R语言--基础(三)
1. 字符串
- 连接字符串 - paste()函数
对于粘贴功能的基本语法是 -
paste(..., sep = " ", collapse = NULL)
以下是所使用的参数的说明 -
-- ...表示要组合的任意数量的自变量。
-- sep表示参数之间的任何分隔符。它是可选的。
-- collapse用于消除两个字符串之间的空格。 但不是一个字符串的两个字内的空间。
示例:
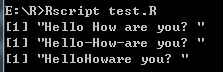
# 连接字符串 - paste()函数
a <- "Hello"
b <- 'How'
c <- "are you? "
print(paste(a,b,c))
print(paste(a,b,c, sep = "-"))
print(paste(a,b,c, sep = "", collapse = ""))
打印结果:
- 格式化数字和字符串 - format()函数
格式化函数的基本语法是 -
format(x, digits, nsmall, scientific, width, justify = c("left", "right", "centre", "none"))
以下是所使用的参数的描述 -
-- x是向量输入。
-- digits是显示的总位数。
-- nsmall是小数点右边的最小位数。
-- scientific科学设置为TRUE以显示科学记数法。
-- width指示通过在开始处填充空白来显示的最小宽度。
-- justify是字符串向左,右或中心的显示。
示例:
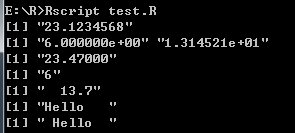
# 格式化函数 - format()函数
# 显示总位数
result <- format(23.123456789, digits = 9)
print(result)
# 科学计数法显示
result <- format(c(6, 13.14521), scientific = TRUE)
print(result)
# 小数右边最小位数
result <- format(23.47, nsmall = 5)
print(result)
# 格式化为一个字符串
result <- format(6)
print(result)
# 设置数据宽度
result <- format(13.7, width = 6)
print(result)
# 设置对齐方式-左对齐
result <- format("Hello", width = 8, justify = "l")
print(result)
# 设置对齐方式-居中
result <- format("Hello", width = 8, justify = "c")
print(result)
打印结果:
- 字符串中的字符数 - nchar()函数
nchar()函数的基本语法是 -
nchar(x)
以下是所使用的参数的描述 -
-- x是向量输入。
示例:
# 计算字符数-nchar()
result <- nchar("Count the number of characters.")
print(result)
打印结果:
- 更改大小写 - toupper()和tolower()函数
toupper()和tolower()函数的基本语法是 -
toupper(x)
tolower(x)
以下是所使用的参数的描述 -
-- x是向量输入。
示例:
# 更改大小写
# 转换大写
result <- toupper("Changin To Upper")
print(result)
# 转换小写
result <- tolower("Changin To Upper")
print(result)
打印结果:

- 提取字符串的一部分 - substring()函数
substring()函数的基本语法是 -
substring(x,first,last)
以下是所使用的参数的描述 -
-- x是字符向量输入。
-- 首先是要提取的第一个字符的位置。
-- last是要提取的最后一个字符的位置。
示例:
# 截取字符串
result <- substring("Extract", 5, 7)
print(result)
打印结果:
2. 向量
- 创建向量
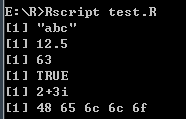
# 创建向量
# 字符向量
print("abc")
# 双精度向量
print(12.5)
# 整型向量
print(63L)
# 逻辑型向量
print(TRUE)
# 复数向量
print(2+3i)
# 原型向量
print(charToRaw('Hello'))
示例:
- 多元素向量
# 多元素向量
# 创建序列5-13
v <- 5:13
print(v)
# 创建序列6.6-12.6
v <- 6.6:12.6
print(v)
# 如果最后的结点是特殊的,未在序列中定义
v <- 3.8:11.4
print(v)
打印结果:
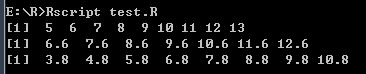
- 使用sequence (Seq.)序列运算符
# 创建从5-9,涨幅为0.4的向量
print(seq(5, 9, by = 0.4))
打印结果:
- 使用c()函数
# 使用c函数--如果其中一个元素是字符,则非字符值被强制转换为字符类型
s <- c('apple', 'red', 5, TRUE)
print(s)
打印结果:
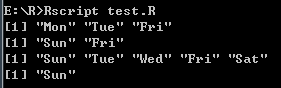
- 访问向量元素
# 访问向量元素
# 使用索引访问向量的元素。 []括号用于建立索引。 索引从位置1开始。在索引中给出负值会丢弃来自result.TRUE,FALSE或0和1的元素,也可用于索引。
t <- c("Sun", "Mon", "Tue", "Wed", "Thurs", "Fri", "Sat")
# 使用坐标
v <- t[c(2, 3, 6)]
print(v)
# 使用逻辑值
v <- t[c(TRUE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE)]
print(v)
# 使用负数
v <- t[c(-2,-5)]
print(v)
# 使用0/1
v <- t[c(0,0,0,0,0,0,1)]
print(v)
打印结果:
- 向量运算
# 向量操作
# 创建两个向量
v1 <- c(3, 8, 4, 5, 0, 11)
v2 <- c(4, 11, 0, 8, 1, 2)
# 向量加法
add.result <- v1 + v2
print(add.result)
# 向量减法
sub.result <- v1 - v2
print(sub.result)
# 向量乘法
multi.result <- v1 * v2
print(multi.result)
# 向量除法
div.result <- v1 / v2
print(div.result)
打印结果:

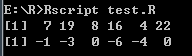
- 向量元素回收
# 向量元素回收
# 如果我们对不等长的两个向量应用算术运算,则较短向量的元素被循环使用
v1 <- c(3, 8, 4, 5, 0, 11)
v2 <- c(4, 11)
# v2 -> c(4, 11, 4, 11, 4, 11)
add.result <- v1 + v2
print(add.result)
sub.result <- v1 - v2
print(sub.result)
打印结果:
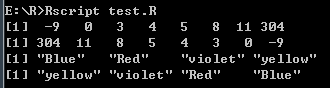
- 向量元素排序(sort()函数)
# 向量排序
v <- c(3, 8, 4, 5, 0, 11, -9, 304)
# 排序
sort.result <- sort(v)
print(sort.result)
# 递减排序
revsort.result <- sort(v, decreasing = TRUE)
print(revsort.result)
# 字符排序
v <- c("Red", "Blue", "yellow", "violet")
sort.result <- sort(v)
print(sort.result)
# 递减排序
revsort.result <- sort(v, decreasing = TRUE)
print(revsort.result)
3. 列表
- 创建列表
# 创建列表
list_data <- list("Red", "Green", c(21, 32, 11), TRUE, 51.23, 119.1)
print(list_data)
打印结果:
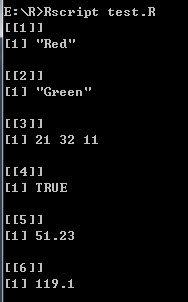
- 命名列表元素
# 创建一个包含向量,矩阵,列表的列表
list_data <- list(c("Jan", "Feb", "Mar"), matrix(c(3, 9, 5, 1, -2, 8), nrow = 2), list("green", 12.3))
# 命名
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
print(list_data)
打印结果:

- 访问列表元素
# 创建一个包含向量,矩阵,列表的列表
list_data <- list(c("Jan", "Feb", "Mar"), matrix(c(3, 9, 5, 1, -2, 8), nrow = 2), list("green", 12.3))
# 命名
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# 打印第一个结点数据
print(list_data[1])
print("===========================")
# 打印第三个结点数据
print(list_data[3])
print("===========================")
# 使用名字访问
print(list_data$A_Matrix)
print("===========================")
打印结果:
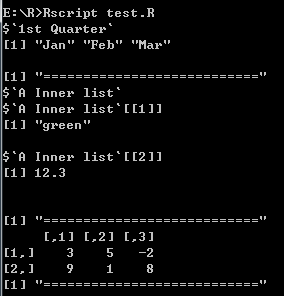
- 操控列表元素
# 操控列表元素
# 创建一个包含向量,矩阵,列表的列表
list_data <- list(c("Jan", "Feb", "Mar"), matrix(c(3, 9, 5, 1, -2, 8), nrow = 2), list("green", 12.3))
# 命名
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# 在列表的末尾添加节点
list_data[4] <- "New element"
print(list_data[4])
# 移除最后一个节点
list_data[4] <- NULL
print(list_data[4])
# 更新第三个节点
list_data[3] <- "updated element"
print(list_data[3])
打印结果:

- 合并列表
# 合并列表
list1 <- list(1, 2, 3)
list2 <- list("Sun", "Mon", "Tue")
# 合并两个列表
merged.list <- c(list1, list2)
print(merged.list)
打印结果:
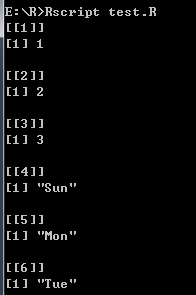
- 列表转换为向量
# 列表转换为向量--unlist()函数
list1 <- list(1:5)
print(list1)
list2 <- list(10:14)
print(list2)
# 将列表转换为向量
v1 <- unlist(list1)
v2 <- unlist(list2)
print(v1)
print(v2)
# 计算和
result <- v1 + v2
print(result)
打印结果:
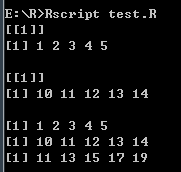
4. 矩阵
- 语法
在R语言中创建矩阵的基本语法是 -
matrix(data, nrow, ncol, byrow, dimnames)
以下是所使用的参数的说明 -
-- 数据是成为矩阵的数据元素的输入向量。
-- nrow是要创建的行数。
-- ncol是要创建的列数。
-- byrow是一个逻辑线索。 如果为TRUE,则输入向量元素按行排列。
-- dimname是分配给行和列的名称。
示例:
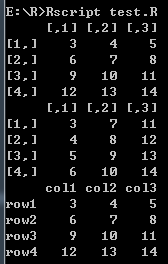
# 创建矩阵
# 按行排列
M <- matrix(c(3:14), nrow = 4, byrow = TRUE)
print(M)
# 按列排列
M <- matrix(c(3:14), nrow = 4, byrow = FALSE)
print(M)
# 定义行和列的名字
rowName = c("row1", "row2", "row3", "row4")
colName = c("col1", "col2", "col3")
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rowName, colName))
print(P)
打印结果:
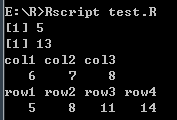
- 访问矩阵的元素
# 访问矩阵元素
rowName = c("row1", "row2", "row3", "row4")
colName = c("col1", "col2", "col3")
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rowName, colName))
# 打印第一行第三列
print(P[1, 3])
# 打印第四行第二列
print(P[4, 2])
# 仅打印第二行
print(P[2, ])
# 打印第三列
print(P[ , 3])
打印结果:
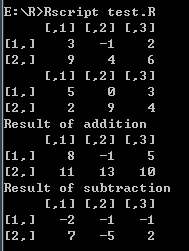
- 矩阵加法和减法
# 矩阵加法和减法
matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2)
print(matrix1)
matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2)
print(matrix2)
# 矩阵加法
result <- matrix1 + matrix2
cat("Result of addition","
")
print(result)
# 矩阵减法
result <- matrix1 - matrix2
cat("Result of subtraction","
")
print(result)
打印结果:
- 矩阵乘法和除法
# 矩阵乘法和除法
matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2)
print(matrix1)
matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2)
print(matrix2)
# 矩阵乘法
result <- matrix1 * matrix2
cat("Result of multiplicaion","
")
print(result)
# 矩阵除法
result <- matrix1 / matrix2
cat("Result of division","
")
print(result)
打印结果:

5. 数组
- 创建数组
# 创建数组
vector1 <- c(5, 9, 3)
vector2 <- c(10, 11, 12, 13, 14, 15)
# 将向量输入到数组中,c(3, 3, 2),它创建2个矩形矩阵,每个矩阵具有3行和3列。 数组只能存储数据类型。
result <- array(c(vector1, vector2), dim = c(3, 3, 2))
print(result)
打印结果:
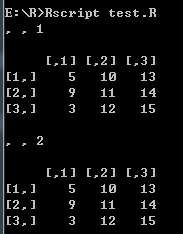
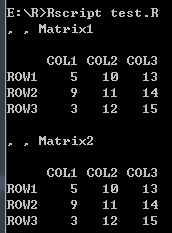
- 命名行和列
# 命名行和列
vector1 <- c(5, 9, 3)
vector2 <- c(10, 11, 12, 13, 14, 15)
# 命名
column.names <- c("COL1", "COL2", "COL3")
row.names <- c("ROW1", "ROW2", "ROW3")
matrix.names <- c("Matrix1", "Matrix2")
result <- array(c(vector1, vector2), dim = c(3, 3, 2), dimnames = list(row.names, column.names, matrix.names))
print(result)
打印结果:
- 访问数组元素
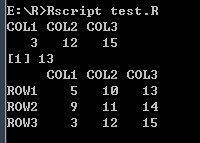
# 访问数组元素
vector1 <- c(5, 9, 3)
vector2 <- c(10, 11, 12, 13, 14, 15)
# 命名
column.names <- c("COL1", "COL2", "COL3")
row.names <- c("ROW1", "ROW2", "ROW3")
matrix.names <- c("Matrix1", "Matrix2")
result <- array(c(vector1, vector2), dim = c(3, 3, 2), dimnames = list(row.names, column.names, matrix.names))
# 打印第二个矩阵第三行
print(result[3, , 2])
# 打印第一个矩阵第一行第三个数据
print(result[1, 3, 1])
# 打印第二个矩阵
print(result[, , 2])
打印结果:
- 操作数组元素
# 操作数组元素
vector1 <- c(5, 9, 3)
vector2 <- c(10, 11, 12, 13, 14, 15)
array1 <- array(c(vector1, vector2), dim = c(3, 3, 2))
print(array1)
print("============================")
vector3 <- c(9, 1, 0)
vector4 <- c(6, 0, 11, 3, 14, 1, 2, 6, 9)
array2 <- array(c(vector3, vector4), dim = c(3, 3, 2))
print(array2)
print("============================")
matrix1 <- array1[, , 2]
matrix2 <- array2[, , 2]
result <- matrix1 + matrix2
print(result)
打印结果:

- 跨数组元素的计算--apply()
语法
apply(x, margin, fun)
以下是所使用的参数的说明 -
-- x是一个数组。
-- margin是所使用的数据集的名称。
-- fun是要应用于数组元素的函数。
示例:
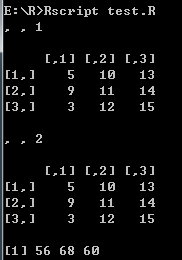
# 跨数组元素的计算
vector1 <- c(5, 9, 3)
vector2 <- c(10, 11, 12, 13, 14, 15)
new.array <- array(c(vector1, vector2), dim = c(3, 3, 2))
print(new.array)
# 其中c(1)代表行相加,c(2)代表列相加,c(3)代表矩阵和
result <- apply(new.array, c(1), sum)
print(result)
打印结果:
6. 因子
- 获取因子
# 创建向量
data <- c("East", "West", "East", "North", "North", "East", "West", "West", "West", "East", "North")
print(data)
# 打印是否为因子
print(is.factor(data))
# 创建因子
factor_data <- factor(data)
print(factor_data)
# 打印是否为因子
print(is.factor(factor_data))
打印结果:

- 数据帧的因子
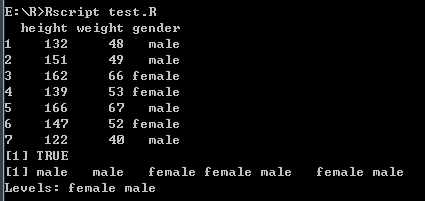
# 为数据帧创建向量
height <- c(132, 151, 162, 139, 166, 147, 122)
weight <- c(48, 49, 66, 53, 67, 52, 40)
gender <- c("male", "male", "female", "female", "male", "female", "male")
# 创建数据帧
input_data <- data.frame(height, weight, gender)
print(input_data)
# 测试性别是否是因子
print(is.factor(input_data$gender))
# 打印性别列等级
print(input_data$gender)
打印结果:
- 更改级别顺序
# 更改级别顺序
data <- c("East","West","East","North","North","East","West","West","West","East","North")
# 创建因子
factor_data <- factor(data)
print(factor_data)
# 应用因子函数,重新设置因子级别
new_order_data <- factor(factor_data, levels = c("East", "West", "North"))
print(new_order_data)
打印结果:

- 生成因子级别
我们可以使用gl()函数生成因子级别。 它需要两个整数作为输入,指示每个级别有多少级别和多少次。
gl(n, k, labels)
以下是所使用的参数的说明 -
-- n是给出级数的整数。
-- k是给出复制数目的整数。
-- labels是所得因子水平的标签向量。
示例:
# 生成因子级别
v <- gl(3, 4, labels = c("Tampa", "Seattle", "Boston"))
print(v)
打印结果:

7. 数据帧
- 创建数据帧
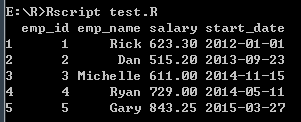
# 创建数据帧
emp.data <- data.frame(
emp_id = c(1:5),
emp_name = c("Rick", "Dan", "Michelle", "Ryan", "Gary"),
salary = c(623.3, 515.2, 611.0, 729.0, 843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11", "2015-03-27")),
stringsAsFactors = FALSE
)
print(emp.data)
打印结果:
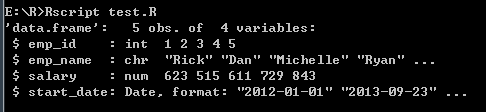
- 获取数据帧的结构
# 获取数据帧结构--str()
str(emp.data)
打印结果:
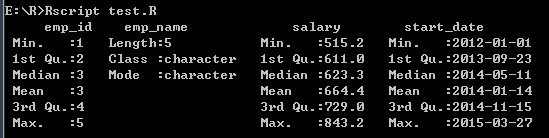
- 数据框中的数据摘要
# 数据框中的数据摘要
print(summary(emp.data))
打印结果:
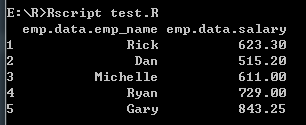
- 从数据帧提取数据
# 从数据帧中提取数据
result <- data.frame(emp.data$emp_name, emp.data$salary)
print(result)
打印结果:
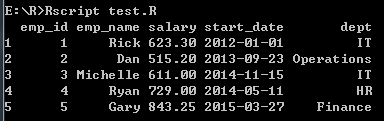
- 添加列
# 添加列
emp.data$dept <- c("IT", "Operations", "IT", "HR", "Finance")
v <- emp.data
print(v)
打印结果:
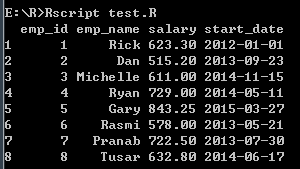
- 添加行
# 添加行
# 创建第二个数据帧
emp.newdata <- data.frame(
emp_id = c(6:8),
emp_name = c("Rasmi", "Pranab", "Tusar"),
salary = c(578.0, 722.5, 632.8),
start_date = as.Date(c("2013-05-21","2013-07-30","2014-06-17")),
# dept = c("IT", "Operations", "Finance"),
stringsAsFactors = FALSE
)
emp.finaldata <- rbind(emp.data, emp.newdata)
print(emp.finaldata)
打印结果: