©原创作者 | 朱林
论文解读:
Can Generative Pre-trained Language Models Serve as Knowledge Bases for Closed-book QA?
论文作者:
Cunxiang Wang, Pai Liu, Yue Zhang
论文地址:
https://aclanthology.org/2021.acl-long.251.pdf
收录会议:
ACL2021
代码和数据集:
https://github.com/wangcunxiang/Can_PLM_Server_as_KB
01 背景

图1 预训练语言模型
BERT、GPT等大型预训练语言模型(Pre-trained Language Model, PLM)显著提高了各种自然语言处理(NLP)任务的性能。
越来越多的证据表明PLM中蕴含着大千世界丰富的知识,故最新的实验研究着重探究“LM as KB”的范式,即直接生成语言模型作为知识库(Knowledge Base, KB)来解决问题。
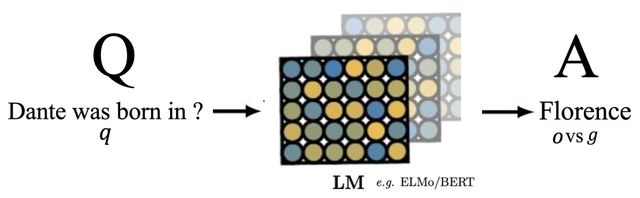
图2 LM直接完成闭卷问答任务
本文探讨的就是是否可以用PLM作为KB来完成闭卷问答(Closed-book QA)任务。该任务是一项极具挑战性的任务,它需要一个模型能直接回答问题,而无需访问外部知识。
形式上如图2所示,输入问题q,输出词序列o,同时将正确答案g与输出结果o进行比较来评估模型准确性。
02 问题
由于PLM天然可以存储和使用知识,所以它们可以在闭卷问答任务中实现较高的性能。然而,现有的研究留下了许多悬而未决的问题,比如:
(1) PLM在闭卷问答任务上到底有多少潜力?比如:用于训练的数据集仅包含了标准问答对数据集,是否可以通过其他语料数据来训练?在回答闭卷问题之前,是否有机制可以控制具体使用哪些知识来训练PLM?
(2)目前,主要研究成果基于的实验数据集里面训练集和测试集数据之间有较高重合,使得我们难以分辨出训练出的模型给出的答案到底是来自其固有知识(泛化能力强)还是训练数据中的表层线索(泛化能力弱)。
03 探究
实验准备与说明
为了探讨之前研究所遗留的问题,本文作者用SQuAD数据集构建了一套新的问答数据集(以下亦称为SQuAD),原始SQuAD数据集是一个阅读理解数据集,其中每个问题都有一个对应的维基百科段落作为可追溯的知识源,新SQuAD将原始数据集改造为了问答对数据集,该数据集的特点是训练集和测试集的数据重合度低。
其他数据集均为传统问答任务常用的问答数据集,如WebQuestions(WB)、TriviaQA(TQ)和NaturalQuestions(NQ),这三者有重合度高的特点,如表1所示。
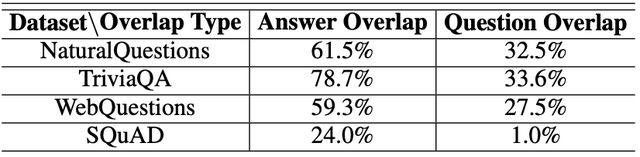
表1 四个数据集的问答数据重合度
同时,本文选用BART模型作为PLM的主实验对象,因为它在众多生成任务上取得了最先进的结果。当然,作者也比较了GPT-2/3模型,相关结果和BART表现一致。
实验结果
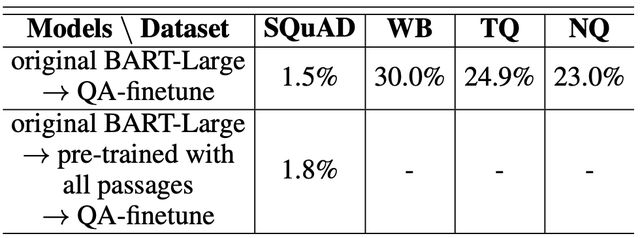
表2 BART在四个数据集上闭卷问答任务的准确率结果
四个数据集的准确率结果显示在表2的第一行,其中BART模型在三个数据集WB、TQ和NQ上取得了相对较高的结果,但它在SQuAD上表现不佳,准确率仅为1.5%。
作者还使用SQuAD段落进一步预训练BART,然后进行QA-funetune。结果如表2的第二行所示,性能为1.8%,略好于1.5%,但仍然极低。
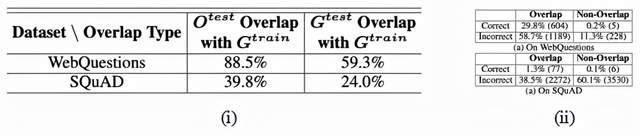
表3 重合分析结果
为了检测重合率对结果的影响,作者定义如下符号:

作者选择WQ作为高重合数据集的典型,以与低重合的SQuAD进行比较。

结果表明,如果测试问题与训练问题有很大的重合,则模型倾向于在训练集中就生成目标和单词。

04 改进
通过分析、对比和探究BERT在不同数据集上的表现,作者找到了一些有希望改进结果的方向。可以通过使用简单的数据增强技巧,例如,简单地将相关段落添加到测试输出中可以帮助BART检索相关的知识并给出正确的答案。
此外,用类似的方式处理问答,进行QA-finetuning。将语言模型预生成和问答优化任务解耦可以让模型更好地保留知识。
总体设计

图3 为闭卷问答生成PLM的优化过程
如图3所示,作者的设计受到课堂教学的启发。
老师首先讲授课本内容,然后让学生背诵书中的要点,以测试他们对这本书的了解程度。
接下来,老师给学生一些练习题进行练习。
最后,老师给出一组不同的试题来测试学生。注意是整本书讲授和背诵,而不是一本书的拆分,练习题和考试题都与本书有关。
教学&背诵
方法
为了研究BART是否可以从原始语料库中获取和存储知识,作者使用SQuAD中的段落来微调BART模型,作者称之为LM-finetuning。这段时期可以看作是为BART注入知识,亦称“教学”。然后测试模型以检查BART可以记住多少知识,称为“背诵”。
LM-finetuning训练阶段(教学):作者遵循BART的原始训练目标进行MLM-finetune步骤,这是一个去噪自动编码过程。
传统BART训练目标有五个操作,作者在这里只采用了词填充。对于每个输入段落,作者随机遮掩(Mask)了30%的词喂给模型进行训练,如图3的第三行所示。

图4 LM-finetuning训练和测试期间两种Mask策略的示例
LM-finetuning测试阶段(背诵):在这一阶段,作者开发了一个名为“背诵”的任务来检测模型有学到了多少特定的知识。
作者的背诵任务是给PLM几个Mask段落并要求PLM恢复它们。对每个段落,作者遮掩了作为相关问题的答案,如图4最后一行所示。通过这种方式,如果BART可以恢复特定遮掩的段落,它必须具有进一步问答所需的知识。
由于Answer Spans大多是实体或独立的知识片段,模型通过启发式或表面线索恢复它们的可能性相对较小。
结果

表4模型“背诵”表现
作者首先使用原始BART、随机初始化BART和LM-finetuning的BART对所有SQuAD段落进行背诵实验,结果如表4(i)所示。
随机初始化BART给出0准确率,表明该任务很困难,没有猜测的可能性。原始BART得分为2.2%,表明它包含某些有限的知识。
LM-finetuning的BART的准确度为2.7%,这个结果表明其在一定程度上是有用的,但仍然不高,BART在记忆重要知识方面面临重大挑战。
鉴于上述观察,作者尝试通过从SQuAD中提取子集来生成更小的数据集来降低挑战难度。结果如表4(ii)的前两行所示,作者发现当量增加时,记忆能力迅速下降。
作者得出结论,BART具有一定的存储知识的能力,但该能力较弱。如果控制LM-finetuning的段落数,可以确保BART记住最需要的知识。当确信相关知识被保留时,在较小子集上训练的LM-finetuning模型是更好的选择。
练习&考试
方法
作者提出了一种加强知识检索的简单方法,即QA-bridge-tune,这是一个扩展的QA-finetuning过程。
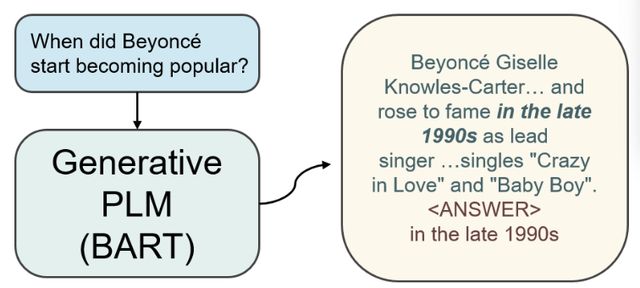
图5 一种直观的QA-bridge-tuning方法
该过程如图5所示,对于每个问题输入,输出将相关段落与答案连接起来。由此,该模型在回答问题时可以显式地回忆记忆过的段落,QA-bridge-tune通过它在问答和记忆知识之间架起一座桥梁,使模型可以用学到的知识回答问题。此外,这种方法可以帮助提高可解释性。
结果
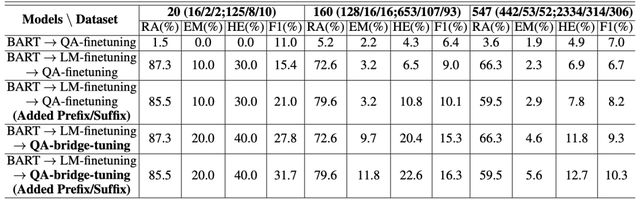
图6多种BERT优化组合模型在SQuAD问答任务性能表现
结果如表6所示,可以看到QA-bridge-tune帮助模型在问答时唤醒相关的记忆知识,从而提高准确率,在基线上提高2到3倍。
05 结论
本文通过细致实验分析探讨了“LM as KB”范式下解决闭卷问答任务时采用普通PLM会产生的诸多问题。
实验表明,闭卷问答任务对于PLM(如BART)仍然具有极大挑战性。这种挑战既在于需要模型记住知识细节,也在于记住知识后如何回答问题。
作者通过采用简单预处理方法对于PLM分多步进行微调,将学习记忆和回答问题过程进行了解耦,提供了一个不错的优化思路。
06 启发与思考
本文留给了我们一些启发与思考:
(1)“LM as KB ”这一范式是目前的一个研究热点,理想情况下,这种范式下可以为很多NLP问题,尤其是QA问题提供非常通用便捷的解决方案。但是目前在实际应用中准确率不高,有很多问题亟待深入研究;
(2)有监督的深度学习方法重新设计数据输入或者数据增强,虽然简单,但是也是不能忽视的提高模型性能的手段之一;
(3)对于前人的方法和结论,需要多辩证思考、提问和批判,自己亲自动手实验验证最佳。实验设计要全面,片面的实验可能会产生令人误导的结果;
(4)模型流程更加精细化、过程寻求可解释性是未来深度学习学术研究的趋势;
(5)学会观察生活,从生活中汲取灵感,很多绝妙想法往往来源于朴素的生活现象或者生活道理。比如本文的灵感就来自于我们日常的课堂教学过程。