其实我们之前所讲的回表,就是两个索引树同时使用,先在二级索引树中搜索到对应的主键值,然后在再去主键索引树中查询完整的记录。
但是我今天的问题是,两个不同的二级索引树,会同时生效吗?理论上来说,应该是可以同时生效的,不然这个 MySQL 也太笨了。不过根据松哥日常开发经验,这种事情最好能够避免,如果发生了同时搜索两棵索引树的事情,大概是你的索引设计有问题,此时就要去检查一下索引的设计是否合理。
加粗的是实践经验,但是对于两个索引同时生效的知识点,我们还是要懂,一起来看下。
1. 索引合并
例如我有如下一张表结构:
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(32) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`address` varchar(32) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`password` varchar(32) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`email` varchar(16) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `username` (`username`),
KEY `address` (`address`)
) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;这个表里边有 username 和 address 两个索引,注意是两个索引,每个索引中有一个字段,这不是联合索引。
现在我的查询 SQL 如下:
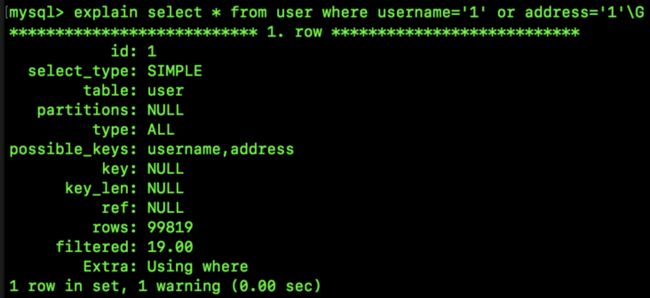
select * from user where username='1' or address='1';搜索条件有两个,username 和 address,这是两个索引,分属于两棵不同的索引树。那么它在搜索的时候会两棵索引树都去搜索吗?还是只搜索一颗索引树,再用另一个搜索条件过滤第一棵树搜索出来的结果?
我们来看下数据库执行计划:
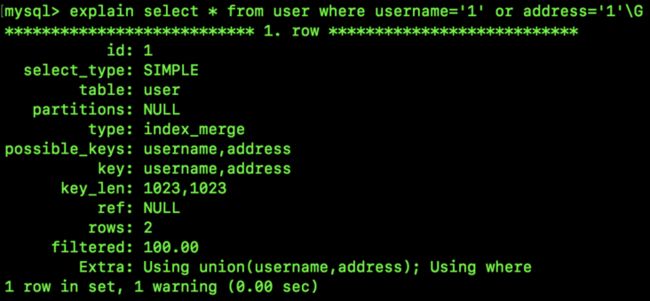
大致上瞥一眼这个执行计划,大家也能猜出来,这里其实两个索引都用到了,在这个执行计划中有几个新面孔:
- type 为
index_merge。 - Extra 为
Using union(username,address); Using where。
这个 type 中的 index_merge 就是索引合并。
2. 旧版玩法
当然这个 index_merge 并不是一开始就有的,这是从 MySQL5.0 开始引入的东西。虽然大家现在基本山不会再用到 MySQL5.0 之前的版本了,但是我这里还是说一下,加深大家对 MySQL 的理解。在 MySQL5.0 之前,对于我们上面给出的查询 SQL,是不会走索引的,会全表扫描。在那个年代,如果你想实现上面这个查询,但是又想走索引,你的 SQL 得这样写:
select * from user where username='1' union all select * from user where address='1' and username!='1'不过这种写法很明显有点笨拙。
所以,从 MySQL5.0 开始,在查询中可以自动使用多个索引进行扫描,并将结果进行合并,也就是我们前面所说的索引合并(index_merge)。
3. 三种情况
索引合并这种算法有三个变种,我们分别来看。
3.1 union
这是求两个索引的并集。
我们来看如下 SQL:
select * from user where username like '1%' or address like '1%';这个 SQL 在执行的过程中就会涉及到两个索引,需要去两棵索引树中进行搜索,再对搜索结果求并集,我们来看一下该 SQL 的执行计划:
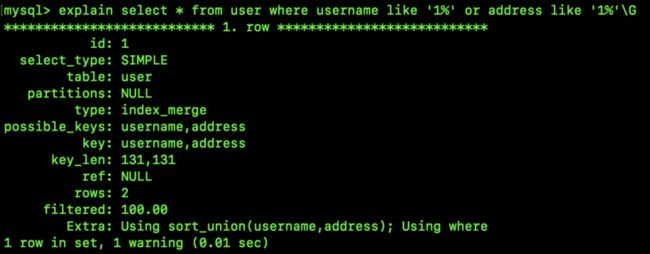
可以看到,这个执行计划中已经发生了索引合并(看 type 、key、Extra)。
那么是不是只要是两个索引查询就总会发送索引合并呢?我们再来看一个栗子:
select * from user where username>'a' or address='1';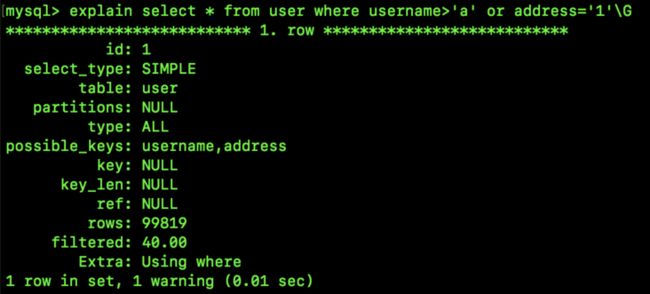
大家看一下,只是搜索条件变了一下而已,这里就没用索引合并了,而变成了全表扫描,这是为什么呢?这就引出来索引合并的一个条件,即:每个索引对应的搜索条件,搜到的主键必须是有序的,如果搜到的主键是无序的,抱歉,索引合并用不了。在二级索引中,数据按照二级索引的顺序进行排序,结构类似下面这样:
| username | 主键 |
|---|---|
| a | 20 |
| b | 30 |
| c | 9 |
| c | 10 |
| c | 18 |
| d | 1 |
| d | 5 |
当 username 相同的时候,主键是有序的,当 username 不同的时候,就不能保证主键有序了,如果获取到的主键无序,就无法实现索引合并了。
这又引出来一个问题,为什么获取到的主键有序才能发生索引合并呢?因为只有当主键是有序的,将来去重(union、sort-union)亦或者求交集(intersect),效率都要高一些。
从 MySQL5.0 开始,索引合并默认是开启的,当然你也可以选择关闭,关闭 union 索引合并方式如下:
SET optimizer_switch = 'index_merge_union=off';关闭之后再来看执行计划:
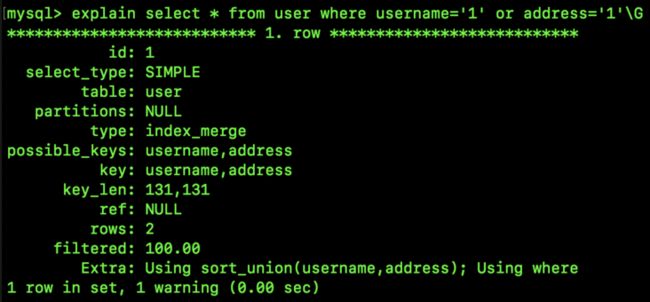
大家看到,依然发生了索引合并,但是这次不是 union,而是 sort_union 了,那我们接下来就来看下什么是 sort_union。
3.2 sort_union
sort_union 基本上和 union 一样,只是多了一个排序的能力。
因为前面我们说,如果获取到无序的主键,就不会发生索引合并,可能最终会直接上全表扫描。因此 MySQL 里边又搞了一个 sort_union,就是先在 username 索引树和 address 索引树中同时进行搜索,分别拿到主键值之后先进行排序,排序完了再进行去重,然后回表拿完整的数据。
和 union 相比主要是多了加粗的那一步。
那我们继续,关闭 sort_union,如下:
SET optimizer_switch = 'index_merge_sort_union=off';关闭之后,再去看执行计划,如下:
此时就没有索引合并了,直接全表扫描。
3.3 intersect
这个是求两个索引的交集。
例如如下 SQL:
select * from user where username like '1%' and address like '1%';这个 SQL 在执行的过程中就有可能出现求交集的情况。当然这并非绝对的,具体还要看优化器优化后的情况。
松哥尝试了很久,没法复现一个例子出来,主要是我的模拟数据不太对味。如果小伙伴们有现成的 Using intersect 例子欢迎留言分享(执行计划 Extra 中会出现 Using intersect 的)。
但是我把这个原理这里和大家分享下,我们来看如下一张图:

假设有二级索引 S 和二级索引 T,现在交叉获取主键(这里有一点需要注意,如果我们是单独在 S 和 T 上搜索,且 S 上搜索条件是 username like '1%',T 上的搜索条件是 address like '1%',那么在搜索的过程中,各自拿到的主键 id 是有序的,这也是 intersect 的前提):
- 首先去二级索引 S 上去搜索,找到第一条满足条件的记录,由于二级索引的叶子结点保存的是主键值,此时拿到主键值之后,先不要急着回表。
- 接下来去二级索引 T 上去搜索,找到第一条满足条件的记录,并且拿到对应的主键值。
- 比较第一步和第二步搜索拿到的主键值:
3.1 如果主键值不相等,则舍弃值小的主键,留下大的主键,下一次在 S 上搜索的时候,就拿着这个大的主键和 S 上搜索出来的主键进行比较。
3.2 如果主键值相等,则说明这个主键是满足搜索条件的,那就拿着这个主键回表。 - 重复前三步,直到各自索引中没有满足条件的记录为止。
这就是所谓的交叉获取主键。
好啦,这就是索引合并的三种情况。
4. 小结
很多小伙伴可能会说,既然有索引合并,是不是我索引就可以随便建立了?nonono!索引合并是一种不得已而为之的办法,如果发生了索引合并,大概率是你设计的索引不太合理导致的,所以我们应该去琢磨该如何优化索引。
参考资料:
- https://dev.mysql.com/doc/ref...
- 《MySQL 是怎么运行的》
- 《高性能 MySQL》
- https://www.modb.pro/db/29619