Hadoop编程学习(四):使用FileSystem类进行文件读写及查看文件信息
在这一节我们要深入了解Hadoop的FileSystem类——这是与与hadoop的文件系统交互的重要接口。虽然我们只是着重于HDFS的实现,但我们在编码时一般也要注意代码在FileSystem不同子类文件系统之间的可移植性。这是非常有用的,比如说你可以非常方便的直接用同样的代码在你的本地文件系统上进行测试。
使用hadoop URL读数据
从hadoop文件系统中读取文件的最简单的方法之一便是使用java.net.URL对象来打开一个欲从中读取数据的流(stream)。通常情况下的编程风格如下:
1 InputStream in = null; 2 try { 3 in = new URL("hdfs://host/path").openStream(); 4 // process in 5 } finally { 6 IOUtils.closeStream(in); 7 }
想要使java识别出hdfs开头的URL标示还需要一点其他的工作要做:通过URL的setURLStreamHandlerFactory()方法为java设置一个FSUrlStreamHandlerFactory。这个方法在每个JVM中只能调用一次,所以它通常会被放在一个static block中执行(如下所示),但如果你的某部分程序——例如一个你无法修改源代码的第三方组件——已经调用了这个方法,那你就不能通过URL来这样读取数据了(下一节我们会介绍另一种方法)。
1 public class URLCat { 2 static { 3 URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory()); 4 } 5 6 public static void main(String[] args) throws Exception{ 7 InputStream in = null; 8 try { 9 in = new URL(args[0]).openStream(); 10 IOUtils.copyBytes(in, System.out, 4096, false); 11 } finally { 12 // TODO: handle exception 13 IOUtils.closeStream(in); 14 } 15 } 16 }
上例中我们使用了Hadoop中的IOUtils类的两个静态方法:
1)IOUtils.copyBytes(),其中in表示拷贝源,System.out表示拷贝目的地(也就是要拷贝到标准输出中去),4096表示用来拷贝的buffer大小,false表明拷贝完成后我们并不关闭拷贝源可拷贝目的地(因为System.out并不需要关闭,in可以在finally语句中被关闭)。
2)IOUtils.closeStream(),用来关闭一个流。
下面是我们的测试例子:
| % hadoop URLCat hdfs://localhost/user/tom/quangle.txt On the top of the Crumpetty Tree The Quangle Wangle sat, But his face you could not see, On account of his Beaver Hat. |
使用FileSystem读取数据
就像上节所说的,有时候我们无法通过设置URLStreamHandlerFactory方法的方式来通过URL读取数据,这时FIleSystem API就派上用场了。
Hadoop文件系统中的文件是用Hadoop的Path对象来表示的(而不是java中的java.io.File对象,因为它的语义太接近于本地文件系统了)。你可以把一个Path对象看做Hadoop文件系统中的某一个URL,如上例中的“hdfs://localhost/user/tom/quangle.txt”。
Filesystem是一个通用的文件系统API,所以使用它的第一步就是先抽取出它的一个实例出来——在这个例子中是HDFS。下面列出了几个Filesystem的用于抽取Filesystem实例的几个静态方法:
| public static FileSystem get(Configuration conf) throws IOException public static FileSystem get(URI uri, Configuration conf) throws IOException public static FileSystem get(URI uri, Configuration conf, String user) throws IOException |
一个Configuration对象封装了客户端或服务器端的配置信息,这些配置信息是通过从conf/core-size.xml之类的配置文件中读取出来的名值对来设置的。下面我们一一说明上面的三个方法:
1)第一个方法返回一个默认的文件系统(在conf/core-site.xml中通过fs.default.name来指定的,如果在conf/core-site.xml中没有设置则返回本地文件系统)。
2)第二个方法通过uri来指定要返回的文件系统(例如,如果uri是上个测试例子中的hdfs://localhost/user/tom/quangle.txt,也即以hdfs标识开头,那么就返回一个hdfs文件系统,如果uri中没有相应的标识则返回本地文件系统)。
3)第三个方法返回文件系统的机理同(2)是相同的,但它同时又限定了该文件系统的用户,这在安全方面是很重要的。
有时候你可能想要使用一个本地文件系统,你可以使用另一个很方便的方法:
public static LocalFileSystem getLocal(Configuration conf) throws IOException
得到一个文件系统的实例后,我们可以调用该实例的open()方法来打开某个给定文件的输入流(第一个方法使用一个默认的4KB的输入缓冲):
| public FSDataInputStream open(Path f) throws IOException public abstract FSDataInputStream open(Path f, int bufferSize) throws IOException |
把上面介绍的组合起来我们就得到了下面的代码:
1 public class FileSystemCat { 2 public static void main(String[] args) throws Exception { 3 String uri = args[0]; 4 Configuration configuration = new Configuration(); 5 FileSystem fs = FileSystem.get(URI.create(uri), configuration); 6 InputStream in = null; 7 try{ 8 in = fs.open(new Path(uri)); 9 IOUtils.copyBytes(in, System.out, 4096, false); 10 } finally { 11 IOUtils.closeStream(in); 12 } 13 } 14 }
FSDataInputStream
与URL的openStream()方法返回InputStream不同,FileSystem的open()方法返回的是一个FSDataInputStream对象(继承关系:java.io.InputStream --> java.io.FilterInputStream --> java.io.DataInputStream --> org.apache.hadoop.fs.FSDataInputStream)。由于FSDataInputStream实现了Closeable, DataInput, PositionedReadable, Seekable等接口,你可以从流中的任意一个位置读取数据。
Seekable接口的seek()和getPos()方法允许我们跳转到流中的某个位置并得到其位置:
| public interface Seekable { void seek(long pos) throws IOException; long getPos() throws IOException; } |
如果调用seek()时指定了一个超过文件长度的位移值,会抛出IOException异常。
与java.io.Inputstream的skip()方法指明一个相对位移值不同,seek()方法使用的是绝对位移值。如下所示的代码通过seek()方法读取了两次输入文件:
1 public class FileSystemDoubleCat { 2 public static void main(String[] args) throws Exception { 3 String uri = args[0]; 4 Configuration conf = new Configuration(); 5 FileSystem fs = FileSystem.get(URI.create(uri), conf); 6 FSDataInputStream in = null; 7 try { 8 in = fs.open(new Path(uri)); 9 IOUtils.copyBytes(in, System.out, 4096, false); 10 in.seek(0); // go back to the start of the file 11 IOUtils.copyBytes(in, System.out, 4096, false); 12 } finally { 13 IOUtils.closeStream(in); 14 } 15 } 16 }
运行结果如下:
| % hadoop FileSystemDoubleCat hdfs://localhost/user/tom/quangle.txt On the top of the Crumpetty Tree The Quangle Wangle sat, But his face you could not see, On account of his Beaver Hat. On the top of the Crumpetty Tree The Quangle Wangle sat, But his face you could not see, On account of his Beaver Hat. |
FSDataInputStream也实现了 PositionedReadable接口,这允许你从流中的某个给定位置读取给定长度的内容:
| public interface PositionedReadable { public int read(long position, byte[] buffer, int offset, int length) throws IOException; public void readFully(long position, byte[] buffer, int offset, int length) throws IOException; public void readFully(long position, byte[] buffer) throws IOException; } |
说明:read()方法从文件的给定position出读取length个字节到buffer的offset处。返回值是读取到的实际字节数,调用者应该检查这个返回值,因为它可能比length小(可能读到了文件末尾,或发生了中断等等)。
调用所有的这些方法并不会改变文件的偏移值,所以这些方法是线程安全的。也由此提供了一种当访问某文件的内容时访问该文件的另一部分数据——例如元数据——的很方便的方法。
最后需要注意的是调用seek()方法的代价比较高,应尽量避免使用。你的程序应该基于流式访问来构建,而不是执行一大堆seek。
写数据
FileSystem类有很多方法用来创建一个文件,最简单的就是以欲创建文件的Path对象为参数的create(Path f)方法,该方法返回一个用来写入数据的输出流:
public FSDataOutputStream create(Path f) throws IOException
该方法还有几个重载的方法,通过这些重载的方法你可以指定是否覆盖该文件名已存在的文件,这个文件的备份数,用来写数据的buffer size,该文件的block大小和文件权限等。
| create()方法会创建指定的文件名中包含的任何不存在的父目录,这样虽然很方便,但不推荐使用(因为如果某个父目录中存在其他数据,会被覆盖掉从而导致文件丢失)。如果你想要当父目录不存在时该创建操作失败,你可以在调用create()方法之前调用exists()方法检查指明的父目录是否存在,如果存在则报错以让create()失败 |
create()方法还有一个重载方法可以让你传递一个回调的借口——progressable,这样你的程序就会知道你的数据被写入了多少,也即写入的进度(progress):
| package org.apache.hadoop.util; public interface Progressable { public void progress(); } |
除了创建一个新文件以写入数据以外,我们还可以使用append()方法向一个已存在文件添加数据:
public FSDataOutputStream append(Path f) throws IOException
有了这个函数,应用程序就可以向那些不能限制大小的文件(如logfile,你事先并不知道待记录日志会有多少)写数据了。append操作在Hadoop的fileSystem中是可选的,例如HDFS实现了它,但S3就没有。
下面这个例子展示了如何从本地文件系统拷贝一个文件到HDFS,我们在每64KB大小的数据写入之后调用一次progress()函数,这个函数每被调用一次打印一个句点:
1 public class FileCopyWithProgress { 2 public static void main(String[] args) throws Exception { 3 String localSrc = args[0]; 4 String dst = args[1]; 5 InputStream in = new BufferedInputStream(new FileInputStream(localSrc)); 6 Configuration conf = new Configuration(); 7 FileSystem fs = FileSystem.get(URI.create(dst), conf); 8 OutputStream out = fs.create(new Path(dst), new Progressable() { 9 public void progress() { 10 System.out.print("."); 11 } 12 }); 13 IOUtils.copyBytes(in, out, 4096, true); 14 } 15 }
下面是该例子的示范用法:
| % hadoop FileCopyWithProgress input/docs/1400-8.txt hdfs://localhost/user/tom/ 1400-8.txt ............... |
注:现在除了HDFS以外的其他Hadoop支持的文件系统都不支持progress()方法,但我们应该知道进度信息(pregress)在MapReduce程序中是非常重要的。
FSDataOutputStream
FileSystem中的create()方法返回一个FSDataOutputStream,像FSDataInputStream一样,它也有一个用于查询位移的方法(但并没有类似于FSDataInputStream中seek()的方法,因为Hadoop不允许向流中的任意位置写数据,我们只能在一个文件的末尾处添加数据):
| package org.apache.hadoop.fs; public class FSDataOutputStream extends DataOutputStream implements Syncable { public long getPos() throws IOException { // implementation elided } // implementation elided } |
查询某个文件系统
文件元数据:FileStatus
任何文件系统的典型功能就是能够遍历它的目录结构从而获取有关目录和文件的信息。Hadoop中的FileStatus类为文件和目录包装了其元数据(包括文件长度,block大小,冗余度,修改时间,文件所有者和权限等信息),其getFileStatus()方法提供了获取某个给定文件或目录的FileStatus对象的途径,如下所示:
1 public class ShowFileStatusTest { 2 private MiniDFSCluster cluster; // use an in-process HDFS cluster for testing (这个类在最新的Hadoop1.0.4中已经被废弃了) 3 4 private FileSystem fs; 5 6 @Before 7 public void setUp() throws IOException { 8 Configuration conf = new Configuration(); 9 if (System.getProperty("test.build.data") == null) { 10 System.setProperty("test.build.data", "/tmp"); 11 } 12 cluster = new MiniDFSCluster(conf, 1, true, null); 13 fs = cluster.getFileSystem(); 14 OutputStream out = fs.create(new Path("/dir/file")); 15 out.write("content".getBytes("UTF-8")); 16 out.close(); 17 } 18 19 @After 20 public void tearDown() throws IOException { 21 if (fs != null) { 22 fs.close(); 23 } 24 if (cluster != null) { 25 cluster.shutdown(); 26 } 27 } 28 29 @Test(expected = FileNotFoundException.class) 30 public void throwsFileNotFoundForNonExistentFile() throws IOException { 31 fs.getFileStatus(new Path("no-such-file")); 32 } 33 34 @Test 35 public void fileStatusForFile() throws IOException { 36 Path file = new Path("/dir/file"); 37 FileStatus stat = fs.getFileStatus(file); 38 assertThat(stat.getPath().toUri().getPath(), is("/dir/file")); 39 assertThat(stat.isDir(), is(false)); 40 assertThat(stat.getLen(), is(7L)); 41 assertThat(stat.getModificationTime(), 42 is(lessThanOrEqualTo(System.currentTimeMillis()))); 43 assertThat(stat.getReplication(), is((short) 1)); 44 assertThat(stat.getBlockSize(), is(64 * 1024 * 1024L)); 45 assertThat(stat.getOwner(), is("tom")); 46 assertThat(stat.getGroup(), is("supergroup")); 47 assertThat(stat.getPermission().toString(), is("rw-r--r--")); 48 } 49 50 @Test 51 public void fileStatusForDirectory() throws IOException { 52 Path dir = new Path("/dir"); 53 FileStatus stat = fs.getFileStatus(dir); 54 assertThat(stat.getPath().toUri().getPath(), is("/dir")); 55 assertThat(stat.isDir(), is(true)); 56 assertThat(stat.getLen(), is(0L)); 57 assertThat(stat.getModificationTime(), 58 is(lessThanOrEqualTo(System.currentTimeMillis()))); 59 assertThat(stat.getReplication(), is((short) 0)); 60 assertThat(stat.getBlockSize(), is(0L)); 61 assertThat(stat.getOwner(), is("tom")); 62 assertThat(stat.getGroup(), is("supergroup")); 63 assertThat(stat.getPermission().toString(), is("rwxr-xr-x")); 64 } 65 }
Listing files
除了从某个单一文件或目录获取文件信息以外,你可能还需要列出某个目录中的所有文件,这就要使用FileSystem的listStatus()方法了:
| public FileStatus[] listStatus(Path f) throws IOException public FileStatus[] listStatus(Path f, PathFilter filter) throws IOException public FileStatus[] listStatus(Path[] files) throws IOException public FileStatus[] listStatus(Path[] files, PathFilter filter) throws IOException |
当传入参数是一个文件时,它获取此文件的FileStatus对象,当传入文件是目录时,它返回零个或多个FileStatus对象,分别代表该目录下所有文件的对应信息。
重载后的函数允许你指定一个PathFilter来进一步限定要匹配的文件或目录。
下面我们使用listStatus()方法获得参数中指定的文件(可以有多个)的元数据信息,存放在一个FIleStatus数组中,再使用stat2Paths()方法吧FileStatus数组转化为Path数组,最后打印出文件名来:
1 public class ListStatus { 2 public static void main(String[] args) throws Exception { 3 String uri = args[0]; 4 Configuration conf = new Configuration(); 5 FileSystem fs = FileSystem.get(URI.create(uri), conf); 6 Path[] paths = new Path[args.length]; 7 for (int i = 0; i < paths.length; i++) { 8 paths[i] = new Path(args[i]); 9 } 10 FileStatus[] status = fs.listStatus(paths); 11 Path[] listedPaths = FileUtil.stat2Paths(status); 12 for (Path p : listedPaths) { 13 System.out.println(p); 14 } 15 } 16 }
运行结果如下:
| % hadoop ListStatus hdfs://localhost/ hdfs://localhost/user/tom hdfs://localhost/user hdfs://localhost/user/tom/books hdfs://localhost/user/tom/quangle.txt |
文件模式
在某个单一操作中处理一些列文件是很常见的。例如一个日志处理的MapReduce作业可能要分析一个月的日志量。如果一个文件一个文件或者一个目录一个目录的声明那就太麻烦了,我们可以使用通配符(wild card)来匹配多个文件(这个操作也叫做globbing)。Hadoop提供了两种方法来处理文件组:
| public FileStatus[] globStatus(Path pathPattern) throws IOException public FileStatus[] globStatus(Path pathPattern, PathFilter filter) throws IOException |
globStatus()方法返回匹配文件模式的多个文件的FileStatus数组(以Path排序)。一个可选的PathFilter可以用来进一步限制匹配模式。Hadoop中的匹配符与Unix中bash相同,如下所示:

假设某个日志文件的组织结构如下:

则对应于该组织结构有如下表示:
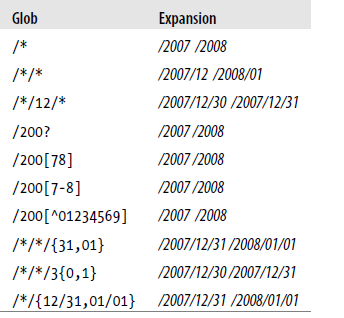
PathFilter
使用文件模式有时候并不能有效的描述你想要的一系列文件,例如如果你想排除某个特定文件就很难。所以FileSystem的listStatus()和globStatus()方法就提供了一个可选参数:PathFilter——它允许你一些更细化的控制匹配:
| package org.apache.hadoop.fs; public interface PathFilter { boolean accept(Path path); } |
PathFilter的作用就像java.io.FileFilter,只不过前者针对Path对象,而后者针对File对象。下面我们用PathFIlter来排除一个符合给定正则表达式的文件:
1 public class RegexExcludePathFilter implements PathFilter { 2 private final String regex; 3 4 public RegexExcludePathFilter(String regex) { 5 this.regex = regex; 6 } 7 8 public boolean accept(Path path) { 9 return !path.toString().matches(regex); 10 } 11 }
RegexExcludePathFilter只让不匹配(具体参见accept方法的实现)给定正则表达式的文件通过,我们通过文件模式(file pattern)得到所需的文件集后,再用RegexExcludePathFilter来过滤掉我们不需要的文件:
fs.globStatus(new Path("/2007/*/*"), new RegexExcludeFilter("^.*/2007/12/31$"))
这样我们就得到:/2007/12/30
注意:Filter只能根据文件名来过滤文件,是不能通过文件的属性(如修改时间,文件所有者等)来过滤文件的。但它仍然提供了文件模式和正则表达式所不能提供的功能。
删除数据
使用FIleSystem的delete()方法可以永久的删除一个文件或目录:
public boolean delete(Path f, boolean recursive) throws IOException
如果传入的Path f是一个文件或者空目录,recursive的值会被忽略掉。当recursive值为true时,给定的非空目录连同其内容会被一并删除掉。
转载请注明出处:http://www.cnblogs.com/beanmoon/archive/2012/12/11/2813235.html