Python全栈开发-数据分析-03 Pandas详解 (中)
Pandas详解 (中)
一. 处理缺失值
1.1 drop函数:删除行,删除列
1、删除某列或某行数据可以用到pandas提供的方法drop
2、drop方法的用法:
drop(labels, axis=0, level=None, inplace=False, errors='raise')
– axis为0时表示删除行,axis为1时表示删除列
3、常用参数如下:

先看一下数据表
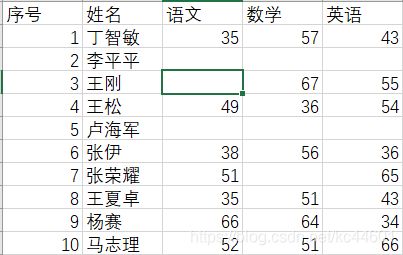
删除行:
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件015-016\删除.xlsx'
data = pd.read_excel(path,index_col='序号')
print(data.drop(2)) # 删除单行,直接写行标签
print('==='*20)
print(data.drop(labels=[1,3])) # 删除多行,使用labels,标签写成列表
运行结果为:
姓名 语文 数学 英语
序号
1 丁智敏 35.0 57.0 43.0
3 王刚 NaN 67.0 55.0
4 王松 49.0 36.0 54.0
5 卢海军 NaN NaN NaN
6 张伊 38.0 56.0 36.0
7 张荣耀 51.0 NaN 65.0
8 王夏卓 35.0 51.0 43.0
9 杨赛 66.0 64.0 34.0
10 马志理 52.0 51.0 66.0
============================================================
姓名 语文 数学 英语
序号
2 李平平 NaN NaN NaN
4 王松 49.0 36.0 54.0
5 卢海军 NaN NaN NaN
6 张伊 38.0 56.0 36.0
7 张荣耀 51.0 NaN 65.0
8 王夏卓 35.0 51.0 43.0
9 杨赛 66.0 64.0 34.0
10 马志理 52.0 51.0 66.0
删除列:
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件015-016\删除.xlsx'
data = pd.read_excel(path,index_col='序号')
print(data.drop('语文',axis=1)) # 删除单列
print('==='*20)
print(data.drop(labels=['语文','数学'],axis=1)) # 删除多列
运行结果为:
姓名 数学 英语
序号
1 丁智敏 57.0 43.0
2 李平平 NaN NaN
3 王刚 67.0 55.0
4 王松 36.0 54.0
5 卢海军 NaN NaN
6 张伊 56.0 36.0
7 张荣耀 NaN 65.0
8 王夏卓 51.0 43.0
9 杨赛 64.0 34.0
10 马志理 51.0 66.0
============================================================
姓名 英语
序号
1 丁智敏 43.0
2 李平平 NaN
3 王刚 55.0
4 王松 54.0
5 卢海军 NaN
6 张伊 36.0
7 张荣耀 65.0
8 王夏卓 43.0
9 杨赛 34.0
10 马志理 66.0
1.1.1 drop函数的使用:inplace参数
注意:凡是会对原数组作出修改并返回一个新数组的,往往都有一个 inplace可选参数。如果手动设定为True(默认为False),那么原数组直接就被替换。
而采用inplace=False之后,原数组名对应的内存值并不改变,需要将新的结果赋给一个新的数组或者覆盖原数组的内存位置 。
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件015-016\删除.xlsx'
data = pd.read_excel(path,index_col='序号')
print('==='*20)
data.drop(labels=['语文','数学'],axis=1,inplace=True)
print(data)
运行结果为:
============================================================
姓名 英语
序号
1 丁智敏 43.0
2 李平平 NaN
3 王刚 55.0
4 王松 54.0
5 卢海军 NaN
6 张伊 36.0
7 张荣耀 65.0
8 王夏卓 43.0
9 杨赛 34.0
10 马志理 66.0
1.2 查看缺失值
案例:
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件015-016\删除.xlsx'
data = pd.read_excel(path,index_col='序号')
print(data.isnull()) # 是缺失值就显示为T
print('==='*20)
print(data.notnull()) # 不是缺失值就显示为T
运行结果为:
姓名 语文 数学 英语
序号
1 False False False False
2 False True True True
3 False True False False
4 False False False False
5 False True True True
6 False False False False
7 False False True False
8 False False False False
9 False False False False
10 False False False False
============================================================
姓名 语文 数学 英语
序号
1 True True True True
2 True False False False
3 True False True True
4 True True True True
5 True False False False
6 True True True True
7 True True False True
8 True True True True
9 True True True True
10 True True True True
1.3 缺失值处理
格式:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
axis:
axis=0: 删除包含缺失值的行
axis=1: 删除包含缺失值的列
how: 与axis配合使用
how=‘any’:只要有缺失值出现,就删除该行或列
how=‘all’: 所有的值都缺失,才删除行或列
thresh: axis中至少有thresh个非缺失值,否则删除
比如 axis=0,thresh=10:标识如果该行中非缺失值的数量小于10,将删除这一行
subset: list
在哪些列中查看是否有缺失值
inplace: 是否在原数据上操作。如果为真,返回None否则返回新的copy,去掉了缺失值
1.3.1 去掉含有缺失值的行和列
案例:
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件015-016\删除.xlsx'
data = pd.read_excel(path,index_col='序号')
print(data.dropna()) # 删除有空值的行
print('==='*20)
print(data.dropna(axis=1)) # 删除有空值的列
print('==='*20)
print(data.dropna(how='all')) # 删除所有值为Nan的行
print('==='*20)
print(data.dropna(thresh=2)) # 至少保留两个非缺失值
print('==='*20)
print(data.dropna(subset=['语文','数学'])) # 在哪些列表中查看
运行结果为:
姓名 语文 数学 英语
序号
1 丁智敏 35.0 57.0 43.0
4 王松 49.0 36.0 54.0
6 张伊 38.0 56.0 36.0
8 王夏卓 35.0 51.0 43.0
9 杨赛 66.0 64.0 34.0
10 马志理 52.0 51.0 66.0
============================================================
姓名
序号
1 丁智敏
2 李平平
3 王刚
4 王松
5 卢海军
6 张伊
7 张荣耀
8 王夏卓
9 杨赛
10 马志理
============================================================
姓名 语文 数学 英语
序号
1 丁智敏 35.0 57.0 43.0
2 李平平 NaN NaN NaN
3 王刚 NaN 67.0 55.0
4 王松 49.0 36.0 54.0
5 卢海军 NaN NaN NaN
6 张伊 38.0 56.0 36.0
7 张荣耀 51.0 NaN 65.0
8 王夏卓 35.0 51.0 43.0
9 杨赛 66.0 64.0 34.0
10 马志理 52.0 51.0 66.0
============================================================
姓名 语文 数学 英语
序号
1 丁智敏 35.0 57.0 43.0
3 王刚 NaN 67.0 55.0
4 王松 49.0 36.0 54.0
6 张伊 38.0 56.0 36.0
7 张荣耀 51.0 NaN 65.0
8 王夏卓 35.0 51.0 43.0
9 杨赛 66.0 64.0 34.0
10 马志理 52.0 51.0 66.0
============================================================
姓名 语文 数学 英语
序号
1 丁智敏 35.0 57.0 43.0
4 王松 49.0 36.0 54.0
6 张伊 38.0 56.0 36.0
8 王夏卓 35.0 51.0 43.0
9 杨赛 66.0 64.0 34.0
10 马志理 52.0 51.0 66.0
1.3.2 将缺失值用某些值填充(0,平均值,中值等)
格式:
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
参数说明:
value: scalar, dict, Series, or DataFrame
dict可以指定每一行或列用什么值填充
method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None
在列上操作
ffill / pad: 使用前一个值来填充缺失值
backfill / bfill:使用后一个值来填充缺失值
limit填充的缺失值个数限制。应该不怎么用
1.3.3 填充常数
案例:
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件015-016\删除.xlsx'
data = pd.read_excel(path,index_col='序号')
print(data.fillna(0)) # 用常数填充
print('==='*20)
print(data.fillna({'语文':0.1,'数学':0.2,'英语':0.3})) # 通过字典填充不同的常数
运行结果为:
姓名 语文 数学 英语
序号
1 丁智敏 35.0 57.0 43.0
2 李平平 0.0 0.0 0.0
3 王刚 0.0 67.0 55.0
4 王松 49.0 36.0 54.0
5 卢海军 0.0 0.0 0.0
6 张伊 38.0 56.0 36.0
7 张荣耀 51.0 0.0 65.0
8 王夏卓 35.0 51.0 43.0
9 杨赛 66.0 64.0 34.0
10 马志理 52.0 51.0 66.0
============================================================
姓名 语文 数学 英语
序号
1 丁智敏 35.0 57.0 43.0
2 李平平 0.1 0.2 0.3
3 王刚 0.1 67.0 55.0
4 王松 49.0 36.0 54.0
5 卢海军 0.1 0.2 0.3
6 张伊 38.0 56.0 36.0
7 张荣耀 51.0 0.2 65.0
8 王夏卓 35.0 51.0 43.0
9 杨赛 66.0 64.0 34.0
10 马志理 52.0 51.0 66.0
1.3.4 填充方式
| ffill | 用前面的值填充 |
|---|---|
| bfill | 用后面的值填充 |
| pad | 向后填充 |
| backfill | 向前填充 |
先看一下数据:
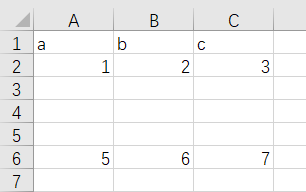
案例:
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件015-016\填充.xlsx'
data = pd.read_excel(path)
data = pd.read_excel(path)
print(data.fillna(method='ffill'))
运行结果为:
a b c
0 1.0 2.0 3.0
1 1.0 2.0 3.0
2 1.0 2.0 3.0
3 1.0 2.0 3.0
4 5.0 6.0 7.0
1.3.5 限制填充数量
例如:只替换第1个值
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件015-016\填充.xlsx'
data = pd.read_excel(path)
print(data.fillna(method='ffill',limit=1))
运行结果为:
a b c
0 1.0 2.0 3.0
1 1.0 2.0 3.0
2 NaN NaN NaN
3 NaN NaN NaN
4 5.0 6.0 7.0
二. 数学统计函数
2.1 数学统计函数表
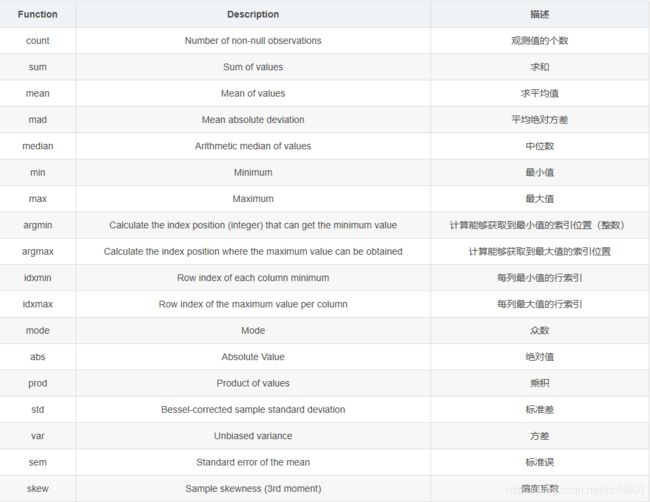
2.2 describe 数据值列汇总

先看一下数据:
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件017\数据统计.xlsx'
data = pd.read_excel(path,index_col='序号')
print(data.fillna(method='ffill',limit=1))
运行结果为:
姓名 性别 语文 数学 英语
序号
1 张三 男 89 60 88
2 李四 女 60 71 98
3 王五 男 73 84 68
4 小孙 男 85 96 96
5 小刘 女 70 63 97
6 小赵 女 63 63 91
只看一列
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件017\数据统计.xlsx'
data = pd.read_excel(path,index_col='序号')
print(data['语文'].describe())
运行结果为:
count 6.000000
mean 73.333333
std 11.639015
min 60.000000
25% 64.750000
50% 71.500000
75% 82.000000
max 89.000000
Name: 语文, dtype: float64
三. 重复数据的处理
先看一下数据:
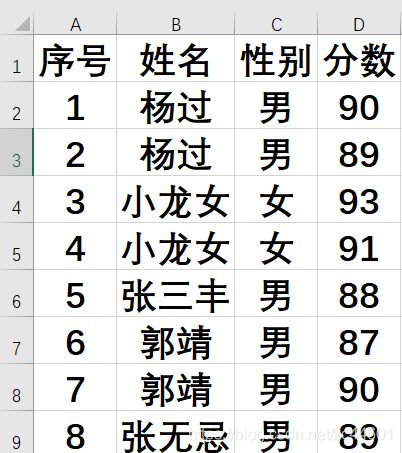
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件018\去重.xlsx'
data = pd.read_excel(path,index_col='序号')
print(data['姓名'].unique()) # 唯一值,以一个列表出现
print('=='*20)
print(data['姓名'].value_counts()) # 姓名出现过几次
运行结果为:
['杨过' '小龙女' '张三丰' '郭靖' '张无忌']
========================================
杨过 2
郭靖 2
小龙女 2
张三丰 1
张无忌 1
Name: 姓名, dtype: int64
3.1 删除重复值
删除重复的方法:
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
参数说明:
keep:指定处理重复值的方法:
first:保留第一次出现的值
last:保留最后一次出现的值
False:删除所有重复值,留下没有出现过重复的
subset:用来指定特定的列,默认是所有列
inplace:是直接在原来数据上修改还是保留一个副本
案例:
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件018\去重.xlsx'
data = pd.read_excel(path,index_col='序号')
print(data.drop_duplicates(subset=['姓名'],keep='first'))
运行结果为:
姓名 性别 分数
序号
1 杨过 男 90
3 小龙女 女 93
5 张三丰 男 88
6 郭靖 男 87
8 张无忌 男 89
3.2 提取重复
格式:
DataFrame.duplicated(subset=None, keep='first')
参数说明:
keep:指定处理重复值的方法:
first:保留第一次出现的值
last:保留最后一次出现的值
False:删除所有重复值,留下没有出现过重复的
subset:用来指定特定的列,默认是所有列
inplace:是直接在原来数据上修改还是保留一个副本
案例:
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件018\去重.xlsx'
data = pd.read_excel(path,index_col='序号')
print(data.duplicated()) # 判断重复行
print('=='*20)
print(data.duplicated(subset='姓名')) # 判断某列重复数据
print('=='*20)
重复 = data.duplicated(subset='姓名')
print(data[重复]) # 提取重复
运行结果为:
序号
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
dtype: bool
========================================
序号
1 False
2 True
3 False
4 True
5 False
6 False
7 True
8 False
dtype: bool
========================================
姓名 性别 分数
序号
2 杨过 男 89
4 小龙女 女 91
7 郭靖 男 90
四. 算数运算与数据对齐
算数运算无非就是加减乘除,但是需要注意2点:
空值与数字进行计算,结果是空值!
对除数为0的处理:
1/0 = inf 无穷大
-1/0 = -inf 负无穷大
0/0 = Nan
4.1 处理空值
案例:
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件019\计算.xlsx'
data = pd.read_excel(path)
result = data['1店'] + data['2店']
print(result)
运行结果为:
无论加减乘除,结果都是 空值与数字计算 等于 空值
0 8.0
1 NaN
2 NaN
dtype: float64
方法一:将空值填充为0
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件019\计算.xlsx'
data = pd.read_excel(path)
result = data['1店'].fillna(0) + data['2店'].fillna(0)
print(result)
运行结果为:
0 8.0
1 1.0
2 1.0
dtype: float64
方法二:灵活算术法
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件019\计算.xlsx'
data = pd.read_excel(path)
result = data['1店'].add(data['2店'],fill_value=0)
print(result)
运行结果为:
0 8.0
1 1.0
2 1.0
dtype: float64
| 方法 | 反转方法 | 描述 |
|---|---|---|
| add | radd | 加法 |
| sub | rsub | 减法 |
| div | rdiv | 除法 |
| floordiv | rfloordiv | 整除 |
| mul | rmul | 乘法 |
| pow | rpow | 幂次方 |
4.2 处理inf无穷大
如果想将inf或-inf当成NaN,可以通过以下设置
pandas.options.mode.use_inf_as_na = True
案例:
import pandas as pd
pd.options.mode.use_inf_as_na = True
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件019\无穷大.xlsx'
data = pd.read_excel(path)
result = data['1店'].div(data['2店'],fill_value=0)
print(result)
运行结果为:
0 NaN
1 NaN
2 NaN
3 1.0
dtype: float64
4.3 数据对齐
数据对齐:是数据清洗的重要过程,可以按索引对齐进行运算,如果没对齐的位置则补NaN,最后也可以填充NaN
在Excel通常是先Vlookup然后再加减乘除,Pandas省去了这个过程,直接计算
先看一下数据:
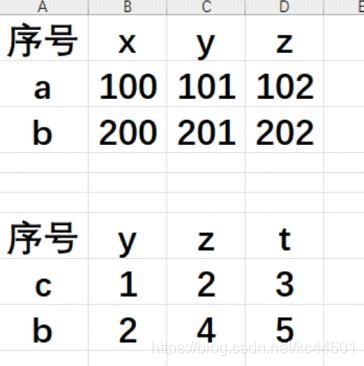
案例:
import pandas as pd
path =r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件019\对齐.xlsx'
data1 = pd.read_excel(path,index_col='序号',sheet_name='Sheet1')
data2 = pd.read_excel(path,index_col='序号',sheet_name='Sheet2')
result = data1.add(data2,fill_value=0)
print(result.fillna(0))
运行结果为:
t x y z
序号
a 0.0 100.0 101.0 102.0
b 5.0 200.0 203.0 206.0
c 3.0 0.0 1.0 2.0
五. 分层索引与计算
分层索引:就是在一个轴上拥有多个(两个以上)索引级别,使用户能以低维度形式处理高维度数据.
| levels | 每个等级上轴标签的唯一值 |
|---|---|
| labels | 以整数来表示每个level上标签的位置 |
| sortorder | 按照指定level上的标签名称的字典顺序进行排序(可选参数) |
| names | index level的名称 |
| copy | 布尔值,默认为False。是否拷贝元数据产生新的对象 |
| verify_integrity | 布尔值,默认为Ture。检查levels/labels是否持续有效 |
案例:
import pandas as pd
path= r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件020\多层索引.xlsx'
data= pd.read_excel(path,index_col=[0,1],sheet_name='有序')
print(data)
print('=='*20)
print(data.index)
print('=='*20)
print(data.index.levels[0]) # 对应外层索引
print('=='*20)
print(data.index.levels[1]) # 对应内层索引
运行结果为:
分数
班级 学号
1班 a 1
b 2
c 3
2班 a 4
b 5
c 6
3班 a 7
b 8
========================================
MultiIndex([('1班', 'a'),
('1班', 'b'),
('1班', 'c'),
('2班', 'a'),
('2班', 'b'),
('2班', 'c'),
('3班', 'a'),
('3班', 'b')],
names=['班级', '学号'])
========================================
Index(['1班', '2班', '3班'], dtype='object', name='班级')
========================================
Index(['a', 'b', 'c'], dtype='object', name='学号')
5.1 分层索引设置与查询
1.index为有序的
import pandas as pd
path= r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件020\多层索引.xlsx'
data= pd.read_excel(path,index_col=[0,1],sheet_name='有序')
data2 = data.loc[('1班',slice(None)),:] # 切片筛选index
print(data2)
运行结果为:
分数
班级 学号
1班 a 1
b 2
c 3
2.index为无序
前面的例子对应的index列为数字或字母,是有序的,接下来我们看看index列为中文的情况
import pandas as pd
path= r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件020\多层索引.xlsx'
data = pd.read_excel(path,index_col=[0,1],sheet_name='无序') # 设置分层索引
# 数据 = 数据.set_index('课程','得分') # 也可以这样设置分层索引
# 数据2 = 数据.loc[('语文',slice(None)),:] # 不能使用这种方法,因为科目是无序的
print(data.index.is_lexsorted()) # 检查index是否有序
# 接下来,我们尝试对Index进行排序。(排序时要在level里指定index名)
data = data.sort_index(level='科目')
data2 = data.loc[('语文',slice(None)),:]
print(data2)
运行结果为:
False
分数
科目 得分
语文 最低 50
最高 90
5.2 多层索引的创建的方式【行】
| from_arrays | 接收一个多维数组参数,高维指定高层索引,低维指定底层索引 |
|---|---|
| from_tuples | 接收一个元组的列表,每个元组指定每个索引(高维索引,低维索引) |
| from_product | 接收一个可迭代对象的列表,根据多个可迭代对象元素的笛卡尔积进行创建索引 |
注:from_product相对于前两个方法而言,实现相对简单,但是,也存在局限。
1.from_arrays方法
from_arrays 参数为一个二维数组,每个元素(一维数组)来分别制定每层索引的内容
案例:
import pandas as pd
data = pd.MultiIndex.from_arrays([['a', 'a', 'b', 'b'], [1, 2, 1, 2]],names=['x','y'])
print(data)
运行结果为:
MultiIndex([('a', 1),
('a', 2),
('b', 1),
('b', 2)],
names=['x', 'y'])
2.from_tuples方法
from_tuples 参数为一个(嵌套的)可迭代对象,元素为元祖类型。元祖的格式为:(高层索引内容,低层索引内容)
案例:
import pandas as pd
data = pd.MultiIndex.from_tuples([('a',1),('a',2),('b',1),('b',2)],names=['x','y'])
print(data)
运行结果为:
MultiIndex([('a', 1),
('a', 2),
('b', 1),
('b', 2)],
names=['x', 'y'])
3.from_product方法
使用笛卡尔积的方式来创建多层索引。参数为嵌套的可迭代对象。结果为使用每个一维数组中的元素与其他一维数组中的元素来生成 索引内容。
案例:
import pandas as pd
data = pd.MultiIndex.from_product([['a', 'b'], [1, 2]],names=['x','y'])
print(data)
运行结果为:
MultiIndex([('a', 1),
('a', 2),
('b', 1),
('b', 2)],
names=['x', 'y'])
注:如果不在MultiIndex中设置索引名,也可以事后设置
5.3 多层索引的创建的方式【列】
在DataFrame中,行和列是完全对称的,就像行可以有多个索引层次一样,列也可以有多个层次。
案例:
import pandas as pd
import numpy as np
index = pd.MultiIndex.from_product([[2019, 2020], [5, 6]],names=['年', '月'])
columns = pd.MultiIndex.from_product([['香蕉', '苹果'], ['土豆', '茄子']],names=['水果', '蔬菜'])
data = pd.DataFrame(np.random.random(size=(4, 4)), index=index, columns=columns)
print(data)
运行结果为:
水果 香蕉 苹果
蔬菜 土豆 茄子 土豆 茄子
年 月
2019 5 0.098798 0.101808 0.284840 0.800074
6 0.202283 0.144098 0.851228 0.662407
2020 5 0.403155 0.158876 0.626379 0.222655
6 0.487665 0.452485 0.137461 0.197541
5.4 分层索引计算

多层索引:允许你在一个轴上有多个索引。
案例:
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件020\销售.xlsx'
data = pd.read_excel(path,header=[0,1]) # 设置前2行是表头,笔记2.1.2
# print(数据.columns)
# 结果1 = 数据[('土豆', '销量')]+数据[('倭瓜', '销量')] # 通过两层索引相加
# print(结果1)
# 结果2 = 数据['土豆'] +数据['倭瓜'] # 通过第一层索引相加
# print(结果2)
sum = data['土豆']+data['倭瓜']
# print(总计) # 单层索引与多层索引无法拼接
sum.columns = pd.MultiIndex.from_product([['合计'],sum.columns])
# print(总计)
result =pd.concat([data,sum],axis=1) # 横向拼接,笔记4.3.3
print(result)
运行结果为:
土豆 倭瓜 合计
销量 毛利 销量 毛利 销量 毛利
0 10 5 20 6 30 11
1 11 4 30 5 41 9
附:MultiIndex参数表

六. 数据替换
前面我们使用fillna填充缺失值替换属于特殊案例。

6.1 替换全部或者某一行
先查看一下数据

6.1.1 整个表全部替换
把城八区替换为海淀区
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件021\替换.xlsx'
data = pd.read_excel(path)
data.replace('城八区','海淀区',inplace=True)
print(data)
运行结果为:
国家 省市 城市 城市2 数值
0 中国 北京 海淀区 海淀区 100
1 中国 北京 海淀区 海淀区 A
2 中国 NaN 海淀区 海淀区 B
3 中国 北京 海淀区 海淀区 A
4 中国 北京 海淀区 海淀区 B
5 中国 北京 海淀区 海淀区 C
6 中国 北京 海淀区 海淀区 D
7 中国 北京 海淀区 海淀区 E
8 中国 北京 海淀区 海淀区 F
9 中国 北京 海淀区 海淀区 G
6.1.2 某一行替换
把城市二的城八区替换为海淀区
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件021\替换.xlsx'
data = pd.read_excel(path)
data['城市2'].replace('城八区','海淀区',inplace=True)
print(data)
运行结果为:
国家 省市 城市 城市2 数值
0 中国 北京 城八区 海淀区 100
1 中国 北京 城八区 海淀区 A
2 中国 NaN 城八区 海淀区 B
3 中国 北京 城八区 海淀区 A
4 中国 北京 城八区 海淀区 B
5 中国 北京 城八区 海淀区 C
6 中国 北京 城八区 海淀区 D
7 中国 北京 城八区 海淀区 E
8 中国 北京 城八区 海淀区 F
9 中国 北京 城八区 海淀区 G
6.2 替换指定的某个或多个数值(用字典的形式)
个人推荐使用字典的方式
将 A 的值替换为 20, B 替换为 30
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件021\替换.xlsx'
data = pd.read_excel(path)
dict1 = {'A':20,'B':30}
data.replace(dict1,inplace=True)
print(data)
运行结果为:
国家 省市 城市 城市2 数值
0 中国 北京 城八区 城八区 100
1 中国 北京 城八区 城八区 20
2 中国 NaN 城八区 城八区 30
3 中国 北京 城八区 城八区 20
4 中国 北京 城八区 城八区 30
5 中国 北京 城八区 城八区 C
6 中国 北京 城八区 城八区 D
7 中国 北京 城八区 城八区 E
8 中国 北京 城八区 城八区 F
9 中国 北京 城八区 城八区 G
这个很好理解,就是字典里的建作为原值,字典里的值作为替换的新值。
也可以用列表的方式:
运行结果和上面一样
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件021\替换.xlsx'
data = pd.read_excel(path)
data.replace(['A','B'],[20,30],inplace=True)
print(data)
进阶:如果想要替换的新值是一样的话
这种情况推荐用列表
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件021\替换.xlsx'
data = pd.read_excel(path)
data.replace(['A','B'],30,inplace=True)
print(data)
运行结果为:
国家 省市 城市 城市2 数值
0 中国 北京 城八区 城八区 100
1 中国 北京 城八区 城八区 30
2 中国 NaN 城八区 城八区 30
3 中国 北京 城八区 城八区 30
4 中国 北京 城八区 城八区 30
5 中国 北京 城八区 城八区 C
6 中国 北京 城八区 城八区 D
7 中国 北京 城八区 城八区 E
8 中国 北京 城八区 城八区 F
9 中国 北京 城八区 城八区 G
6.3 替换某个数据部分内容
把城市列的 城八 字段替换为 市
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件021\替换.xlsx'
data = pd.read_excel(path)
data['城市'] = data['城市'].str.replace('城八','市')
print(data)
运行结果为:
国家 省市 城市 城市2 数值
0 中国 北京 市区 城八区 100
1 中国 北京 市区 城八区 A
2 中国 NaN 市区 城八区 B
3 中国 北京 市区 城八区 A
4 中国 北京 市区 城八区 B
5 中国 北京 市区 城八区 C
6 中国 北京 市区 城八区 D
7 中国 北京 市区 城八区 E
8 中国 北京 市区 城八区 F
9 中国 北京 市区 城八区 G
6.4 正则表达式替换
将字母A-Z全替换为 88
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件021\替换.xlsx'
data = pd.read_excel(path)
data.replace('[A-Z]',88,regex=True,inplace=True)
print(data)
运行结果为:
国家 省市 城市 城市2 数值
0 中国 北京 城八区 城八区 100
1 中国 北京 城八区 城八区 88
2 中国 NaN 城八区 城八区 88
3 中国 北京 城八区 城八区 88
4 中国 北京 城八区 城八区 88
5 中国 北京 城八区 城八区 88
6 中国 北京 城八区 城八区 88
7 中国 北京 城八区 城八区 88
8 中国 北京 城八区 城八区 88
9 中国 北京 城八区 城八区 88
七. 离散化和分箱
后期我们会接触到机械学习,人工智能,神经网络
机械学习中的分箱处理
在机械学习中,我们经常会对数据进行分箱处理的操作, 也就是 把一段连续的值切分成若干段,每一段的值看成一个分类。这个把连续值转换成离散值的过程,我们
叫做分箱处理。
比如,把年龄按15岁划分成一组,0-15岁叫做少年,16-30岁叫做青年,31-45岁叫做壮年。在这个过程中,我们把连续的年龄分成了三个类别,“少年”,“青年”和“壮年”
就是各个类别的名称,或者叫做标签。
cut和qcut函数的基本介绍
在pandas中,cut和qcut函数都可以进行分箱处理操作。其中cut函数是按照数据的值进行分割,而qcut函数则是根据数据本身的数量来对数据进行分割。
cut格式:
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
参数说明:
- x,类array对象,且必须为一维,待切割的原形式
- bins, 整数、序列尺度、或间隔索引。如果bins是一个整数,它定义了x宽度范围内的等宽面元数量,但是在这种情况下,x的范围在每个边上被延长1%,以保证包
括x的最小值或最大值。如果bin是序列,它定义了允许非均匀bin宽度的bin边缘。在这种情况下没有x的范围的扩展- right,布尔值。是否是左开右闭区间
- labels,用作结果箱的标签。必须与结果箱相同长度。如果FALSE,只返回整数指标面元。
- retbins,布尔值。是否返回面元
- precision,整数。返回面元的小数点几位
- include_lowest,布尔值。第一个区间的左端点是否包含
返回值:
若labels为False则返回整数填充的Categorical或数组或Series
若retbins为True还返回用浮点数填充的N维数组
qcut 格式
pandas.qcut(x, q, labels=None, retbins=False, precision=3, duplicates='raise')
参数说明:
1.x
2.q,整数或分位数组成的数组。
3.labels,
4.retbins
5.precisoon
6.duplicates
结果中超过边界的值将会变成NA
7.1 指定分界点分箱 【cut】
Python实现连续数据的离散化处理主要基于两个函数:
pandas.cut和pandas.qcut,pandas.cut根据指定分界点对连续数据进行分箱处理
pandas.qcut可以指定箱子的数量对连续数据进行等宽分箱处理
(注意:所谓等宽指的是每个箱子中的数据量是相同的)
案例:
import pandas as pd
year = [1992, 1983, 1922, 1932, 1973] # 待分箱数据
box = [1900, 1950, 2000] # 指定箱子的分界点
result = pd.cut(year, box)
print(result)
运行结果为:
结果说明:其中(1950, 2000]说明【年份】列表的第一个值1992位于(1950, 2000]区间
[(1950, 2000], (1950, 2000], (1900, 1950], (1900, 1950], (1950, 2000]]
Categories (2, interval[int64]): [(1900, 1950] < (1950, 2000]]
对不同箱子中的数进行计数
print(pd.value_counts(result)) # 对不同箱子中的数进行计数
运行结果为:
(1950, 2000] 3
(1900, 1950] 2
dtype: int64
labels参数为False时,返回结果中用不同的整数作为箱子的指示符
result2 = pd.cut(year, box,labels=False)
# 输出结果中的数字对应着不同的箱子
print(result2)
运行结果为:
[1 1 0 0 1]
结果说明:其中 1 说明【年份】列表的第一个值1992位于(1950, 2000]区间
其中 0 说明【年份】列表的第一个值1922位于(1900, 1950]区间
案例:
import pandas as pd
year = [1992, 1983, 1922, 1932, 1973] # 待分箱数据
box = [1900, 1950, 2000] # 指定箱子的分界点
# 可以将想要指定给不同箱子的标签传递给labels参数
name = [ '50年代前', '50年代后']
result = pd.cut(year, box, labels=name)
print(pd.value_counts(result))
运行结果为:
50年代后 3
50年代前 2
dtype: int64
7.2 等频分箱 【qcut】
import pandas as pd
year = [1992, 1983, 1922, 1932, 1973, 1999, 1993, 1995] # 待分箱数据
result = pd.qcut(year,q=4) # 参数q指定所分箱子的数量
# 从输出结果可以看到每个箱子中的数据量时相同的
print(result)
print('=='*20)
print(pd.value_counts(result)) # 从输出结果可以看到每个箱子中的数据量时相同的
运行结果为:
[(1987.5, 1993.5], (1962.75, 1987.5], (1921.999, 1962.75], (1921.999, 1962.75], (1962.75, 1987.5], (1993.5, 1999.0], (1987.5, 1993.5], (1993.5, 1999.0]]
Categories (4, interval[float64]): [(1921.999, 1962.75] < (1962.75, 1987.5] < (1987.5, 1993.5] < (1993.5, 1999.0]]
========================================
(1993.5, 1999.0] 2
(1987.5, 1993.5] 2
(1962.75, 1987.5] 2
(1921.999, 1962.75] 2
dtype: int64
八. 字符串操作
先看一下数据
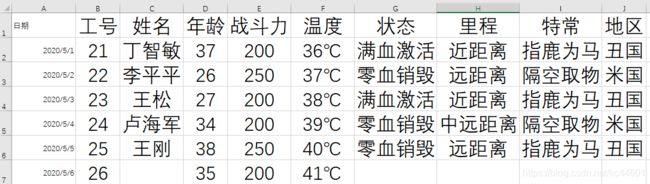
8.1 字符串对象方法
8.1.1 cat 和指定字符进行拼接
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['姓名'].str.cat()) # 不指定参数,所有姓名拼接
print('==='*20)
print(data['姓名'].str.cat(sep='、'))
print('==='*20)
print(data['姓名'].str.cat(['变身'] * len(data)))
print('==='*20)
# ['变身'] * len(数据) 相当于 ['变身'] * 6次
print(data['姓名'].str.cat(['变身'] * len(data),sep='^'))
# 如果一方为NaN,结果也为NaN,因此我们可以指定na_rep,表示将NaN用na_rep替换
运行结果为:
丁智敏李平平王松卢海军王刚
============================================================
丁智敏、李平平、王松、卢海军、王刚
============================================================
0 丁智敏变身
1 李平平变身
2 王松变身
3 卢海军变身
4 王刚变身
5 NaN
Name: 姓名, dtype: object
============================================================
0 丁智敏^变身
1 李平平^变身
2 王松^变身
3 卢海军^变身
4 王刚^变身
5 NaN
Name: 姓名, dtype: object
8.1.2 split 按照指定字符串分隔
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['状态'].str.split()) # 不指定分隔符,就是一列表
print('==='*20)
print(data['状态'].str.split('血')) # 和python内置split一样
print('==='*20)
print(data['状态'].str.split('血',n=-1)) # 指定n,表示分隔次数,默认是-1,全部分隔
print('==='*20)
print(data['状态'].str.split('血',expand=True))
运行结果为:
0 [满血激活]
1 [零血销毁]
2 [满血激活]
3 [零血销毁]
4 [零血销毁]
5 NaN
Name: 状态, dtype: object
============================================================
0 [满, 激活]
1 [零, 销毁]
2 [满, 激活]
3 [零, 销毁]
4 [零, 销毁]
5 NaN
Name: 状态, dtype: object
============================================================
0 [满, 激活]
1 [零, 销毁]
2 [满, 激活]
3 [零, 销毁]
4 [零, 销毁]
5 NaN
Name: 状态, dtype: object
============================================================
0 1
0 满 激活
1 零 销毁
2 满 激活
3 零 销毁
4 零 销毁
5 NaN NaN
# 注意这个expand,默认是False,得到是一个列表
# 如果指定为True,会将列表打开,变成多列,变成DATAFrame
# 列名则是按照0 1 2 3····的顺序,并且默认Nan值分隔后还是为Nan
# 如果分隔符不存在,还是返回DATAFrame
rsplit
和split用法一致,只不过默认是从右往左分隔
8.1.3 partition 按照指定字符分割
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['状态'].str.partition('血'))
print('==='*20)
# partition只会分隔一次
# 第一个元素:第一个分隔符之前的部分
# 第二个元素:分隔符本身
# 第三个元素:第一个分隔符之后的内容
# 如果有多个分隔符,也只会按照第一个分隔符分隔
print('BbBbB'.partition('b'))
print('==='*20)
print((data['状态'].str.partition('平')))
print('==='*20)
print((data['状态'].str.partition()))
# 上面两个情况结果是一样的
运行结果为:
0 1 2
0 满 血 激活
1 零 血 销毁
2 满 血 激活
3 零 血 销毁
4 零 血 销毁
5 NaN NaN NaN
============================================================
('B', 'b', 'BbB')
============================================================
0 1 2
0 满血激活
1 零血销毁
2 满血激活
3 零血销毁
4 零血销毁
5 NaN NaN NaN
============================================================
0 1 2
0 满血激活
1 零血销毁
2 满血激活
3 零血销毁
4 零血销毁
5 NaN NaN NaN
rpartition
和partition类似,不过是默认是从右往左找到第一个分隔符
8.1.4 get 获取指定位置的字符,只能获取1个
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['状态'].str.get(2)) # 获取指定索引的字符,只能传入int
运行结果为:
0 激
1 销
2 激
3 销
4 销
5 NaN
Name: 状态, dtype: object
# 如果全部越界,那么None也为NaN,并且整体是float64类型
# 如果pandas用的时间比较长的话,一定会遇见该问题
# 像数据库、excel、csv等等,原来的类型明明为整型,但是读成DataFrame之后变成浮点型了
# 就是因为含有空值,变成float了。
"""
如果是object类型(或者理解为str),空值可以是None,也可以是NaN,但不可以是NaT
对于整型来说,如果含有空值,那么空值为NaN。
对于时间类型来说,如果含有空值,那么空值为NaT。
即使你想转化也是没用的,如果想把NaN或者NaT变成None,只有先变成object(str)类型,才可以转化
"""
8.1.5 slice获取指定范围的字
slice 和python内置的slice一样。get相当于是[n],slice相当于是[m: n]
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['状态'].str.slice(0)) # 指定一个值的话,相当于[m:]
print('==='*30)
print(data['状态'].str.slice(0,3)) # 相当于[m:n],从0开始不包括3
print('==='*30)
print(data['状态'].str.slice(0,3,2)) # 相当于[m: n: step]
print('==='*30)
print(data['状态'].str.slice(5,9,2)) # 索引越界,默认为空字符串,原来Nan还是Nan
运行结果为:
0 满血激活
1 零血销毁
2 满血激活
3 零血销毁
4 零血销毁
5 NaN
Name: 状态, dtype: object
==========================================================================================
0 满血激
1 零血销
2 满血激
3 零血销
4 零血销
5 NaN
Name: 状态, dtype: object
==========================================================================================
0 满激
1 零销
2 满激
3 零销
4 零销
5 NaN
Name: 状态, dtype: object
==========================================================================================
0
1
2
3
4
5 NaN
Name: 状态, dtype: object
8.1.6 slice_replace 筛选出来之后替换
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['状态'].str.slice_replace(1,3,"520"))
# 将slice为[1:3]的内容换成"distance",既然替换,所以这里不支持步长
运行结果为:
0 满520活
1 零520毁
2 满520活
3 零520毁
4 零520毁
5 NaN
Name: 状态, dtype: object
8.1.7 join 将每个字符之间使用指定字符相连
join 将每个字符之间使用指定字符相连,相当于sep.join(list(value))
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['状态'].str.join('a'))
运行结果为:
0 满a血a激a活
1 零a血a销a毁
2 满a血a激a活
3 零a血a销a毁
4 零a血a销a毁
5 NaN
Name: 状态, dtype: object
8.1.8 contains 判断字符串是否含有指定子串,返回的是bool类型
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['状态'].str.contains('血')) # NaN还是返回Nan
print('==='*20)
print(data['状态'].str.contains('血',na=False))
print('==='*20)
print(data['状态'].str.contains('血',na=True))
print('==='*20)
print(data['状态'].str.contains('血',na="没有"))
运行结果为:
0 True
1 True
2 True
3 True
4 True
5 NaN
Name: 状态, dtype: object
============================================================
0 True
1 True
2 True
3 True
4 True
5 False
Name: 状态, dtype: bool
============================================================
0 True
1 True
2 True
3 True
4 True
5 True
Name: 状态, dtype: bool
============================================================
0 True
1 True
2 True
3 True
4 True
5 没有
Name: 状态, dtype: object
8.1.9 startswith 是否某个子串开头
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['状态'].str.startswith('满'))
# NaN还是返回Nan,可按照 na= False 或 na = True 替换
运行结果为:
0 True
1 False
2 True
3 False
4 False
5 NaN
Name: 状态, dtype: object
8.1.10 endswith 判断是否以某个子串结尾
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['状态'].str.endswith('满'))
# NaN还是返回Nan,可按照 na= False 或 na = True 替换
运行结果为:
0 False
1 False
2 False
3 False
4 False
5 NaN
Name: 状态, dtype: object
8.1.11 repeat 重复字符串
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['姓名'].str.repeat(3)) # 把姓名重复3次
运行结果为:
0 丁智敏丁智敏丁智敏
1 李平平李平平李平平
2 王松王松王松
3 卢海军卢海军卢海军
4 王刚王刚王刚
5 NaN
Name: 姓名, dtype: object
8.1.12 pad 将每一个元素都用指定的字符填充,记住只能是一个字符
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
# 表示要占5个长度,用"&"填充,默认填在左边的
print(data['姓名'].str.pad(5,fillchar='&'))
print('==='*20)
# 表示要占5个长度,用"&"填充,指定填在右边
print(data["姓名"].str.pad(5, fillchar="<", side="right"))
print('==='*20)
# 指定side为both,会填在两端
print(data["姓名"].str.pad(5, fillchar="<", side="both"))
运行结果为:
0 &&丁智敏
1 &&李平平
2 &&&王松
3 &&卢海军
4 &&&王刚
5 NaN
Name: 姓名, dtype: object
============================================================
0 丁智敏<<
1 李平平<<
2 王松<<<
3 卢海军<<
4 王刚<<<
5 NaN
Name: 姓名, dtype: object
============================================================
0 <丁智敏<
1 <李平平<
2 <<王松<
3 <卢海军<
4 <<王刚<
5 NaN
Name: 姓名, dtype: object
# 这三个是有pad变来的
"""
center(5, fillchar="<") <==> pad(5, size="both", fillchar="<")
ljust(5, fillchar="<") <==> pad(5, size="right", fillchar="<")
rjust(5, fillchar="<") <==> pad(5, size="left", fillchar="<")
"""
8.1.13 zfill 填充,只能是0,从左边填充
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['姓名'].str.zfill(10))
运行结果为:
0 0000000丁智敏
1 0000000李平平
2 00000000王松
3 0000000卢海军
4 00000000王刚
5 NaN
Name: 姓名, dtype: object
8.1.14 strip 按照指定内容,从两边去除
strip按照指定内容,从两边去除,和python字符串内置的
strip一样
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['里程'].str.strip("中远近离"))
运行结果为:
0 距
1 距
2 距
3 距
4 距
5 NaN
Name: 里程, dtype: object
lstrip 和rstrip
类比python字符串的lstrip和rstrip
8.1.15 get_dummies
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['里程'].str.get_dummies('距'))
# 按照"距"进行分割,得到列表
# 所有列表中的元素总共有"中远、近、远、离"四种
运行结果为:
中远 离 近 远
0 0 1 1 0
1 0 1 0 1
2 0 1 1 0
3 1 1 0 0
4 0 1 0 1
5 0 0 0 0
8.1.16 translate 指定部分替换
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
dict1 = str.maketrans({'距':'ju','离':'li'})
print(data['里程'].str.translate(dict1))
运行结果为:
0 近juli
1 远juli
2 近juli
3 中远juli
4 远juli
5 NaN
Name: 里程, dtype: object
8.1.17 find 查找指定字符第一次出现的位置
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data["日期"].astype('str').str.find("-"))
print('==='*20)
# 当然可以指定范围,包括起始和结束
print(data["日期"].astype('str').str.find("-", 5))
print('==='*20)
print(data["日期"].astype('str').str.find("我")) #找不到返回-1
运行结果为:
0 4
1 4
2 4
3 4
4 4
5 4
Name: 日期, dtype: int64
============================================================
0 7
1 7
2 7
3 7
4 7
5 7
Name: 日期, dtype: int64
============================================================
0 -1
1 -1
2 -1
3 -1
4 -1
5 -1
Name: 日期, dtype: int64
8.1.18 字母大小写
print(数据.str.lower()) # 所有字符转成小写
print(数据.str.upper()) # 所有字符转成大写
print(数据.str.title()) # 每一个单词的首字母大写
print(数据.str.capitalize()) # 第一个字母大写
print(s.str.swapcase()) # 大小写交换
8.1.19 判断 【返回T或F】
print(数据.str.isalpha()) # 是否全是字母
print(数据.str.isnumeric()) # 判断是否全是数字
print(数据.str.isalnum()) # 判断是否全是字母或者数字
# isdecimal只能用于Unicode数字
# isdigit用于Unicode数字,罗马数字
# isnumeric用于unicode数字,罗马数字,汉字数字
# 总的来说,isnumeric最广泛,但是实际项目中,一般很少会有这种怪异的数字出现
# 如果只是普通的阿拉伯数字,那么这三个方法基本上是一样的,可以互用
print(s4.str.isspace()) # 判断是否全是空格
print(s5.str.islower()) # 判断是否全是小写
print(s5.str.istitle()) # 判断每个单词的首字母是否是大写(其他字母小写)
8.2 正则表达式
8.2.1 match 是否匹配给定的模式
match 和python正则中的match一样,是从头开始匹配的。返回布尔型,表示是否匹配给定的模式
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data['状态'].str.match(".{2}激"))
# NaN还是返回Nan,可按照 na= False 或 na = True 替换
运行结果为:
0 True
1 False
2 True
3 False
4 False
5 NaN
Name: 状态, dtype: object
8.2.2 extract 分组捕获
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data["日期"].astype('str').str.extract("\d{4}-(\d{2})-(\d{2})"))
运行结果为:
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data["日期"].astype('str').str.extract("\d{4}-(\d{2})-(\d{2})"))
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data["日期"].astype('str').str.extract("\d{4}-(\d{2})-(\d{2})"))
0 1
0 05 01
1 05 02
2 05 03
3 05 04
4 05 05
5 05 06
8.2.3 replace 替换
import pandas as pd
path = r'E:\Desktop\科学计算\Pandas课件\pandas教程\课件023-024\字符串.xlsx'
data = pd.read_excel(path)
print(data["日期"].astype('str').str.replace("(\d+)-(\d+)-(\d+)", r"\3/\2/\1"))
# 这里面的replace是支持正则的。
# 并且一般我们会加上r表示原生的,这是在正则中
# 对于pandas来说,第一个参数是不需要加的,如match。但是第二个参数是要加上r的
# 尤其是分组替换,但如果只是简单字符串替换就不需要了。
运行结果为:
0 01/05/2020
1 02/05/2020
2 03/05/2020
3 04/05/2020
4 05/05/2020
5 06/05/2020
Name: 日期, dtype: object