联邦学习--论文汇集(六)
面向大规模的联邦学习系统设计,感觉像综述。
[1] Bonawitz K , Eichner H , Grieskamp W , et al. Towards Federated Learning at Scale: System Design[J]. 2019.
[2] Karimireddy S P , Kale S , Mohri M , et al. SCAFFOLD: Stochastic Controlled Averaging for On-Device Federated Learning[J]. 2019.
第一篇
背景
在移动设备上基于Tensorflow 构造 scalable production 联邦学习系统,阐述一些挑战和解决方案,以及开放问题和未来的方向。
联邦学习:“将代码带到数据中,而不是将数据带到代码中”。
系统允许用户使用tensorflow对存储在手机上的数据(永远不会离开设备)训练深度神经网络,例如在电话键盘领域。
内容(在通信协议、设备和服务器级别解决)
1.复杂的方式(如时区依赖)、相关设备本地数据分布;
2.不可靠的设备连接和中断的情形;
3.具有不同可用性的设备间锁步执行的编排以及有限的设备存储和计算资源。
(选择和报告阶段由一组参数指定,这些参数产生灵活的时间窗口。)
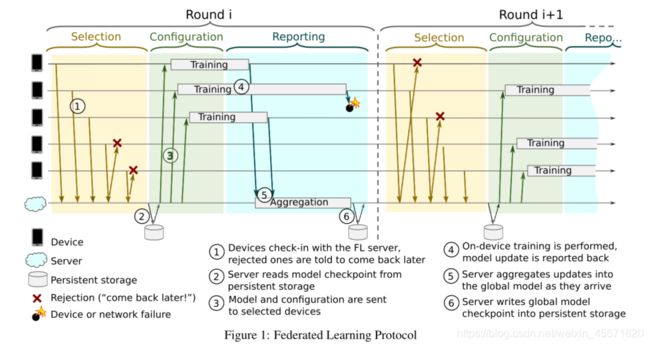
选择:服务器根据某些目标(如参与设备的最佳数量)选择连接设备的子集。考虑设备参与者目标计数、超时以及运行一轮所需的目标计数的最小百分比。(选择阶段一直维持达到目标数数或超时状态)
配置:设备选择的聚合机制进行配置,服务器将FL计划和带有全局模型的FL检查点发送到每个设备。
报告:等待参与设备报告更新。这一轮将根据是否达到最低目标数开始或放弃。
速度转向:流量控制机制,调节设备连接的模式。使FL服务器既可以向下扩展以处理较小的FL种群,或向上扩展到非常大的FL种群。基于服务器向设备建议重新连接的最佳时间窗口。使用速度控制来确保有足够数量的设备同时连接到服务器。考虑活跃设备数量的每日振荡,并能够相应地调整时间窗口,避免在高峰时段过度活动,同时不影响FL在一天中其他时间的表现。
存储和FL运行时之间的关系。
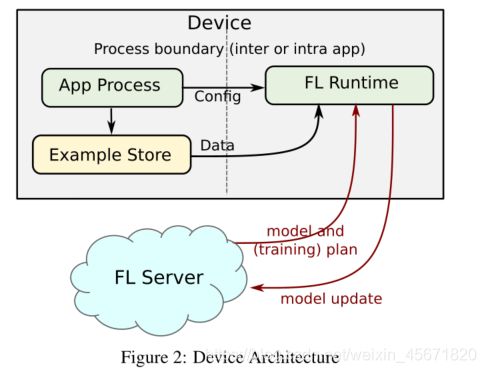
控制流如下:
- 可编程配置:使用Android的Job Scheduler来调度一个周期性的FL运行作业。在终端用户的设备上训练机器学习(ML)模型的要求可能是避免对用户体验、数据使用或电池寿命产生任何负面影响。FL运行时请求作业调度程序仅在手机空闲、充电并连接到WiFi等未计量网络时调用作业。一旦启动,如果这些条件不再满足,FL运行时将中止,释放所分配的资源。
- 作业调用程序:服务器决定是否有任何FL任务可用于填充,并返回FL计划或稍后的建议签入时间。
- 广播:FL运行时向服务器报告计算的更新和指标,并清理任何临时资源。
多租户架构
支持在同一个应用程序(或服务)中培训多个FL群体。这允许多个训练活动之间的协调,避免设备因同时进行多个训练课程而过载。
匿名
排除了通过用户身份对其进行身份验证的可能性,使用Android的远程认证机制
服务器
人口大小和其他维度的多个数量级上操作的需求驱动,能够处理从数十个设备到数万个参与者的轮数,每轮收集和传递的更新大小可以从千字节到几十兆字节不等。根据设备空闲和充电的时间,进入或离开任何特定地理区域的流量在一天内可能会发生巨大变化。
角色模型
每个参与者都严格地按顺序处理消息/事件流,形成一个简单的编程模型。运行相同类型的参与者可以自然地扩展到大量的处理器/机器。作为对消息的响应,参与者可以做出本地决策,向其他参与者发送消息,或者动态地创建更多参与者。根据功能和可伸缩性需求,参与者实例可以共存于同一进程/机器上,也可以分布于多个地理区域的数据中心,使用显式或自动配置机制。
架构
协调器:实现全局同步和同步推进的顶级行为者,协调器接收到关于有多少设备连接到每个选择器的信息,并根据计划的FL任务指示它们接受多少设备参与。协调员产生的主要聚集管理轮的每个FL任务。

选择器负责接受和转发设备连接。它们定期从协调器接收关于每个FL填充需要多少设备的信息,它们使用这些信息来在本地决定是否接受每个设备。
主聚合器: 管理每个FL任务的轮次。随着设备数量和更新大小的增加而扩大规模,动态地决定生成一个或多个聚合器,并将工作委托给它们。
管道
通过并行运行协议下一轮的选择阶段和上一轮的配置/报告阶段,可以实现延迟优化。
分析
在设备和服务器之间的交互中有许多因素和故障保护机制。
- 单独的心理按样本不能直接检查,需要在测试和模拟中使用工具处理代理数据。
- 模型不能交互运行,必须编译成FL计划,通过FL服务器部署。
- FL计划运行在真实的设备上,模型资源消耗和运行时兼容性必须由基础设施自动验证
将输入张量映射到输出指标。当一个FL群中部署多个FL任务时,FL服务使用一种动态策略进行选择,允许在单个模型的培训和评估之间交替。
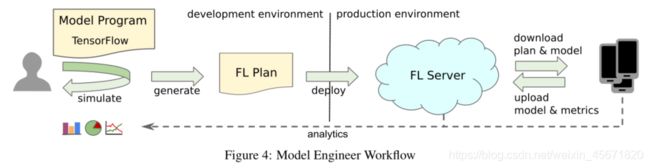
计划生成
每个FL任务都与FL计划相关联。计划是由模型工程师提供的模型和配置的组合自动生成的。FL计划由两部分组成: 一个用于设备,一个用于服务器。
未来的工作
偏差
如果设备参与的偏差或其他问题导致劣质模型,将被检测到。
收敛时间
联邦平均算法,只能有效地并行利用100个设备,但还有更多的算法可供选择;新的算法将大大提高FL的并行度。
第二篇
SCAFFOLD:使用控制方差来纠正局部更新中的“客户端漂移”。SCAFFOLD估计了服务器模型c和每个客户机ci的更新方向。(c−ci)是客户端漂移的估计,用于纠正本地更新。异构性很重要,但是相似性也很重要。
贡献
- 下界证明即使没有客户端抽样和全批梯度,FEDAVG因客户端漂移而比SGD慢。
- 证明SCAFFOLD至少和SGD一样快,并可以对任意异构的数据进行聚合
- SCAFFOLD可利用客户之间的相似之处,进一步减少所需的通信量,首次证明了本地步骤不是大批量SGD的优势。
- 证明了SCAFFOLD相对不受客户端取样获取方差降低率的影响,适合联邦学习。

假设f是 f ∗ f^* f∗的界, f i f_i fi满足 β \beta β-光滑。梯度 g i ( x ) g_i(x) gi(x)是 f i f_i fi的无偏估计,方差为 δ 2 \delta^2 δ2. 梯度差异的界,黑塞矩阵差异的界

强凸和非凸函数的界,及上述假设在下面的方案用到了:

收敛速度

上图是2个客户进行了3轮,本地更新想个别用户偏移。
异构性的界
当函数 f i f_{i} fi不同时,FEDAVG算法在每个客户端上的更新会漂移,从而减慢收敛速度。客户端的漂移量及收敛速度完全由(A1)中的梯度不同参数G决定。为了应对这种偏移,FEDAVG被迫使用更小的步长,反过来损害了收敛性。

服务器模型 x, SCAFFOLD维持每一个用户和服务器的状态。每一轮通信,服务器参数(x,c)传到参与的客户集合 S,集合中的客户初始化模型,
![]()

提供两个选项,选项I涉及对本地数据的额外传递,服务器x上计算梯度。选项II则重新使用先前计算的梯度来更新控制变量。选项I可能比II更稳定,这取决于应用程序,但II计算成本更低。


客户端是有状态的,在多轮中维持 c i c_i ci的状态,通常为0,等价于FedAvg.
更新本质是计算f的无偏估计,但需要和所有用户通信,Scaffold使用控制变量

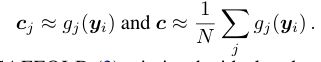
Scaffold度量了理想更新:
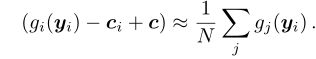
对于任意异构的客户机,SCAFFOLD的本地更新保持同步和收敛。
SCAFFOLD的收敛性

局部步骤的有用性
该算法利用控制变量来克服梯度的不相似性。通过强收敛证明了SCAFFOLD的有效性,取决于数据中的Hessian差异。