MySQL分库分表原理
MySQL分库分表原理
- 前言
-
- 数据库为什么要分库分表
- 影响数据库性能的三个要素
-
- 数据量
- 磁盘
- 数据库连接
- 1、分库分表的原理和实现
-
- 1.1 什么是分区、分表、分库
-
- 分区
- 分表
- 分库
- 1.2 什么时候考虑使用分区?
-
- 分区解决的问题
- 分区的实现方式(简单),例如:
- 1.3 分库分表概述
- 1.4 适用场景
- 1.5 业务分库(又叫mysql垂直拆分)
- 1.6 业务分表(又叫水平拆分)
-
- 1.6.1 业务分表带来的问题:
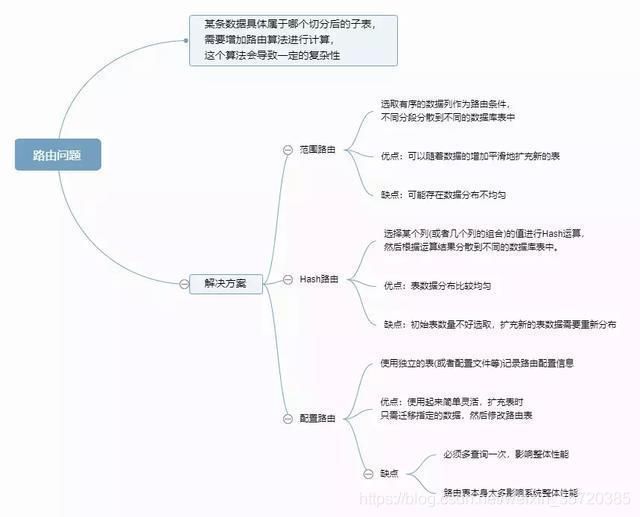
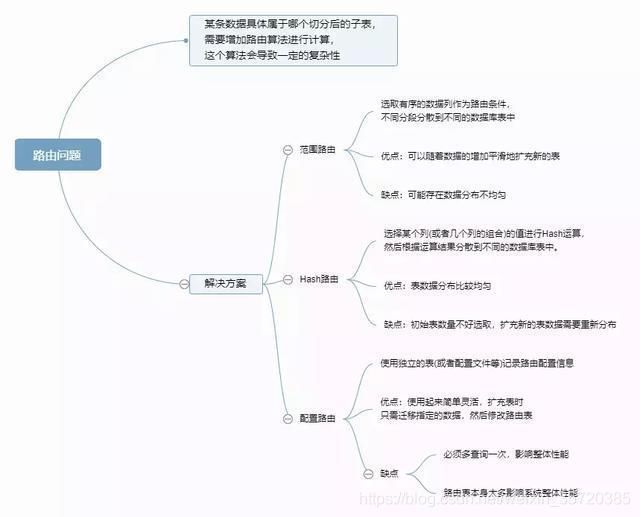
- 1.6.2 路由问题
- 1.6.2 数据库操作问题
- 1.6.3 数据库分库分表的实现方法
- 2 读写分离的原理和实现
-
- 2.1、什么是读写分离
- 2.2、为什么要读写分离呢?
- 2.3、什么时候要读写分离?
- 2.4 主从复制、读写分离的基本设计
- 3 分库分表、读写分离总结:
-
- 1.分区
- 2.分表
- 3.分库
- 4.读写分离方案
前言
数据库为什么要分库分表
mysql推荐的是单表百万级存储,当单表的数据量达到1000W或100G以后,由于查询维度较多,即使添加从库、优化索引,做很多操作时性能仍下降严重。
例如淘宝网,海量的数据存储和访问成为系统设计的瓶颈问题,日益增长的业务数据,对数据库造成了恒大的负载。同时对于系统的稳定性和扩展性提出了很高的要求。
随着时间和业务的发展,数据库中的表会越来越多,表中的数据量也会越来越大,单台服务器的资源(CPU、磁盘IO、内存、网络IO、事务数、连接数)总是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
分表、分库和读写分离可以有效地减小单台数据库的压力。
影响数据库性能的三个要素
数据量
MySQL单库数据量在5000万以内性能比较好,超过阈值后性能会随着数据量的增大而变弱。
MySQL单表的数据量是500w-1000w之间性能比较好,超过1000w性能也会下降。
解决途径:分库分表–水平拆分
磁盘
因为单个服务的磁盘空间是有限制的,如果并发压力下,所有的请求都访问同一个节点,肯定会对磁盘IO造成非常大的影响。
解决途径:读写分离(主从复制)
数据库连接
数据库连接是非常稀少的资源,如果一个库里既有用户、商品、订单相关的数据,当海量用户同时操作时,数据库连接就很可能成为瓶颈。
解决途径:分库分表–垂直拆分
1、分库分表的原理和实现
1.1 什么是分区、分表、分库
分区
就是把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的,分区实现比较简单,数据库mysql、oracle等很容易就可支持。
分表
就是把一张表按一定的规则分解成N个具有独立存储空间的实体表。系统读写时需要根据定义好的规则得到对应的字表明,然后操作它。
分库
一旦分表,一个库中的表会越来越多
1.2 什么时候考虑使用分区?
一张表的查询速度已经慢到影响使用的时候。
sql经过优化
数据量大
表中的数据是分段的
对数据的操作往往只涉及一部分数据,而不是所有的数据
分区解决的问题
主要可以提升查询效率
分区的实现方式(简单),例如:
mysql5 开始支持分区功能
CREATE TABLE sales (
id INT AUTO_INCREMENT,
amount DOUBLE NOT NULL,
order_day DATETIME NOT NULL,
PRIMARY KEY(id, order_day)
) ENGINE=Innodb
PARTITION BY RANGE(YEAR(order_day)) (
PARTITION p_2010 VALUES LESS THAN (2010),
PARTITION p_2011 VALUES LESS THAN (2011),
PARTITION p_2012 VALUES LESS THAN (2012),
PARTITION p_catchall VALUES LESS THAN MAXVALUE);
1.3 分库分表概述
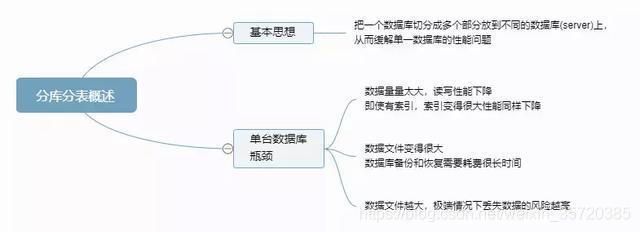
读写分离分散数据库读写操作压力,分库分表分散存储压力,以及数据库连接压力
1.4 适用场景
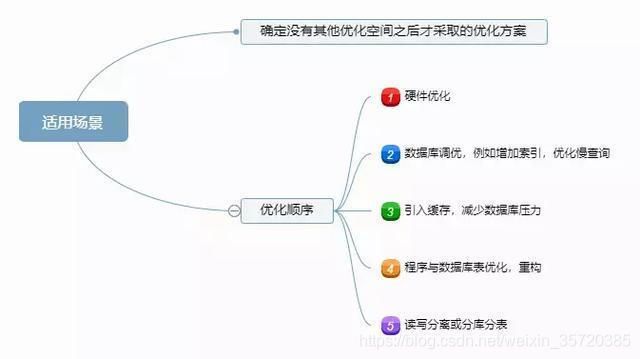
类似读写分离,分库分表也是确定没有其他优化空间之后才采取的优化方案。那如果业务真的发展很快岂不是很快要进行分库分表了?
那为何不一开始就设计好呢?
按照架构设计的“三原则”(简单原则,合适原则,演化原则),简单分析一下:
首先,这里的“如果”事实上发生的概率比较低,做10个业务有一个业务能活下去就很不错了,更何况快速发展,和中彩票的概率差不多。
如果我们每个业务上来就按照淘宝、微信的规模去做架构设计,不但会累死自己,还会害死业务。
其次,如果业务真的发展很快,后面进行分库分表也不迟。因为业务发展好,相应的资源投入就会加大,可以投入更多的人和更多的钱,那业务分库带来的代码和业务复杂问题就可以通过加人来解决,成本问题也可以通过增加资金来解决。
什么情况下要开始准备分库分表呢?
例如,你的交易业务表以及有1000W的数据了,而且数据的增长速度,按照每个月50W条的数据增长,那么就要和DBA商议准备做数据迁移和分库分表的打算了。以为一年后将会有1600W条数据,所以必须要分库分表了。
1.5 业务分库(又叫mysql垂直拆分)
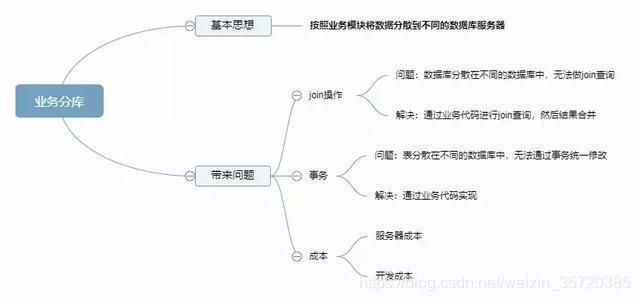
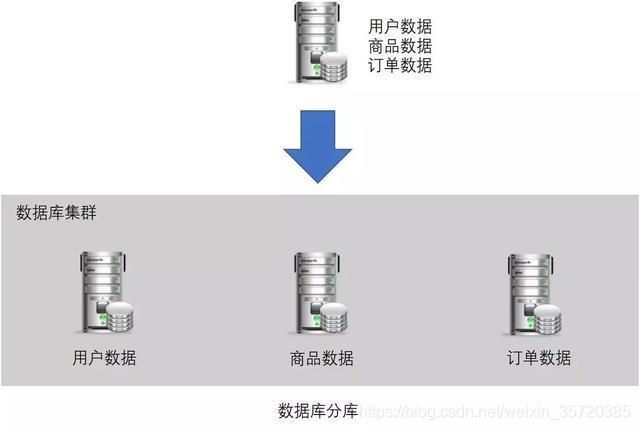
1.6 业务分表(又叫水平拆分)
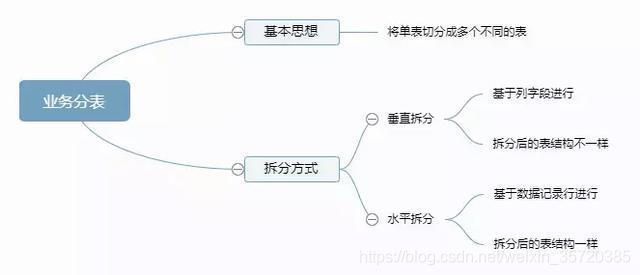

1.6.1 业务分表带来的问题:
垂直分表–>增加表操作的次数、
水平分表–>路由问题
1.6.2 路由问题
1.6.2 数据库操作问题
1.6.3 数据库分库分表的实现方法
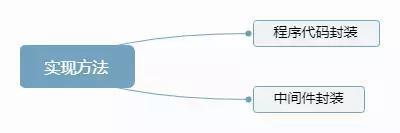
类似读写分离,具体实现也是“程序代码封装”和“中间件封装”,但具体实现复杂一些,因为还有要判断SQL中具体操作的表,具体操作(例如count、order by、group by等),根据具体操作做不同的处理。
2 读写分离的原理和实现
2.1、什么是读写分离
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
2.2、为什么要读写分离呢?
因为数据库的“写”(写10000条数据到oracle可能要3分钟)操作是比较耗时的。
但是数据库的“读”(从oracle读10000条数据可能只要5秒钟)。
所以读写分离,解决的是,数据库的写入,影响了查询的效率。
2.3、什么时候要读写分离?
数据库不一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用,利用数据库 主从同步 。可以减少数据库压力,提高性能。当然,数据库也有其它优化方案。memcache 或是 表折分,或是搜索引擎。都是解决方法。
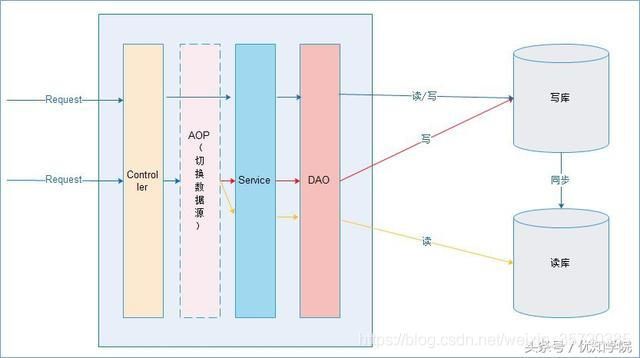
2.4 主从复制、读写分离的基本设计
在实际的生产环境中,对数据库的读和写都在同一个数据库服务器中,是不能满足实际需求的。无论是在安全性、高可用性还是高并发等各个方面都是完全不能满足实际需求的。
因此,通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力。
一台主、多台从,主提供写操作,从提供读操作。
读写分离的实现:
我们只需要实现读写分离,主从复制数据一般由数据库级来实现同步,当然也可以自己去实现同步,只是需要考虑的点比较多。
3 分库分表、读写分离总结:
1.分区
对业务透明,分区只不过把存放数据的文件分成了许多小块,根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后的表呢,还是一张表。
2.分表
当数据量大到一定程度的时候,都会导致处理性能的不足,这个时候就没有办法了,只能进行分表处理。也就是把数据库当中数据根据按照分库原则分到多个数据表当中,这样,就可以把大表变成多个小表,不同的分表中数据不重复,从而提高处理效率。
3.分库
分表和分区都是基于同一个数据库里的数据分离技巧,对数据库性能有一定提升,但是随着业务数据量的增加,原来所有的数据都是在一个数据库上的,网络IO及文件IO都集中在一个数据库上的,因此CPU、内存、磁盘IO、网络IO都可能会成为系统瓶颈。
当业务系统的数据容量接近或超过单台服务器的容量、QPS/TPS接近或超过单个数据库实例的处理极限等此时,往往是采用垂直和水平结合的数据拆分方法,把数据服务和数据存储分布到多台数据库服务器上。
4.读写分离方案
当数据库读远大于写,查询多的情况,就可以考虑主数据负责写操作,从数据库负责读操作,一主多重,从而把数据读写分离,最后还可以结合redis等缓存来配合分担数据的读操作,大大的降低后端数据库的压力。