随着冬奥会的完美闭幕和残奥会的开幕,北京成为了奥运史上首个成功举办奥运会和冬奥会的“双奥之城”。在本届冬奥会赛场上,大家除了对赛场内奥运健儿们的表现印象深刻以外,在赛场外,中国的科技创新力量也让人眼前一亮。其中,自动驾驶作为“科技冬奥专项”的重点项目之一,首次实现全天候、多车型、全场景应用。
事实上,自动驾驶并不是第一次亮相奥运会。在 2018 年平昌冬奥会上,现代汽车就展示 L4 级自动驾驶功能的车辆,但由于当时数据量少、技术不成熟、车辆系统不稳定,产生了识别误差问题,导致出现了车辆经过人行横道时未主动减速刹车,需要驾驶员干预的情况。在自动驾驶生产过程中,一旦缺少数据,就意味着缺少模型来提升车辆精准度。数据对车辆环境感知、精准定位、路径规划都有一定的影响,而这些功能直接影响了车辆构建感知层、决策层、执行层的技术架构。
本篇文章重点分享自动驾驶厂商飞步科技通过使用焱融科技高性能分布式文件存储 YRCloudFile 快速存储及性能提升的实践过程。杭州飞步科技公司(以下简称:飞步科技),成立于 2017 年,在经历多次扩张后,飞步科技在自动驾驶领域获得较大突破。经过近 2 年的自动驾驶算法验证后,飞步科技于 2019 年开始研发基于 Level 4 级别的港口自动驾驶技术,并于 2020 年 5 月在舟山港梅山港区投入商用,开始与人工驾驶的卡车协同运作。
No.1 YRCloudFile 开启自动驾驶“进阶之路”
随着技术的不断升级,高性能、高可靠和高可用已然成为下一代自动驾驶存储解决方案的关键词,也成为各大公司存储技术发展的主流方向。面对自动驾驶技术发展过程中遇到的数据处理流程,焱融科技切实提出了相应的解决方案。
一站式数据服务平台,减少数据重复拷贝时间
当前,众多车企和解决方案提供商在提出方案时,通常会基于规模的限制和前期成本两方面考虑,采用传统的 NAS 存储来为上层应用提供数据访问。但是,因为传统存储的性能和并发性能都有一定限制,不能达到最优效果,所以客户往往采用拷贝的形式,以本地的电脑的 SSD 磁盘作为模型训练的存储底座。
实际上,这一整套架构体系不仅会耗费大量的数据拷贝时间,而且容易对大量客户端的并发造成不良后果,严重影响客户的研发进度及公司发展计划。在传统架构中,存在一定的局限性,容易限制 L4 级自动驾驶的研发进度和业务拓展,所以更换存储架构体系成为客户亟需解决的问题。
焱融科技认为可以通过统一的数据服务平台进行管理的方式,以此减少数据重复拷贝时间。其中,YRCloudFile 分布式存储系统能够实现:
- 有效确保数据被放置在多个节点的多个磁盘上,降低节点夯机和磁盘损坏带来的数据丢失几率,提高数据冗余性和解决数据独立存放带来的风险;
- 支持多客户端并发,有效提高并发效率和训练效率;
- 具备多元数据 MDS 服务,有利于提高海量训练文件的读写效率,以及快速完成训练模型开发的任务。
为了后续业务增长和扩容的需求,焱融科技 YRCloudFile 高性能分布式文件存储提供了快速便捷的方案,在升级过程中,保证业务持续运行。在统一的数据管理平台下,轻松解决了分散存储和反复拷贝数据所带来的时间消耗问题。
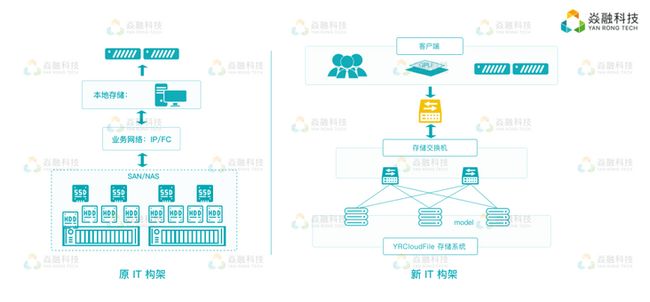 IT 架构对比图
IT 架构对比图
突破算法长尾场景难点,海量数据性能需求更加明确
当前,大家普遍认为制约自动驾驶技术发展的重要因素是,无法准确处理所有复杂环境下无限可能的长尾场景。但如果能让算法突破长尾场景,那么就需要控制单元更智能、响应速度更快、控制更精确。
面对算法的突破和控制单元更智能的要求,就需要研发人员采集大量的数据,支持研发的突破和 AI 芯片的智能提升,这也对海量数据性能有了更明确的要求。
为了解决这个问题,我们采取了可水平扩展设计的 MDS 架构方法,以此实现 MDS 集群化。这主要考虑到以下三方面:
- MDS 集群化有利于缓解 CPU,降低内存压力;
- 多个 MDS 有利于企业存储更多元的数据信息;
- 在实现元数据处理能力水平扩展的同时,提升海量文件并发访问的性能。
多级智能缓存+预读,解决多样化的海量混合文件读写能力
为了实现 L4 级自动驾驶能完全脱离人的掌控,通常会由车辆的控制单元和辅助支持单元来辅助车辆进行自动驾驶。通常车辆在城市道路行驶时,会面临大量复杂、多样化的场景。
从封闭的环境到高速公路,再到一般城市道路,道路环境会逐渐复杂和多样化。为了满足道路环境条件,这就要求 L4 级自动驾驶的车载系统覆盖和感知能力极高。
目前,覆盖的手段主要通过高精地图;感知能力主要依靠雷达、传感器、摄像头、卫星成像系统等。在面对多样化的数据类型和大小以及辅助手段的精确度时,我们更需要为存储提供海量非结构化数据大小文件混合的处理能力。
以往自动驾驶车辆通常会采用普通文件系统缓存的解决方案,但是其通常会面临两种问题:
- 普通文件系统缓存只提供内存缓存且容量有限,通常一台 GPU 服务器可用的内存缓存仅几十 GB 左右;
- 内存缓存 LRU 置换算法,导致缓存在每个 Epoch 的命中率低。
针对以上问题,焱融科技 YRCloudFile 高性能分布式文件存储提出通过私有客户端的方式,提供了多级智能缓存。这样的方式主要有三个优势:
- 内存缓存 + GPU 服务器 SSD 缓存;
- 对训练框架、应用程序完全透明;
- 在整个训练中,数据集加载速度实测提升幅度超过 500%。
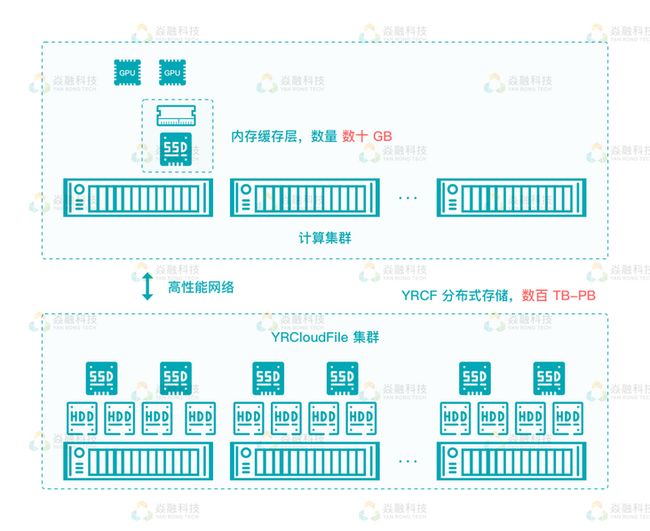 YRCloudFile 多级智能缓存
YRCloudFile 多级智能缓存
No.2 YRCloudFile 全面解决自动驾驶的问题
如今,自动驾驶训练过程是非常严谨的,不仅需要大量的训练数据,而且需要兼顾性能、运行效率和数据安全。为此,众多自动驾驶训练厂商会关注:如何避免资源抢占的分配问题,实现热数据在为 AI 提供高性能访问的特性的同时,冷数据可以在用户现有的低成本对象存储中有效保存。基于上述考虑,焱融科技 YRCloudFile 高性能分布式文件存储作出了如下优化:
智能冷热数据分层,有效平衡成本和性能
在自动驾驶训练过程中,YRCouldFile 文件存储系统的智能分层功能可以根据用户需要,自定义冷热数据策略,冷数据自动流动至低成本的公有云对象存储并完成压缩,向上仍然为业务提供标准的文件访问接口,并保持目录结构不变,数据在冷热数据层之间流动对业务完全透明,能有效地对成本和性能做好平衡。另外,焱融科技还进一步深度优化了产品:
- 标准文件接口,数据访问路径不改变;
- 目录级智能分层;
- 冷数据性能不降级;
- 统一纳管对象存储数据;
- 分层镜像双活
通过冷、热数据智能分层的方式,YRCloudFile 可以满足绝大多数企业在自动驾驶训练过程中,对于高性能存储和数据长期保存的需求。
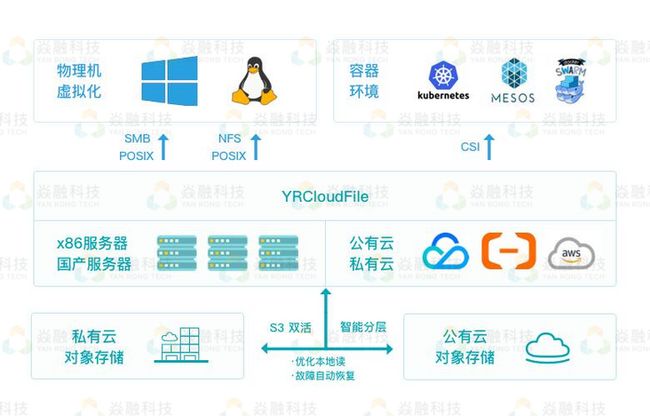 YRCloudFile 分布式存储架构图
YRCloudFile 分布式存储架构图
在高性能分布式文件存储 YRCloudFile 的帮助下,飞步科技解决了数据独立存放带来的风险,实现通过多客户端并发的方式,提高并发效率和训练效率。同时,YRCloudFile 的多元数据 MDS 服务,有效提高海量训练文件的读写效率,实现快速完成训练模型开发的任务。此外,YRCloudFile 还为飞步科技后续的业务增长和扩容提供快速便捷的方案,让业务无停滞。