记一次TCP TIME_WAIT引发的血案
前言
记录线上一次故障,状态延迟,状态使用短连接,长轮训的方式获取,在每天的固定时间点,出现状态延迟,持续几分钟,然后又莫名其妙的恢复了,很是怪异,下面就来复盘下,这次问题的定位和思考。
冰山一角
我们可以掌握的线索有
1.固定的时间点,发生。
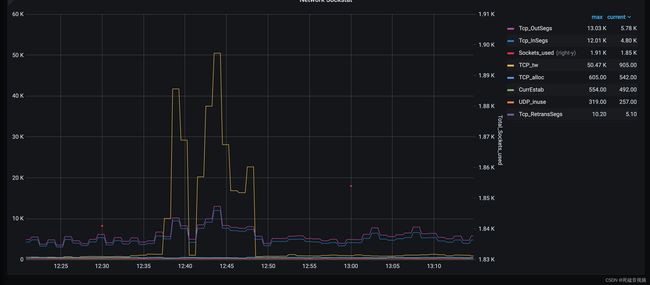
2.通过监控可以看到,流量并不高,但是TCP TIMEWAIT一瞬间疯涨
3.出问题的时间点,远程客户的电脑(全内网),ping网关和服务器,发现有大量延时
4.有同事通过jstat看,发现gc的次数很多,认为gc导致了接口延时。
5.接口超时的时间点,CPU不高,内存不高,I/O不高,系统负载不高,也就是未达到机器的性能瓶颈。机器配置16核64g
软件版本:
- 操作系统 centos7.9
- JDK 1.6
- nginx7.7
由于,这个问题牵涉的大客户,很多技术人员,投入进来一起攻破,每个人的想法不一致,导致问题更难以统一突破。
一部分人,认为是网络问题,和某为扯了半天,没有个所以然
一部分人,认为gc太频繁,full gc次数太多了,所以需要gc调优
一部分人,认为需要在测试环境,压测,测试出系统瓶颈
实施的方案
抛开以上的言论,我们回到线索上
1、每天固定时间出现,询问客户,这个时间段是否是业务高峰期。
回答:是
2、从监控来看,TCP-TIMEWAIT高,那我们就要先定位到系统部署方案。
系统部署方案如下
1.nginx反向代理java服务。
nginx监听443端口
java服务监听8080端口
每一次轮训,发起http请求,通过nginx,nginx请求java服务
查看8080端口的tcp端口timewait个数,发现全是timewait,现在可以确定的是nginx和tcp连接出现了大量的timewait,导致接口延时。
翻了运维的调优记录如下:
- 根据监控看,丢弃的连接数比较多
| 修改后 | 当前情况 | 说明 |
|---|---|---|
| net.core.netdev_max_backlog = 16384 | net.core.netdev_max_backlog = 1000 | 系统建立全链接队列长度(TCP三次握手成功后的连接放入队列) |
| net.ipv4.tcp_max_syn_backlog = 8192 | net.ipv4.tcp_max_syn_backlog = 512 | 系统建立半链接队列长度(TCP三次握手过程中的连接放入队列) |
| net.core.somaxconn = 4096 | net.core.somaxconn = 128 | 系统建立全链接队列(TCP三次握手成功后的连接放入队列 系统级别的 |
TCP 建立连接时要经过 3 次握手,在客户端向服务器发起连接时,对于服务器而言,一个完整的连接建立过程,服务器会经历 2 种 TCP 状态:SYN_REVD, ESTABELLISHED
对应也会维护两个队列:
一个存放 SYN 的队列(半连接队列)
一个存放已经完成连接的队列(全连接队列)
- ESTABLISHED列长度如何计算?
如果 backlog 大于内核参数 net.core.somaxconn,则以 net.core.somaxconn 为准,
即全连接队列长度 = min(backlog, 内核参数 net.core.somaxconn),net.core.somaxconn 默认为 128。
这个很好理解,net.core.somaxconn 定义了系统级别的全连接队列最大长度,
backlog 只是应用层传入的参数,不可能超过内核参数,所以 backlog 必须小于等于 net.core.somaxconn。
- SYN_RECV队列长度如何计算?
半连接队列长度由内核参数 tcp_max_syn_backlog 决定,
当使用 SYN Cookie 时(就是内核参数 net.ipv4.tcp_syncookies = 1),这个参数无效,
半连接队列的最大长度为 backlog、内核参数 net.core.somaxconn、内核参数 tcp_max_syn_backlog 的最小值。
即半连接队列长度 = min(backlog, 内核参数 net.core.somaxconn,内核参数 tcp_max_syn_backlog)。
这个公式实际上规定半连接队列长度不能超过全连接队列长度,但是tcp_syncooking默认是启用的,如果按上文的理解,那这个参数设置没有多大意义
其实,对于 Nginx/Tomcat 等这种 Web 服务器,都提供了 backlog 参数设置入口,当然它们都会有默认值,通常这个默认值都不会太大(包括内核默认的半连接队列和全连接队列长度)。如果应用并发访问非常高,只增大应用层 backlog 是没有意义的,因为可能内核参数关于连接队列设置的都很小,一定要综合应用层 backlog 和内核参数一起看,通过公式很容易调整出正确的设置
- nginx调优
nginx到java建立的连接Timewait比较大,优化nginx配置,降低握手次数。
upstream node {
server 127.0.0.1:8080;
keepalive 10000; //新增
keepalive_timeout 65s; //新增
keepalive_requests 20000; //新增
}
- 从以上记录看,似乎都和TCP连接数有关。
解决思路如下:
1.长轮训 短连接改为websocket方案
评估:不确定因素太多,客户要限时解决问题,不敢上线
2.降低tcp 连接数,根据业务拆分,降低请求量。
3.控制timewait数量,保证业务高峰期不会发生太大的抖动
4.询问业务人员,请求会分配到一个线程的处理,并且没有限制线程数量,所以如果请求量很大,应该会有很多线程,并且cpu应该有很高的使用量,而现在cpu的使用量很低,不太正常。使用jstack打印线程情况
实施
-
找到运维沟通,tcp的连接数设置高点。然而被告知最多只能创建65535个。这个问题我们稍后在细聊下。
-
控制TCP TIMEWAIT的数量,设置参数
net.ipv4.tcp_max_tw_buckets=1024
- jstack打印线程池,发现有很多线程在等待同一个锁。
锁是使用synchronized关键字,锁的是HashTable一个数组,锁的代码逻辑,处理比较长。
优化:拆分锁的逻辑,不需要一致性的数据踢出去。
后记
一台机器最多能创建多少个TCP连接?
上面的截图中,tcp timewait的个数太多,到了65535限制,导致连接被重置,那为什么有这个结论呢
注意看上面的nginx配置
upstream node {
server 127.0.0.1:8080;
keepalive 10000; //新增
keepalive_timeout 65s; //新增
keepalive_requests 20000; //新增
}
这里指定了去连接127.0.0.1的8080端口,那么nginx去连接java服务的时候如下:
| 源ip | 源端口 | 目标ip | 目标端口 |
|---|---|---|---|
| 127.0.0.1 | 20000 | 127.0.0.1 | 8080 |
| 127.0.0.1 | 20001 | 127.0.0.1 | 8080 |
| 127.0.0.1 | 20002 | 127.0.0.1 | 8080 |
所以为什么会说一个机器上最多65535个端口数。
这个端口号16位的,可以有0~65535端口数是针对单个ip来描述的,那我们在机器上可不是只有一个ip,所以理论上端口数是无上限的,配置nginx的时候这里需要注意上。
- 端口号的上限不一定是65535
如果你有幸见过cannot assign requested address
那么你一定知道
Linux对可使用的范围端口有具体限制,使用以下命令查看
cat /proc/sys/net/ipv4/ip_local_port_range
1024 65000
- 文件描述符
Linux 下一切皆文件
我们突破tcp端口限制的时候,很可能会遇到以下错误too many open files
每建立一个TCP连接,会分配一个文件描述符,linux 对可打开的文件描述符的数量分别作了三个方面的限制。
系统级:当前系统可打开的最大数量,通过 cat /proc/sys/fs/file-max 查看
用户级:指定用户可打开的最大数量,通过 cat /etc/security/limits.conf 查看
进程级:单个进程可打开的最大数量,通过 cat /proc/sys/fs/nr_open 查看
- C10K
每创建一个TCP连接,操作系统都需要消耗一个线程,当我们TCP连接数过多,会导致线程不停的上下文切换,导致cpu处理时间越来越长。
C10K就是早期单机性能的瓶颈代名词。所以后续有了 I/O多路复用模型。
何时进行JVM调优?
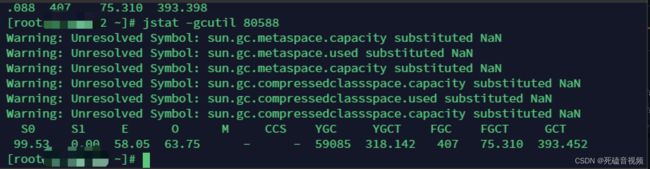
还记得上面说过,通过jstat看到gc很频繁,full gc次数很多,所以建议GC调优吗?
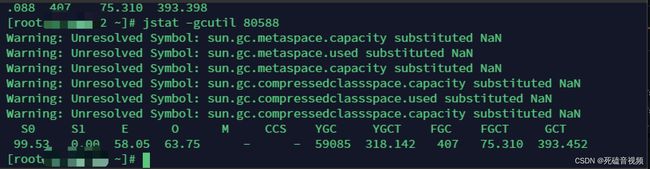
我们看关键指标
YGC 59085 Young GC次数
YGCT 318.142 Young 总时间 单位秒
FGC 407 Full GC 次数
FGCT 75.310 Full GC 总时间,单位为妙
我们看平均时间
年轻代平均gc时间
318.142/59085=0.0005
- 老年代平均gc时间
75.310/407=0.185
我们可以看到GC的次数很多,但是GC的平均时间并不高。
但是这并不是万能的
有一种情况比如Full GC发生了10次,平均值不高,但是某几次的Full GC时间为5~6秒,所以为了更确定这个问题,我们可以使用启动参数,查看每次GC的时间。
-verbose:gc -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:./gc.log
![]()
查看当天gc日志,Full gc时间并不高,可以排除,GC引起的问题。
所有的优化,GC调优应该是最后的手段,更多的是优化我们的代码。