电商数据仓库的架构、模型与应用实践
一. 数据仓库概念

二. 项目需求及架构设计
1. 项目需求分析

2. 项目框架
2.1 技术选型

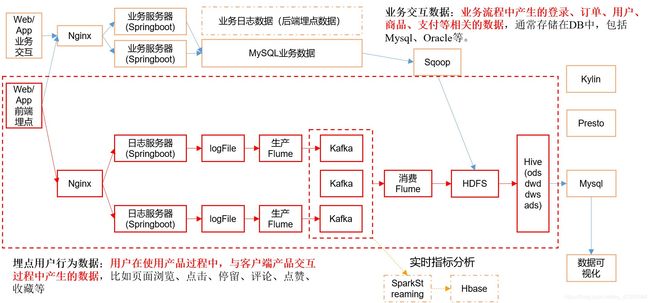
2.2 系统数据流程设计

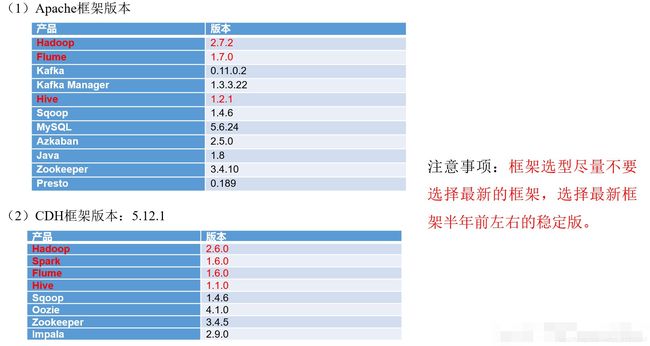
2.3 框架版本选型
2.4 服务器选型

2.5 集群资源规划设计

2)测试集群服务器规划
| 服务名称 |
子服务 |
服务器 hadoop102 |
服务器 hadoop103 |
服务器 hadoop104 |
| HDFS |
NameNode |
√ |
|
|
| DataNode |
√ |
√ |
√ |
|
| SecondaryNameNode |
|
|
√ |
|
| Yarn |
NodeManager |
√ |
√ |
√ |
| Resourcemanager |
|
√ |
|
|
| Zookeeper |
Zookeeper Server |
√ |
√ |
√ |
| Flume(采集日志) |
Flume |
√ |
√ |
|
| Kafka |
Kafka |
√ |
√ |
√ |
| Flume(消费Kafka) |
Flume |
|
|
√ |
| Hive |
Hive |
√ |
|
|
| MySQL |
MySQL |
√ |
|
|
| Sqoop |
Sqoop |
√ |
|
|
| Presto |
Coordinator |
√ |
|
|
| Worker |
|
√ |
√ |
|
| Azkaban |
AzkabanWebServer |
√ |
|
|
| AzkabanExecutorServer |
√ |
|
|
|
| Druid |
Druid |
√ |
√ |
√ |
| 服务数总计 |
|
13 |
8 |
9 |
三. 数仓分层概念
1. 分层概念

2. 数仓分层


3. 数据集市与数据仓库概念

4. 数仓命名规范
- ODS层命名为ods
- DWD层命名为dwd
- DWS层命名为dws
- ADS层命名为ads
- 临时表数据库命名为xxx_tmp
- 备份数据数据库命名为xxx_bak
四. 数仓搭建环境准备
集群规划
|
|
服务器hadoop102 |
服务器hadoop103 |
服务器hadoop104 |
| Hive |
Hive |
|
|
| MySQL |
MySQL |
|
|
五. 业务知识准备
1. 业务术语
1.用户
用户以设备为判断标准,在移动统计中,每个独立设备认为是一个独立用户。Android系统根据IMEI号,IOS系统根据OpenUDID来标识一个独立用户,每部手机一个用户。
2. 新增用户
首次联网使用应用的用户。如果一个用户首次打开某APP,那这个用户定义为新增用户;卸载再安装的设备,不会被算作一次新增。新增用户包括日新增用户、周新增用户、月新增用户。
3. 活跃用户
打开应用的用户即为活跃用户,不考虑用户的使用情况。每天一台设备打开多次会被计为一个活跃用户。
4. 周(月)活跃用户
某个自然周(月)内启动过应用的用户,该周(月)内的多次启动只记一个活跃用户。
5. 月活跃率
月活跃用户与截止到该月累计的用户总和之间的比例。
6.沉默用户
用户仅在安装当天(次日)启动一次,后续时间无再启动行为。该指标可以反映新增用户质量和用户与APP的匹配程度。
7.版本分布
不同版本的周内各天新增用户数,活跃用户数和启动次数。利于判断APP各个版本之间的优劣和用户行为习惯。
8.本周回流用户
上周未启动过应用,本周启动了应用的用户。
9.连续n周活跃用户
连续n周,每周至少启动一次。
10.忠诚用户
连续活跃5周以上的用户
11.连续活跃用户
连续2周及以上活跃的用户
12.近期流失用户
连续n(2<= n <= 4)周没有启动应用的用户。(第n+1周没有启动过)
13.留存用户
某段时间内的新增用户,经过一段时间后,仍然使用应用的被认作是留存用户;这部分用户占当时新增用户的比例即是留存率。
例如,5月份新增用户200,这200人在6月份启动过应用的有100人,7月份启动过应用的有80人,8月份启动过应用的有50人;则5月份新增用户一个月后的留存率是50%,二个月后的留存率是40%,三个月后的留存率是25%。
14.用户新鲜度
每天启动应用的新老用户比例,即新增用户数占活跃用户数的比例。
15.单次使用时长
每次启动使用的时间长度。
16. 日使用时长
累计一天内的使用时间长度。
17. 启动次数计算标准
IOS平台应用退到后台就算一次独立的启动;Android平台我们规定,两次启动之间的间隔小于30秒,被计算一次启动。用户在使用过程中,若因收发短信或接电话等退出应用30秒又再次返回应用中,那这两次行为应该是延续而非独立的,所以可以被算作一次使用行为,即一次启动。业内大多使用30秒这个标准,但用户还是可以自定义此时间间隔。
六. 电商业务与数据结构简介
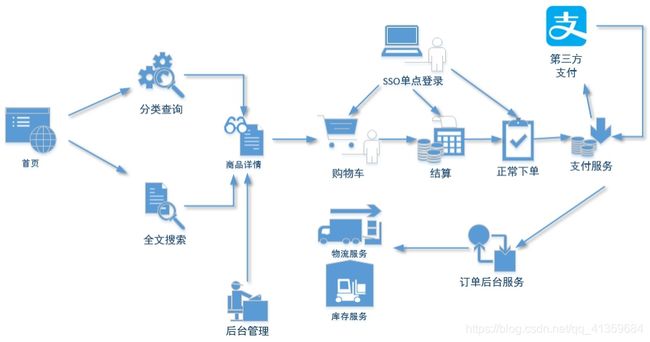
1 电商业务流程
2 电商常识(SKU、SPU)
SKU=Stock Keeping Unit(库存量基本单位)。现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的SKU号。
SPU(Standard Product Unit):是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息集合。
比如,咱们购买一台iPhoneX手机,iPhoneX手机就是一个SPU,但是你购买的时候,不可能是以iPhoneX手机为单位买的,商家也不可能以iPhoneX为单位记录库存SKU。必须要以什么颜色什么版本的iPhoneX为单位。比如,你购买的是一台银色、128G内存的、支持联通网络的iPhoneX,商家也会以这个单位来记录库存数。那这个更细致的单位就叫库存单元(SKU)。
那SPU又是干什么的呢?

SPU表示一类商品。好处就是:可以共用商品图片,海报、销售属性等。
3 电商表结构

3.1 订单表(order_info)
| 标签 |
含义 |
|
| id |
订单编号 |
|
| total_amount |
订单金额 |
|
| order_status |
订单状态 |
|
| user_id |
用户id |
|
| payment_way |
支付方式 |
|
| out_trade_no |
支付流水号 |
|
| create_time |
创建时间 |
|
| operate_time |
操作时间 |
|
3.2 订单详情表(order_detail)
| 标签 |
含义 |
|
| id |
订单编号 |
|
| order_id |
订单号 |
|
| user_id |
用户id |
|
| sku_id |
商品id |
|
| sku_name |
商品名称 |
|
| order_price |
商品价格 |
|
| sku_num |
商品数量 |
|
| create_time |
创建时间 |
|
3.3 商品表
| 标签 |
含义 |
|
| id |
skuId |
|
| spu_id |
spuid |
|
| price |
价格 |
|
| sku_name |
商品名称 |
|
| sku_desc |
商品描述 |
|
| weight |
重量 |
|
| tm_id |
品牌id |
|
| category3_id |
品类id |
|
| create_time |
创建时间 |
|
3.4 用户表
| 标签 |
含义 |
|
| id |
用户id |
|
| name |
姓名 |
|
| birthday |
生日 |
|
| gender |
性别 |
|
| |
邮箱 |
|
| user_level |
用户等级 |
|
| create_time |
创建时间 |
|
3.5 商品一级分类表
| 标签 |
含义 |
|
| id |
id |
|
| name |
名称 |
|
3.6 商品二级分类表
| 标签 |
含义 |
|
| id |
id |
|
| name |
名称 |
|
| category1_id |
一级品类id |
|
3.7 商品三级分类表
| 标签 |
含义 |
|
| id |
id |
|
| name |
名称 |
|
| Category2_id |
二级品类id |
|
3.8 支付流水表
| 标签 |
含义 |
|
| id |
编号 |
|
| out_trade_no |
对外业务编号 |
|
| order_id |
订单编号 |
|
| user_id |
用户编号 |
|
| alipay_trade_no |
支付宝交易流水编号 |
|
| total_amount |
支付金额 |
|
| subject |
交易内容 |
|
| payment_type |
支付类型 |
|
| payment_time |
支付时间 |
|
七. 数仓理论
1 表的分类
1.1 实体表
实体表,一般是指一个现实存在的业务对象,比如用户,商品,商家,销售员等等。
用户表:
| 用户id |
姓名 |
生日 |
性别 |
邮箱 |
用户等级 |
创建时间 |
| 1 |
张三 |
2011-11-11 |
男 |
2 |
2018-11-11 |
|
| 2 |
李四 |
2011-11-11 |
女 |
3 |
2018-11-11 |
|
| 3 |
王五 |
2011-11-11 |
中性 |
1 |
2018-11-11 |
|
| … |
… |
… |
… |
… |
… |
… |
1.2 维度表
维度表,一般是指对应一些业务状态,编号的解释表。也可以称之为码表。
比如地区表,订单状态,支付方式,审批状态,商品分类等等。
订单状态表:
| 订单状态编号 |
订单状态名称 |
| 1 |
未支付 |
| 2 |
支付 |
| 3 |
发货中 |
| 4 |
已发货 |
| 5 |
已完成 |
商品分类表:
| 商品分类编号 |
分类名称 |
| 1 |
服装 |
| 2 |
保健 |
| 3 |
电器 |
| 4 |
图书 |
1.3 事务型事实表
事务型事实表,一般指随着业务发生不断产生的数据。特点是一旦发生不会再变化。
一般比如,交易流水,操作日志,出库入库记录等等。
交易流水表:
| 编号 |
对外业务编号 |
订单编号 |
用户编号 |
支付宝交易流水编号 |
支付金额 |
交易内容 |
支付类型 |
支付时间 |
| 1 |
7577697945 |
1 |
111 |
QEyF-63000323 |
223.00 |
海狗人参丸1 |
alipay |
2019-02-10 00:50:02 |
| 2 |
0170099522 |
2 |
222 |
qdwV-25111279 |
589.00 |
海狗人参丸2 |
wechatpay |
2019-02-10 00:50:02 |
| 3 |
1840931679 |
3 |
666 |
hSUS-65716585 |
485.00 |
海狗人参丸3 |
unionpay |
2019-02-10 00:50:02 |
| 。。。 |
。。。 |
。。。 |
。。。 |
。。。 |
。。。 |
。。。 |
。。。 |
。。。 |
1.4 周期型事实表
周期型事实表,一般指随着业务发生不断产生的数据。
与事务型不同的是,数据会随着业务周期性的推进而变化。
比如订单,其中订单状态会周期性变化。再比如,请假、贷款申请,随着批复状态在周期性变化。
订单表:
| 订单编号 |
订单金额 |
订单状态 |
用户id |
支付方式 |
支付流水号 |
创建时间 |
操作时间 |
| 1 |
223.00 |
2 |
111 |
alipay |
QEyF-63000323 |
2019-02-10 00:01:29 |
2019-02-10 00:01:29 |
| 2 |
589.00 |
2 |
222 |
wechatpay |
qdwV-25111279 |
2019-02-10 00:05:02 |
2019-02-10 00:05:02 |
| 3 |
485.00 |
1 |
666 |
unionpay |
hSUS-65716585 |
2019-02-10 00:50:02 |
2019-02-10 00:50:02 |
| 。。。 |
。。。 |
。。。 |
。。。 |
。。。 |
。。。 |
。。。 |
。。。 |
2 同步策略
数据同步策略的类型包括:全量表、增量表、新增及变化表、拉链表
- 全量表:存储完整的数据。
- 增量表:存储新增加的数据。
- 新增及变化表:存储新增加的数据和变化的数据。
- 拉链表:对新增及变化表做定期合并。
2.1 实体表同步策略
实体表:比如用户,商品,商家,销售员等
实体表数据量比较小:通常可以做每日全量,就是每天存一份完整数据。即每日全量。
2.2 维度表同步策略
维度表:比如订单状态,审批状态,商品分类
维度表数据量比较小:通常可以做每日全量,就是每天存一份完整数据。即每日全量。
说明:
1)针对可能会有变化的状态数据可以存储每日全量。
2)没变化的客观世界的维度(比如性别,地区,民族,政治成分,鞋子尺码)可以只存一份固定值。
2.3 事务型事实表同步策略
事务型事实表:比如,交易流水,操作日志,出库入库记录等。
因为数据不会变化,而且数据量巨大,所以每天只同步新增数据即可,所以可以做成每日增量表,即每日创建一个分区存储。
2.4 周期型事实表同步策略
周期型事实表:比如,订单、请假、贷款申请等
这类表从数据量的角度,存每日全量的话,数据量太大,冗余也太大。如果用每日增量的话无法反应数据变化。
每日新增及变化量,包括了当日的新增和修改。一般来说这个表,足够计算大部分当日数据的。但是这种依然无法解决能够得到某一个历史时间点(时间切片)的切片数据。
所以要用利用每日新增和变化表,制作一张拉链表,以方便的取到某个时间切片的快照数据。所以我们需要得到每日新增及变化量。
拉链表:
| name姓名 |
start新名字创建时间 |
end名字更改时间 |
| 张三 |
1990/1/1 |
2018/12/31 |
| 张小三 |
2019/1/1 |
2019/4/30 |
| 张大三 |
2019/5/1 |
9999-99-99 |
| 。。。 |
。。。 |
。。。 |
select * from user where start =<’2019-1-2’ and end>=’2019-1-2’
3. 关系建模与维度建模
- 关系模型

关系模型主要应用与OLTP系统中,为了保证数据的一致性以及避免冗余,所以大部分业务系统的表都是遵循第三范式的。
- 维度模型

维度模型主要应用于OLAP系统中,因为关系模型虽然冗余少,但是在大规模数据,跨表分析统计查询过程中,会造成多表关联,这会大大降低执行效率。
所以把相关各种表整理成两种:事实表和维度表两种。所有维度表围绕着事实表进行解释。
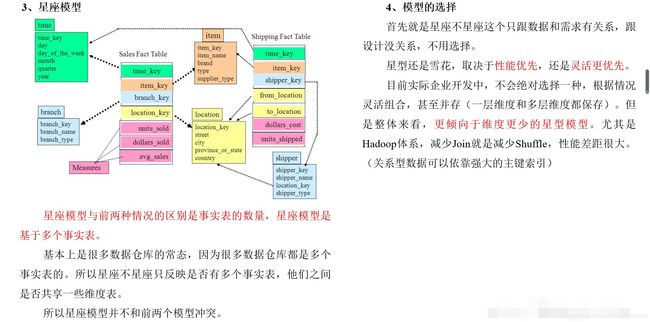
4. 雪花模型、星型模型和星座模型
在维度建模的基础上又分为三种模型:星型模型、雪花模型、星座模型。