决策树,随机森林,集成学习的算法实现
文章目录
- 一、决策树
-
- 1.训练和可视化决策树
- 2.训练数据集
- 3.可视化
- 4.绘制训练数据集
- 5.绘制决策边界
- 6.估计类别概率
- 7.正则化超参数
- 8.回归
- 9.可视化回归树
- 二.集成学习和随机森林
- 投票分类器
- Bagging & Pasting
- 总结
一、决策树
“决策树是通用的机器学习算法,可以执行分类和回归任务,甚至可以执行多输出任务。”
1.训练和可视化决策树
首先,让我们从sci-kit学习库中加载虹膜数据集。
X = iris.data[:, 2:] # only focus on petal length and width
Y = iris.target
feature_names = iris.feature_names[2:]
print("given:",feature_names,
"\npredict whether:", iris.target_names)
given: [‘petal length (cm)’, ‘petal width (cm)’]
predict whether: [‘setosa’ ‘versicolor’ ‘virginica’]
2.训练数据集
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X,Y)
DecisionTreeClassifier(class_weight=None, criterion=‘gini’, max_depth=2,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter=‘best’)
决策树分类器具有许多超参数。 您可以从上面的输出中看到将用于预测的参数。 可以在sci-kit学习中与决策树一起使用以下两个标准。 这些指标在决策树的每个节点中计算。
**Gini impurity criterion=‘gini’**是衡量从集合中随机选择的元素被错误标记的频率的度量。 形式上它是通过以下方式计算的: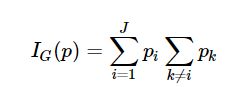
其中J表示类别,pi是标记为类别i的项的分数。
**Information Gain criterion=‘entropy’**是熵的度量,在热力学中用于度量分子无序。 熵= 0表示分子是有序的。
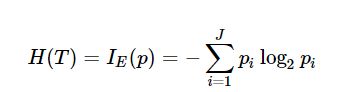
p1,p2,…与Gini一样,是加起来为1的分数。
这两个指标用于在训练决策树时确定拆分。
3.可视化
您可以将决策树从sci-kit Learn中导出为点文件。 您可以通过安装graphviz将点转换为png图像。
from sklearn.tree import export_graphviz
export_graphviz(tree_clf,
out_file="iris_tree.dot",
feature_names=feature_names,
class_names=iris.target_names,
rounded=True,
filled=True
)
# Make sure you installed graphviz (exclamation mark is for shell commands)
!apt install graphviz
# Convert dot file to png file.
!dot -Tpng iris_tree.dot -o iris_tree.png
from IPython.display import Image
Image(filename='iris_tree.png')
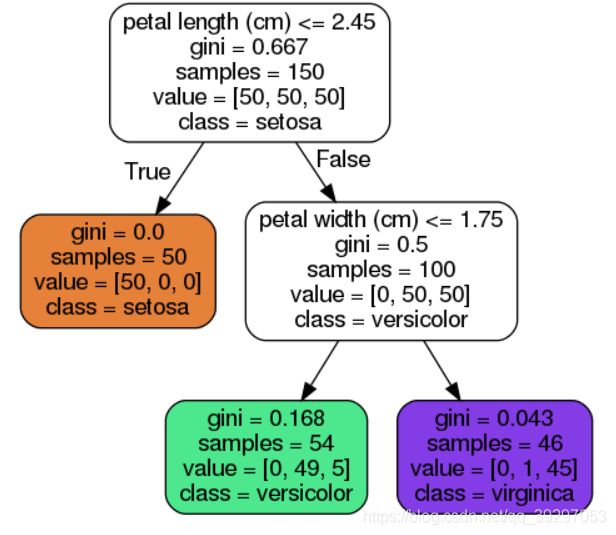
可视化决策树的另一种方法
ANTLR(解析器生成器)的创建者提供了一个全新的可视化库,用于决策树,称为dtreeviz。 您可以从其存储库中找到其他一些示例,以实现更好的可视化。 请按照以下步骤操作:
# install the package
!pip install dtreeviz
# (optional)
!apt-get install msttcorefonts -qq
from dtreeviz.trees import dtreeviz
import matplotlib as mpl
mpl.rcParams['axes.facecolor'] = 'white'
viz = dtreeviz(tree_clf,
X,
Y,
target_name='flower type',
feature_names=feature_names,
class_names=list(iris.target_names),
fancy=True,
orientation ='TD')
# uncomment this
# viz
4.绘制训练数据集
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
CUSTOM_CMAP = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
# helper function to plot the boundaries
def plot_decision_boundary(clf, x, y):
color_map = ["yo", "bs", "g^"]
for target_index, target_name in enumerate(iris.target_names):
plt.plot(x[:, 0][y==target_index], # petal length on X axis (the ones that equal to target)
x[:, 1][y==target_index], # petal width on Y axis (the ones that equal to target)
color_map[target_index],
label=target_name)
x1s = np.linspace(np.min(x[:, 0]), np.max(x[:, 0]), 100)
x2s = np.linspace(np.min(x[:, 1]), np.max(x[:, 1]), 100)
x1, x2 = np.meshgrid(x1s, x2s)
x_test = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(x_test).reshape(x1.shape)
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=CUSTOM_CMAP)
plot_decision_boundary(tree_clf, X, Y)
plt.xlabel(feature_names[0]) # petal length (cm)
plt.ylabel(feature_names[1]) # petal width (cm)
plt.show()
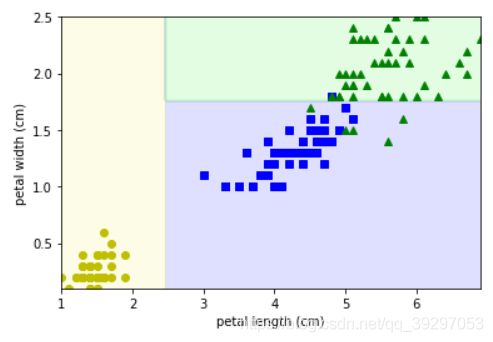
5.绘制决策边界
# check np.mgrid[minX1:maxX1:increment, minX2:maxX2:increment]
X = np.mgrid[0:10:1, -5:0:1].reshape(2,-1).T
X
6.估计类别概率
要估计实例属于某个类的可能性,可以使用predict_proba来确定将分配实例以使用predict的类。
tree_clf.predict_proba([[5, 1.5]])
tree_clf.predict([[5, 1.5]])
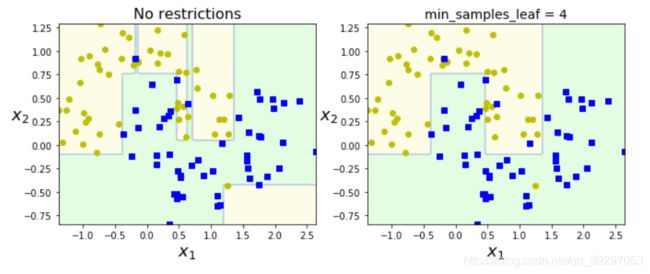
7.正则化超参数
“限制模型使其更简单并降低过度拟合的风险称为_regularization” 为避免过度拟合,您可以通过min_samples_leaf限制节点的生成(节点必须具有的最小样本数分裂)。
from sklearn.datasets import make_moons
Xm, ym = make_moons(n_samples=100, noise=0.25, random_state=53)
deep_tree_clf1 = DecisionTreeClassifier(random_state=42)
deep_tree_clf2 = DecisionTreeClassifier(min_samples_leaf=4, random_state=42)
deep_tree_clf1.fit(Xm, ym)
deep_tree_clf2.fit(Xm, ym)
plt.figure(figsize=(11, 4))
plt.subplot(121)
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
plot_decision_boundary(deep_tree_clf1, Xm, ym)
plt.title("No restrictions", fontsize=16)
plt.subplot(122)
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
plot_decision_boundary(deep_tree_clf2, Xm, ym)
plt.title("min_samples_leaf = {}".format(deep_tree_clf2.min_samples_leaf), fontsize=14)
plt.show()
8.回归
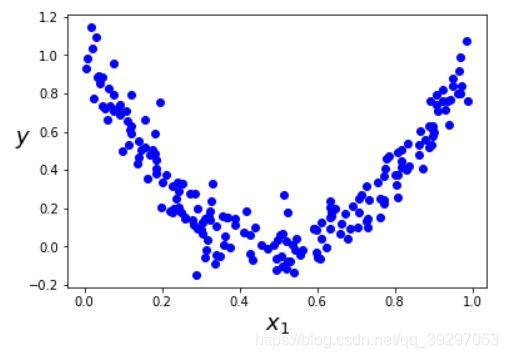
决策树也可以用于回归任务。 在回归任务中,目标不是预测类别,而是预测数字值(例如汽车的价格)。 假设我们有一些噪声的二次数据集:
# Quadratic training set + noise
np.random.seed(42)
m = 200
X = np.random.rand(m, 1)
y = 4 * (X - 0.5) ** 2
Y = y + np.random.randn(m, 1) / 10
plt.plot(X, Y, "bo")
plt.xlabel("$x_{1}$", fontsize=18)
plt.ylabel("$y$", fontsize=18, rotation=0)
plt.show()
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X,Y)
DecisionTreeRegressor(criterion=‘mse’, max_depth=2, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter=‘best’)
9.可视化回归树
使用graphviz可视化与以前相同的回归树。
绘制此回归树(提示:尝试x的许多值(例如np.linspace(min,max,noOfPoints)))
绘制max_depth = 2和max_depth = 3回归树的决策边界(也可以尝试min_samples_leaf = 10)
比较差异图上的差异。 注意,平均值是在由决策树回归器分隔的区域中得出的。
Xs = np.linspace(0, 1, 100)
Xs
# predict Y values for Xs and plot
二.集成学习和随机森林
为了改善我们的预测,我们不再使用单个学习器,而是使用一个整体:一组学习器。 就像您要向许多专家提出有关问题的意见并汇总他们的答案一样。
投票分类器
使用三个预测变量进行软投票和硬投票的简要比较:
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X, Y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=42)
from sklearn.metrics import accuracy_score
def test_clfs(*clfs): # clf -> classifier
for clf in clfs:
clf.fit(X_train, Y_train) # train the classifier
Y_pred = clf.predict(X_test)
print(clf.__class__.__name__ + ":", accuracy_score(Y_test, Y_pred))
让我们先测试硬投票。
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# Don't worry about the warnings,
# sci-kit community will be fixing it in the next major version 0.20.0
log_clf = LogisticRegression(random_state=42)
rnd_clf = RandomForestClassifier(random_state=42)
svm_clf = SVC(random_state=42, probability=True)
voting_clf = VotingClassifier(estimators=[('lr', log_clf),
('rf', rnd_clf),
('svc', svm_clf)],
voting='hard')
test_clfs(log_clf, rnd_clf, svm_clf, voting_clf)
结果:
LogisticRegression: 0.864
RandomForestClassifier: 0.872
SVC: 0.888
VotingClassifier: 0.896
Bagging & Pasting
代替给整体中的每个预测变量提供训练集,获取更高准确性的另一种方法是分离训练集,并为每个预测变量提供不同的训练子集。 有两种方法:
Bagging:从训练集中选择一个随机子集,而不是从每个预测变量的训练集中删除此选定的集合,即通过替换抽样
Pasting:从训练集中选择一个随机子集,然后从训练集中为每个预测变量删除此选定的集合,即不替换而进行采样。
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
# define our decision tree classifier
tree_clf = DecisionTreeClassifier(random_state=42)
# 500 copies of the predictor, which has 100 samples from training set
# n_jobs=-1 for utilizing all cores
bag_clf = BaggingClassifier(tree_clf,
n_estimators=500,
max_samples=100,
bootstrap=True,
n_jobs=-1,
random_state=42)
# fit the bagging classifier
bag_clf.fit(X_train, Y_train)
tree_clf.fit(X_train, Y_train)
Y_pred_bag = bag_clf.predict(X_test)
Y_pred_tree = tree_clf.predict(X_test)
from sklearn.metrics import accuracy_score
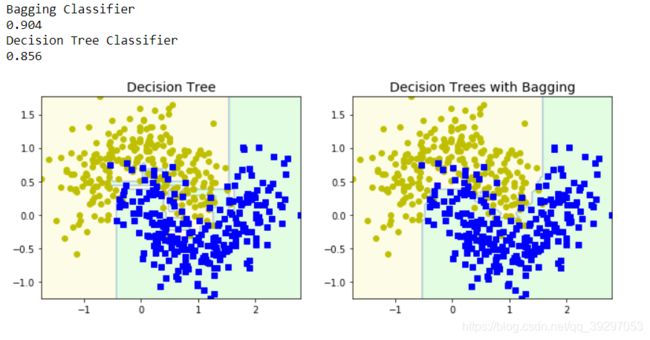
print("Bagging Classifier")
print(accuracy_score(Y_test, Y_pred_bag))
print("Decision Tree Classifier")
print(accuracy_score(Y_test, Y_pred_tree))
plt.figure(figsize=(11,4))
plt.subplot(121)
plot_decision_boundary(tree_clf, X, Y)
plt.title("Decision Tree", fontsize=14)
plt.subplot(122)
plot_decision_boundary(bag_clf, X, Y)
plt.title("Decision Trees with Bagging", fontsize=14)
plt.show()
总结
本章讨论了基于sk-learn框架的决策树,集成学习等算法的代码实现