【研一小白的白话理解】pytorch-CycleGAN-and-pix2pix
pytorch-CycleGAN-and-pix2pix
- 博客简述
-
- 项目整体理解
- GAN
- Cycle GAN
- CGAN
- DCGAN
- Pix2pix
-
- Pix2pix简介
- Auto-encoder
- U-net
- Pix2pix结构
- 项目结构
- 文件夹data
- 文件夹models
- 文件夹options
- 文件夹util
- train.py
- test.py
博客简述
这是我第一次在csdn上写博客,开学研一,自己开始自学深度学习,本篇博客内容主要是针对基于pytorch的CycleGAN-and-pix2pix的一个小白对于该算法的一个浅显粗略的理解。可能会有很多错误,我自己本身也有许多概念不够通透,但是希望大神们可以指点一下,好啦进入正文。
项目整体理解
pytorch-CycleGAN-and-pix2pix这个项目主要是由CycleGAN和pix2pix合在一起的,所以先要分别了解CycleGAN和pix2pix是个什么东西。
项目下载地址:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
GAN
首先我们要知道什么是GAN生成对抗网络呢?在没有大量标签数据同时又想达到一个很好的效果,从而又想减少对监督式学习的依赖,GAN可以说是对于非监督式学习的一种提升。
在不明确定义模型的密度分布,而是直接让模型的分布与数据的分布相作用,从中取样,这里分为两类:1.一是利用达到平稳后的马尔可夫链来取样,这里就是生成随机网络GSN。2.而另一类便是GAN,GAN是一种隐式计算,在GAN中G网络(生成器:生成能混淆判别器的图片,是一个梯度下降的过程)和D网络(判别器:区分生成器生成的图片和真实的图片,是一个梯度上升的过程)两个网络对抗训练,协同进化。关键在于训练方式有所不同:这里G网和D网没有直接去训练而是间接对抗,先训练判别器固定生成器,让生成器尽可能误导判别器的图片,就像0和博弈水火不容一样。在我的理解看来,这既是优化问题,又是博弈问题的解,这个解是一种纳什均衡。
举一个简单的例子,伪造minst数据集:
1.创建解析器,创建一个 ArgumentParser 对象:parser = argparse.ArgumentParser(),parser 对象包含将命令行解析成 Python 数据类型所需的全部信息。
2.添加参数:通过调用 add_argument() 方法给 parser对象添加程序所需的参数信息,以此来定义众多可变的全局变量。从一个噪音数据,100个特征开始,生成出来一个结果,代表minst数据集
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
3.解析参数:通过 parse_args() 方法解析参数,结果返回给opt。
4.定义图片shape(通道数长宽)(12828)以及使用cuda的条件
5.定义G网:定义两个函数block和forward
def block(in_feat, out_feat, normalize=True): # 传入参数为(输入,输出,是否归一化)
layers = [nn.Linear(in_feat, out_feat)] # 先定义好一个全连接层,生成器生成的100维向量
if normalize: # 如果需要归一化的话,则在列表末端添加两个对象:归一化层和泄露的修正线性单元
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False), #调用四次bolock函数
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))), #输出的特征个数必须和原始输入是一样的,原始28*28*1,所以是784,一会还得reshape回去
nn.Tanh() #np.prod用来计算所有元素的乘积,对于有多个维度的数组可以指定轴,如axis=1指定计算每一行的乘积
)
6.定义D网:
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
7.定损失义函数.,实例化网络。
值得一提的是BCE损失函数数学表达为(其中*o[i]*表达的概率值是已经结果sigmoid()激活函数运算后得到的)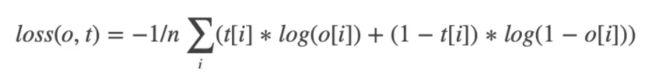
8.定义数据加载器对象dataloader,设置好batch-size。定义两个优化器对象虽然一样但是也是两个。
9.**(重点)**训练方法和损失函数:在dataloader中循环batch来训练
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)#真的就是从minst数据集拿出来的,真数据标签就是1
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False) #一开始100维向量,结果生成器网络得到的图像就是一假的标签就是0
# ---------------------
# Train Generator
# ---------------------
#随机的高斯分布噪声,均值为0标准差为1,z的意思就是随机初始化一个batch的向量,维度是(图片通道数,opt的维度)也即1*100
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
real_imgs = Variable(imgs.type(Tensor)) #真实图片
optimizer_G.zero_grad() #生成器梯度清零
gen_imgs = generator(z) #得到假数据,通过生成网络将100维向量生成784维的特征
g_loss = adversarial_loss(discriminator(gen_imgs), valid) #损失函数的定义方法:gen_imgs是生成结果,想骗过判别器,将结果传入判别器,对于生成器来说是希望能骗过去的,所以传入的标签值是1。也即用假数据和真标签训练生成器
g_loss.backward() #生成器反向传播,但是损失值是经过了判别器了的,由于求导的链式法则,所以此时判别器不得不有了梯度
optimizer_G.step() #只更新生成器的梯度
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad() # 把生成器损失函数梯度反向传播时,顺带计算的判别器参数梯度清空
real_loss = adversarial_loss(discriminator(real_imgs), valid) #判别器的第一个损失值:真数据真标签来训练判别器
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake) #判别器的第二个损失值:假数据和假标签来训练判别器
d_loss = (real_loss + fake_loss) / 2 #求平均,得到判别器的总损失
d_loss.backward() #损失回传,反向传播
optimizer_D.step() #梯度更新
10.训练完成,得到生成器。
**(重点)**可是这里突然又出现了一个问题,明明之前说好的是先训练判别器在训练生成器。但是为什么在展示的这个例子中反而先训练生成器又训练了判别器呢?
答:首先我们先要理解计算图的概念,在pytorch中计算图的本质是一种动态的有向无环图,计算图什么时候会被释放呢?在每次调用backward时被释放(有一种特殊情况:当对列表进行torch.stack()操作时增加新的维度进行堆叠,其对应的反向传播会多次执行,所以会提前释放,一般的解决方案就是添加retain_graph=True;将叶子节点detach掉)。
神经网络的训练有时候可能希望保持一部分的网络参数不变,只对其中一部分的参数进行调整;或者只训练部分分支网络,并不让其梯度对主网络的梯度造成影响,torch.tensor.detach()和torch.tensor.detach_()函数来切断一些分支的反向传播,torch.tensor.detach_()和torch.tensor.detach()的区别:detach()和detach_()很像,两个的区别就是detach_()是对本身的更改,detach()则是生成了一个新的variable。
回到问题来,如果先训练判别器,再训练生成器的话,在判别器反向传播对假标签和假数据的过程中也会计算生成器的梯度,但只更新判别器的梯度。而当生成器在反向传播的时候,对于假数据和真标签也同样经过判别器的网络,故要进行两次反向传播。我参考了篇[博客]_34218078/article/details/109591000),具体代码在这篇博客中。但是仍然会有些同学难以理解,为了更好的理解,我做了画图标识,通俗易懂来讲就是有三种方法:
1.先D后G:针对噪声noise,一次前向传播两次反向传播(第一次反向传播为了更新 discriminator 的参数,但多余计算了 generator 的梯度。第二次反向传播为了更新 generator 的参数,但是计算了 discriminator 的梯度),所以要在第一次反向传播结束后保证计算图不会被释放,必须用参数控制。
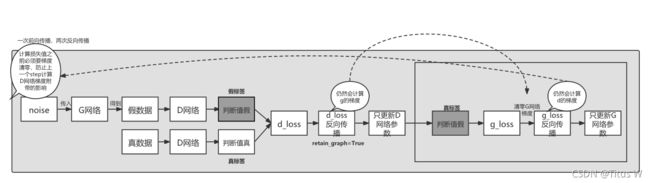
2.先D后G:第二种则是计算了两次判别器和一次生成器,也是一种方法

3.先G后D:
解决方法则是需要要在判别器反向传播参数设置中 retain_graph=True 十分重要,否则计算图内存将会被释放,为了保持计算图不被释放。因为 pytorch 默认一个计算图只计算一次反向传播,反向传播后,这个计算图的内存就会被释放,所以用这个参数控制计算图不被释放。还有一种方法就是使用detach()函数,也就是在往判别器传入假数据的时候,给假数据加上.detach()函数,pred_gen_det = discriminator(gen_imgs.detach()) # 假数据detach(),禁止生成器更新,判别器对假数据的输出。 这个流程则是我之前展示出代码所经过的流程。
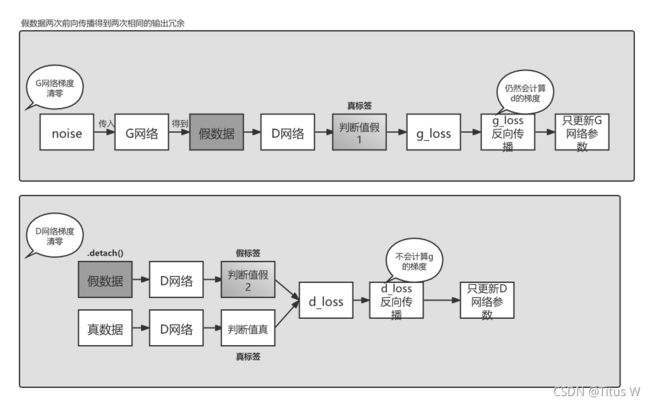
事实上各种方法区别不是很大,实际意义也不是很大。但是如果参数量巨大的时候,反而这第三种方法会提高一些效率,一般来说生成网络要比判别网络复杂一些,判别网络本质上也只是一个求概率的分类问题,所以尽可能少的减少生成网络前向传播的计算量是更好的。
经过以上的分析之后给出我对生成对抗网络GAN的浅显粗略的理解:首先GAN的主要任务是创造出这个世界上不存在的事物,主要分为三个部分,生成、判别、对抗。生成器的任务是根据随机向量产生内容。判别器负责判断内容是否是真实的,通常他会给出一个概率。对抗是交替训练的过程,直到判别器对输入内容的预测概率都接近0.5,也就是无法分辨真假就停止训练。GAN家族庞大,还有WGAN(wasserstein distance),DCGAN(均采用卷积神经网络的GAN),Cycle GAN(拥有两个生成器和两个判别器),StyleGAN(融合特征),3DGAN(升维)。能完成类似功能的还有玻尔兹曼机、变分自编码器等。
Cycle GAN
在了解了最基本的生成对抗网络的概念之后,接下来就要介绍Cycle GAN了,相比较上述简单但对生成器和判别器组成的生成对抗网络。想要了解Cycle GAN必须先知道在原始基础的结构上有了什么变化,做了那些升级呢?
主要来说三点做了比较明显的升级变化:1.整体网络架构
2.涉及到四种损失函数:G网络,D网络,Cycle,Identity
3.D网络的PatchGAN
围绕这三点,我们逐一来进行一个学习和探讨:
首先是整体网络架构Cycle GAN有两个生成器和两个判别器,其中一个生成器负责将A转换成B,并使B尽可能通过B判别器的审查。而另一个生成器负责将B转化成A,并让A尽可能通过A判别器的审查。然后首尾相连,让经过两次转化的内容尽可能与原始的内容一致,我们就会拥有两个很强的生成器,如下图:一共有四个网络,两个生成网络和两个判别网络
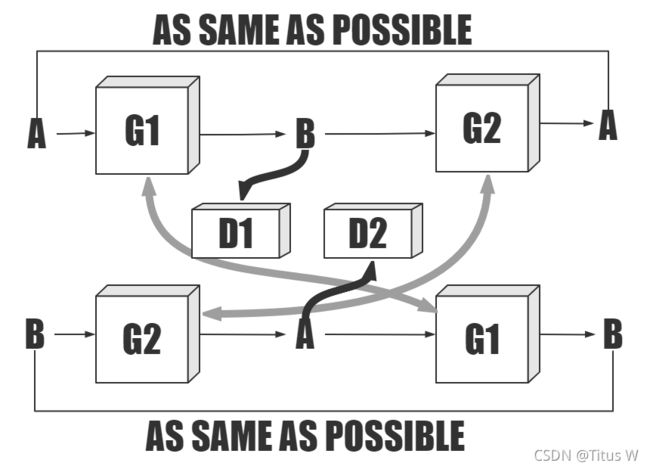
接下来就是四种损失函数了,G网络和D网络的损失函数和之前一样。关键是在A到B到A这个过程中。输入的A和还原生成的A最后逐个像素点每一个pix进行一个lrloss,计算每一个像素点之间的值加上平方项计算差异项。identity映射:生成出来的图像再次传入生成它的网络再次输出,这两个越小越好。
PatchGAN的作用:PatchGAN输出的是一个N*N的矩阵,需要基于感受野来计算损失。基于感受野在特征图上的预测结果,和标签(也需设置成N*N)计算损失。这么说可能有些官方,以我自己简单理解在Cycle GAN中判别器并不是得到一个结果值或者说是概率值,而是通过CNN得到的特征图结果不会连全连接层,更不会传入sigmoid函数中。这个输出的特征图肯定是三维的N*N*1,在这个特征图中每一个像素点都对于原始感受野的某一个区域,这个区域就叫做一个patch。所以此时并不会通过将这个特征图传入判别器来判别真假,而是基于每一个小patch都做判断。而此时标签也不仅仅是一个值了,也是一个N*N的矩阵,通过这个矩阵和特征图矩阵来进行比较。
CGAN
没接触之前,我以为cGAN是Cycle GAN的一个缩写,结果我错了。cGAN是条件式生成对抗网络(Conditional Generative Adversarial Nets)的简称。通过原始论文了解到,是通过为数据增加label来进行构造,在G网络和D网络的输入上都增加label,然后通过做了两个实验,给定条件y结合随机分布,生成符合条件的y的样本。
做了两个什么实验呢?1.mnist数据集,基于给定label生成特定数字的模型实验。2.用于multi-model- model多模态学习,生成不属于训练的描述性标记。我个人并没有做这两个实验,主要是为了理解cGAN的概念。
之前的无条件GAN中,生成的数据是不可控的,但是给定标签的cGAN网络,可以基于label生成特定的图像。对于one-to-many mapping模型,比如image tag问题,一张图像可能不止一个tag,传统模型无法解决,因此可以使用条件生成概率,将输入图像视为conditional variable(条件变量),使用条件预测分布去获取一对多的映射关系。
原始论文中CGAN的流程图

D判别器的输入除了图像之外加入了y标签(绿色的圆圈)。y这个特征维度与x相同是因为在模型内部进行了embedding处理。G生成器的输入除了噪声之外,也加入了y标签。维度关系同上。然后将生成的图像作为一半输入与y结合送入到D判别器。
接下来一一段简单的代码来理解CGAN:
class Discriminator(nn.Module):
'''全连接判别器,用于1x28x28的MNIST数据,输出是数据和类别'''
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(28 * 28 + 10, 512),
nn.LeakyReLU(0.2, inplace=True),#inplace为True,将会改变输入的数据 ,否则不会改变原输入,只会产生新的输出
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x, c): #输入和标签
x = x.view(x.size(0), -1) #展平成一维
validity = self.model(torch.cat([x, c], -1)) #cat()函数,连接函数,连接两个tensor,torch.cat( ( ) ,0 ) 是竖着连接,torch.cat( ( ) ,1 or-1 ) 是横着连接
return validity
class Generator(nn.Module):
'''全连接生成器,用于1x28x28的MNIST数据,输入是噪声和类别'''
def __init__(self, z_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(z_dim + 10, 128), #噪声维度加10,为10个标签值预留空间
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(128, 256),
nn.BatchNorm1d(256, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.BatchNorm1d(512, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(in_features=512, out_features=28 * 28),
nn.Tanh()
)
def forward(self, z, c): #噪声和标签
x = self.model(torch.cat([z, c], dim=1))
x = x.view(-1, 1, 28, 28) #x是判别器的输入,-1的意思是自适应
return x
# 初始化构建判别器和生成器
discriminator = Discriminator().to(device)
generator = Generator(z_dim=z_dim).to(device)
# 初始化二值交叉熵损失
bce = torch.nn.BCELoss().to(device)
ones = torch.ones(batch_size).to(device)
zeros = torch.zeros(batch_size).to(device)
# 初始化优化器,使用Adam优化器
g_optimizer = optim.Adam(generator.parameters(), lr=learning_rate)
d_optimizer = optim.Adam(discriminator.parameters(), lr=learning_rate)
# 开始训练,一共训练total_epochs
for epoch in range(total_epochs):
# torch.nn.Module.train() 指的是模型启用 BatchNormalization 和 Dropout
# torch.nn.Module.eval() 指的是模型不启用 BatchNormalization 和 Dropout
# 因此,train()一般在训练时用到, eval() 一般在测试时用到
generator = generator.train()
# 训练一个epoch
for i, data in enumerate(dataloader):
# 加载真实数据
real_images, real_labels = data
real_images = real_images.to(device)
# 把对应的标签转化成 one-hot 类型
tmp = torch.FloatTensor(real_labels.size(0), 10).zero_()
real_labels = tmp.scatter_(dim=1, index=torch.LongTensor(real_labels.view(-1, 1)), value=1)
real_labels = real_labels.to(device)
# 生成数据
# 用正态分布中采样batch_size个随机噪声
z = torch.randn([batch_size, z_dim]).to(device)
# 生成 batch_size 个 ont-hot 标签
c = torch.FloatTensor(batch_size, 10).zero_()
c = c.scatter_(dim=1, index=torch.LongTensor(np.random.choice(10, batch_size).reshape([batch_size, 1])),
value=1) #从【src源数据】中获取的数据,按照【dim指定的维度】和【index指定的位置】,替换input中的数据。
c = c.to(device)
# 生成数据
fake_images = generator(z, c)
# 计算判别器损失,并优化判别器
real_loss = bce(discriminator(real_images, real_labels), ones)
fake_loss = bce(discriminator(fake_images.detach(), c), zeros)
d_loss = real_loss + fake_loss
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# 计算生成器损失,并优化生成器
g_loss = bce(discriminator(fake_images, c), ones)
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
# 输出损失
print("[Epoch %d/%d] [D loss: %f] [G loss: %f]" % (epoch, total_epochs, d_loss.item(), g_loss.item()))
# 下面我们用随机噪声生成一组图像,看看CGAN的效果:
# 用于生成效果图
# 生成100个随机噪声向量
fixed_z = torch.randn([100, z_dim]).to(device)
# 生成100个one_hot向量,每类10个
fixed_c = torch.FloatTensor(100, 10).zero_()
fixed_c = fixed_c.scatter_(dim=1, index=torch.LongTensor(np.array(np.arange(0, 10).tolist() * 10).reshape([100, 1])),
value=1)
fixed_c = fixed_c.to(device)
generator = generator.eval()
fixed_fake_images = generator(fixed_z, fixed_c)
plt.figure(figsize=(8, 8))
for j in range(10):
for i in range(10):
img = fixed_fake_images[j * 10 + i, 0, :, :].detach().cpu().numpy()
img = img.reshape([28, 28])
plt.subplot(10, 10, j * 10 + i + 1)
plt.imshow(img, 'gray')
```ut_dim=self.latent_dim))
根据代码,我们很容易看出和之前传统的GAN的区别,生成网络的输入值增加了真实图片的类标签,生成网络的初始向量z_dimension之前用的是100维,由于MNIST有10类,Onehot以后一张图片的类标签是10维,所以将类标签放在后面z_dimension=100+10=110维;训练生成器的时候,由于生成网络的输入向量z_dimension=110维,而且是100维随机向量和10维真实图片标签拼接,需要做相应的cat()拼接操作;
DCGAN
在了解DCGAN之前,我们需要先了解什么叫做转置卷积,也叫反卷积。但是我觉得这里叫反卷积有些不太好,对于初学者来说会有些误人子弟。因为卷积操作本身就是不可逆的,卷积嘛,本身就是特征提取和信息丢失的过程,怎么能够还原出来呢?所以客观理解,属于一种特殊的正向卷积。这里我阅读了一篇很赞的博客理解了转置卷积,虽然这篇博客已经写的非常通俗易懂了,但是我还是以一个小白的角度来说一下我对转置卷积的理解。
首先我们知道在普通卷积的过程中,卷积核在感受野上根据步长不停的滑动从而计算得到特征,事实上这个计算过程计算机并不是通过这种方式来进行的,而是把卷积核外围补上几圈直角0使卷积核和输入矩阵完全一样,再把这个输入矩阵拉长成向量再取转置,直接和补完0之后的所有卷积核拼接起来相乘,便得到输出特征的转置。这个过程不是转置卷积,但如果把输出特征的转置乘上卷积核拼接后的转置,得到的结果的形状不也和输入拉长的向量的转置是相同的吗?这便是转置卷积思想的由来,所以这并不是一个卷积操作的逆过程,而是逆形式的正向卷积操作,对于同一个卷积核,经过转置卷积操作之后并不能恢复到原始的数值,保留的只有原始的形状。
也就是说在实际卷积的过程中:滑动计算的过程=输入维度转成列向量取转置*卷积核补0拼接后拉成的列向量
而实际转置卷积的过程中:输入维度转成列向量(因为太小,需要补0)*卷积核补0拼接后拉成的列向量=像是一个更大的卷积核再超过了原始输入的维度的边框进行滑动计算。
以后我们再做转置卷积的时候,其实就是一种特殊的直接卷积,只不过步骤有些不太一样,但是也很简单,因为卷积核大小已经大于输入了,所以根据卷积核大小尺寸来为原始输入补充0增大尺寸,然后再将卷积核左右上下反转(旋转180°),直接进行卷积即可。
```python
class D_dcgan(nn.Module):
'''滑动卷积判别器'''
def __init__(self):
super(D_dcgan, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=4, stride=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True)
)
# 全连接层+Sigmoid激活函数
self.linear = nn.Sequential(nn.Linear(in_features=128, out_features=1), nn.Sigmoid())
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0), -1)
validity = self.linear(x)
return validity
class G_dcgan(nn.Module):
'''转置卷积生成器'''
def __init__(self, z_dim):
super(G_dcgan, self).__init__()
self.z_dim = z_dim
# 第一层:把输入线性变换成256x4x4的矩阵,并在这个基础上做转置卷积操作
self.linear = nn.Linear(self.z_dim, 4*4*256)
self.model = nn.Sequential(
nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=3, stride=2, padding=0),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(in_channels=64, out_channels=1, kernel_size=4, stride=2, padding=2),
nn.Tanh()
)
def forward(self, z):
# 把随机噪声经过线性变换,resize成256x4x4的大小
x = self.linear(z)
x = x.view([x.size(0), 256, 4, 4])
# 生成图片
x = self.model(x)
return x
判别器 和 生成器 的网络结构,和之前类似,只是使用了卷积结构。
Pix2pix
Pix2pix简介
在了解了Cycle GAN的基本的网络结构之后,我们知道在Cycle GAN中生成器的输入信息可以是噪声也可以是其他条件信息,当输入为图像时,Pix2pix就诞生了。通俗理解为Pix2pix是用作图像翻译的CGAN,且用比较深的网络,进行精密的调参产生不错的结果。但是Pix2pix是需要配对的标签图像和实际图像的。虽然图像翻译的效果很好,但是我的电脑不太行,唉没办法。
那么再学习pix2pix之前,我们先要了解pix2pix的结构,而再了解pix2pix的结构之前,我们要先了解两个概念自动编码器和U-net。
Auto-encoder
关于自动编码器,我这里就不看论文大谈了,只是把我自己学到的关于自动编码器的知识和理解浅谈一下。
首先是概念:我个人理解现在高质量的带标签的数据集是很难得很珍贵的,所以在未来非监督学习的应用将更加广泛,我把把编码器理解为一种从输入到输出的映射。通过编码器把输入变成一个隐变量(隐变量是指一个压缩后的表示),再通过解码器还原重构这个数据。也就是说编码器和解码器能尽可能还原会原始的输入。可这有什么用呢?输进去又数出来?其实是有用的,这其中的关键就是中间的embedding层,或者说也叫中间的压缩表示(compressed representation),这个压缩表示则是通过降维得来的,我们知道降维属于非监督学习的一种,这里不得不提到的就是隐含层了。
首先隐含层是什么?有什么意义?隐含层的定义很简单,除了输入和输出层意外的其余所有各层都叫隐含层。之前深度学习的发展停滞,主要是由于亦或问题得不到解决,但是非线性激活函数的引入让我们突破这一屏障,一个神经元拟合一条直线,多个神经元就能拟合非线性的边界,通过一层一层的提取,隐含层就可以把输入数据的特征抽象到另一个维度的空间,是这些特征更加抽象化,方便线性划分。所以神经网络的万能近似定理就是只要有一个隐含层的神经网络,理论上就可以拟合任何一种函数。而编码器和解码器都是可以通过神经网络来构建的。
回到自动编码器来说,因为自动编码器本身就是一层神经网络,所以可以用普通的前馈神经网络,但事实上卷积神经网络的效果会更好。在编码器部分用的最多的是池化,把大的feature-map变成小的feature-map,而在解码器部分用的比较多的则是转置卷积。
接下来要谈一谈自动编码器的类别:
1.如果中间的隐变量比原始输入维度要小,称之为欠完备自动编码器,因为要强制自编码器捕捉训练数据中最显著的特征,所以学习过程等价于最小化一个损失函数(MSE或者L2)。
2.反之则成为过完备自动编码器:隐藏编码的维度大于或等于输入维度,这种编码器信息过于冗杂,学不到有用的东西。
3.去噪自编码器:意如其名,输入的是带噪声的数据,而输出的是去掉噪声的数据,也就是接受损坏数据作为输入,并训练来预测原始未被损坏的数据。
4.变分的自动编码器:关于变分自动编码器我又要多说几句了。
传统的自动编码器转换过程是:数据—>隐变量—>重构回新的数据。
而变分自动编码器的转换过程是 :每一个隐变量都要找到一个正态分布(这里是通过正则化的方式把每一个隐变量分布都作为正态分布),每一个正态分布都要拟合均值和方差,每一个输入的数据都能对应一个隐变量的分布都作为正态分布。好像听起来比较抽象。。。。现在我不是每一个隐变量都得到一个分布嘛,我就就在每一个分布上采样,能才好几个样好几个不同值,每一个采样都能重构会原来的值。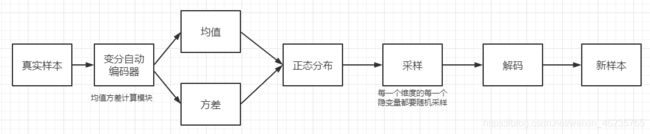
这里又跑出来一个新概念叫变分,这是一个泛函分析里的一个概念。函数的微分叫做微分,而泛函的微分叫做变分。那泛函又是什么呢?我看了几节课程,这个不在这里太多赘述,简单来讲:泛函虽然也是一种像函数一样的映射关系,但是确实截然不同的一个概念,关键的不同之处就是在于从哪映射到哪,泛函研究的是无穷维空间到无穷维空间的映射,至于再深入到拓扑线性空间里去就算了哈哈,感觉没啥必要了就。
U-net
在了解了自动编码器之后,U-net是一种全卷积的神经网络,在当初刚发表时具有很好的创新性,我对这个算法理解并不是很充分,根据下图可以简单的概括一下U-net的基本思路:
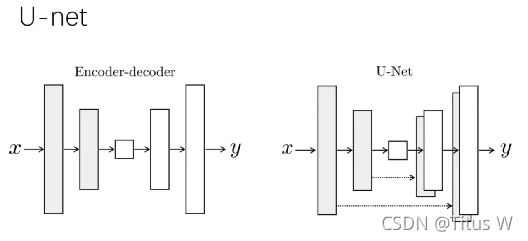
这里看一个知乎的回答对这个结构描述很到位:U-Net是一种典型的编码-解码结构,编码器部分利用池化层进行逐级下采样,解码器部分利用反卷积进行逐级上采样,原始输入图像中的空间信息与图像中的边缘信息会被逐渐恢复,由此,低分辨率的特征图最终会被映射为像素级的分割结果图。而为了进一步弥补编码阶段下采样丢失的信息,在网络的编码器与解码器之间,U-Net算法利用Concat拼接层来融合两个过程中对应位置上的特征图,使得解码器在进行上采样时能够获取到更多的高分辨率信息,进而更完善地恢复原始图像中的细节信息,提高分割精度。而增加了skip connection结构的U-Net,能够使得网络在每一级的上采样过程中,将编码器对应位置的特征图在通道上进行融合。通过底层特征与高层特征的融合,网络能够保留更多高层特征图蕴含的高分辨率细节信息,从而提高了图像分割精度。
Pix2pix结构
在有了一些铺垫知识知识以后,就可以了解Pix2pix的结构了,Pix2pix从本质上讲是一种更强的CGAN,整体的结构还是比较简单的:
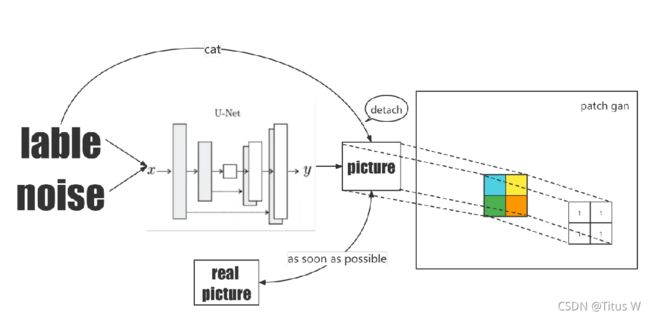
项目结构
该项目涉及的代码文件比较多,所以我会先按照文件夹名字来进行划分。
文件夹data
该文件夹包括数据的加载和处理以及用户可制作自己的数据集,介绍一下以下七种数据集类。
init_.py: 实现包和train、test脚本之间的接口。train.py 和 test.py 根据给定的 opt 选项调包来创建数据集 from data import create_dataset和dataset = create_dataset(opt)
**base_dataset.py:**继承了 torch 的 dataset 类和抽象基类,该文件还包括了一些常用的图片转换方法,方便后续子类使用。
本文件主要定义了一个BaseDataset的继承基类的接口来定义四种方法,继承BaseDataset的子类必须实现这四种方法:
1.init:(初始化这个类),根据获取到的opt里的dataroot来得到数据集的存放路径。
2.len:(返回数据集的大小),@abstractmethod接口的注解。
3.getitem(得到一条data),@abstractmethod接口的注解。
4.modify_commandline_options(可选的,设置数据集的一些默认选项),@staticmethod注解将该方法改为静态方法,因为该方法不需要用到对象中的任何资源,传入的参数为是否训练解析器parser。
定义好接口,就写几个和图像变化相关的方法:
get_params(根据用户指定的方式resize或者crop出合适大小的输入尺寸,并返回随机数和bool值)
get_transform(此函数是通过transform_list列表中的操作进行图像变换,使用transforms.Lambda封装其为transforms策略,通过transforms.Compose()将各种变换、比例尺、旋转裁剪、标准化等transform操作串联起来,这些操作函数将再下面定义好)
接下来的五个函数为get_transform函数所调用:
__make_power_2(按照相应尺寸,调整大小)
__scale_width(调整图片的宽和高,保持相同的比例)
__crop(随机平移滑动裁剪,裁剪中心点是随机生成的)
__flip(图像向左或者向右翻转旋转)
__print_size_warning(打印一些警告信息)
image_folder.py:更改了官方pytorch的image folder的代码,使得从当前目录和子目录都能加载图片,目的就是获得指定目录下的图片路径和 加载路径图片。首先会定义一个元组来存放该程序支持图片的后缀名来限制图片格式,紧接着会写三个函数:
is_image_file:检查传入列表中的文件名是否符合要求,这里有一个any()函数需要注意一下,any()函数用于判断给定的可迭代参数iterable是否全部为False,则返回False,如果有一个为True,则返回True。
make_dataset:传入图片数据集文件夹的路径来制作数据集。这里会先定义一个空列表,然后传入路径是否存在,把路径传入os.walk()函数作为遍历基础,通过遍历得到文件夹路径和图片名称并存放在之前定义的空列表里,最后返回该列表的前一部分。
default_loader:把读到的图片转成RGB格式,不转则是四通道。
接下来终于要写ImageFolder这个类了,一般情况下在做图像分类任务时,会采用官方写好的torchvision.datasets.ImageFolder接口实现数据导入,因为对于分类问题,数据集路径下一般包括两个文件夹,train和test,每个文件夹下有包括N个子文件夹,N便是分类的类别数。但是有些情况就不是这样的,比如一个文件夹下面各种类别图像数据都有,用一个对应的txt文件当作对应的标签文件,在这种情况下就需要自定义一个数据的接口了。首先在Pytorch中和数据读取相关的类基本都要继承data.Dataset这个基类,然后改写其中的__init__、len、__getitem__等方法。
1.init:初始化,并判断是否真实存在图片。
2.len:返回目录下图片的数量。
3.getitem:返回图片或图片和路径。
template_dataset.py:为制作自己数据集提供了模板和参考,里面注释一些细节信息,就是提供一个实现自定义数据集的模板,因为实现了BaseDataset接口,同样要实现那四个方法。
1.init:初始化数据集的类,保存选项、获取数据集的图像路径和元信息,定义图像变换,定义默认的变换函数。您可以使用,也可以定义自定义变换函数。
2.len:返回图像的总数量。
3.getitem:传入用于数据索引的随机整数,返回有名称的数据字典。(这个过程总共分为四步:步骤1:获取随机图像路径。步骤2:从磁盘加载数据。步骤3:将数据转换为PyTorch张量。步骤4:将数据点作为字典返回。)
4.modify_commandline_options:调用 add_argument() 方法添加参数,调用set_defaults()方法修改一些默认值,最后返回修改过后的解析器。
single_dataset.py:继承BaseDataset类定义最简单的dataset类,只加载指定路径下的一张图片,它可以加载由路径dataroot /path/to/data指定的一组单个图像。它也可以用于生成周期的结果仅为一侧与模型选项-模型测试。
colorization_dataset.py:它可以加载RGB格式的自然图像集,并将RGB格式转换为实验室颜色空间中的(L, ab)对。加载一张 RGB 图片并转化成(L,ab)对在 Lab 彩色空间,pix2pix用来绘制彩色模型。它是基于pix2pixel的着色模型(——模型着色)所需要的。同样继承了BaseDataset就要实现那四种方法,大同小异,在这里不再赘述,补充几个函数吧:
os.path.join(): 径拼接函数,连接两个或更多的路径名组件。
sorted():函数对所有可迭代的对象进行排序操作。
assert():并非只是一个报错函数,而是一个宏,相当于一个if语句,其作用是如果他条件返回错误,则终止程序的执行。
color.rgb2lab():将RGB三元组转换为LAB三元组。
aligned_dataset.py:从同一个文件夹中加载的是一对图片 {A,B},测试过程中需要准备一个目录/path/到/data/test作为测试数据。
unaligned_dataset.py:从两个不同的文件夹下分别加载 {A},{B} ,在测试期间需要准备两个目录/path/to/data/testA和/path/to/data/testB。
这两个数据集类最大的区别在于__getitem__()方法的实现,在得到数据索引之后。
前者:根据索引创建了一个AB_path的路径,得到AB数据,再通过对AB的剪裁分别得到A和B的数据,对A和B调用相同的get_transform90方法,最后返回A和B已经他们各自的路径,他们各自的路径都是相同的都是AB_path。
后者:根据索引分别创建A和B的路径A_path和B_path,里要注意首先要确保索引在正确的范围内,再随机化这些索引避免固定对,再通过这些索引得到A和B数据,对A和B调用相同的get_transform90方法,最后返回A和B已经他们各自的路径,他们各自的路径是不同的。
这个文件夹就先说的这里,总结一下,主要是定义了一下操作数据集的类。
文件夹models
这里是这个项目的核心代码,像上面刚刚介绍的data一样,各种类也需要继承BaseModel写各种方法。
init_.py: 实现包和train、test脚本之间的接口。train.py 和 test.py 根据给定的 opt 选项调包来创建数据集 from data import create_dataset和dataset = create_dataset(opt)
base_model.py:继承了抽象类,也包括一些其他常用的函数:setup,test,update_learning_rate,save_networks,load_networks,在子类中会被使用。这个类是一个模型类的接口,要创建子类,您需要实现以下五个方法:
–<init>:初始化类。需要定义四个列表:1.–self.loss_name(str list):指定要绘制和保存的训练损失。
2.–self.model_name(str list):指定要显示和保存的图像
3. --self.visual_name(str list):定义培训中使用的网络。
4.–self.optimizers(优化器列表):定义和初始化优化器。可以为每个网络定义一个优化器。
5.–self.image_paths(str list):定义图片的存放路径。
–
–
–:产生中间结果。
–
紧接着又定义了一些函数:
1.setup(加载和打印网络;创建调度程序。):若是训练,调用networks.py中的get_scheduler函数再优化器中迭代;如果不是训练且迭代次数大于0,则创建调度load_suffix,并适用于下述的load_networks方法加载该网络,学习率衰减。
2.eval(测试期间使模型处于评估模式。):在循环中判断网络名字的类型是否为str,得到网络名字后调用eval()。
3.test(测试时间中使用的正向功能,它还调用
4.compute_visuals(计算visdom和HTML可视化的其他输出图像。):直接一个pass目的只是为了防止报错,毕竟这些内置函数是用C或者C++写的。
5.get_image_paths(返回用于加载当前数据的图像路径。)
6.update_learning_rate(在每次epoc结束时调用,更新所有网络的学习率。):提一个题外点,scheduler.step()需要在optimizer.step()的后面调用,因为scheduler.step()的其中一个作用是调整学习率,如果调用scheduler.step(),则会改变optimizer中的学习率。
7.get_current_visuals(返回可视化图像。train.py将使用visdom显示这些图像,并将图像保存到HTML。):首先实例化一个OrderedDict类,使用OrderedDict会根据放入元素的先后顺序进行排序,所以输出的值是排好序的。接下来循环中判断类型返回对象。
8.get_current_losses(返回训练损失/错误。train.py将在控制台上打印这些错误,并将它们保存到文件中。)同上。
9.save_networks(将所有网络保存到磁盘。)同样还是在循环中判断类型得到名字,判断cuda安装没有GPU是否可用,然后保存。
10.__patch_instance_norm_state_dict(修复InstanceForm检查点不兼容(0.4之前的版本)。)
11.load_networks(从磁盘加载所有网络。)同样在循环中判断类型得到文件名和文件路径,当迭代次数或者epoch足够大的时候,使用nn.DataParallel函数来用多个GPU来加速训练同时这个过程会将key值加一个module,然后创建一个新的对象,用torch.load()从文件中加载一个用torch.save()保存的对象,最后用hasattr() 函数用于判断对象是否包含对应的属性,此时就可以用load_state_dict()函数将刚刚加载了的模型load进另一个网络模型。
12.print_networks(打印网络和(如果详细)网络体系结构中的参数总数。)
13.set_requires_grad(为所有网络设置requires_grad=Fasle,以避免不必要的计算。)先判断网络是否为列表,如果不是先转成列表。
template_model.py: 实现自己模型的一个模板,里面注释了一些细节。它实现了一个简单的基于回归损失的图像到图像的转换基线。给定输入-输出对(数据A、数据B),它学习一个可以最小化以下L1损失的网络netG:
<init>: 初始化模型,定义一些损失函数loss_G,图片数据名字’data_A’, ‘data_B’, ‘output’,网络名字G,优化器Adam等。
: 把数据A传到G网络走一个前向传播。
: 计算损失反向传播。
pix2pix_model.py:实现了pix2pix 模型,用于在给定成对数据的情况下学习从输入图像到输出图像的映射。模型训练需要的数据集是–dataset_mode aligned。默认情况下生成器netG采用u-net256,而判别器netD采用basic判别器(PatchGAN)。损失函数 vanillaGAN loss (原始论文中使用的是标准交叉熵)。首先这个类继承了BaseModel,所以BaseModel中定义的那五个方法肯定是要实现的。
–
–<init>:初始化pix2pix类。需要定义四个列表:1.–self.loss_name(str list):指定要绘制和保存的训练损失,这些损失要打印出来分 别是’G_GAN’, ‘G_L1’, ‘D_real’, ‘D_fake’
2.–self.model_name(str list):指定要显示和保存的图像’real_A’, ‘fake_B’, ‘real_B’。
3. --self.visual_name(str list):定义培训中使用的模型的名字’G’, ‘D’。 这里定义的netG网络 和netD要调用在networks.py里的define_G函数和define_D函数,因为是条件GAN,所以要同时获取输入和输出图像opt.input_nc + opt.output_nc作为整个函数的输入input_nc。
4.–self.optimizers(优化器列表):定义和初始化优化器。可以为每个网络定义一个优化器。
–
–:产生中间结果。real_A传到G网络得到fake_B。
–
–
–
colorization_model.py:继承了pix2pix_model,模型所做的是:将黑白图片映射为彩色图片。该类中实现的四个方法:
–
–<init>:对于可视化,我们将“visual_names”设置为“real_A”(输入真实图像,真马),“real_B_rgb”(真实rgb图像)和fake_B_rgb”(预测rgb图像),我们将“real_B”(从Pix2pixModel继承)转换为RGB图像“real_B_RGB”,我们将“fake_B”(从Pix2pixModel继承)转换为RGB图像“fake_B_RGB”。所以主要定义一个列表,列表中的名称是指定可视化图像的名称。
–:主要是将tensor类型的图片转换成RGB numpy类型的输出。
单通道的tensor张量: L (1-channel tensor array): L channel images (range: [-1, 1], torch tensor array)
双通道的tensor张量: AB (2-channel tensor array): ab channel images (range: [-1, 1], torch tensor array)
返回值是一个RGB输出图像,类型是一个numpy array类型的。
–
cycle_gan_model.py:来实现cyclegan模型。用于学习图像到图像的转换也即图像翻译,无需成对数据。所以模型训练需要’–dataset_mode unaligned’数据集。默认情况下,它使用“–netG resnet_9blocks”resnet生成器,“–netD basic”鉴别器(由pix2pix引入的PatchGAN),和一个最小二乘GANs目标(’–gan_模式lsgan’)。该类同样继承BaseModel,一共包含9个函数。这里额外有一个关键点,就是除了GAN本身网络需要的损失函数之外,我们会额外引入新的损失函数lambda_A, lambda_B, and lambda_identity。从图像翻译一段到另一端:A (source domain), B (target domain).
Generators: G_A: A -> B; G_B: B -> A.(两个完全相同的生成器,只是输入不同)
Discriminators: D_A: G_A(A) vs. B; D_B: G_B(B) vs. A. (两个判别器)
Forward cycle loss: lambda_A * ||G_B(G_A(A)) - A|| (Eqn. (2) in the paper)
Backward cycle loss: lambda_B * ||G_A(G_B(B)) - B|| (Eqn. (2) in the paper)
Identity loss (optional): lambda_identity * (||G_A(B) - B|| * lambda_B + ||G_B(A) - A|| * lambda_A) (Sec 5.2 “Photo generation from paintings” in the paper)
在普通的CycleGAN网络里Dropout并不适用。
–
–<init>:初始化:1.指定所有损失函数的名字loss_names在一个列表中[‘D_A’, ‘G_A’, ‘cycle_A’, ‘idt_A’, ‘D_B’, ‘G_B’, ‘cycle_B’, ‘idt_B’], 共有八个损失函数。
2.指定所有数据的名字visual_names_A和visual_names_B分别不同的列表中[‘real_A’, ‘fake_B’, ‘rec_A’]和[‘real_B’, ‘fake_A’, ‘rec_B’]。如果lambda_identity已经被使用了的话,还需往列表里添加两个损失函数的名字idt_B和idt_A。训练过程中会用到’G_A’, ‘G_B’, ‘D_A’, ‘D_B’这四个损失函数,测试阶段只会用到’G_A’, ‘G_B’。
3.通过define_G函数和define_D函数分别构建两个生成器网络和两个判别器网络。
4.构建一个缓存池来存放中间生成的假图片。
5.定义损失函数:MSELoss计算逐个pixcel,反映图像从G_A到G_B再到还原回这个图像的相似程度。
L1Loss根据绝对值计算差异性。
6.定义优化器。
–
–:前向传播总共分为四步:1.G_A(A)=G_A(real_A)=fake_B
2.G_B(G_A(A))=G_B(fake_B)=rec_A
3.G_B(B)=G_B(real_B)=fake_A
4.G_A(G_B(B))=G_A(fake_A)=rec_B
–
–
–
–
G_A(B)=G_A(real_B)=B
G_B(A)=G_B(real_A)=A
通过这两个式子会求出两个生成器的损失值。
对于判别器A的作用是区分哪个是真B,哪个是假B;而判别器B的作用是区分哪个是真A,哪个是假A。所以我们把假B这真标签丢给判别器A,把假A和真标签丢给判别器B。这样又会得到两个损失值。
最后把四个损失值都加起来反向传播。
–
networks.py:包含生成器和判别器的网络架构,normalization layers,初始化方法,优化器结构(learning rate policy)GAN的目标函数(vanilla,lsgan,wgangp)。 主要是实现一些普通的实现功能,写一些函数。这里介绍一下每一个函数的作用,但是具体的实现过程不作过多赘述。
1.get_norm_layer(返回归一化的一层):functools.partial(函数,传入此函数的参数)来包装一个函数,其实主要作用就是减少乱七八糟参数的传递。
2.get_scheduler(返回一个学习率的计时器):如果学习率的优化策略是线性的,则在第一个周期保持相同的学习率,并在接下来的周期手动实现线性衰减。但对于其他的优化策略或者是调度器(阶跃step、平稳plateau和余弦cosine)就调Pytorch默认的函数。
3.init_weights(初始化网络权重):hasattr()函数用于判断对象是否包含对应的属性,先判断传入函数的m对象是否有权重和偏置项这些属性,然后选择对应的初始化类型。
4.init_net(初始化网络):最好能多GPU并行。
5.define_G(创建一个生成器):我们当前的实现提供了两种类型的生成器(每种类型分别有两种生成器):
1.U-Net:[unet_128](用于128x128输入图像)和[unet_256](用于256x256输入图像)
2.基于Resnet的生成器:[Resnet_6块](具有6个Resnet块)和[Resnet_9块](具有9个Resnet块)
基于Resnet的生成器由几个下采样/上采样操作之间的几个Resnet块组成。生成器已由
6.define_D(创建一个判别器):当前的实现提供了三种类型的鉴别器:
1.[basic]:默认PatchGAN分类器,它可以区分70×70重叠斑块是真是假,这种贴片级判别器结构具有较少的参数,比一个完整的图像鉴别器,可以以完全卷积的方式工作在任意大小的图像。
2.[n_layers]:使用此模式,在原来的基础上有了更多的设置,可以在判别器中指定conv层的数量(在[basic](PatchGAN)中使用的默认值为3)。
3.[pixel]:每一个像素分类,所以就是1x1 PixelGAN鉴别器可对像素是否真实进行分类。它鼓励更大的颜色多样性,但对空间统计没有影响。
判别器已由
7.定义一个类GANLoss,在这个类中定义了一些方法: 1.init:初始化一些损失函数。
2.get_target_tensor:创建与输入标签相同的标签张量, 就是把传入的标签转换成tensor的格式,再通过expand_as把这个tensor转换成和预测值一样的形状。
3.call:计算判别器输出与真实标签的损失。
8.cal_gradient_penalty:计算梯度惩罚损失。
9.定义一个类ResnetGenerator,基于Resnet的生成器,由几个下采样/上采样操作之间的Resnet块组成:
1.init:构造一个基于Resnet的生成器。assert()函数的作用是如果不满足条件则程序终止执行,定义一个基本的模型,然后为模型添加两层下采样层,在添加ResNet块,再添加几层上采样层。
2.forward:前向传播。
10.定义一个类ResnetBlock,用来定义Resnet块。像残差网络一样,resnet块是具有跳过连接的conv块,我们用build_conv_block函数构造一个conv块,并在功能中实现跳越连接: 1.build_conv_block:通过判断padding类型和是否使用dropout构建*conv_block。
2.forward:加上跳跃连接out = x + self.conv_block(x)。
11.定义一个类UnetGenerator,创建一个基于U-net的生成器,通过接下来要定义的UnetSkipConnectionBlock类,构建unet结构,使用ngf8过滤器添加中间层(ngf为最后的卷积层中过滤器的数量),逐渐将过滤器数量从ngf8减少到ngf。
12.定义一个类UnetSkipConnectionBlock,定义具有跳跃连接的U-net子模块,子模块可以理解为下采样的结果或者上采样的基础。
13.定义一个类NLayerDiscriminator,定义一个PatchGAN的判别器,输出一通道的判别器。
14.定义一个类PixelDiscriminator,定义一个1*1的PatchGAN的判别器。
test_model.py:此测试模型可用于仅为一个方向生成CycleGAN结果。此模型将自动设置“–dataset_mode single”,它仅从一个集合加载图像。
文件夹options
包含训练模块,测试模块的设置TrainOptions和TestOptions都是 BaseOptions的子类。详细说明options下的文件。
base_options.py:定义基础的命令行参数,一般训练和测试都需要的且值不变的命令行参数大多定义在这个文件夹里,如数据集的路径等。,除了training,test都用到的option,还有一些辅助方法:parsing,printing,saving options,包括打印和保存选项。
–<init>:重置类;表示该类尚未初始化。
–:在解析器里添加一些基础参数、模型参数、数据集参数、额外参数等。
–
–
–:解析我们的选项,创建检查点目录后缀suffix,并设置gpu设备。
train_options.py:训练需要的options。
test_options.py:测试需要的options。
文件夹util
主要包含一些有用的工具类,如数据的可视化。详细说明utils下的文件:
get_data.py:用来下载数据集的脚本。
首先定义一个GetData的类:1.–<init>:初始化pix2pix和cyclegan资源的地址。
2.–<_get_options>:通过BeautifulSoup从网页中抓取数据,在find_all()把满足条件的值取出组成一个列表,再通过text.endswith函数判断列表中以压缩文件后缀名为结尾的字符串。
3…–<_present_options>:通过r=request.get(url)构造一个向服务器请求资源的url对象。
4…–<_download_data>:识别文件类型,并对压缩包的路径传入函数extractall()解压。
5.–:下载数据集并返回路径。
html.py:保存图片写成html。基于diminate中的DOM API。此HTML类允许我们将图像和文本保存到单个HTML文件中。它包括诸如
它基于Python库“dominate”,一个使用DOM API创建和操作HTML文档的Python库:
1.–<init>:初始化HTML类。
2.–
3.–
4.–
5.–:保存现在HTML文件的内容。
image_pool.py:此类实现了一个存储之前生成的图像的图像缓冲区,该缓冲区使我们能够使用生成图像的历史更新判别器。先使用unsqueeze()扩大图片数据的维度,0代表行扩展,1代表列扩展,如果缓存池一直不满(图片数量小于缓存区大小),就一直保持插入图片数据。但如果图片数量大于缓存区大小,定义一个随机生成的概率值,有百分之50的几率,也就是把图片数据分成两部分,随机往之前定义的列表中添加。
visualizer.py:保存图片,展示图片:
1.–
定义一个类Visualizer,这个类包括几个可以显示/保存图像和打印/保存日志信息的函数。它使用Python库“visdom”进行显示,使用Python库“dominate”(包装为“HTML”)创建带有图像的HTML文件:
1.–<init>:“初始化可视化工具类:1.缓存培训/测试选项。2.连接到visdom服务器。3.创建用于保存HTML筛选器的HTML对象。4.创建日志文件以存储培训损失。
2.–
3.–
4.–
5.–
6.–
utils.py:包含一些辅助函数:tensor2numpy转换,mkdir,诊断网络梯度等:
1.–:将tensor类型转变为numpy类型。
2…–:计算并打印绝对梯度的平均值。
3…–
4…–
5…–:如果路径不存在就创建空的目录。
6…–:如果路径不存在就创建单一的空目录。
train.py
特点:此脚本适用于各种模型,支持不同的模型(带有选项“-model”:例如,pix2pix、cyclegan、彩色化)。支持不同的数据集模式(带有选项“-dataset_mode”:例如,对齐、未对齐、单一、着色)。需要指定数据集(’–dataroot’)、实验名称(’–name’)和模型(’–model’)。它首先在给定选项的情况下创建模型、数据集和可视化工具。然后进行标准的网络培训。在培训期间,它还可以可视化/保存图像、打印/保存损失图和保存模型。
支持继续/暂停训练。使用“–continue_train”恢复先前的培训。
import time
from options.train_options import TrainOptions #首先,自然是导入,这里导入训练参数,如果没有写__init__.py文件会报错哦
from data import create_dataset
from models import create_model
from util.visualizer import Visualizer
#关于这个cycleGan,主要有四种损失函数所决定,g网络和d网络的损失函数比较简单,关键是cycle:因为之前的输入和最终还原的输出要进行逐个像素点的比较(每个像素点之间的值加上平方项加上差异项),还有一个映射identity损失函数,
#因为生成器要生成一个假的,加上一个映射的损失,再把这个假的再次传入生成器,此时要一模一样,这两个图像之间的差异要越小越好
#在cycleGAN当中,判别器还有些许不同,判别器会用卷积网络得到输出结果,但是这个结果不会往sigmoid函数里面传,也不会连什么全连接层,就是一个特征图,此时这个特征图中的每一个点代表原始感受野的一个区域patch(如果是真实图像,标签和输出结果是一样的,每一个区域patch的判别结果都必须是1才达到完美)
#所以patchGAN的作用就是不是输出一个sigmoid值,而是得到一个特征图,这个特征图每一个位置都代表一个小区域,构造标签的时候构造的是和标签一样的矩阵,然后通过标签的矩阵和特征图比较
#这个patch就是判别器多加的一个部分
if __name__ == '__main__':
opt = TrainOptions().parse() # get training options 得到训练的选项opt
dataset = create_dataset(opt) # create a dataset given opt.dataset_mode and other options 根据opt得到数据集dataset
dataset_size = len(dataset) # get the number of images in the dataset. 根据数据集得到数据集图片的数量
print('The number of training images = %d' % dataset_size)
model = create_model(opt) # create a model given opt.model and other options 根据opt得到模型model
model.setup(opt) # regular setup: load and print networks; create schedulers 根据opt进行模型设置
visualizer = Visualizer(opt) # create a visualizer that display/save images and plots 根据opt设置一个可视化工具visualizer
total_iters = 0 # the total number of training iterations 训练迭代的总数
for epoch in range(opt.epoch_count, opt.niter + opt.niter_decay + 1): # outer loop for different epochs; we save the model by , + 循环从opt.epoch_count开始,到opt.niter + opt.niter_decay结束(为了继续上次的训练)
epoch_start_time = time.time() # timer for entire epoch 开始计时
iter_data_time = time.time() # timer for data loading per iteration 计时每一次迭代加载的数据
epoch_iter = 0 # the number of training iterations in current epoch, reset to 0 every epoch 每一个周期迭代次数重置为0
visualizer.reset() # reset the visualizer: make sure it saves the results to HTML at least once every epoch 重置可视化工具:确保它至少每一次将结果保存为HTML
for i, data in enumerate(dataset): # inner loop within one epoch
iter_start_time = time.time() # timer for computation per iteration 每次迭代计算的计时器
if total_iters % opt.print_freq == 0:
t_data = iter_start_time - iter_data_time
total_iters += opt.batch_size #已经迭代了的总数
epoch_iter += opt.batch_size #每个周期的迭代书
model.set_input(data) # unpack data from dataset and apply preprocessing 解压数据并做预处理
model.optimize_parameters() # calculate loss functions, get gradients, update network weights 更新权重
if total_iters % opt.display_freq == 0: # display images on visdom and save images to a HTML file 展示图片并保存图片到html文件中
save_result = total_iters % opt.update_html_freq == 0
model.compute_visuals()
visualizer.display_current_results(model.get_current_visuals(), epoch, save_result)
if total_iters % opt.print_freq == 0: # print training losses and save logging information to the disk 打印训练损失并保存到磁盘
losses = model.get_current_losses()
t_comp = (time.time() - iter_start_time) / opt.batch_size
visualizer.print_current_losses(epoch, epoch_iter, losses, t_comp, t_data)
if opt.display_id > 0:
visualizer.plot_current_losses(epoch, float(epoch_iter) / dataset_size, losses)
if total_iters % opt.save_latest_freq == 0: # cache our latest model every iterations
print('saving the latest model (epoch %d, total_iters %d)' % (epoch, total_iters))
save_suffix = 'iter_%d' % total_iters if opt.save_by_iter else 'latest'
model.save_networks(save_suffix)
iter_data_time = time.time()
if epoch % opt.save_epoch_freq == 0: # cache our model every epochs
print('saving the model at the end of epoch %d, iters %d' % (epoch, total_iters))
model.save_networks('latest')
model.save_networks(epoch)
print('End of epoch %d / %d \t Time Taken: %d sec' % (epoch, opt.niter + opt.niter_decay, time.time() - epoch_start_time))
model.update_learning_rate() # update learning rates at the end of every epoch.
整体结构:options.train_options.TrainOptions().parse()
训练时可以手动定义参数的选项函数
返回值parse:包含四部分:
1.在baseoptions的基础上,即baseoptions里的参数都有
2. 可视化参数
显示频率
可视化visdom的一些参数、网页的参数
打印频率
3.网络保存和加载参数
保存最新模型的总iter数的频率
以epoch数为频率保存模型
是否以iteration为频率保存
是否继续上次训练
继续训练,从多少epoch开始
4.训练参数
学习率为0的iter数
lr初始化学习率
gan的模式可选
池化层的size
学习率衰减政策
学习率每多少个iter乘以gamma
test.py
train.py运行会进行前向传播和反向求导,而test.py模型仅仅进行前向传播。用于图像到图像翻译的通用测试脚本。
使用train.py训练模型后,可以使用此脚本测试模型。它将从–checkpoints\u dir加载保存的模型,并将结果保存到–results\u dir。
它首先在给定选项的情况下创建模型和数据集。它将硬编码一些参数。
然后对–num_测试图像运行推断,并将结果保存到HTML文件中。
测试pix2pix模型:
if __name__ == '__main__':
opt = TestOptions().parse() # 获取测试参数
# 硬编码一些测试参数
opt.num_threads = 0 # 测试代码仅支持num_threads=1
opt.batch_size = 1 # 测试代码仅支持 batch_size = 1
opt.serial_batches = True # 禁用数据打乱; 如果需要随机选择图像的结果,请对此行进行注释。
opt.no_flip = True # 不翻转;如果需要翻转图像的结果,请对此行进行注释。
opt.display_id = -1 #无视觉显示;测试代码将结果保存到HTML文件中。
dataset = create_dataset(opt) # 使用opt.dataset_模式和其他选项创建数据集
model = create_model(opt) # 根据opt.model和其他选项创建模型
model.setup(opt) # 常规设置:加载和打印网络;创建调度程序
# 创建网站
web_dir = os.path.join(opt.results_dir, opt.name, '{}_{}'.format(opt.phase, opt.epoch)) #定义网站主管
if opt.load_iter > 0: # 默认情况下,load_iter为0
web_dir = '{:s}_iter{:d}'.format(web_dir, opt.load_iter)
print('creating web directory', web_dir)
webpage = html.HTML(web_dir, 'Experiment = %s, Phase = %s, Epoch = %s' % (opt.name, opt.phase, opt.epoch))
# 使用评估模式进行测试。这只影响batchnorm和dropout等层。
# 对于[pix2pix]:我们在原始pix2pix中使用batchnorm和dropout。您可以使用eval()模式和不使用eval()模式进行试验。
# 对于[CycleGAN]:它不应该影响CycleGAN,因为CycleGAN使用instancenorm而没有退出。
if opt.eval:
model.eval()
for i, data in enumerate(dataset):
if i >= opt.num_test: # 仅将我们的模型应用于opt.num_测试图像。apply our model to opt.num_test images.
break
model.set_input(data) # 从数据加载器解包数据
model.test() # 运行推理
visuals = model.get_current_visuals() # 获取图像结果
img_path = model.get_image_paths() # 获取图像路径
if i % 5 == 0: # 将图像保存到HTML文件
print('processing (%04d)-th image... %s' % (i, img_path))
save_images(webpage, visuals, img_path, aspect_ratio=opt.aspect_ratio, width=opt.display_winsize)
webpage.save() # save the HTML
由于内容实在太多了,项目部署我放在下次。