Double-Scale Self-Supervised Hypergraph Learning for Group Recommendation 论文笔记
Double-Scale Self-Supervised Hypergraph Learning for Group Recommendation
topic:
(1)定义了用户层、组层超图(解决现有方法未考虑到的复杂交互)
(2)双粒度自监督体系(解决稀疏问题)
提出模型:
模型三部分:
Hierarchical hypergraph,通过将信息从用户级传递到组级,来描述组内和组外的用户交互
Double-scale self-supervised learning, 包含粗粒度和细粒度的节点dropout策略,以细化用户和群组表示,缓解数据稀疏问题;
Model Optimization, 统一了群体推荐和自监督学习的目标,增强了两项任务。
1、Hierarchical Hypergraph Convolution
1.1 User-Level hypergraph
User representation learning
![]()
$$pl$$是指第l层超图卷积网络的user embedding
$$Dul、Bul$$分别是用户节点度矩阵、超边的度矩阵
$$Hul$$是表示节点和超边关系的关联矩阵(一个超边可以连接多个节点)
$$Wul$$是超边的权重对角矩阵,用单位矩阵来初始化
是两个卷积层之间的参数矩阵
Group representation learning

$$zg是群体表示$$
是用户u在群组决策中的权重
pj表示同一群组中的其他成员向量
d*d的矩阵wagg和d维向量x都是用于计算权重的参数。
1.2 Group-Level hypergraph
Hypergraph construction
将用户级超图转换为投影图,其中组超边充当节点。,如果两个组超边有共同的用户成员,则将它们连接起来,确保组间偏好的相关性。然后采用三角形来选择群体层次超图中最相关的群体。如果有三角形,将这三组定义为一个hyperedge。

Group representation learning
当不考虑自连接时,基于motif的邻接矩阵可以计算为表示为:
模体(Motif)是指序列中局部的区域,或者是一组序列中共有的一小段序列模式。

Hgl是群组超图的关联矩阵
![]() 是指投影图的对称邻接矩阵(如果群组i和群组j有连接,则cij=1,否则为0 )
是指投影图的对称邻接矩阵(如果群组i和群组j有连接,则cij=1,否则为0 )
CC表示连接三个顶点的路径,后面对C进行的的操作将路径转换为了必闭合三角形
群组超图的卷积操作为(由于自连接对性能的影响很小,故下列公示与1.1的卷积公式等价。):
![]()
Dgl是(基于motif的邻接矩阵)的度矩阵
φ(l)是l层的参数矩阵
z(l)是第l层的群体表示,z(0)=z~ z~从基于注意力的群体偏好聚合器中学习
1.3 Loss function
采用pairwise学习任务丢失函数优化用户级超图中的用户和项目表示,其设计如下: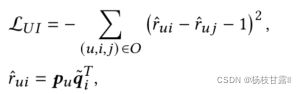
pu、qi表示user和item的嵌入向量
o表示训练集,其中每个训练集包括用户u、交互项i和未观察项j。
目标是使阳性样本和阴性样本之间的差值尽可能接近1。
组级超图的loss function:
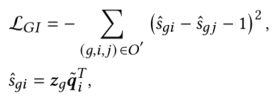
zg是从基于注意的偏好聚合策略中学习到的群体表征
总的损失:
![]()
2、Boosting Group Recommendation with Double-Scale Self-Supervision
group-item交互稀疏、user-item交互也稀疏
为解决这一问题和增强用户和组的表现,double-scale dropout层次超图(包括粗和细粒度)增加原始数据并创建两种类型的自监督信号对比学习提高HHGR的性能,变成了S²-HHGR
Coarse-grained node dropping strategy粗粒度
其中dropout节点的规模是一个超参数。(与简单图中删除连接边的节点删除不同,丢弃超图中的某些节点时,超边可能不会被删除。当一个被删除的节点属于多个组超边时,该节点将在所有特定的超边中被删除。)
![]()
hc表示粗粒度超图关联矩阵Hc的列向量
$$fcoarse$$是粗粒度dropout函数
![]()
ac是一个用于控制Hul(上面提到的关联矩阵)中节点dropout规模的,在给定的概率下为0的mask 向量; ⊙表示elemen-twise乘积,表示mask向量将与用户级超图关联矩阵(Hul)中的每一列相乘
粗粒度dropout以后可以得到一个扰动用户级超图。我们通过一个新的超图卷积网络gc(·)对其进行编码,得到粗粒度用户表示P',作为原始用户表示的一个数据扩充:![]()
┏ 表示粗粒度超图卷积网络中的参数矩阵
P'(0)=p~ p~ 是随机初始化的d维表示矩阵。
Fine-grained node dropping strategy细粒度
我们通过在特定的组中减少一定数量的用户来干扰超图的构造,类似的,
$$ffine$$细粒度dropout函数有如下关系
![]()
hf表示粗粒度超图关联矩阵Hf的列向量
af是细粒度mask向量,它将在一个超边中以固定的概率丢弃节点。
与粗粒度策略不同:每次af乘以hul时,它都被重新分配。接下来,我们将P“”编码为g(·),以获得新的用户表示:![]()
最终表示:![]()
Contrastive learning
在建立了节点的不同粒度扩展视图之后,将同一节点的粒度视为正对,将任何不同粒度的节点视为负对。我们希望两个pretext任务(该任务不是目标任务,但是通过执行该任务可以有助于模型更好的执行目标任务)的用户表示向量分布能尽可能接近。 设计判别器函数fD(.) 来学习两个输入向量之间的分数,并给阳性样本比阴性样本更高的分数。采用交叉熵损失: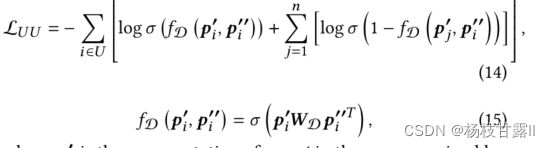
其中p是粗粒度超图中用户j的表示;n是从同一批次中随机选择的阴性样本数。
3、Model Optimization
统一了组推荐任务和自监督学习任务的损失函数, 使用Adam算法训练模型。总体目标定义如下:![]()
β 是超参数,用于平衡自监督学习任务和团体推荐的监督学习任务。
4、Complexity Analysis
Model size
该模型的参数组成:1)层次超图卷积网络;2)基于注意的群体偏好聚合器;3)判别器网络。
粗粒度和细粒度用户级超图卷积网络具有大小为 2**的参 数。组级超图卷积网络的参数大小是**. 偏好聚合器中的可训练加权矩阵的参数大小是 3** ;鉴别器fD 中的权重矩阵WD大小为*.
Time complexity
计算代价主要来自两部分:层次超图卷积(主要花销来自信息传播)和双scale自监督学习策略。
(1)层次超图卷积(主要花销来自信息传播):
通过l次传播,少于O(l*|H|*d), |H|表示关联矩阵中非零元素的个数。 由于我们的模型包含一个用户级超图卷积网络和一个群级超图卷积网络,因此层次超图卷积神经网络的时间复杂度约为:![]()
(2)自监督学习策略:
其成本来源于不同粒度和对比学习的超图生成。 生成超图的时间成本小于O(2*M*M). 对比学习的时间成本小于O(|U|*n) ,n是负样本的数量。
EXPERIENCE AND RESULTS
研究问题:
RQ1:与目前最先进的group推荐模型相比,该模型表现如何
RQ2:该模型中,每个组件(即层次超图和自我监督学习)的有效性是啥
RQ3:超参数是如何影响S²-HHGR的效率的
1、Experimental Settings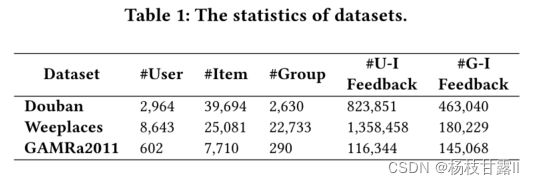
Weeplaces数据集包括用户在基于地理位置的社交网络中的签到历史。遵循GroupIM[32],通过使用用户签到记录和他们的社交网络来构建组交互。
CAMRa2011,是一个包含个人用户和家庭记录的电影评级数据集。遵循AGREE[6]的思想,将显式评级转换为隐式偏好,其中评级记录被视为1。
Douban数据集来自豆瓣平台,包含了各种群体社交活动。不包含显式的组信息,遵循SIGR[44]的思想提取隐式的组数据。具体来说,将参与过相同活动的用户好友视为群组成员。三个数据集的统计信息如表1所示。
随机分为训练组:验证组:测试组=7:1:2
Baselines
Popularity: 根据项目的受欢迎程度对其进行排名。
NeuMF: 一种基于神经网络的协同过滤模型,用于评测推荐性能。 本文将所有组视为虚拟用户,并利用组项交互来生成组偏好。
AGREE: 利用注意偏好聚合计算群体成员权重,利用神经协同过滤学习群体-项交互。
MoSAN: 使用一组亚注意sub-attentional网络来学习每个用户的偏好,并模拟成员之间的互动。
SIGR: 最先进的群体推荐模型,它引入了一个潜在变量和注意机制,以了解用户在本地和全球的社会影响力。利用二部图嵌入模型解决了数据稀疏性问题。
GroupIM: 通过注意机制将用户偏好聚合为群体偏好。它最大限度地提高了用户表示和所属组表示之间的相互信息,从而缓解了数据稀疏性问题。
Evaluation metrics
NDCG 评估推荐列表中真实项目的排名、Recall@k 是在Top-K相关条目中检索到的相关条目的比例。k是{20,50}
Parameter settings
embedding size is 64
batch size for the mini-batch is 512,
The number of negative samples is 10.
双scale自我监督学习的训练过程中,初始学习率为5e-4
群组超图训练学习率1e-4
用户级和群级超图神经网络的结构分别为两层和一层。对于baselines,我们参考原始论文中报告的最佳参数设置,如果我们使用相同的数据集和评估设置,则直接报告其结果。
2、Recommendation Performance Comparison (RQ1)
一般性能
基于注意力的组模型在大多数数据集上优于基线推荐器(即Popular和NeuMF)(它们能够动态建模组内的用户交互,并学习组中不同成员的各种权重)
在基于注意机制的模型中,HHGR优于大多数模型(包括AGREE、MoSAN和SIGR)。我们认为,HHGR的性能改进验证了超图和超图神经网络模块在开发高阶用户交互方面的有效性。
SIGR比AGREE和MoSAN表现得更好,因为它考虑了二部图的形式来表示用户-项交互,尤其是在CAMRa2011数据集上。此外,MoSAN还因为偏好聚合器在群体条目交互中捕获不同个人权重的表达能力而取得了更好的结果。
在稀疏数据集上的性能
只在weeplaces上展开基于注意力的模型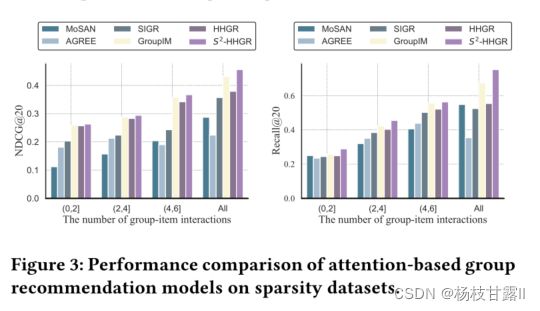
NDCG和Recall通常会随着物品交互组数的增加而增加,因为更多的交互将为学习群体偏好表示提供更多的信息。 超图神经网络中的双scale dropout策略,该策略可以增强群体偏好的表征。
3、Ablation Study (RQ2)
Investigation of the hierarchical hypergraph
HHGR-wg去掉组级,只考虑用户级超图,这意味着从偏好聚合器生成的组偏好表示是最终的组偏好 HHGR-wu去掉用户级,采用组项交互信息初始化组优先级,只考虑组级超图更新组优先级。
Investigation of self-supervised learning.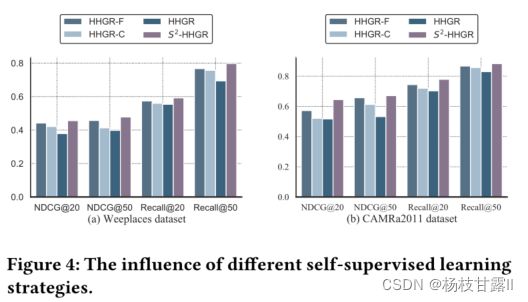
HHGR - F表示只考虑细粒度的节点丢弃。HHGR - C意味着只使用粗粒度的节点丢弃
缺一不可,细粒度的贡献度最大
Different extent of self-supervised learning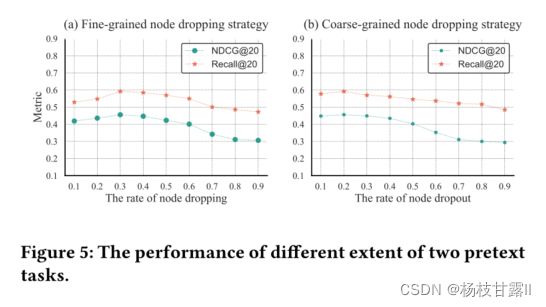
dropout可以随着丢弃强度的增加而提高HHGR性能,但过多的删除会加剧数据稀疏问题。
4、Parameter Sensitivity Analysis (RQ3)
分析的超参数包括学习速率、超图卷积层的深度、批量大小的数量和负样本的数量。
最佳:学习率5e-4; 超图卷积层深度为2(太多了下降可能是因为过平滑);批大小512; 负样本10(少量的负面样本可以促进推荐任务,而大量的负面样本则会误导推荐任务)
RELATED WORK
Group Recommendation
Hypergraph-Based Recommendation
Self-Supervised Learning in RS
CONCLUSION AND FUTURE WORK
在未来的工作中,我们倾向于深化自我监督学习在小组推荐模型中的应用,为推荐设计更多通用的辅助任务,以提高推荐的性能。