数字营销行业大数据平台云原生升级实战
简介: 加和科技CTO 王可攀:技术是为业务价值而服务

王可攀 加和科技CTO
本文将基于加和科技大数据平台升级过程中面临的问题和挑战、如何调整数据平台架构以及调整后的变化,为大家介绍数字营销行业大数据平台云原生升级实战经验。主要分为以下三个部分。
- 加和简介
- 加和的大数据服务挑战
- 加和大数据平台升级
一、加和简介
加和科技于2014年创立,2015年搭建自己的技术服务,整个的服务模式为品牌广告客户,现在也涉及到主要有营销需求的客户提供营销的技术解决方案。
(1) 加和服务模式
以下是加和科技对接的媒体方和数据方。

加和服务模式是把所有的媒体流量形成一个管道,当客户需要在不同的媒体之间做联合的控频,比如说同一个用户在优酷上看到一个广告,在爱奇艺上又看到一次广告,客户希望用户只看到三次广告。加和科技可以做一个跨平台的管控,同时客户希望有第三方的挑选和监控,就和其他的服务商协作,为客户提供一个广告的服务。
(2) 加和数据规模
加和科技数据量级增长的非常迅速,最开始的时候流量可能还不如一个中小型的媒体,上个月峰值达到800亿的请求。数据的复杂度也比较高,每一个请求都带着相应的广告的信息,每一个请求里面有近百个相关的维度需要处理。每天日均触达的达到5亿+次,全年上线的活动5000+,服务100+品牌的客户。

二、加和的大数据服务挑战
(1) 服务场景的挑战
随着体量的增大,遇到一些问题和痛点:
一是数据量级大,服务运算复杂。服务的量级很大,这个量级每天都要去实时,需要分析或者是查找。客户在一定的时间范围内做活动信息的归纳,或者是跨媒体的去重的处理。
二是客户需求多变,需求复杂度大。客户的需求也是多变的,服务的客户分析的数据的维度非常多,每一个媒体用户不同标签属性上去做拆分去重,并不是统一化的需求,所以需要在大数据的范围内对这些需求进行处理。
三是计算量起伏大,峰值难以预估。随着客户的需求而走,整个计算的量级起伏也会比较大。客户有一波紧急的投放,会导致很多的媒体的流量都包下来,导致在短期的流量峰值会非常高。如果客户这段时间没有下单,量级也会相应的有些下降,服务成本和能力之间需要一个弹性支持的。
四是服务保障要求高。从媒体到请求,把信息发给第三方或者是流量监控的平台,再回来,最终把决策好要给用户产生什么样的素材,整个过程在100毫秒之内完成,要考虑多次的网络延时和计算的延时。如果产生一些数据的错误,会对客户的服务造成很大的影响。
(2) 自建大数据架构
加和科技选择自建的服务平台,数量级没那么大的时候选择了一款商用数据库去做整体的数据的支持。加和科技的服务体系一直在阿里云上面,但是数据库选择了一个商用数据库。当时也是平衡人员成本和服务的性能的要求,在复杂的分析的体系之下,商用数据库的性能还是比自己搭建的集群要好很多,而且相应的服务器成本也会更低。
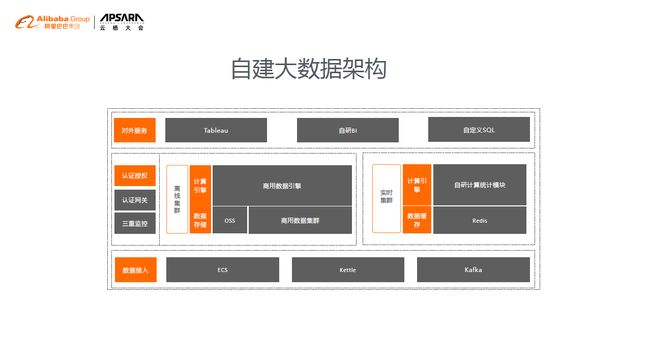
当时的数据来源主要是从ECS获得的一些日志,对数据实时性要求不高,更多的是离线分析。所以一开始用的是把日志做压缩,然后定时汇总到的数据集群去做处理的方式。再利用Kafka收集合作方的相关数据的信息,整合到业务报表后给客户呈现。
历史数据是存在OSS 上面,另外一个自研的BI 是用于展示对应的复杂数据报表,结果支持一些自主自拖拽的分析。从成本考虑,简化了数据分析的部分,利用小时级别的这种离线数据,再加上Redis 的缓存数据,去做了在线统计的模块。
(3) 历史架构服务痛点
历史结构有很多痛点,随着业务增长、数据量增长,出现了越来越多的问题。
首先,是计算弹性差。数据量不大的情况下,商用数据群还是可以比较快的做一些扩缩容。负载越大越难扩展、 应对突发故障困难、增减资源耗时不可控整,就会对业务造成拖累。如果出现服务器发生故障,整体的业务就会产生很大的影响。
其次,是数据管理很复杂。历经多年后,形成了很多中间表,数据难以划分、调控复杂度高、业务之间依赖高、 任务资源争抢,中间的逻辑关系很难梳理的。在计算中又产生一些资源消耗,就进一步加剧了对弹性的需求。
再次,是特定场景效率低。服务的场景经常用到大规模的数据交集,涉及对大量数据交集的查询。单一的数据引擎在某些场景下很快的,但在一些特定场景下效率不高,因为把数据都放在同样的集群里面去,所以它的效率会受比较大的影响。
最后,是计算消耗难以预估。这个从业务角度考量,成本不可控、 计算任务难以和业务打通,很难为客户提供一个标准化、可视化服务。
三、 加和大数据平台升级
(1) 升级后架构
调整最重要的环节在整个计算引擎的部分,把数据搬迁到了MaxCompute的平台上面,用DataWorks去做数据的调度和管理。 MaxCompute的使用带来了大幅的灵活性提升。
使用云环境扩缩容是比较方便的,计算的资源和存储的资源都获得了保障。也可以把原来的数据表做更好的分区分表的管理,可以看清楚这些数据怎样用,在中间的关系是怎样的,可以做更好的业务流程的管理。

在搬迁的时候,MaxCompute不支持这种开源的调度,后来是联合阿里云的一块开发,最终支持调用MaxCompute的任务的方式。变化比较大的是自研的BI2.0模块,之前的服务模块是自拖拽的一个产品,发现有的客户不会拖拽,这种方式也是难以接受的,现在改善成自动生成报表服务。这个服务目前看起来可以让客户大幅用起来,数据查询的数量会大幅的提升。
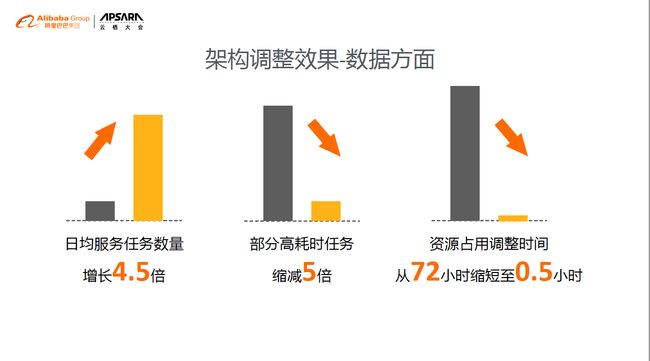
(2) 架构调整效果-数据方面
架构调整的效果,最显著的是数据方面。首先是日均用户数量有很大量的提升,从原来的每年的几百个实时的请求上升到几千个,一部分的耗时很高的任务通过MaxCompute也得到了解决。以前部分高耗时任务等待时间非常长,现在时间缩减5倍。以前整个资源的调整时间平均大概72小时左右,现在可能都不到半小时的时间,这是云带来的能力。
(3) 云原生大数据平台对加和的价值总结
最后,做了架构调整之后带来的一些变化,从几个角度来说:
一是响应业务需求能力提升。业务需求服务能力大幅提升,单次服务成本降低。业务成本可预估,提升业务服务效率;
二是服务稳定性和韧性提升。大幅降低资源调整耗时和难度、特定计算场景的耗时大幅下降;
三是数据团队能力转型。一方面从业务运维转化为业务推动,另一方面从数据分析转向机器学习;
四是扩展新应用场景。流程自动化和任务管理自动化、技术栈和业务的服务的持续优化。

总体来说,技术决策者,我们并没有用到很多复杂的开源技术,优化服务架构的时候,更多的考量是我们的业务弹性,和人员组成。作为技术决策者和技术从业者,更多关注技术供应链,依赖阿里云提供成熟的技术,我们的团队得以专注于解决业务问题,更多去灵活的组合市场上现有的技术,然后快速地支撑我业务的发展。这样专业化分工,专业的人做专业的事,让我们的团队可以更好地为客户服务。
原文链接
本文为阿里云原创内容,未经允许不得转载。