Kafka原理1
文章目录
- Kafka
-
- Kafka使用场景
-
- 消息传递 Messaging
- website Activity tracking 网站活动跟踪
- Log Aggregation 日志聚合
- 应用指标监控
- 数据集成+流式计算
- Kafka的安装
- Kafka架构分析
-
- Broker
- 消息
- 生产者
- 消费者
- Topic
- Partition与Cluster
- Partition 副本 Replica机制
- Segment
- Consumer Group
- Consumer Offset
- kafka开发
-
- kafka+canal
- 消息的幂等性
- kafka生产者事务
- kafka与RabbitMq对比
Kafka
第一个问题,kafka是消息队列吗?它是如何诞生的?
LinkedIn,作为一家社交企业,18年用户超过5.6亿,每天要收集很多实时生成的数据,比如用户活跃度、用户页面访问情况、用户搜索内容,这些数据被很多系统用到。
最开始这些数据的传输都是点对点传输,但是随着应用程序的增多,指标细分,数据量不断增长,这种方式的效率也越来越差。(2019年10月,每天处理的消息是7万亿)
所以,LinkedIn设计了一个集中式的数据通道,大家统一通过这个数据通道来交互数据。
最开始这个数据通道用ActiveMq来实现,但是经常发现消息阻塞和服务不可用的情况。(开始想是何必重复发明轮子,后来发现这个轮子是个方的)。所以LinkedIn自己开发了一个数据引擎,就是Kafka。
从这个故事看来,Kafka解决的是生产环境中数据上下游的耦合问题,所以很多时候不仅仅把它叫做消息中间件,也称为消息引擎,或者分布式实时流处理平台。
Kafka使用场景
首先,当然作为普通的消息队列应用。
消息传递 Messaging
消息传递就是发送数据,作为Tcp Http或者Rpc的替代方案,可以实现异步解耦削峰(RabbitMq能做的它也能做)。因为Kafka的吞吐量更高,在大规模消息系统更有优势。
website Activity tracking 网站活动跟踪
把用户活动发布到数据管道中,可以用来做监控、实时处理、报表等等。比如社交网站的行为跟踪,网购的行为跟踪,这样可以实现更加精确的内容推荐。
举例:外卖、物流、店里系统的实时信息。
Log Aggregation 日志聚合
又比如kafka来实现日志聚合。这样就不用把日志记录到本地磁盘或者数据库。
实现分布式的日志聚合。
应用指标监控
还可以用来记录运营监控数据。或者运维数据监控,cpu、内存、磁盘、网络连接的使用情况,可以实现告警。
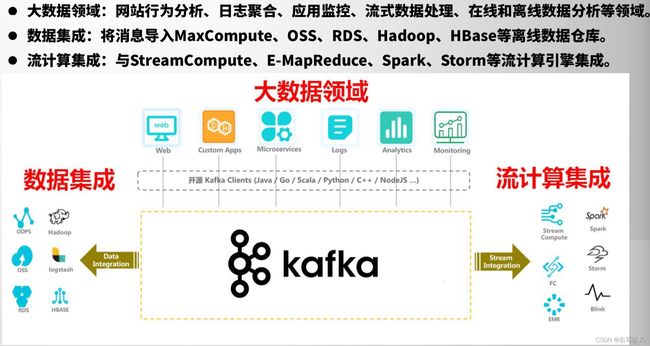
数据集成+流式计算
数据集成指的是把kafka把数据导入Hadoop、HBASE等离线数据仓库,实现数据分析。
流计算。什么是流?它不是静态数据,而是没有边界、源源不断的产生数据,像水流一样。流计算指的是Stream做实时计算。
Kafka内置了流处理框架API----Kafka Streams。
所以,它跟RabbitMq的定位差别比较大,不仅仅是一个简单地消息中间件,而且是一个流处理平台。
在kafka里面,消息被称为日志。日志就是消息的数据文件。
Kafka的安装
kafka的安装依赖zookeeper。生产环境通常是一个ZK集群。而且Kafka还自带了一个ZK服务。不过生产还是要用外部zookeeper集群。
总结起来:利用zookeeper的有序节点、临时节点和监听机制,ZK帮kafka做了这些事情:
配置中心、负载均衡、命名服务、分布式通知、集群管理和选举、分布式锁。
Kafka架构分析
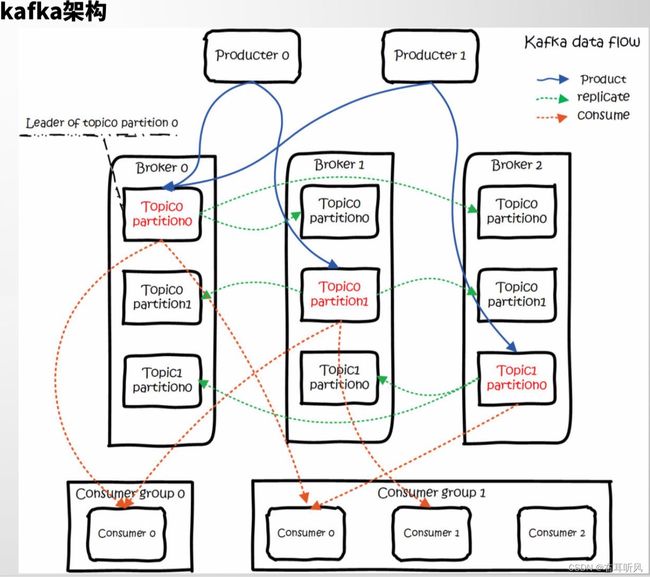
Broker
Broker:kafka作为一个中间件,是帮我们存储和转发消息的,他做的事情有点像中介,所以我们把kafka的服务叫做Broker。
默认端口是:9092。生产者和消费者都需要跟这个Broker建立一个连接,才可以实现消息的收发。
消息
客户端之间传输的数据叫做消息,或者叫记录(Record)。
在客户端代码中,Record可以使一个KV键值对。
生产者对应的封装类是ProducerRecord,消费者对应的是ConsumerRecord。
消息在传输的过程中需要序列化,所以代码里面要制定序列化工具。
生产者
为提升消息发送效率,生产者不是逐条发送消息给Broker,而是批量发送的。
多少条发一次由一个参数决定。
pros.put(“batch.size”,16384)
不是说非要达到16384条才发送,还有一个时间参数限制。
props.put(“linger.ms”,5);
超过5毫秒,即使不到16384也会被发送。
消费者
一般来说消费者有2种模式,一种是pull模式,一种是push模式。
pull模式是消息堆放在Broker,消费者自己决定什么时候拉取。
push模式,只要消息到达Broker,都直接推给消费者。
RabbitMq Consumer支持push也支持pull,一般用push。
Kafka只有pull模式。
为什么kafka消费者用pull模式?
在push模式下,如果生产消息的速度远远大于消费者消费的速度,那么消费者就会不堪负重,(已经吃不下,硬往你嘴里赛),直到挂掉。
而且消费者可以自己控制一次到底获取多少条消息。
max.poll.records
默认500。在poll方法里面可以指定。
Topic
生产者跟消费者是怎么关联起来的?或者说生产者发送消息,怎么才能到达某个特定消费者?
他们要通过队列关联起来,也就是说,生产者发送消息,要指定发到哪个队列。消费者接受消息,要指定从哪个队列接收。
在kafka里面,这个队列叫Topic,是一个逻辑概念。可以理解成一组消息的集合。
生产者和topic,以及topic和消费者关系都是多对多。一个生产者可以发送消息到多个topic,一个消费者也可以从多个topic获取消息。(但是不建议这么做)
注意:生产者发送消息,如果topic不存在,会自动创建。由一个参数控制
auto.create.topics.enable
默认是true。如果要彻底删除topic,这个参数必须设置false,否则只要有代码使用这个topic,它就会自动创建。
Partition与Cluster
如果说一个topic中消息太多,会带来2个问题:
1)第一不方便横向扩展,比如我要把数据分布在不同的机器上实现扩展。
2)第二是并发或者负载的问题,所有客户端操作都是同一个topic,在高并发场景下性能会大大下降。
怎么解决这个问题?
我们想到就是把一个topic进行拆分(分片的思想)。
kafka引入一个分区(Partition)的概念。一个topic可以划分成多个区。
分区在创建topic的时候,每个topic至少有一个分区。
创建topic命令:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic myTopicName
如果没有指定分区数,默认分区数是一个,这个参数可以修改:
num.partitions=1
partitions是分区数,replication-factor是主体的副本数。
partitions思想类似分库分表,实现横向扩展和负载的目的。
跟RabbitMq不一样的地方,partition里面的消息被读取后不会被删除,所以同一批消息在一个Partition里面顺序、追加写入的。 这个也是kafka吞吐量大的一个原因。
Partition 副本 Replica机制
如果Partition数据只存储一份,发生网络或硬件故障时,该分区的数据就无法被访问或者无法恢复。
每个partition可以有若干副本(replica),副本必须在不同的Broker上面。一般来说我们说的副本包括我们的主节点。
由replication-factor 指定一个topic的副本数。
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic myTopicName
举例:部署3个Broker,该topic有3个分区,每个分区一共3个副本
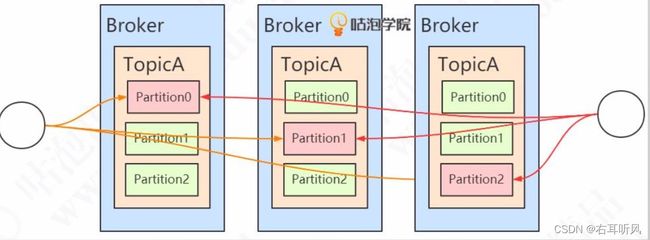
注意:这些存放数据的partition副本有leader(红色)和follower(绿色)
的概念。leader在哪个机器不一定,选举出来的。
生产者发消息和消费者读消息都是针对leader来操作的。
follower的数据是从leader同步过来的。
Segment
kafka数据是存放在后缀.log的文件里面的。如果一个partition只有1个log文件,消息不断的追加,这个log文件会变得越来越大,这个时候检索效率就会降低。
所以干脆把partition做了一个切分,切分出来的单位叫段(Segment)。实际上kafka的存储文件是划分成段来存储的。
默认存储路径:/tmp/kafka-logs/
每个segment有1个数据文件和2个索引文件。

segment多大一个?默认大小是10737411824 bytes (1G)
由这个参数控制:
log.segment.bytes
Consumer Group
如果生产者发送消息的速度过快,会造成消息在Broker的堆积。
怎么提升消费的速度呢?增加消费者的数量。但是这么多消费者,怎么知道大家是不是消费的是同一个topic呢?
所以引入了 Consumer Group消费组的概念,在代码中通过group id来配置。消费同一个topic的消费者不一定是同一个组,只有group id相同的消费者才是同一个消费组。
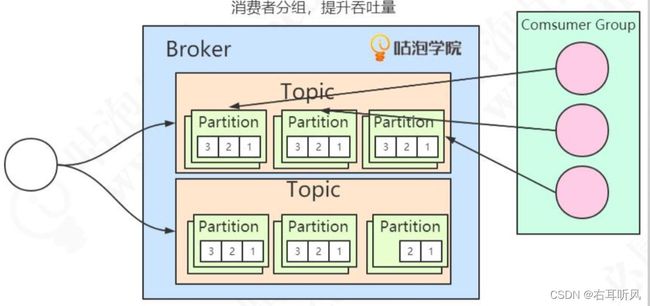
注意:同一个group中的消费者,不能消费相同的partition。partition要在消费者之间分配。
1、如果消费者比partition少,一个消费者可能消费多个partition。
2、如果消费者比partition多,肯定有消费者没哟partition可以消费者。
(学生多了,桌子不够,会有人站着上课)不会出现一个group里面的消费者消费同一个partition。
3、如果想要同时消费同一个partition的消息,那么需要其他组来消费。
Consumer Offset
我们前面说过,partition里面的消息是顺序写入的,被读取之后不会被删除。
因为消息是有序的,我们可以对消息进行编号,用来标识一条唯一的消息。
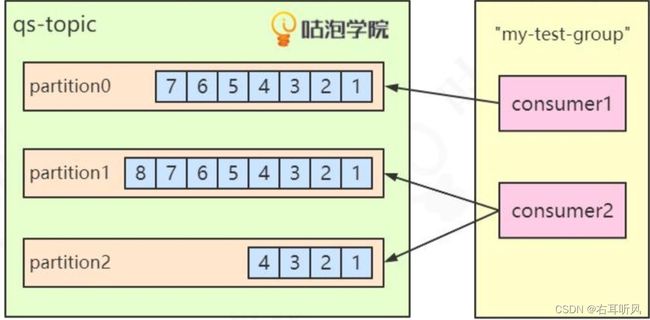
这个编号我们叫做offset,偏移量。
offset记录着下一条将要发送给consumer的消息的序号。
这个消费者和partition的偏移量没有保存在zk,而是直接保存在服务端。
kafka开发
我们有一个需求,需要商品数据同时保存在Mysql和Es,当商品数据有变动的时候,比如增删改,必须要两边保持一致。怎么做呢?
直接改代码?就是操作mysql的地方,都同时操作ES。有点麻烦了。
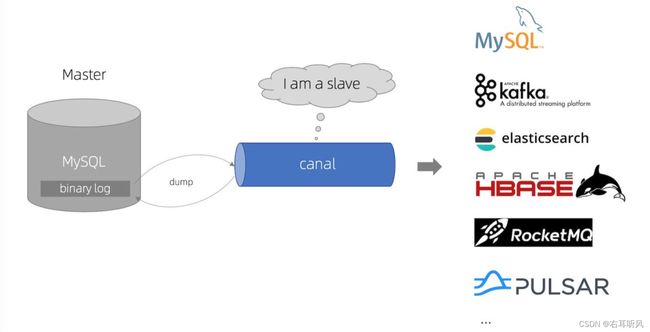
mysql底层有一个binlog,会记录数据的增删改,阿里开源工具canal可以帮我们实现。
kafka+canal
binlog有个重要的功能就是主从同步。
canal利用这一点,把自己伪装成一个slave节点,不断请求最新的binlog。
canal会解析binlog内容,把它发送给关注数据变动的接受者,完成业务逻辑处理。
消息的幂等性
在RabbitMq里面,如果消费失败了,消息需要重发。但是在不清楚消费者是不是真的消费失败的情况下,有可能会出现消息重复的情况。
消息重复消费要在消费端解决,也就是在消费者实现幂等性。
kafka干脆直接在Broker实现了消息的重复性判断。
去重重要依赖于生产者的消息的唯一标识,不然没法知道是不是同一条消息。那么这个标识怎么产生的?
props.put(“enable.idempotence”,true)
enable.idempotence设置成true后,Producer自动升级幂等性Producer,kafka会自动去重。到底要怎么实现呢?
1、PID(producer id),幂等性的生产者每个客户端都有一个唯一编号。
2、sequence number,幂等性的生产者发送的每条消息都会带相应的sequence number,Server端就是根据这个值来判断数据是否重复。
如果说发现sequence number 比服务端记录的值小,那肯定是重复消费了。
sequence number并不是全局有序的,不能保证所有时间上的幂等性。
所以,它的作用范围是有限的:
1、只能保证单分区的幂等性,即一个幂等性Producer能够保证某个主体的一个分区上不出现重复消息。
2、只能实现单会话的幂等性,这里的会话指的是Producer进程的一次运行。当重启Producer进程之后,幂等性不保证。
如果实现多个分区的消息的原子性,就要用到kafka的事务了
kafka生产者事务
kafka的分布式事务怎么实现的?这里不分析具体流程
其中有几个关键点:
1)生产者的消息可能库分区,所以这里的事务属于分布式事务。分布式事务有很多,kafka选择了常见的两阶段提交(2PC)。如果大家都可以commit,那么就commit,否则abort。
kafka与RabbitMq对比
因为kafka是解决数据流传输问题的,所以有这些特性
1、高吞吐、低延迟:kafka最大的特点就是收发消息非常快,kafka每秒可以处理几十万条消息,它的最低延迟只有几毫秒。
2、高伸缩性:可以通过增加partition来扩容
3、持久性、可靠性:kafka能够允许数据持久化存储。
4、高并发:支持说签个客户端同时读写。
5、容错性:允许集群节点宕机,kafka能够继续工作。
与RabbitMQ对比:
1、产品上,kafka侧重:流式消息处理;RabbitMq侧重于:消息代理
2、性能:kafka有更高的吞吐。RabbitMq主要是push,kafka只有pull
3、消息顺序:kafka分区里面的消息是有序的。
4、消息的路由和分发:RabbitMq更加灵活
5、RabbitMq支持延迟消息和死信队列。
6、消息的留存:kafka消费完后消息会保存,RabbitMq消费完会删除。
kafka也可以设置retention清理消息。