基于MATLAB的计算机视觉与深度学习实战
基于深度学习的汽车目标检测
一、项目任务
随着标记数据的积累和GPU高性能汁算技术的发展,卷积神经网络的研究和应用也不断涌现出新的成果。本项目使用己标记的小汽车样本数据训练RCNN(Regions uith Convolutional Neural Networks, RCNN)神经网络得到检测器模型,并采用测试样本对训练好的检测器模型进行准确率评测,实现汽车目标检测的效果。
二、项目内容
1.了解神经网络,卷积层、池化层、全连接层等;
2.搭建卷积神经网络;
3.训练卷积神经网络得出模型;
4.利用模型进行预测图片汽车目标位置。
三、项目步骤
3.1 神经网络基础
3.1.1 神经网络
神经网络的单条神经元是模仿人体神经元构造的,经过一定权重与偏置进行计算得出结果,但人体神经网络十分复杂,人们也构造出人工神经网络通过模拟大脑神经网络处理、记忆信息的方式进行信息处理。
人工神经网络也由最初的输入层、隐藏层、输出层渐渐发展起来,2012年Alex Krizhevsky提出AlexNet,夺得2012年ILSVRC比赛的冠军,top5预测的错误率为16.4%,远超第一名。自此人工神经网络声名大噪,由此越来越多的研究者开始着手研究神经网络,神经网络也飞速发展起来。
人工神经网络按其模型结构大体可以分为前馈型网络(也称为多层感知机网络)和反馈型网络(也称为Hopfield网络)两大类,前者在数学上可以看作是一类大规模的非线性映射系统,后者则是一类大规模的非线性动力学系统。按照学习方式,人工神经网络又可分为有监督学习、非监督和半监督学习三类;按工作方式则可分为确定性和随机性两类;按时间特性还可分为连续型或离散型两类,等等。
3.1.2 卷积层
卷积层(Convolutional layer),卷积神经网络中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
卷积运算的基本操作是将卷积核与图像的对应区域进行卷积得到一个值,通过在图像上不断移动卷积核和来计算卷积值,进而完成对整幅图像的卷积运算。在卷积神经网络中,卷积层不仅涉及一般的图像卷积,还涉及深度和步长的概念。深度对应到于同一个区域的神经元个数,即有几个卷积核对同一块区域进行卷积运算;步长对应于卷积核移动多少个像素,即前后距离的远近程度。
人对外界的认知一般可以归纳为从局部到全局的过程,而图像的像素空间联系也是局部间的相关性强,远距离的相关性弱。卷积神经网络的每个神经元实际上只需关注图像局部的感知,对图像全局的感知可通过更高层综合局部信息来获得,这也说明了卷积神经网络部分连通的思想。类似于生物学中的视觉系统结构,视觉皮层的神经元用于局部接收信息,即这些神经元只响应某些特定区域的刺激,呈现出部分连通的特点。
对于一个简单的神经网络而言,由于卷积神经网络的每个神经元实际上只需关注图像局部的感知,对图像全局的感知可通过更高层综合局部信息来获得。此处以最简单的三层神经网络举例,输入层为4个神经元,隐藏层为2个神经元,输出层为1个神经元。如图1所示列举了上述最简单的三层神经网络的全连接方式与局部连接方式。如果通过全连接的方式,输入层与隐藏层之间需要计算4×2=8个参数,而隐藏层到输出层则需计算2×1=2个参数,共需计算8×2=16个参数;而对于全局的感知可通过综合局部信息获得,则通过局部连接的方式,输入层到隐藏层之间需要计算2×2=4个参数,隐藏层到输出层则需计算2×1=2个参数,共需计算4×2=8个参数。计算量降低了,而学习到的知识却是一样的,而神经网络的参数计算往往很多,故此,通过局部连接可以降低数据的计算量。
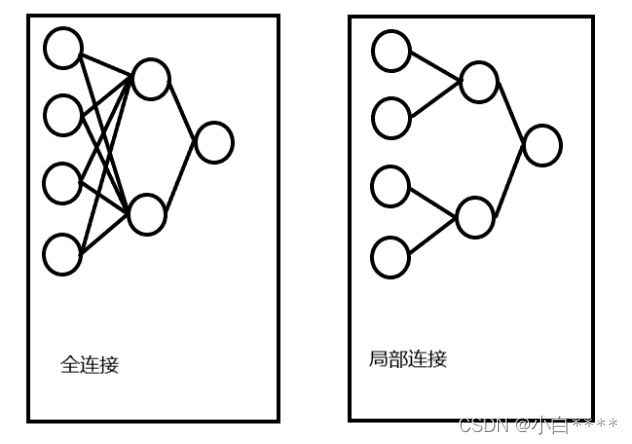
图1全连接与局部连接示意图
卷积层一般会设定卷积核(kernel)的大小、步长(step)、是否填充(padding),输出的通道数(channels),通道数取决于多少个卷积核与图像作卷积,如果RGB三通道图片与三个卷积核作卷积,那输出则也是三通道,输入的图像通道与卷积核的个数也应一致,图像与卷积核的计算过程如下所示:
此处以kernel大小为3×3,step=1,padding=0进行卷积示例,原图像矩阵为 与卷积核
与卷积核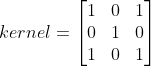 卷积,以步长为1,将kernel与图像矩阵I左上部分进行卷积计算左上部分结果得出
卷积,以步长为1,将kernel与图像矩阵I左上部分进行卷积计算左上部分结果得出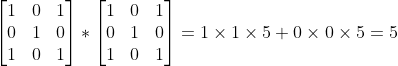 ,继而滑动一格,计算中上部分
,继而滑动一格,计算中上部分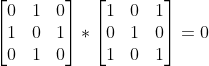 ,依次往下按step=1滑动计算,计算出图像矩阵I与卷积核kernel卷积结果为:
,依次往下按step=1滑动计算,计算出图像矩阵I与卷积核kernel卷积结果为:![]() 。
。
填充(padding)对于提取图像边缘信息有一定的作用,避免忽视边缘信息,提取出边缘的细节信息。padding一般在图像的最外围添加一圈0。如原图像矩阵为I,padding=1的图像矩阵为。
3.1.2 池化层
从理论上来看,经卷积层得到特征集合,可直接用于训练分类器,但这往往会带来巨大计算量的问题。通过计算图像局部区域上的某特定特征的平均值或最大值等来计算概要统计特征。这些概要统计特征相对于经卷积层计算得到的特征图,不仅达到了降维目的,同时还会提高训练效率。这种特征聚合的操作叫作池化(Pooling)。
池化层夹在连续的卷积层中间,用于压缩数据和参数的量,减小过拟合。池化层也叫下采样层,其具体操作与卷积层的操作基本相同,但池化作用于图像中不重合的区域,这与卷积操作不同,下采样的卷积核为只取对应位置的最大值、平均值等(最大池化、平均池化),即矩阵之间的运算规律不一样,并且不经过反向传播的修改。
池化层一般也会设置核(kernel)大小、步长(stride)、池化方式:最大值池化或平均值池化(max pooling or avg pooling)。步长一般与核大小一致。
最大值池化(max pooling):最大值池化通过将原始图像分割为若干区域后,选取各区域内最大的像素值用以代替该区域的像素值。
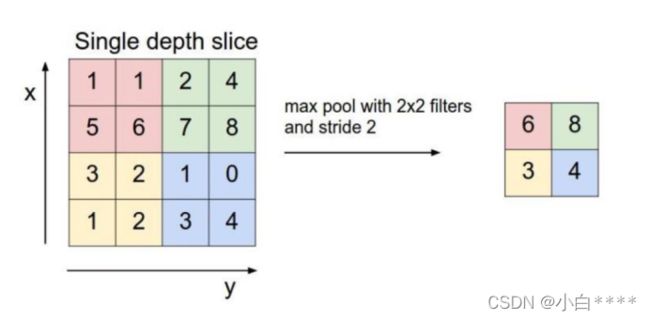
图2 max pooling示例
平均值池化(average pooling):平均值池化通过将原始图像分割为若干区域后,选取各区域内的平均像素值用以代替该区域的像素值。
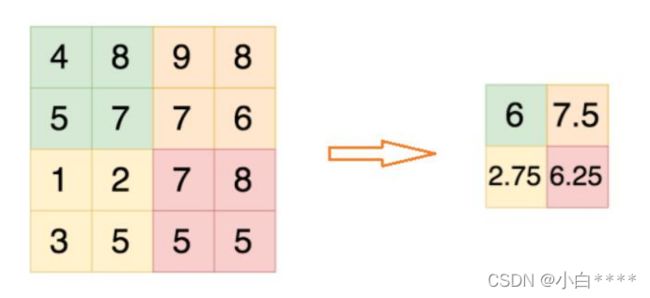
图3 avg pooling示例
3.1.3 全连接层
全连接层(Fully connected layer)的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。全连接层中的每个神经元与其前一层的所有神经元进行全连接.全连接层可以整合卷积层或者池化层中具有类别区分性的局部信息。为了提升CNN 网络性能,全连接层每个神经元的激励函数一般采用 ReLU 函数。最后一层全连接层的输出值被传递给一个输出,可以采用 softmax 逻辑回归(softmax regression)进行 分 类,该层也可称为 softmax 层(softmax layer)。对于一个具体的分类任务,选择一个合适的损失函数是十分重要的。
3.1.4 前向传播
前向传播(Forward propagation),假设上一层结点i,j,k,…等一些结点与本层的结点w有连接,那么结点w的值就是通过上一层的i,j,k,...等结点以及对应的连接权值进行加权和运算,最终结果再加上一个偏置项,最后在通过一个非线性函数(即激活函数),如ReLu,sigmoid等函数,最后得到的结果就是本层结点w的输出。最终不断的通过这种方法一层层的运算,得到输出层结果。
对于前向传播来说,不管维度多高,对于第i层第j个神经元的前向传播其过程都可以用如下公式表示:
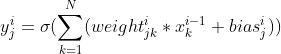
式中表示上一级的神经元输入乘以权重加上偏置再经过激活函数后便作为该层神经元的输出,其中σ表示激活函数,weight表示上一层的神经元到下一层神经元的权重,bias表示神经元的偏置。
3.1.5 反向传播
反向传播(Backpropagation,BP)是“误差反向传播”的简称,是一种与最优化方法结合使用的,用来训练人工神经网络的常见方法。该方法对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。在神经网络上执行梯度下降法的主要算法,该算法会先按前向传播方式计算并缓存每个节点的输出值,然后再按反向传播遍历图的方式计算损失函数值相对于每个参数的偏导数。
3.1.6 激活函数
激活函数(Activation functions)对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。它们将非线性特性引入到网络中。在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数。引入激活函数是为了增加神经网络模型的非线性。没有激活函数的每层都相当于矩阵相乘。
神经网络中的每个神经元节点接受上一层神经元的输出值作为本神经元的输入值,并将输入值传递给下一层,输入层神经元节点会将输入属性值直接传递给下一层(隐层或输出层)。在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数(又称激励函数)。
不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机(Perceptron)。使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
3.1.6.1 Relu 激活函数:
Relu函数其实就是一个取最大值函数,注意这并不是全区间可导的,但是我们可以取sub-gradient。
优点:
①解决了梯度消失(gradient vanishin)问题 (在正区间);
②计算速度非常快,只需要判断输入是否大于0;
③收敛速度远快于sigmoid和tanh。
缺点:
①ReLU的输出不是0均值(zero-centered);
②Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生:参数初始化导致,这种情况比较少见;learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
3.1.6.2 Softmax激活函数:
特点:
它能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1。
缺点:
①在深度神经网络中梯度反向传递时导致梯度爆炸和梯度消失,其中梯度爆炸发生的概率非常小,而梯度消失发生的概率比较大。
②Sigmoid的output不是0均值(即zero-centered)。这是不可取的,因为这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。产生的一个结果就是:如,那么对w求局部梯度则都为正,这样在反向传播的过程中w要么都往正方向更新,要么都往负方向更新,导致有一种捆绑的效果,使得收敛缓慢。如果按batch去训练,那么那个batch可能得到不同的信号,所以这个问题还是可以缓解一下的。因此,非0均值这个问题虽然会产生一些不好的影响,不过跟上面提到的梯度消失问题相比还是要好很多的。
③其解析式中含有幂运算,计算机求解时相对来讲比较耗时。对于规模比较大的深度网络,这会较大地增加训练时间。
3.2 RCNN结构
3.2.1 输入层
由于本项目的任务是进行目标检测,而训练数据中最小汽车区域的像素约为32×32,且图片为RGB三通道图片。定义输入层代码如下:
%输入层
inputLayer=imageInputLayer([32 32 3]);3.2.2 中间层
神经网络的中间层由两层核大小为3、步长为1、padding为1的卷积层和两层的输出经过relu函数再进行下采样,经过核大小为3、步幅为2的池化层组成,为了避免下采样过度导致图像细节的丢失,仅用了一层池化层进行下采样。定义中间层代码如下:
% 定义卷基层参数
filterSize = [3 3];
numFilters = 32;
middleLayers = [
% 卷积+激活
convolution2dLayer(filterSize, numFilters, 'Padding', 1)
reluLayer()
% 卷积+激活+池化
convolution2dLayer(filterSize, numFilters, 'Padding', 1)
reluLayer()
maxPooling2dLayer(3, 'Stride',2)
];3.2.3 输出层
神经网络的输出层用于输出结果,构建的神经网络由两个输出维度分别为64和2的全连接层组成,第一层全连接层经由relu函数输入第二层全连接层,而后经由softmax函数输入classificationlayer。定义输出层代码如下:
% 输出层
finalLayers = [
% 新增一个包含64个输出的全连接层
fullyConnectedLayer(64)
% 新增一个非线性ReLU层
reluLayer
% 新增全连接层,用于判断图片是否包含检测对象
fullyConnectedLayer(width(vehicleDataset))
% 添加softmax和classification层
softmaxLayer
classificationLayer
];3.2.4组合构建神经网络
最后将输入层、中间层、输出层连接在一起,构建神经网络。代码如下:
% 组合所有层
layers = [
inputLayer
middleLayers
finalLayers
]构建的神经网络结构如表1所示:
| 网络层 |
核尺寸 |
步长 |
填充 |
输出维度 |
|
| Input layer |
- |
- |
- |
3 |
|
| Middle layer |
Convolution layer |
3×3 |
1 |
1 |
32 |
| Relu layer |
- |
- |
- |
- |
|
| Convolution layer |
3×3 |
1 |
1 |
32 |
|
| Relu layer |
- |
- |
- |
- |
|
| Max pooling layer |
3×3 |
2 |
0 |
- |
|
| Final layer |
Fully connected layer |
- |
- |
- |
64 |
| Relu layer |
- |
- |
- |
- |
|
| Fully connected layer |
- |
- |
- |
2 |
|
| Softmax layer |
- |
- |
- |
- |
|
| Classification layer |
- |
- |
- |
- |
|
表1 RCNN结构
3.3 训练模型
3.3.1 数据集划分
本项目采用的数据集共295张,均为RGB三通道图片,数据中最小汽车区域的像素约为32×32。
对此,将图片数据按7:3的比例进行划分训练集与测试集,前70%的数据用于训练,后30%的数据用于测试。划分数据集代码如下:
% 将数据划分两部分
% 前70%的数据用于训练,后面30%用于测试
idx = floor(0.7 * height(vehicleDataset));
trainingData = vehicleDataset(1:idx,:);
testData = vehicleDataset(idx:end,:);
图4 部分数据集展示
3.3.2 参数初始化
3.3.2.1 学习率(learning rate)
学习率(Learning rate)作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。学习速率通过损失函数的梯度调整网络权重的超参数。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。学习率越低,损失函数的变化速度就越慢。虽然使用低学习率可以确保我们不会错过任何局部极小值,但也意味着我们将花费更长的时间来进行收敛。
由于神经网络工具箱提供了trainFastRCNNObjectDetector来训练CNN网络,整个过程包含四步,每一步都可以指定不同的训练参数,也可以使用相同的训练参数。故此设置前两步的learning rate=1e-5即10-5,后两步的learning rate=1e-6即10-6。前两步设置的learning rate较大,目的是为了加快收敛速度,使目标函数更快接近收敛值;后两步的learning rate较小是为了使目标函数接近于收敛,趋于稳定。
3.3.2.2最优化方法
最优化方法,是指解决最优化问题的方法。所谓最优化问题,指在某些约束条件下,决定某些可选择的变量应该取何值,使所选定的目标函数达到最优的问题。
常见的最优化方法有SGD(随机梯度下降)、SGDM(带动量的SGD)、Adam、Adagrad、RMSPropt。本项目使用的是SGDM。下面介绍SGD和SGDM。
SGD(随机梯度下降):
SGD就是每一次迭代计算mini-batch的梯度,然后对参数进行更新。
式中η为学习率,gt是梯度SGD完全依赖于当前batch的梯度,所以η可理解为允许当前batch的梯度多大程度影响参数更新。
而SGD也存在一些缺点,选择合适的learning rate比较困难,对所有的参数更新使用同样的learning rate,对于稀疏数据或者特征,有时我们可能想更新快一些对于不经常出现的特征,对于常出现的特征更新慢一些,选择恰当的初始学习率很困难;学习率调整策略受限于预先指定的调整规则;高度非凸的误差函数的优化过程,如何避免陷入大量的局部次优解或鞍点。由此引入带动量的SGD算法。
SGDM(带动量的随机梯度下降):
SGDM就是SGD+ Momentum,从直观理解就是加入了一个惯性,在坡度比较陡的地方,会有较大的惯性,这是下降的多。坡度平缓的地方,惯性较小,下降的会比较慢。
为了抑制SGD的震荡,SGDM认为梯度下降过程可以加入惯性。下坡的时候,如果发现是陡坡,那就利用惯性跑快一些。SGDM全称为SGD with momentum,在SGD的基础上引入了一阶动量:
一阶动量是各个时刻梯度方向的指数移动平均值,约等于最近个时刻的梯度向量和的平均值,即t时刻的下降方向,不仅由当前点的梯度方向决定,而且由此前累积的下降方向决定。
由此选择SGDM进行最优化,再结合learning rate的设置,训练10个epoch,参数初始化的关键代码如下:
% 配置训练参数
options = [
% 第1步,Training a Region Proposal Network (RPN)
trainingOptions('sgdm', 'MaxEpochs', 10,'InitialLearnRate', 1e-5,'CheckpointPath', tempdir)
% 第2步,Training a Fast R-CNN Network using the RPN from step 1
trainingOptions('sgdm', 'MaxEpochs', 10,'InitialLearnRate', 1e-5,'CheckpointPath', tempdir)
% 第3步,Re-training RPN using weight sharing with Fast R-CNN
trainingOptions('sgdm', 'MaxEpochs', 10,'InitialLearnRate', 1e-6,'CheckpointPath', tempdir)
% 第4步,Re-training Fast R-CNN using updated RPN
trainingOptions('sgdm', 'MaxEpochs', 10,'InitialLearnRate', 1e-6,'CheckpointPath', tempdir)
];3.3.3 模型训练
利用先前构建的RCNN以及初始化参数的配置进行模型训练,关键代码如下:
% 训练Faster R-CNN
% 设置模型的本地存储
doTrainingAndEval = false;
if doTrainingAndEval
% 设置锚点,并执行训练
rng(0);
detector = trainFasterRCNNObjectDetector(trainingData, layers, options, ...
'NegativeOverlapRange', [0 0.3], ...
'PositiveOverlapRange', [0.6 1], ...
'BoxPyramidScale', 1.2);
else
% 直接载入
detector = data.detector;
end参数说明:
TrainingData——划分的训练集。
layers——构建的神经网络RCNN。
option——配置的训练方式。
‘PositiveOverlapRange’——一个双元素向量,指定0和1之间的边界框重叠比例范围。与指定范围内(即之前做图片标注画出的框)的边界框重叠的区域提案被用作正训练样本。Default: [0.5 1]
‘NegativeOverlapRange’——一个双元素向量,指定0和1之间的边界框重叠比例范围。与指定范围内(即之前做图片标注画出的框)的边界框重叠的区域提案被用作负训练样本。Default: [0.1 0.5]
3.3.4 结果评估
MATLAB让算视觉工具箱提供了平均精确度 evaluateDetectionprecision函数和对数平均失误率evaluateDetectionMissRate函数来评估检测器的训练效果,本项目采用evaluateDetectionPrecision函数进行评估,并计算召回率和精确率指标来作为评估标准。一般而言,针对一个目标检测问题,存在如表2所示的四种情况。
| 包含目标 |
不包含目标 |
|
| 检测到 |
TP(True Positives)纳真 |
FP(False Positives)纳伪(误报) |
| 未检测到 |
FN(False Negatives)去真(漏报) |
TN(True Negatives)去伪 |
表2 目标检测评估参数
定义精确率P=TP/(TP+FP),也就是检测到目标的图像中真正包含目标的比例。定义召回率 R=TP/(TP+FN),也就是包含目标的图像中被成功检测出来的比例。显然,在检测结果中期望精确率P和召回率R越高越好,但有时二者是矛盾的,需要做一个折中考虑。关键代码如下所示:
%% 评估训练效果
if doTrainingAndEval
resultsStruct = struct([]);
for i = 1:height(testData)
% 读取测试图片
I = imread(testData.imageFilename{i});
% 运行RCNN检测器
[bboxes, scores, labels] = detect(detector, I, 'ExecutionEnvironment', 'cpu');
% 结果保存到结构体
resultsStruct(i).Boxes = bboxes;
resultsStruct(i).Scores = scores;
resultsStruct(i).Labels = labels;
end
% 将结构体转换为table数据类型
results = struct2table(resultsStruct);
else
% 直接加载之前评估好的数据
results = data.results;
end
% 从测试数据中提取期望的小车位置
expectedResults = testData(:, 2:end);
%采用平均精确度评估检测效果
[ap, recall, precision] = evaluateDetectionPrecision(results, expectedResults);
% 绘制召回率-精确率曲线
figure
plot(recall, precision)
xlabel('Recall')
ylabel('Precision')
grid on
title(sprintf('Average Precision = %.2f', ap))3.4 模型预测
经过一定时间的训练后,得到了CNN网络模型。为了快速测试,选择一张图片进行预测,观察是否能检测出汽车目标,给出标记位置。关键代码如下:
%% 测试结果
I = imread(picture filename);
% 运行检测器,输出目标位置和得分
[bboxes, scores] = detect(detector, I, 'ExecutionEnvironment', 'cpu');
% 在图像上标记处识别的小汽车
I = insertObjectAnnotation(I, 'rectangle', bboxes, scores);
figure
imshow(I)四、项目结果与改进
4.1 部分数据集展示

图5 标记的部分训练集图片展示
4.2 结果评估曲线
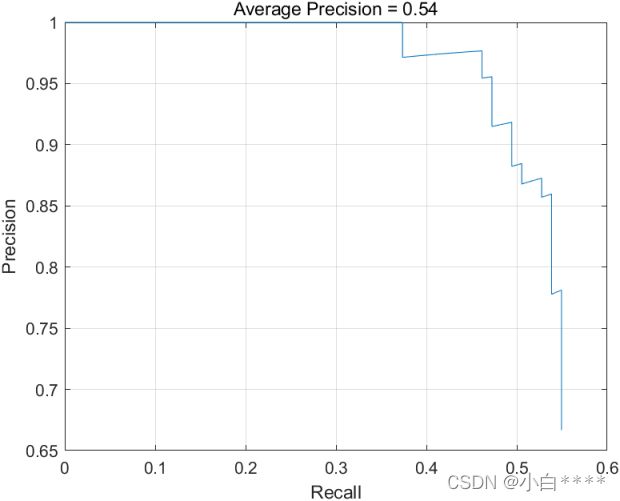
图6 召回率-精确率训练评估曲线
4.3 模型预测结果
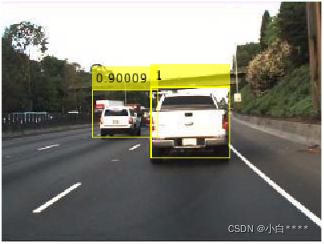
图7 预测结果图片1

图8 预测结果图片2

图9 预测结果图片3
4.4 不足与改进
理想情况是在所有召回率水平下精确率都是1,本项目的平均精确率为0.54,评估曲线如图6所示,对于部分图片的预测结果并没有肉眼观察的那么仔细,对于多目标检测存在一定的失误,对此可以选择增加中间层的卷积层,但由此也会增加训练和检测的成本,也可提高精确率;另一方面,训练的数据集仅有295张,对此,也可对数据集进行扩增,增加更多的数据图片进行训练;也可以改进训练的epoch,增大epoch,使神经网络学习更多次,学到的东西也更多。但个人由于没有GPU的支持,一些层数较多的神经网络对于个人情况还是不太适合的。