Linux环境基础开发工具的使用
文章目录
- Linux软件包管理器yum
-
- 软件包
- 查看软件包
- 安装软件
- 卸载软件
- Linux编辑器-vim使用
-
- vim的基本概念
- vim的基本操作
- vim正常模式命令集
- vim末行模式命令集
- 简单vim配置
- Linux编译器-gcc/g++使用
- Linux调试器-gdb使用
- Linux项目自动化构建工具-make/Makefile
-
- make/Makefile
- Linux第一个小程序-进度条
- 使用 git 命令行
Linux软件包管理器yum
软件包
安装软件一般有三种方法:
1.源码
2.rpm包。有点像windows下载的安装包
3.yum命令行
在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译, 得到可执行程序.但是这样太麻烦了, 于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解成windows上的安装程序)放在一个服务器上, 通过包管理器可以很方便的获取到这个编译好的软件包, 直接进行安装.软件包和软件包管理器, 就好比 “App” 和 “应用商店” 。yum(Yellow dog Updater, Modified)是Linux下非常常用的一种包管理器. 主要应用在Fedora, RedHat, Centos等发行版上.
一个服务器同一时刻只能让一个yum进行安装,不能同时安装多个软件。
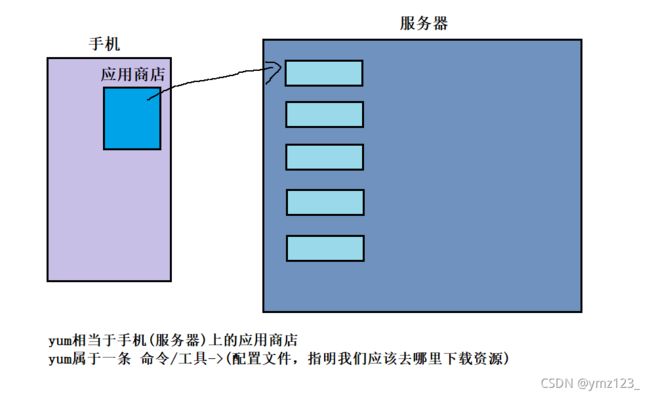
yum是从服务器上下载rpm包,关于 yum 的所有操作必须保证主机(虚拟机)网络畅通,可以通过 ping 指令验证。例如:
查看软件包
[ymz@VM-16-9-centos ~]$ yum list
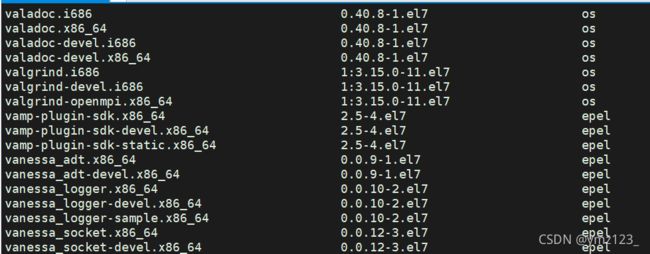
- 软件包名称: 主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构.
- “x86_64” 后缀表示64位系统的安装包, “i686” 后缀表示32位系统安装包. 选择包时要和系统匹配.
- “el7” 表示操作系统发行版的版本. “el7” 表示的是 centos7/redhat7. “el6” 表示 centos6/redhat6.
- 最后一列, base 表示的是 “软件源” 的名称, 类似于 “小米应用商店”, “华为应用商店” 这样的概念.
通过 yum list 命令可以罗列出当前一共有哪些软件包. 由于包的数目可能非常之多, 这里我们需要使用 grep 命令只筛选出我们关注的包. 例如:
[ymz@VM-16-9-centos ~]$ yum list | grep lrzsz
(lrzsz可以将Windows中的文件上传到Linux中,也可以将Linux中的文件下载到Windows中,实现云服务器和本地机器之间信息互传)

安装软件
通过 yum, 我们可以通过很简单的一条命令完成 gcc 的安装.
[ymz@VM-16-9-centos ~]$ sudo yum install lrzsz
yum 会自动找到都有哪些软件包需要下载, 这时候敲 “y” 确认安装.出现 “complete” 字样, 说明安装完成.
卸载软件
[ymz@VM-16-9-centos ~]$ sudo yum remove lrzsz

Linux编辑器-vim使用
vi/vim的区别简单点来说,它们都是多模式编辑器,不同的是vim是vi的升级版本,它不仅兼容vi的所有指令,而且还有一些新的特性在里面。例如语法加亮,可视化操作不仅可以在终端运行,也可以运行于x window、 mac os、windows。
vim的基本概念
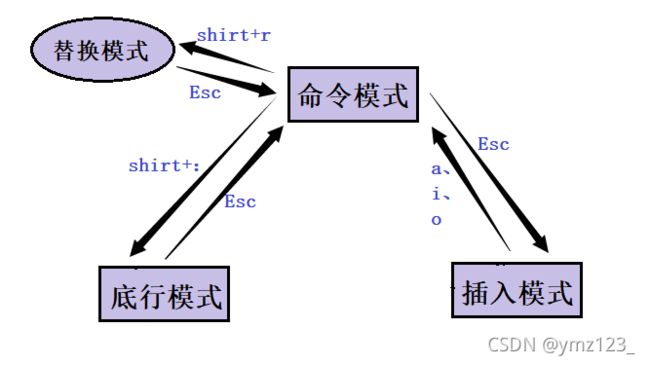
vim本质上是一个多模式的文本编辑器,这里主要介绍三种模式:命令模式(command mode)、插入模式(Insert mode)和底行模式(last line mode)
1.正常/普通/命令模式(Normal mode)
控制屏幕光标的移动,字符、字或行的删除,移动复制某区段及进入Insert mode下,或者到 last line mode。
2.插入模式(Insert mode)
只有在Insert mode下,才可以做文字输入,按「ESC」键可回到命令行模式。该模式是我们后面用的最频繁的编辑模式。
3.底行模式(Command mode)
文件保存或退出,也可以进行文件替换,找字符串,列出行号等操作。 在命令模式下,shift+: 即可进入该模式。要查看你的所有模式:打开vim,底行模式直接输入:help vim-modes
vim的基本操作
进入vim,在系统提示符号输入vim及文件名称后,就进入vim全屏幕编辑画面
[ymz@VM-16-9-centos ~]$ vim test.c
[正常模式]切换至[插入模式]
输入a:在当前光标的后一位置进入插入模式
输入i:在当前光标处进入插入模式
输入o:在当前光标处新起一行进入插入模式
[插入模式]/[底行模式]切换至[正常模式]
按[Esc]键即可
[正常模式]切换至[末行模式]
「shift + ;」, 其实就是输入「:」
退出vim及保存文件,在[正常模式]下,按一下「:」冒号键进入「底行模式」,例如:
:w 保存当前文件
:wq 存盘并退出vim
:q! 输入q!,不存盘强制退出vim
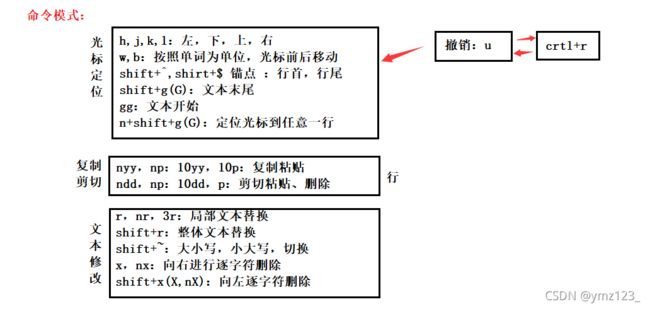
vim正常模式命令集
-
移动光标
vim可以直接用键盘上的光标来上下左右移动,但正规的vim是用小写英文字母「h」、「j」、「k」、
「l」,分别控制光标左、下、上、右移一格
按「G」:移动到文章的最后
按「 $ 」:移动到光标所在行的“行尾”
按「^」:移动到光标所在行的“行首”
按「w」:光标跳到下个字的开头
按「e」:光标跳到下个字的字尾
按「b」:光标回到上个字的开头
按「nl」:光标移到该行的第n个位置,如:5l,56l
按[gg]:进入到文本开始
按[shift+g]:进入文本末端
按「ctrl」+「b」:屏幕往“后”移动一页
按「ctrl」+「f」:屏幕往“前”移动一页
按「ctrl」+「u」:屏幕往“后”移动半页
按「ctrl」+「d」:屏幕往“前”移动半页 -
删除文字
「x」 :每按一次,删除光标所在位置的一个字符
「nx」:例如,「6x」表示删除光标所在位置的“后面(包含自己在内)”6个字符
「X」:大写的X,每按一次,删除光标所在位置的“前面”一个字符
「nX」:例如,「20X」表示删除光标所在位置的“前面”20个字符
「dd」:删除光标所在行
「ndd」:从光标所在行开始删除n行 -
复制
「yw」:将光标所在之处到字尾的字符复制到缓冲区中。
「nyw」:复制n个字到缓冲区
「yy」:复制光标所在行到缓冲区。
「nyy」:例如,「6yy」表示拷贝从光标所在的该行“往下数”6行文字。
「p」:将缓冲区内的字符贴到光标所在位置。注意:所有与“y”有关的复制命令都必须与“p”配合才能完成复制与粘贴功能。 -
替换
「r」:替换光标所在处的字符。
「R」:替换光标所到之处的字符,直到按下「ESC」键为止。 -
撤销上一次操作
「u」:如果您误执行一个命令,可以马上按下「u」,回到上一个操作。按多次“u”可以执行多次回复。
「ctrl + r」: 撤销的恢复 -
更改
「cw」:更改光标所在处的字到字尾处
「c#w」:例如,「c3w」表示更改3个字 -
跳至指定的行
「ctrl」+「g」列出光标所在行的行号。
「#G」:例如,「15G」,表示移动光标至文章的第15行行首。
vim末行模式命令集
在使用末行模式之前,请记住先按「ESC」键确定已经处于正常模式,再按「:」冒号即可进入末行模式。
- 列出行号
「set nu」: 输入「set nu」后,会在文件中的每一行前面列出行号。 - 跳到文件中的某一行
「#」:「#」号表示一个数字,在冒号后输入一个数字,再按回车键就会跳到该行了,如输入数字15,再回车,就会跳到文章的第15行。 - 查找字符
「/关键字」: 先按「/」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按「n」会往后寻找到您要的关键字为止。
「?关键字」:先按「?」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按「n」会往前寻找到您要的关键字为止。 - 保存文件
「w」: 在冒号输入字母「w」就可以将文件保存起来 - 离开vim
「q」:按「q」就是退出,如果无法离开vim,可以在「q」后跟一个「!」强制离开vim。
「wq」:一般建议离开时,搭配「w」一起使用,这样在退出的时候还可以保存文件。

分屏显示:
简单vim配置
配置文件的位置:
- 在目录 /etc/ 下面,有个名为vimrc的文件,这是系统中公共的vim配置文件,对所有用户都有效。
- 而在每个用户的主目录下,都可以自己建立私有的配置文件,命名为:“.vimrc”。例如,/root目录下,通常已经存在一个.vimrc文件,如果不存在,则创建之。
- 切换用户成为自己执行
su,进入自己的主工作目录,执行cd ~ - 打开自己目录下的.vimrc文件,执行 vim .vimrc
Linux编译器-gcc/g++使用
预处理(进行宏替换)
- 预处理功能主要包括宏定义,文件包含,条件编译,去注释等
- 预处理指令是以#号开头的代码行。
- 实例:
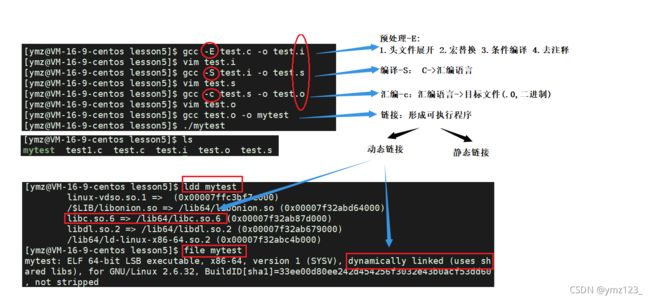
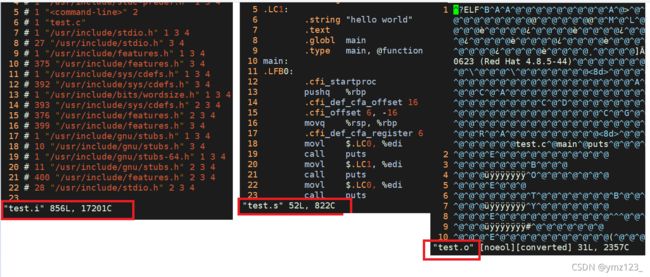
gcc –E hello.c –o hello.i - 选项“-E”,该选项的作用是让 gcc 在预处理结束后停止编译过程.
- 选项“-o”是指目标文件,“.i”文件为已经过预处理的C原始程序
编译(生成汇编)
- 在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。
- 用户可以使用“-S”选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码
- 实例:
gcc –S hello.i –o hello.s
汇编(生成机器可识别代码)
- 汇编阶段是把编译阶段生成的“.s”文件转成目标文件
- 可使用选项“-c”就可看到汇编代码已转化为“.o”的二进制目标代码了
- 实例:
gcc -c hello.s -o hello.o
链接(生成可执行文件或库文件)
- 在成功编译之后,就进入了链接阶段
- 实例:
gcc hello.o –o hello
函数库
我们的C程序中,并没有定义“printf”的函数实现,且在预编译中包含的“stdio.h”中也只有该函数的声明,而没有定义函数的实现,那么,是在哪里实现“printf”函数的呢?
最后的答案是:系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径“/usr/lib”下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数“printf”了,而这也就是链接的作用。
函数库一般分为静态库和动态库两种
1.静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为“.a”
2.动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为“.so”,如前面所述的 libc.so.6 就是动态库。gcc 在编译时默认使用动态库。完成了链接之后,gcc 就可以生成可执行文件,如下所示。 gcc hello.o –o hello
3.gcc默认生成的二进制程序,是动态链接的,这点可以通过 file 命令验证。
gcc选项
- -E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面
- -S 编译到汇编语言不进行汇编和链接
- -c 编译到目标代码
- -o 文件输出到 文件
- -static 此选项对生成的文件采用静态链接
- -g 生成调试信息。GNU 调试器可利用该信息
- -shared 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库
- -O0、-O1、-O2、-O3 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高
- -w 不生成任何警告信息。
- -Wall 生成所有警告信息。
 _
_
Linux调试器-gdb使用
程序的发布方式有两种,debug模式和release模式。
Linux gcc/g++出来的二进制程序,默认是release模式。且是动态链接,使用动态库。
要使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项(发布以debug方式)。

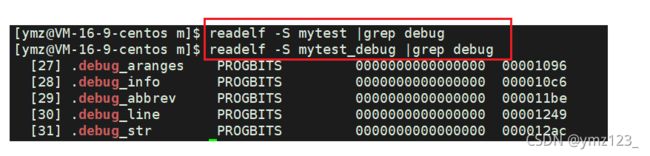
可以看到debug版本文件大小比release大一些,因为debug版本多了一些调试信息(debuginfo):

用readelf可以查看到release版本没有调试信息,而debug版本有
进入调试:gdb binFile
 退出:
退出:quit或ctrl+d
调试命令:
- list/l 行号:显示binFile源代码,接着上次的位置往下列,每次列10行。
- list/l 函数名:列出某个函数的源代码。
- r或run:运行程序。(重新运行)
- n 或 next:单条执行。(等价于VS中的F10)
- s或step:进入函数调用。(等价于VS中的F11)
- break(b) 行号:在某一行设置断点。(F9)
- break 函数名:在某个函数开头设置断点。
- info break :查看断点信息。
- finish:执行到当前函数返回,然后挺下来等待命令。
- print§:打印表达式的值,通过表达式可以修改变量的值或者调用函数。
- p 变量:打印变量值。
- set var:修改变量的值。
- continue(或c):从当前位置开始连续而非单步执行程序。
- run(或r):从开始连续而非单步执行程序。
- delete breakpoints:删除所有断点。
- delete breakpoints n:删除序号为n的断点。
- disable breakpoints:禁用断点。
- enable breakpoints:启用断点。
- info(或i) breakpoints:参看当前设置了哪些断点。
- display 变量名:跟踪查看一个变量,每次停下来都显示它的值。
- undisplay:取消对先前设置的那些变量的跟踪。
- until X行号:跳至X行。
- breaktrace(或bt):查看各级函数调用及参数。
- info(i) locals:查看当前栈帧局部变量的值。
- quit:退出gdb。
Linux项目自动化构建工具-make/Makefile
make/Makefile
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。
makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一
种在工程方面的编译方法。
make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
touch Makefile/makefile
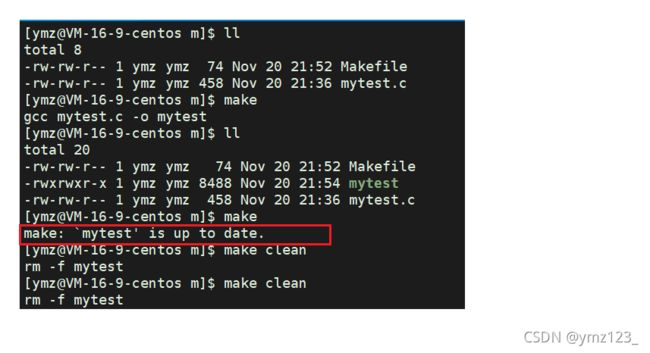
在Makefile中,.PHONY后面的target表示的也是一个伪造的target, 而不是真实存在的文件target,注意Makefile的target默认是文件。Makefile拒绝了执行第二次执行make(第一条), 因为文件mytest存在。而Makefile却总是执行clean后面的规则。由此可见,.PHONY:clean发挥了作用。
依赖关系
下面的文件mytest依赖mytest.o
而mytest.o依赖mytest.s
mytest.s依赖mytest.i
mytest.i依赖mytest.c

依赖方法

原理
make是如何工作的,在默认的方式下,也就是我们只输入make命令。那么:
- make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
- 如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到“mytest”这个文件,并把这个文件作为最终的目标文件。
- 如果mytest文件不存在,或是mytest所依赖的后面的mytest.o文件的文件修改时间要比mytest这个文件新(可以用 touch 测试),那么,他就会执行后面所定义的命令来生成mytest这个文件。
- 如果mytest所依赖的mytest.o文件不存在,那么make会在当前文件中找目标为mytest.o文件的依赖性,如果找到则再根据那一个规则生成mytest.o文件。(这有点像一个堆栈的过程)
- 当然,你的C文件和H文件是存在的啦,于是make会生成 mytest.o 文件,然后再用 mytest.o 文件声明make的终极任务,也就是执行文件mytest了。
- 这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
- 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。
- make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那么对不起,我就不工作啦。
项目清理
像clean这种没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行,不过,我们可以显示要make执行。即命令——“make clean”,以此来清除所有的目标文件,以便重编
译。
但是一般我们这种clean的目标文件,我们将它设置为伪目标,用 .PHONY 修饰,伪目标的特性是,总是被执行的。
Linux第一个小程序-进度条
\r&&\n
换行:在原来行的位置换到下一行
回车:不换到下一行,直接回到该行的起始位置
回车换行:换行并回车
\n就是回车换行
\r是只回车不换行
看以下代码:
printf("hello");
sleep(5);
执行该代码,hello在5s后才会显示出来。
可以肯定的是,printf是先执行的,但printf已经执行完了,不代表字符串就得显示出来。在sleep期间,字符串在缓冲区。
缓冲区的本质就是一段内存空间,暂存临时数据,在合适的时候刷新出去。
刷新策略:1.直接刷新不缓存。2.缓冲区写满再刷新,全缓冲。3.碰到\n就刷新,行刷新(显示器)。4.强制刷新。把数据真正写入磁盘、文件、显示器、网络等设备或文件。
任何一个C程序,启动的时候,会默认打开三个输入输出流(文件)
stdin、stdout、stderr
倒计时代码:
1 #include"mytest.h"
2 #include<unistd.h>
3
4 int main()
5 {
6 int count = 9;
7 while(count>=0){
8 printf("%d\r",count);
9 fflush(stdout);
10 sleep(1);
11 count--;
12 }
13
14 return 0;
15 }
进度条代码:
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<string.h>
4
5 #define NUM 100
6
7 int main()
8 {
9 char bar[NUM+2];
10 memset(bar,0,sizeof(bar));
11
12 const char* lable="|/-\\";
13 int i=0;
14
15 while(i<=NUM){
16 bar[i]='=';
17 bar[i+1]='>';
18 printf("[%-101s][%d%%][%c]\r",bar,i,lable[i%4]);
19 fflush(stdout);
20 usleep(100000);
21 i++;
22 }
23 printf("\n");
24
25 return 0;
26 }
}
![]()
使用 git 命令行
查看是否安装

在gitee创建好项目后,复制项目链接
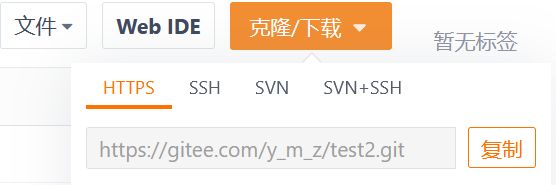
下载项目到本地:
git clone [url]
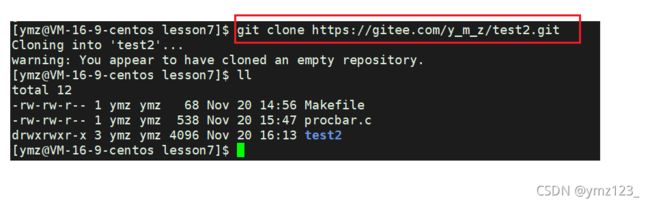
可以看到项目已被下载到本地:
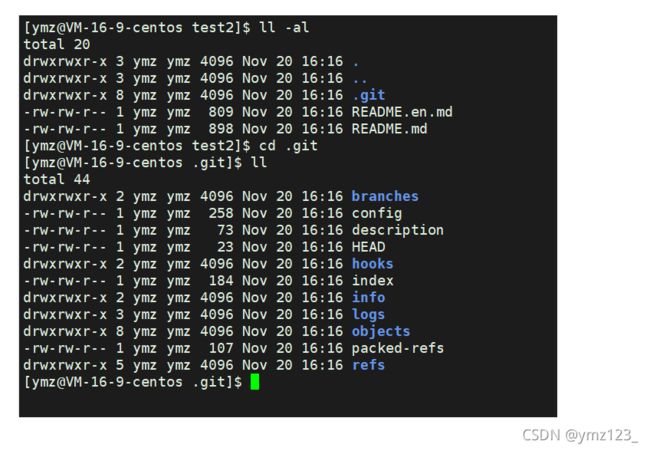
三板斧第一招: git add
将代码放到刚才下载好的目录中
git add [文件名]
将需要用 git 管理的文件告知 git
三板斧第二招: git commit
提交改动到本地
git commit .
最后的 “.” 表示当前目录
提交的时候应该注明提交日志, 描述改动的详细内容.
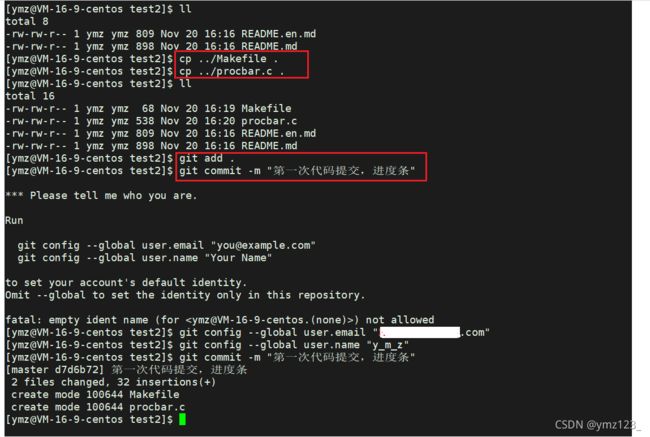
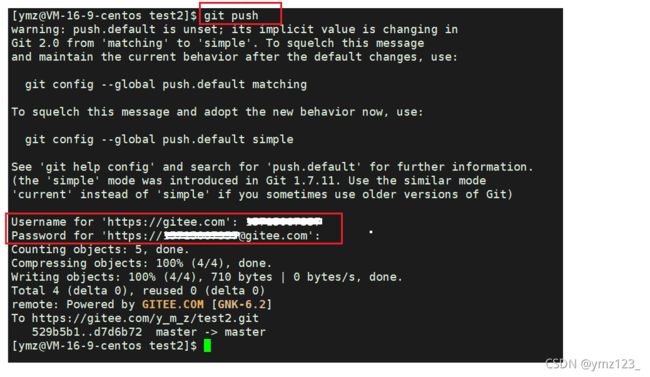
三板斧第三招: git push
git push
需要填入用户名密码. 同步成功后, 刷新 Github 页面就能看到代码改动了.
查看提交记录:git log
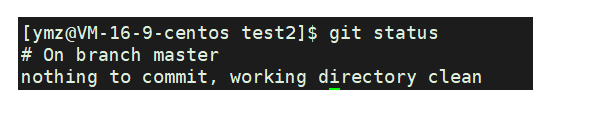
查看提交状态:git status
在windows中,也可以按Windows+x键,打开Windows PowerShell输入命令
