里云云计算程序人生程序员
大家好,我是冰河~~今天周末,就暂时不发技术文章了。今天为大家分享一个对我个人来说,比较高兴的事情,就是我成为阿里云“大咖答”栏目下数据库专题的荣誉版主啦。其实,更令我自豪的是我很荣幸与ACM杰出科学家,阿里巴巴集团副总裁、阿里云智能数据库事业部总负责人、达摩院数据库与存储实验室负责人飞刀大神在阿里云官网同框啦!哈哈,看下图。PS:我的照片是十级美颜加后期制作的效果,哈哈哈哈。。。注:阿里云官网链
- 【数据库专题】实战演示造成数据库全表扫描的坑
掂掂三生有幸
数据库数据库javamysql索引失效全表扫描
文章目录一创建表1.1我们先创建一张学生表:1.2创建索引二测试编写SQL进行测试2.1整个SQL语句里没用where子句2.2添加where子句本文所有示例都使用的是MySQL和DBeaver。为了直观地认识到哪些写法会容易导致全表扫描,我们这里进行实际操作。每日推荐文章开始之前我想首先介绍一下牛客,以便没有使用过的小伙伴能够快速入手,牛客网是国内最大的算法、面试、招聘网站,涵盖了多种大厂面试真
- 【数据库专题】一文搞懂 B+树凭什么成为关系型数据库索引的主流数据结构
掂掂三生有幸
数据库数据结构数据库b+树mysqlb树
文章目录一、非B+树不可吗?二、二叉树演变B+树过程三、B+树总结四、和B树的关系一、非B+树不可吗?数据库最常用的两个功能就是“等值查询”和“范围查询”。如果只是为了满足“等值查询”,那么Hash散列表和平衡二叉查找树都能胜任数据库索引这个使用场景,但是“范围查询”却加大了难度,使得它们不太适合了。在原先讲过的“跳表”倒是很契合,但实际场景中,大家都是使用的B+树。二、二叉树演变B+树过程二叉树
- 【数据库专题】如何理解数据库的索引?
掂掂三生有幸
数据库数据库b树数据结构mysql索引
文章目录前言一、数据结构二、存储引擎三、建立索引的建议四、附录前言索引是帮助数据库来高效获取数据的一种排好顺序的数据结构;一、数据结构二叉查找树定义:根节点的值大于其左子树中任意一个节点的值,小于其右节点中任意一节点的值;优点:查找指定数据不需要遍历全表,时间效率类似二分查找;缺点:在特殊情况下会退化成链表结构,查找尾部数据需要遍历所有数据;平衡二叉树定义:一种特殊的二叉查找树,它会通过自旋操作来
- 【数据库专题】耀杨:听说DDL想c我?——《狗叫江湖》“第四幕”
跟着耀杨学编程
跟着耀阳精通数据库数据库架构sqlmysql云计算数据仓库
作者简介:东星耀杨,C站煮播之星,【无规则教学】创始人,曾奉太上老君之名下凡,为了给迷途中的兄弟萌指点迷津,帮助兄弟萌早日踏入如我这般境界!世人见我,皆称之“王霸之气侧漏”的男人,哇靠蒸滴c!c了兄弟萌!往期回顾:【数据库专题】智多星带你五分钟攻略“关系代数”——《狗叫江湖》第二幕续集【数据库专题】“第二幕”——《狗叫江湖》之关系数据库(1)“解锁新角色:刘能“【数据库专题】“第一幕”——《狗叫江
- 【数据库专题】DML终极奥义——《狗叫江湖》“第五幕”
跟着耀杨学编程
跟着耀阳精通数据库数据库架构云原生数据库sql其他
作者简介:东星耀杨,C站煮播之星,【无规则教学】创始人,曾奉太上老君之名下凡,为了给迷途中的兄弟萌指点迷津,帮助兄弟萌早日踏入如我这般境界!世人见我,皆称之“王霸之气侧漏”的男人,哇靠蒸滴c!c了兄弟萌!往期回顾:【数据库专题】智多星带你五分钟攻略“关系代数”——《狗叫江湖》第二幕续集【数据库专题】“第二幕”——《狗叫江湖》之关系数据库(1)“解锁新角色:刘能“【数据库专题】“第一幕”——《狗叫江
- 【数据库专题】耀杨初入SQL被DML打断了双腿——《狗叫江湖》“第三幕”
跟着耀杨学编程
跟着耀阳精通数据库数据库sqlmysqlunix系统架构
作者简介:东星耀杨,C站煮播之星,【无规则教学】创始人,曾奉太上老君之名下凡,为了给迷途中的兄弟萌指点迷津,帮助兄弟萌早日踏入如我这般境界!世人见我,皆称之“王霸之气侧漏”的男人,哇靠蒸滴c!c了兄弟萌!往期回顾:【数据库专题】智多星带你五分钟攻略“关系代数”——《狗叫江湖》第二幕续集【数据库专题】“第二幕”——《狗叫江湖》之关系数据库(1)“解锁新角色:刘能“【数据库专题】“第一幕”——《狗叫江
- ztree设置禁用节点
3213213333332132
JavaScriptztreejsonsetDisabledNodeAjax
ztree设置禁用节点的时候注意,当使用ajax后台请求数据,必须要设置为同步获取数据,否者会获取不到节点对象,导致设置禁用没有效果。
$(function(){
showTree();
setDisabledNode();
});
- JVM patch by Taobao
bookjovi
javaHotSpot
在网上无意中看到淘宝提交的hotspot patch,共四个,有意思,记录一下。
7050685:jsdbproc64.sh has a typo in the package name
7058036:FieldsAllocationStyle=2 does not work in 32-bit VM
7060619:C1 should respect inline and
- 将session存储到数据库中
dcj3sjt126com
sqlPHPsession
CREATE TABLE sessions (
id CHAR(32) NOT NULL,
data TEXT,
last_accessed TIMESTAMP NOT NULL,
PRIMARY KEY (id)
);
<?php
/**
* Created by PhpStorm.
* User: michaeldu
* Date
- Vector
171815164
vector
public Vector<CartProduct> delCart(Vector<CartProduct> cart, String id) {
for (int i = 0; i < cart.size(); i++) {
if (cart.get(i).getId().equals(id)) {
cart.remove(i);
- 各连接池配置参数比较
g21121
连接池
排版真心费劲,大家凑合看下吧,见谅~
Druid
DBCP
C3P0
Proxool
数据库用户名称 Username Username User
数据库密码 Password Password Password
驱动名
- [简单]mybatis insert语句添加动态字段
53873039oycg
mybatis
mysql数据库,id自增,配置如下:
<insert id="saveTestTb" useGeneratedKeys="true" keyProperty="id"
parameterType=&
- struts2拦截器配置
云端月影
struts2拦截器
struts2拦截器interceptor的三种配置方法
方法1. 普通配置法
<struts>
<package name="struts2" extends="struts-default">
&
- IE中页面不居中,火狐谷歌等正常
aijuans
IE中页面不居中
问题是首页在火狐、谷歌、所有IE中正常显示,列表页的页面在火狐谷歌中正常,在IE6、7、8中都不中,觉得可能那个地方设置的让IE系列都不认识,仔细查看后发现,列表页中没写HTML模板部分没有添加DTD定义,就是<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3
- String,int,Integer,char 几个类型常见转换
antonyup_2006
htmlsql.net
如何将字串 String 转换成整数 int?
int i = Integer.valueOf(my_str).intValue();
int i=Integer.parseInt(str);
如何将字串 String 转换成Integer ?
Integer integer=Integer.valueOf(str);
如何将整数 int 转换成字串 String ?
1.
- PL/SQL的游标类型
百合不是茶
显示游标(静态游标)隐式游标游标的更新和删除%rowtyperef游标(动态游标)
游标是oracle中的一个结果集,用于存放查询的结果;
PL/SQL中游标的声明;
1,声明游标
2,打开游标(默认是关闭的);
3,提取数据
4,关闭游标
注意的要点:游标必须声明在declare中,使用open打开游标,fetch取游标中的数据,close关闭游标
隐式游标:主要是对DML数据的操作隐
- JUnit4中@AfterClass @BeforeClass @after @before的区别对比
bijian1013
JUnit4单元测试
一.基础知识
JUnit4使用Java5中的注解(annotation),以下是JUnit4常用的几个annotation: @Before:初始化方法 对于每一个测试方法都要执行一次(注意与BeforeClass区别,后者是对于所有方法执行一次)@After:释放资源 对于每一个测试方法都要执行一次(注意与AfterClass区别,后者是对于所有方法执行一次
- 精通Oracle10编程SQL(12)开发包
bijian1013
oracle数据库plsql
/*
*开发包
*包用于逻辑组合相关的PL/SQL类型(例如TABLE类型和RECORD类型)、PL/SQL项(例如游标和游标变量)和PL/SQL子程序(例如过程和函数)
*/
--包用于逻辑组合相关的PL/SQL类型、项和子程序,它由包规范和包体两部分组成
--建立包规范:包规范实际是包与应用程序之间的接口,它用于定义包的公用组件,包括常量、变量、游标、过程和函数等
--在包规
- 【EhCache二】ehcache.xml配置详解
bit1129
ehcache.xml
在ehcache官网上找了多次,终于找到ehcache.xml配置元素和属性的含义说明文档了,这个文档包含在ehcache.xml的注释中!
ehcache.xml : http://ehcache.org/ehcache.xml
ehcache.xsd : http://ehcache.org/ehcache.xsd
ehcache配置文件的根元素是ehcahe
ehcac
- java.lang.ClassNotFoundException: org.springframework.web.context.ContextLoaderL
白糖_
javaeclipsespringtomcatWeb
今天学习spring+cxf的时候遇到一个问题:在web.xml中配置了spring的上下文监听器:
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
随后启动
- angular.element
boyitech
AngularJSAngularJS APIangular.element
angular.element
描述: 包裹着一部分DOM element或者是HTML字符串,把它作为一个jQuery元素来处理。(类似于jQuery的选择器啦) 如果jQuery被引入了,则angular.element就可以看作是jQuery选择器,选择的对象可以使用jQuery的函数;如果jQuery不可用,angular.e
- java-给定两个已排序序列,找出共同的元素。
bylijinnan
java
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class CommonItemInTwoSortedArray {
/**
* 题目:给定两个已排序序列,找出共同的元素。
* 1.定义两个指针分别指向序列的开始。
* 如果指向的两个元素
- sftp 异常,有遇到的吗?求解
Chen.H
javajcraftauthjschjschexception
com.jcraft.jsch.JSchException: Auth cancel
at com.jcraft.jsch.Session.connect(Session.java:460)
at com.jcraft.jsch.Session.connect(Session.java:154)
at cn.vivame.util.ftp.SftpServerAccess.connec
- [生物智能与人工智能]神经元中的电化学结构代表什么?
comsci
人工智能
我这里做一个大胆的猜想,生物神经网络中的神经元中包含着一些化学和类似电路的结构,这些结构通常用来扮演类似我们在拓扑分析系统中的节点嵌入方程一样,使得我们的神经网络产生智能判断的能力,而这些嵌入到节点中的方程同时也扮演着"经验"的角色....
我们可以尝试一下...在某些神经
- 通过LAC和CID获取经纬度信息
dai_lm
laccid
方法1:
用浏览器打开http://www.minigps.net/cellsearch.html,然后输入lac和cid信息(mcc和mnc可以填0),如果数据正确就可以获得相应的经纬度
方法2:
发送HTTP请求到http://www.open-electronics.org/celltrack/cell.php?hex=0&lac=<lac>&cid=&
- JAVA的困难分析
datamachine
java
前段时间转了一篇SQL的文章(http://datamachine.iteye.com/blog/1971896),文章不复杂,但思想深刻,就顺便思考了一下java的不足,当砖头丢出来,希望引点和田玉。
-----------------------------------------------------------------------------------------
- 小学5年级英语单词背诵第二课
dcj3sjt126com
englishword
money 钱
paper 纸
speak 讲,说
tell 告诉
remember 记得,想起
knock 敲,击,打
question 问题
number 数字,号码
learn 学会,学习
street 街道
carry 搬运,携带
send 发送,邮寄,发射
must 必须
light 灯,光线,轻的
front
- linux下面没有tree命令
dcj3sjt126com
linux
centos p安装
yum -y install tree
mac os安装
brew install tree
首先来看tree的用法
tree 中文解释:tree
功能说明:以树状图列出目录的内容。
语 法:tree [-aACdDfFgilnNpqstux][-I <范本样式>][-P <范本样式
- Map迭代方式,Map迭代,Map循环
蕃薯耀
Map循环Map迭代Map迭代方式
Map迭代方式,Map迭代,Map循环
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年
- Spring Cache注解+Redis
hanqunfeng
spring
Spring3.1 Cache注解
依赖jar包:
<!-- redis -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
- Guava中针对集合的 filter和过滤功能
jackyrong
filter
在guava库中,自带了过滤器(filter)的功能,可以用来对collection 进行过滤,先看例子:
@Test
public void whenFilterWithIterables_thenFiltered() {
List<String> names = Lists.newArrayList("John"
- 学习编程那点事
lampcy
编程androidPHPhtml5
一年前的夏天,我还在纠结要不要改行,要不要去学php?能学到真本事吗?改行能成功吗?太多的问题,我终于不顾一切,下定决心,辞去了工作,来到传说中的帝都。老师给的乘车方式还算有效,很顺利的就到了学校,赶巧了,正好学校搬到了新校区。先安顿了下来,过了个轻松的周末,第一次到帝都,逛逛吧!
接下来的周一,是我噩梦的开始,学习内容对我这个零基础的人来说,除了勉强完成老师布置的作业外,我已经没有时间和精力去
- 架构师之流处理---------bytebuffer的mark,limit和flip
nannan408
ByteBuffer
1.前言。
如题,limit其实就是可以读取的字节长度的意思,flip是清空的意思,mark是标记的意思 。
2.例子.
例子代码:
String str = "helloWorld";
ByteBuffer buff = ByteBuffer.wrap(str.getBytes());
Sy
- org.apache.el.parser.ParseException: Encountered " ":" ": "" at line 1, column 1
Everyday都不同
$转义el表达式
最近在做Highcharts的过程中,在写js时,出现了以下异常:
严重: Servlet.service() for servlet jsp threw exception
org.apache.el.parser.ParseException: Encountered " ":" ": "" at line 1,
- 用Java实现发送邮件到163
tntxia
java实现
/*
在java版经常看到有人问如何用javamail发送邮件?如何接收邮件?如何访问多个文件夹等。问题零散,而历史的回复早已经淹没在问题的海洋之中。
本人之前所做过一个java项目,其中包含有WebMail功能,当初为用java实现而对javamail摸索了一段时间,总算有点收获。看到论坛中的经常有此方面的问题,因此把我的一些经验帖出来,希望对大家有些帮助。
此篇仅介绍用
- 探索实体类存在的真正意义
java小叶檀
POJO
一. 实体类简述
实体类其实就是俗称的POJO,这种类一般不实现特殊框架下的接口,在程序中仅作为数据容器用来持久化存储数据用的
POJO(Plain Old Java Objects)简单的Java对象
它的一般格式就是
public class A{
private String id;
public Str