【玩转Scikit-learn】机器学习工程师的浅入深出保姆级学习成长指南+变强规划+入门教程~
作者简介:大家好,我是车神哥,府学路18号的车神
⚡About—>车神:从寝室到实验室最快3分钟,最慢3分半(那半分钟其实是等红绿灯)
个人主页:车手只需要车和手,压力来自论文_府学路18号车神_CSDN博客
官方认证:人工智能领域优质创作者
点赞➕评论➕收藏 == 养成习惯(一键三连)⚡希望大家多多支持~一起加油
专栏
《玩转Scikit-learn》
学习成长指南
- 写在前面
- 学习指南
- 变强规划
- 入门scikit-learn
-
- scikit-learn安装
- scikit-learn优点
- 拟合与预测:估计器基础(Fitting and predicting: estimator basics)
- 转换器和预处理(Transformers and pre-processors)
- 数据集加载工具
-
- Iris数据集示例
- 三种方式生成数据
- 数据集使用方法汇总(以波士顿房价数据集为例)
- 预处理器和估计器(Pipelines: chaining pre-processors and estimators)
- 模型评估
- 自动参数搜索
- Next Step!
写在前面
- 为什么会想写这个系列呢?
首先,是在基础应用、数据分析、预测数据等上,scikit-learn算是比较简单和高效的一个科学工具库了。其次,科学库是开源的,相当的友好,我相信未来一定是属于开放、自由、共享的,同时也是不忘这个初心吧。 - 想要写什么内容?
主要还是以核心算法,各种基础为切入点,以最简单明了的方法去总结、分享和解读一些相关的知识原理。同时,辅以Scikit-learn库进行应用与实战解读。 - 主要用到什么工具呢?
工具就PyCharm或者VScode,亦或者你熟悉的编辑器即可。 - 需要哪些基础呢?
需要有一定的编程基础,对Python熟悉,具备一定的数学功底,线性代数、高等数学、矩阵理论、最优化理论和方法等知识功底。
Scikit-learn是一个支持有监督和无监督学习的开源机器学习库。它还提供用于模型拟合、数据预处理、模型选择、模型评估和许多其他实用程序的各种工具。
学习指南
主要就按照scikit-learn的库包含的大部分内容进行讲解,六大块:分类(Classification)、回归(Regression)、聚类(Clustering)、降维(Dimensionality reduction)、模型选择(Model selection)和预处理(Preprocessing)。
变强规划
每天完成一个小节的学习,博主也每天坚持更新一章(节假日或特殊情况除外),多练习多结合实际,公开数据集很多,可以尝试很多公开数据集,后面更新一期公开数据集的合集吧,用于做测试和训练。
说是变强规划,其实要变强,终究还是得靠——勤,多练习多思考,才会变强!
“变强没有捷径!” —— 府学路18号车神
入门scikit-learn

官方规划图:
https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html

scikit-learn安装
有多种安装 scikit-learn 的方法(官方安装方法):
- 安装最新的官方版本。对于大多数用户来说,这是最好的方法。它将提供一个稳定的版本,并且预构建的包可用于大多数平台。
- 安装 操作系统或 Python 发行版提供的 scikit-learn 版本。对于那些拥有分发 scikit-learn 的操作系统或 Python 发行版的人来说,这是一个快速的选择。它可能不提供最新的发布版本。
- 从源代码构建包。这对于想要最新最好的功能并且不怕运行全新代码的用户来说是最好的。希望为项目做出贡献的用户也需要这样做。
上面的方法都太繁琐,反手就是一个否定。
建议直接在你最熟悉的编辑器,如PyCharm、VScode等的终端命令行,直接pip安装,高效又方便:
pip install - U scikit-learn
对于不同系统的安装方法类似,具体可参考官网上的安装教程。
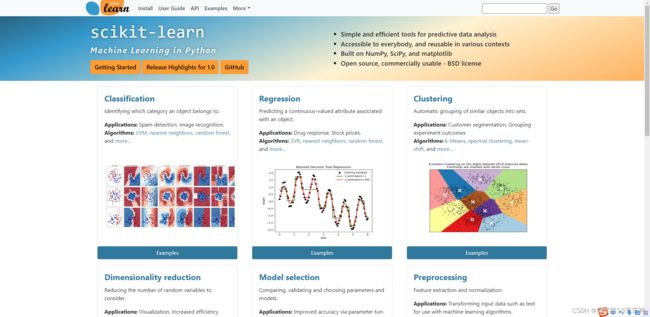
scikit-learn优点
- 用于预测数据分析的简单高效工具
- 每个人都可以访问,并且可以在各种情况下重复使用
- 基于 NumPy、SciPy 和 matplotlib 构建
- 开源,商业可用 - BSD 许可证
最重要的是开源!!!
拟合与预测:估计器基础(Fitting and predicting: estimator basics)
Scikit-learn是一个支持有监督和无监督学习的开源机器学习库。它还提供用于模型拟合、数据预处理、模型选择、模型评估和许多其他实用程序的各种工具。
Scikit-learn提供了数十种内置的机器学习算法和模型,称为估计器。每个估计器都可以使用其拟合方法拟合某些数据。
下面以一个示例展开,这是一个简单的示例,我们将 a 拟合 RandomForestClassifier到一些非常基本的数据:
>>> from sklearn.ensemble import RandomForestClassifier # 导入科学库随机森林
>>> clf = RandomForestClassifier(random_state=0)
>>> X = [[ 1, 2, 3], # 2 samples, 3 features
... [11, 12, 13]]
>>> y = [0, 1] # classes of each sample
>>> clf.fit(X, y)
>
RandomForestClassifier(random_state=0)
fit方法(拟合)通常接受 2 个输入:
- 样本矩阵(或设计矩阵)X。的大小X 通常为,这意味着样本表示为行,特征表示为列。(n_samples, n_features)
- 目标值y是回归任务的实数,或分类的整数(或任何其他离散值集)。对于无监督学习任务,y不需要指定。y通常是一维数组,其中第ith 条目对应于 的 i第 th 样本(行)的目标X。
其中,两者X和y通常都应该是 numpy 数组或等效 的类似数组的数据类型,尽管一些估计器可以使用其他格式,例如稀疏矩阵。
一旦拟合了估计器,它就可以用于预测新数据的目标值。您无需重新训练估算器:
# 预测训练数据的类别
clf.predict(X) # array([0, 1]),结果是两类
# 下面是预测新的数据
clf.predict(([4,5,6], [13,14,15])) # 结果为:array([0, 1]),同样也是两类
转换器和预处理(Transformers and pre-processors)
机器学习工作流程通常由不同的部分组成。一个典型的管道包括一个转换或估算数据的预处理步骤,以及一个预测目标值的最终预测器。
在scikit-learn中,预处理器和转换器遵循与估计器对象相同的 API(它们实际上都继承自同一个 BaseEstimator类)。转换器对象没有预测方法,而是输出新转换的样本矩阵的转换X方法:
- 首先导入库:
from sklearn.preprocessing import StandardScaler
- 输入数据集
X = [[0, 15], [1, -10]]
- 根据计算的缩放值缩放数据
StandardScaler().fit(X).transform(X)
"""
结果为:
array([[-1., 1.],
[ 1., -1.]])
"""
数据集加载工具
scikit-learn提供了很多很多的开源数据集,可以供所有人使用。
https://scikit-learn.org/stable/datasets.html#datasets
该软件包还具有帮助程序来获取机器学习社区常用的更大数据集,以对来自“现实世界”的数据的算法进行基准测试。
n_samples为了评估数据集 (和 )规模的影响,n_features同时控制数据的统计属性(通常是特征的相关性和信息量),还可以生成合成数据。
主要有以下几类:
- 通用数据集 API——根据所需的数据集类型,可以使用三种主要类型的数据集接口来获取数据集。
- 数据集加载器——它们可用于加载小型标准数据集,如玩具数据集部分所述。
- 数据集提取器——它们可用于下载和加载更大的数据集,如真实世界数据集部分所述。
loader 和 fetchers 函数都返回一个Bunch 包含至少两个项目的对象:一个带有 key的 shape n_samples*数组(20newsgroups 除外)和一个 length 的 numpy 数组,包含目标值,带有 key 。n_featuresdatan_samplestarget
Bunch 对象是一个将其键作为属性公开的字典。有关 Bunch 对象的更多信息,请参阅Bunch。
通过将 return_X_y参数设置为 ,几乎所有这些函数都可以将输出限制为仅包含数据和目标的元组True。
DESCR数据集的属性中还包含完整的描述,有些包含feature_names和target_names。有关详细信息,请参阅下面的数据集描述。
- 数据集生成函数——它们可用于生成受控合成数据集,如生成的数据集部分所述。
这些函数返回一个由* numpy 数组和 包含目标的长度数组组成的元组。(X, y)n_samplesn_featuresXn_samplesy
此外,还有其他工具可以加载其他格式的数据集或从其他位置加载,如加载其他数据集 部分所述。
sklearn内置了一些优秀的数据集,比如:Iris数据、房价数据、泰坦尼克数据等。
Iris数据集示例
例举一个鸢尾花数据集的范例,下面是导入数据集:
著名的 Iris 数据库,最初由 RA Fisher 爵士使用。数据集取自 Fisher 的论文。请注意,它与 R 中的相同,但与 UCI 机器学习存储库中的不同,后者有两个错误的数据点。
这可能是模式识别文献中最著名的数据库。Fisher 的论文是该领域的经典之作,至今仍被频繁引用。(例如,参见 Duda & Hart。)数据集包含 3 个类别,每个类别 50 个实例,其中每个类别指的是一种鸢尾植物。一类与另一类线性可分;后者不能彼此线性分离。
import pandas as pd
import numpy as np
import sklearn
from sklearn import datasets # 导入数据集
- 鸢尾花数据集Iris
# iris数据
iris = datasets.load_iris()
type(iris)
sklearn.utils.Bunch
下面看一下Iris数据集到底长什么样子。


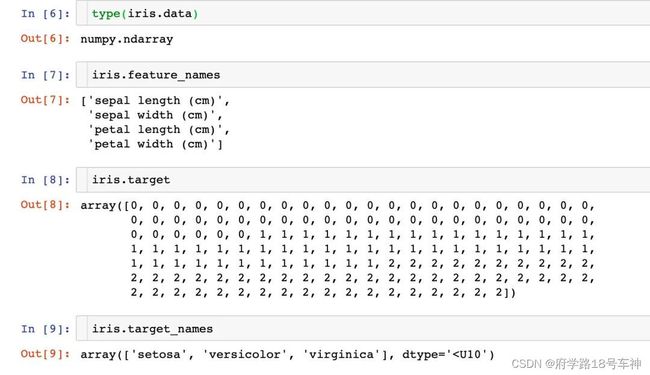
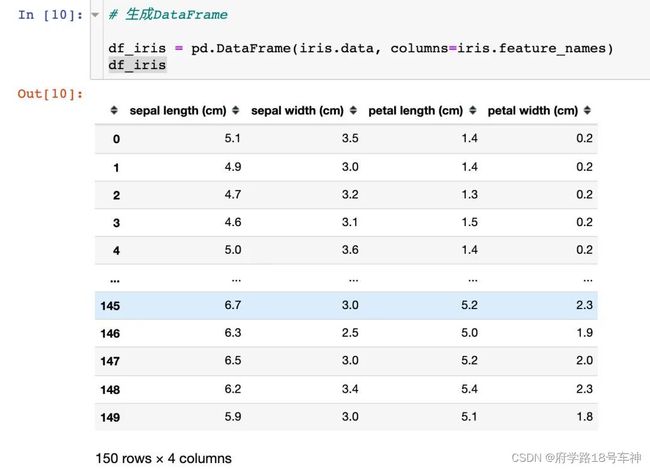
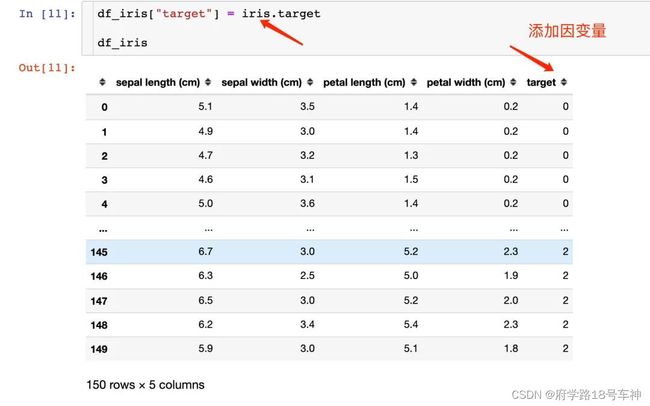
注意,可以将上面的数据生成我们想看到的DataFrame,还可以添加因变量:
其余的数据集也类似,值得关注的有以下几个属性(你需要记住的):
- data
- target、target_names
- feature_names
- filename
三种方式生成数据
- 方法一
# 导入库
from sklearn import datasets
loaded_data = datasets.load_iris() # 导入数据集的属性
#导入样本数据
data_X = loaded_data.data
# 导入标签
data_y = loaded_data.target
- 方法二
# 导入库
from sklearn.datasets import load_iris
# 直接返回
data_X, data_y = load_iris(return_X_y=True)
- 方法三
# 导入库
from sklearn.datasets import load_iris
data = load_iris()
#导入数据和标签
data_X = data.data
data_y = data.target
总而言之,道理都一样。
数据集使用方法汇总(以波士顿房价数据集为例)
from sklearn import datasets # 导入库
boston = datasets.load_boston() # 导入波士顿房价数据
print(boston.keys()) # 查看键(属性) ['data','target','feature_names','DESCR', 'filename']
print(boston.data.shape,boston.target.shape) # 查看数据的形状
print(boston.feature_names) # 查看有哪些特征
print(boston.DESCR) # described 数据集描述信息
print(boston.filename) # 文件路径
预处理器和估计器(Pipelines: chaining pre-processors and estimators)
变换器和估计器(预测器)可以组合在一起成为一个统一的对象:a Pipeline. fit该管道提供与常规估计器相同的 API:它可以通过和拟合并用于预测predict。正如我们稍后将看到的,使用管道还可以防止数据泄漏,即在训练数据中泄露一些测试数据。
在以下示例中,我们加载 Iris 数据集,将其拆分为训练集和测试集,并计算管道在测试数据上的准确度得分:
- 导入库
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
- 创建pipeline
pipe = make_pipeline(
StandardScaler(),
LogisticRegression()
)
- 加载iris数据集,并将其拆分为训练集和测试集
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
- 拟合
pipe.fit(X_train, y_train)
- 可使用估计器做预测、分类等
accuracy_score(pipe.predict(X_test), y_test)
代码汇总:
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# create a pipeline object
pipe = make_pipeline(
StandardScaler(),
LogisticRegression()
)
# load the iris dataset and split it into train and test sets
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# fit the whole pipeline
pipe.fit(X_train, y_train)
# we can now use it like any other estimator
accuracy_score(pipe.predict(X_test), y_test)
模型评估
将模型拟合到某些数据并不意味着它可以很好地预测看不见的数据。这需要直接评估。我们刚刚看到了 train_test_split将数据集拆分为训练集和测试集的助手,但scikit-learn它提供了许多其他工具用于模型评估,特别是用于交叉验证。
关于交叉验证:学习预测函数的参数并在相同的数据上对其进行测试是一个方法论错误:一个模型只会重复它刚刚看到的样本的标签,它会获得完美的分数,但无法预测任何有用的东西——看不见的数据。这种情况称为过拟合。为了避免这种情况,在执行(监督)机器学习实验时,通常的做法是保留部分可用数据作为测试集 。请注意,“实验”一词并非仅表示学术用途,因为即使在商业环境中,机器学习通常也是从实验开始的。这是模型训练中典型的交叉验证工作流程的流程图。

我们在这里简要展示如何使用帮助程序执行 5 折交叉验证过程cross_validate。请注意,也可以手动迭代折叠,使用不同的数据拆分策略,以及使用自定义评分函数。
- 导入库
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_validate
- 线性回归
X, y = make_regression(n_samples=1000, random_state=0)
lr = LinearRegression()
- 交叉验证
result = cross_validate(lr, X, y) # defaults to 5-fold CV
result['test_score'] # r_squared score is high because dataset is easy
代码汇总:
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_validate
X, y = make_regression(n_samples=1000, random_state=0)
lr = LinearRegression()
result = cross_validate(lr, X, y) # defaults to 5-fold CV
result['test_score'] # r_squared score is high because dataset is easy
自动参数搜索
所有估计器都有可以调整的参数(在文献中通常称为超参数)。估计器的泛化能力通常主要取决于几个参数。例如 a RandomForestRegressor有一个n_estimators 参数决定了森林中的树的数量,还有一个 max_depth参数决定了每棵树的最大深度。很多时候,不清楚这些参数的确切值应该是多少,因为它们取决于手头的数据。
Scikit-learn提供自动查找最佳参数组合的工具(通过交叉验证)。在下面的示例中,我们随机搜索带有 RandomizedSearchCV对象的随机森林的参数空间。当搜索结束时,它的RandomizedSearchCV行为就像RandomForestRegressor已经安装了最好的参数集。
- 导入库
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import train_test_split
from scipy.stats import randint
- 获取数据集
X, y = fetch_california_housing(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
- 定义将要搜索的参数空间
# define the parameter space that will be searched over
param_distributions = {'n_estimators': randint(1, 5),
'max_depth': randint(5, 10)}
- 现在创建一个searchCV对象,并使其拟合数据
search = RandomizedSearchCV(estimator=RandomForestRegressor(random_state=0),
n_iter=5,
param_distributions=param_distributions,
random_state=0)
search.fit(X_train, y_train)
- 搜索对象现在就像一个普通的随机森林估计器
search.best_params_
# the search object now acts like a normal random forest estimator
# with max_depth=9 and n_estimators=4
search.score(X_test, y_test)
代码汇总:
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import train_test_split
from scipy.stats import randint
X, y = fetch_california_housing(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# define the parameter space that will be searched over
param_distributions = {'n_estimators': randint(1, 5),
'max_depth': randint(5, 10)}
# now create a searchCV object and fit it to the data
search = RandomizedSearchCV(estimator=RandomForestRegressor(random_state=0),
n_iter=5,
param_distributions=param_distributions,
random_state=0)
search.fit(X_train, y_train)
search.best_params_
# the search object now acts like a normal random forest estimator
# with max_depth=9 and n_estimators=4
search.score(X_test, y_test)
Next Step!
好了,入门就到此为止,后续还好继续更新Scikit-learn的相关基础攻略,从最简单的公开数据集入手,理解每一个算法的核心,结合scikit-learn的科学工具,一起学起来!~
❤坚持读Paper,坚持做笔记,坚持学习,坚持刷力扣LeetCode❤!!!
坚持刷题!!!
⚡To Be No.1⚡⚡哈哈哈哈
⚡创作不易⚡,过路能❤关注、收藏、点个赞❤三连就最好不过了
ღ( ´・ᴗ・` )
❤