安卓如何做界面性能优化
前言:
1.现在网上有很多讲如何进行界面性能优化的文章,但是往往就讲到了如何解决内存波动问题。两者虽然有关联性,但是并不能完全划等号的,内存波动确实一定程度上会影响界面的绘制,但是也只是其中一种原因,并不能混为一谈。以及还有很多介绍过度绘制等等的,感觉都是大同小异。
2.本文的写作目的,是为了帮助初级,中级,包括部分高级安卓开发,快速的定位/解决实际应用场景所遇到的那些界面卡顿的问题,或者说引导一个合理的解决问题的方向。具体问题的解决,还是需要具体的方案去解决的。
3.当然,完全了解了本篇文章的原理后,对于安卓方面的面试,也会有一定的帮助作用。
一、如何衡量界面是否卡顿
衡量页面是否卡顿主要有三代方案,虽然中间也会有一些perfdog一类的监控框架,但是基本上都属于这三代方法原理之中的。
1.1 第一代方案:Looper注册回调方法(代表框架:BlockCanary)
1.1.1原理简介:
核心原理就是利用Looper中的回调,去判断每一个Message中任务的执行时间。如果我们注册的是回调对象是主线程Looper,那么我们就可以知道每个任务在主线程中的执行时间。而如果某个任务执行时间过长,那么就会造成卡顿问题。
所以从严格意义上讲,这种方案应该是属于检测主线程是否卡顿,而不是界面是否绘制流畅的。
具体原理这里就不详细讲了,如果想知道原理的,可以参见我另外一篇文章的第7章:
android源码学习-Handler机制及其六个核心点_分享+记录-CSDN博客
1.1.2如何使用:
BlockCanary中有比较详细的方法方式,链接如下:
GitHub - markzhai/AndroidPerformanceMonitor: A transparent ui-block detection library for Android. (known as BlockCanary)
我这里提供一种简单版的使用方式,效果基本差不多,代码如下:
public class ANRMonitor extends BaseMonitor {
final static String TAG = "anr";
public static void init(Context context) {
if (true) {
return;
}
ANRMonitor anrMonitor = new ANRMonitor();
anrMonitor.start(context);
Log.i(TAG, "ANRMonitor init");
}
private void start(Context context) {
Looper mainLooper = Looper.getMainLooper();
mainLooper.setMessageLogging(printer);
HandlerThread handlerThread = new HandlerThread(ANRMonitor.class.getSimpleName());
handlerThread.start();
//时间较长,则记录堆栈
threadHandler = new Handler(handlerThread.getLooper());
}
private long lastFrameTime = 0L;
private Handler threadHandler;
private long mSampleInterval = 40;
private Printer printer = new Printer() {
@Override
public void println(String it) {
long currentTimeMillis = System.currentTimeMillis();
//其实这里应该是一一对应判断的,但是由于是运行主线程中,所以Dispatching之后一定是Finished,依次执行
if (it.contains("Dispatching")) {
lastFrameTime = currentTimeMillis;
//开始进行记录
return;
}
if (it.contains("Finished")) {
long useTime = currentTimeMillis - lastFrameTime;
//记录时间
if (useTime > 20) {
//todo 这里超过20毫秒卡顿了
Log.i(TAG, "ANR:" + it + ", useTime:" + useTime);
}
threadHandler.removeCallbacks(mRunnable);
}
}
};
private Runnable mRunnable = new Runnable() {
@Override
public void run() {
threadHandler.postDelayed(mRunnable, mSampleInterval);
}
};
}
1.1.3 结论:
通过这种方式,我们可以得到每个主线程任务的执行时间,按照标准16ms刷新一次的话,那么每个主线程任务不应该超过16ms,否则就意味着造成了界面的卡顿。
1.2 第二代方案:Choreographer注册渲染回调(代表框架:腾讯GT)
第一代方案的缺陷就是识别的是主线程卡顿,这个主线程卡顿并不一定会造成用户感知上的卡顿。比如用户停在某个页面没有操作,这时候主线程就算阻塞住了,用户也不会有所感觉。我们想要的界面绘制卡顿,更应该偏向整个绘制的流程。
1.2.1原理简介:
View绘制的整个流程,首先是从子向父级层层通知,最上层是ViewRootImpl。通知到ViewRootImpl后,它会创建一个界面绘制消息,然后向Choreographer进行注册。Choreographer会通过native机制来尽量保证16ms回调一次,回调之后就会执行界面绘制的流程。
核心点就在回调这里,回调通知的是doFrame方法进行界面绘制,doFrame中又有四个回调,其中CALLBACK_TRAVERSAL就是真正通知去执行整个绘制流程的。
try {
Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Choreographer#doFrame");
AnimationUtils.lockAnimationClock(frameTimeNanos / TimeUtils.NANOS_PER_MS);
mFrameInfo.markInputHandlingStart();
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
mFrameInfo.markAnimationsStart();
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);//这里是核心
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
} finally {
AnimationUtils.unlockAnimationClock();
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
所以我们可以针对其他三个做一点手脚,比如我们可以注册CALLBACK_ANIMATION的回调。这样如果CALLBACK_ANIMATION回调是以16ms定时回调通知的话,就可以证明CALLBACK_ANIMATION同样是按照16ms的刷新速度收到了的回调通知。
我的另一篇文章里面有较详细的介绍,有兴趣的可以看下:
android源码学习-View绘制流程_分享+记录-CSDN博客
1.2.2 如何使用:我们可以实现一个FPSFrameCallBacl的类,然后向
public class FPSFrameCallback implements Choreographer.FrameCallback {
private static final String TAG = "FPS_TEST";
private long mLastFrameTimeNanos = 0;
private long mFrameIntervalNanos;
public FPSFrameCallback(long lastFrameTimeNanos) {
mLastFrameTimeNanos = lastFrameTimeNanos;
mFrameIntervalNanos = (long)(1000000000 / 60.0);
}
@Override
public void doFrame(long frameTimeNanos) {
//初始化时间
if (mLastFrameTimeNanos == 0) {
mLastFrameTimeNanos = frameTimeNanos;
}
final long jitterNanos = frameTimeNanos - mLastFrameTimeNanos;
if (jitterNanos >= mFrameIntervalNanos) {
final long skippedFrames = jitterNanos / mFrameIntervalNanos;
if(skippedFrames>30){
Log.i(TAG, "Skipped " + skippedFrames + " frames! "
+ "The application may be doing too much work on its main thread.");
}
}
mLastFrameTimeNanos=frameTimeNanos;
//注册下一帧回调
Choreographer.getInstance().postFrameCallback(this);
}
}
注册代码:
Choreographer.getInstance().postFrameCallback(new FPSFrameCallback(System.nanoTime()));1.2.3 结论:
第二代方案,已经很好的满足了我们只针对界面绘制是否流畅来做评估的需求。但是也存一些问题,比如数据不直观,使用了动画的回调有可能会影响动画的绘制流程等等。
1.3第三代方案:Window注册渲染回调
前面两代都是开发者自己研究出来的,第三代则是谷歌官方产品,所以也是最权威,数据最直观最全的一种方案。
1.3.1 原理简介:
我们最终的渲染都会由ViewRootImpl转换为一个个的渲染任务Renderer,向native层注册回调,获取丢帧数。
具体详细原理以后单独写一章来讲解。
1.3.2 如何使用:
getWindow().addOnFrameMetricsAvailableListener(new Window.OnFrameMetricsAvailableListener() {
@Override
public void onFrameMetricsAvailable(Window window, FrameMetrics frameMetrics, int dropCountSinceLastInvocation) {
}
});1.3.3 结论:
第三代的方案,已经很完美的帮助我们判断是否卡顿,但是并不能帮助我们直接找到出问题的原因,所以这需要我们用各种手段来排查了。
二、排查界面卡顿的手段
2.1卡顿原因:
卡顿以我的观点主要分为三类,
第一类是CPU问题,比如运算量过大导致CPU过载,从而无法进行正常的计算。
第二类是GC问题,虚拟机频繁GC时,会暂停掉主线程的任务。
第三类是主线程阻塞的问题。比如我们主线程进行耗时操作,或者加了不恰当的锁,甚至有可能就是布局复杂或者嵌套层级太多。
2.2 方案一:
针对问题一,我们可以使用perfdog等工具,看一下CPU负载率。
2.3 方案二:
针对问题二,现有网上此类的文章太多了,主流都是这一种,所以我这里就不展开了。
读者可以自行百度
2.4 方案三:
针对问题三,往往才是真正导致界面绘制卡顿的原因。所以这才是我们要解决的重点。我这里采用的方案是上面1.1介绍的Looper回调的方案。
既然我们可以通过回调,知道每个主线程的任务执行时间。那么我们在这段时间里面开启一个新的线程,不断的去dump主线程的堆栈状态,就可以知道主线程被阻塞到了哪里。
举个例子,我在主线程读一个文件,需要100毫秒。那么我每隔20毫秒捕获一下主线程的堆栈,这个主线程堆栈读取文件的代码堆栈,就至少会被捕获5次,那么我们就可以知道,这里段代码是有问题的。
再举一个例子,一个RecyclerView在一个界面加载几百个itemView。刚进入界面的时候大概率会卡顿,这时候我们会发现,大多数的代码堆栈,打印的都是onCreateViewHolder()这个方法,虽然每次执行onCreateViewHolder方法的时间不会超过20毫秒,但是调用的频繁,则出现的概率就会高。我们就会知道是由于频繁创建ViewHolder导致的。
下面我写的简单排查卡顿问题的工具类代码:
public class ANRMonitor extends BaseMonitor {
final static String TAG = "anr";
public static void init(Context context) {
//开关
if (true){
return;
}
ANRMonitor anrMonitor = new ANRMonitor();
anrMonitor.start(context);
Log.i(TAG, "ANRMonitor init");
}
private void start(Context context) {
Looper mainLooper = Looper.getMainLooper();
mainLooper.setMessageLogging(printer);
HandlerThread handlerThread = new HandlerThread(ANRMonitor.class.getSimpleName());
handlerThread.start();
//时间较长,则记录堆栈
threadHandler = new Handler(handlerThread.getLooper());
mCurrentThread = Thread.currentThread();
}
private long lastFrameTime = 0L;
private Handler threadHandler;
private long mSampleInterval = 40;
private Thread mCurrentThread;//主线程
private final Map mStackMap = new HashMap<>();
private Printer printer = new Printer() {
@Override
public void println(String it) {
long currentTimeMillis = System.currentTimeMillis();
//其实这里应该是一一对应判断的,但是由于是运行主线程中,所以Dispatching之后一定是Finished,依次执行
if (it.contains("Dispatching")) {
lastFrameTime = currentTimeMillis;
//开始进行记录
threadHandler.postDelayed(mRunnable, mSampleInterval);
synchronized (mStackMap) {
mStackMap.clear();
}
return;
}
if (it.contains("Finished")) {
long useTime = currentTimeMillis - lastFrameTime;
//记录时间
if (useTime > 20) {
//todo 要判断哪里耗时操作导致的
Log.i(TAG, "ANR:" + it + ", useTime:" + useTime);
//大于100毫秒,则打印出来卡顿日志
if (useTime > 100) {
synchronized (mStackMap) {
Log.i(TAG, "mStackMap.size:" + mStackMap.size());
for (String key : mStackMap.keySet()) {
Log.i(TAG, "key:" + key + ",state:" + mStackMap.get(key));
}
mStackMap.clear();
}
}
}
threadHandler.removeCallbacks(mRunnable);
}
}
};
private Runnable mRunnable = new Runnable() {
@Override
public void run() {
doSample();
threadHandler
.postDelayed(mRunnable, mSampleInterval);
}
};
protected void doSample() {
StringBuilder stringBuilder = new StringBuilder();
for (StackTraceElement stackTraceElement : mCurrentThread.getStackTrace()) {
stringBuilder
.append(stackTraceElement.toString())
.append("\n");
}
synchronized (mStackMap) {
mStackMap.put(mStackMap.size() + "", stringBuilder.toString());
}
}
}
三、解决界面卡顿实战案例
3.1 案例1.通过算法优化解决CPU高频计算
需求和问题场景:
页面上的数据不断通过蓝牙接收,结合本地数据库中查询到的解释,最终拼接为最终的Model进行渲染。发现刷新频率并未达到想象中的速度,并且不跟手。
排查过程:
通过2.4中的工具,发现主线程并没有阻塞。但是滑动操作就是感觉有些许卡顿,不顺手。通过perdog,发现CPU使用率很高。所以初步怀疑是进行复杂运算导致,于是排查代码,发现有双层for循环并且集合数据量大的地方。
解决方案:
1.方案一,优化算法
如下为老的代码结构,输入1000个值,从10W条数据中匹配合适的value,然后取前100个。
private List show() {
List list = new ArrayList<>();//长度10W
List input = new ArrayList<>();//长度1000
List showList = new ArrayList<>();
for (String key : input) {
for (Model model : list) {
if (model.name.equals(key)) {
showList.add(model.value);
}
}
}
return showList.subList(0, 100);
} 则我们首先要把较长的list转换为map,然后取100个之后就跳出循环。则计算效率大幅提升。
优化后代码如下:
//优化后代码
private List show2() {
List list = new ArrayList<>();//长度10W
List input = new ArrayList<>();//长度1000
Map cache = new HashMap<>();
for (Model model : list) {
cache.put(model.name, model);
}
List showList = new ArrayList<>();
for (int i = 0; i < Math.min(input.size(), 100); i++) {
Model model = cache.get(input.get(i));
showList.add(model.value);
}
return showList.subList(0, 100);
} 2.方案二,转JNI实现或尽量位运算
某些如果代码算法本身已经没有优化空间,并且业务运算较多,最终输出值不的多,可以考虑转JNI实现或者转换为位运算,提高效率,这里就不举例了。
3.2 案例2.主线程阻塞问题
需求和问题场景:
进入到一个页面,发现每次进入时都会有明显的卡顿感。
排查过程:
通过2.4中的工具,发现日志中有一个代码堆栈大量出现,则所以怀疑是这里出的问题。最终定位下来,就是主线程IO操作导致。
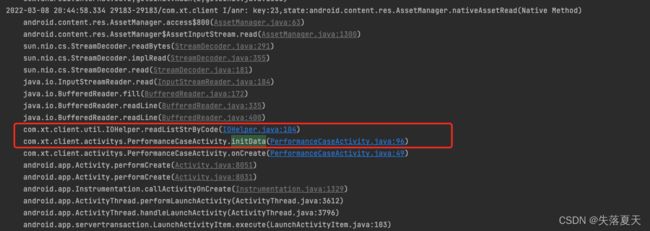
解决方案:
1.方案一,异步加载
IO是耗时操作,则使用线程去读取,读取完成后通知主线成刷新UI:
//3.2案例 优化代码
new Thread(() -> {
String s = "";
try {
InputStream is = getAssets().open("content.txt");
List strings = IOHelper.readListStrByCode(is, "utf-8");
s = strings.get(0);
} catch (IOException e) {
Log.i("lxltest", e.getMessage());
e.printStackTrace();
}
String show = s;
handler.post(() -> title.setText(show));
}).start(); PS:为了代码简洁直观,就不用使用线程池了,后续场景也是。
完整示例代码链接
android_all_demo/PerformanceCaseActivity.java at master · aa5279aa/android_all_demo · GitHub
3.3 案例3.解决RecyclerView高频刷新问题
需求和问题场景:
需求很简单,类似于看股票价格一样,每隔100毫秒请求一次服务,然后取返回的数据展示给用户。
简单代码如下:
RecyclerView recyclerView;
ModelAdapter adapter;
boolean flag = true;
Handler handler = new Handler();
@RequiresApi(api = Build.VERSION_CODES.N)
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_recycler);
recyclerView = findViewById(R.id.recycler_view);
new Thread(() -> {
while (flag) {
List> data = getResponse();
notifyData(data);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
private void notifyData(List> data) {
handler.post(() -> {
adapter.data = data;
adapter.notifyDataSetChanged();
});
} 但是我们在实际运行中发现,这种场景下上下滑动滑动是有卡顿的。
排查过程:
首先,我们使用文章2.4中提供的工具去扫描,发现有出现了大量的如下图所示的堆栈:
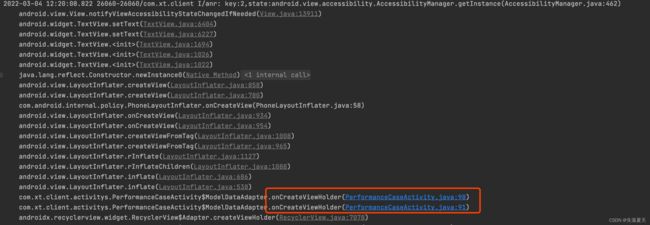
所以我们知道了问题的原因,就是频繁创建ViewHolder导致的卡顿。那为什么会频繁创建ViewHolder呢?带着这个疑问,我们深入RcyclerView的源码,终于知道了原因。每次调用notifyDataSetChanged()方法的时候,都会触发一个回收操作。由于RecyclerBin中默认缓存的数量是5,而我们一页却展示了15条数据,所以,这15个ItemView有10个是被释放掉了。
解决方案:
1.方案一:改大缓存
如下操作,改大缓存数量,问题解决。
recyclerView.getRecycledViewPool().setMaxRecycledViews(0,15);2.方案二:优化算法
当然,我们也可以通过数据层面去解决,服务返回的数据,结合现有的数据计算,计算哪些数据发生了变化,只更新那些发生了变化的数据。
完整示例代码链接
android_all_demo/PerformanceCaseActivity.java at master · aa5279aa/android_all_demo · GitHub
3.4 案例4.复杂页面首次进入卡顿
需求和问题场景:
一个页面元素特别多,并且界面复杂的界面,我们首次点击进入的时候,发现点击之后会过1-2秒之后再会进入,给人明显不跟手的感觉。
排查过程:
还是通过ANRMonitor的工具,我们通过log进行分析,看看到底是什么原因导致的。
最终我们发现,日志里面,耗时最多的堆栈是打印到了setContentView方法。那么就说明,是创建布局耗时了。
解决方案:
1.方案一,预加载
一般来说,复杂页面不会是闪屏页面。所以我们可以在进入到复杂页面之前,预先使用预加载把xml转换成View。复杂页面onCreate的时候,判断缓存中是否存在对应的View,如果存在则使用缓存中的,不存在则创建。
添加缓存:
private var cacheMap = HashMap()
fun addCachePageView(pageClassName: String, layoutId: Int) {
if (cacheMap[pageClassName] != null) {
return
}
val context = DemoApplication.getInstance()
val inflate = View.inflate(context, layoutId, null)
inflate.measure(1, 1)
cacheMap[pageClassName] = inflate
} 使用缓存:
View cachePageView = PageViewCache.Companion.getInstance().getCachePageView(PrepareMiddleActivity.class.getName());
if (cachePageView != null) {
setContentView(cachePageView);
} else {
setContentView(R.layout.prepare_middle_page);
}完整示例代码链接https://github.com/aa5279aa/android_all_demo/blob/master/DemoClient/app/src/main/java/com/xt/client/activitys/PrepareActivity.kt
3.5 案例5.解决高频率波形图的刷新
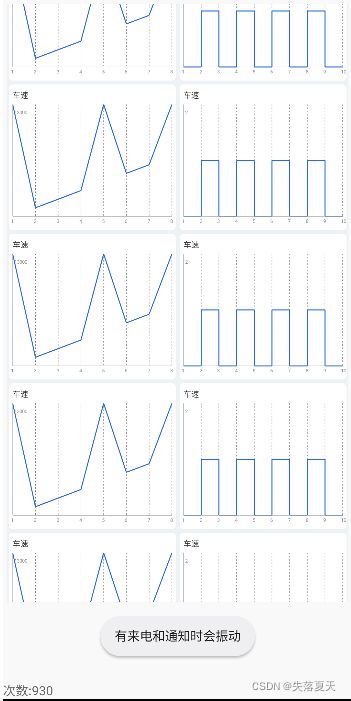
需求和问题场景:
效果图如下图所示,每个波形图的刷新频率要达到1秒10次以上。
这时候我们发现虽然我们按照1秒10次的方式去通知刷新,但是实际上,一秒钟只能刷新2到3次。
排查过程:
使用2.4提供的工具,发现之所以卡顿,主要有两块时间消耗比较大:
1.每个图形的数据坐标计算,
2.measurce,layout等流程。
解决方案:
1.方案一,数据和渲染脱钩
我们可以开启一个线程,专门进行坐标计算,把计算好的数据放到缓存中。
主线程中,定时每隔100毫秒从缓存中获取计算好的数据直接渲染。这样数据就和渲染脱钩了。
2.转surfaceView实现
由于本身就是自定义View,所以也可以转SurfaceView实现,充分利用GPU性能。
完整示例代码链接
这一块代码因未脱密,暂未能开源,提供部分实例代码供参考:
public class DataSurfaceView extends SurfaceView implements SurfaceHolder.Callback {
...省略代码
/**
* 绘制方波图和波形图
*/
protected void drawArc(Canvas canvas) {
//长度不对等或者没有初始化,则不绘制
if (mShowPointList.length != mSettings.length || !isInit) {
return;
}
// canvas.save();
float startX = mMargin;
float startY = mMargin - mOffset;
RectF rectF;
for (int index = 0; index < mShowPointList.length; index++) {
List integers = mShowPointList[index];
ShowPointSetting setting = mSettings[index];
int count = integers.size();
if (setting.showType == ShowConstant.ShowTypeWave) {
count--;
}
float itemWidth = itemCoordWidth / count;//每一个的宽度
//绘制背景 mBgPaint
rectF = new RectF(startX, startY, startX + itemViewWidth - mMargin * 2, startY + itemViewHeight - mMargin * 2);
if (mIndex == index) {
canvas.drawRoundRect(rectF, mItemRound, mItemRound, mBgClickPaint);
} else {
canvas.drawRoundRect(rectF, mItemRound, mItemRound, mBgPaint);
}
float itemX = startX + mItemPadding;
float itemY = startY + mItemPadding;
float nextY = 0;
float[] pts = new float[integers.size() * 8 - 4];
for (int innerIndex = 0; innerIndex < count; innerIndex++) {
Integer value = integers.get(innerIndex);
if (value != null) {
value = value > setting.showMaxValue ? setting.showMaxValue : value;
itemY = startY + mItemPadding + mItemTopHeight + itemCoordHeight - itemCoordHeight * value / setting.showMaxValue;
if (setting.showType == ShowConstant.ShowTypeSquare) {
pts[innerIndex * 8 + 0] = itemX;
pts[innerIndex * 8 + 1] = itemY;
pts[innerIndex * 8 + 2] = itemX + itemWidth;
pts[innerIndex * 8 + 3] = itemY;
}
}
itemX = itemX + itemWidth;
//方形图逻辑
if (setting.showType == ShowConstant.ShowTypeSquare) {
if (innerIndex != count - 1) {
Integer nextValue = integers.get(innerIndex + 1);
if (value != null && nextValue != null) {
nextValue = nextValue > setting.showMaxValue ? setting.showMaxValue : nextValue;
nextY = startY + mItemPadding + mItemTopHeight + itemCoordHeight - itemCoordHeight * nextValue / setting.showMaxValue;
pts[innerIndex * 8 + 4] = itemX;
pts[innerIndex * 8 + 5] = itemY;
pts[innerIndex * 8 + 6] = itemX;
pts[innerIndex * 8 + 7] = nextY;
}
} else {
//绘制坐标
canvas.drawText(String.valueOf(innerIndex + 2), itemX - 5, startY + mItemPadding + mItemTopHeight + itemCoordHeight + 20, mFontPaint);
}
} else if ((setting.showType == ShowConstant.ShowTypeWave)) {
if (value != null && integers.get(innerIndex + 1) != null) {
nextY = startY + mItemPadding + mItemTopHeight + itemCoordHeight - itemCoordHeight * integers.get(innerIndex + 1) / setting.showMaxValue;
pts[innerIndex * 8 + 4] = itemX - itemWidth;
pts[innerIndex * 8 + 5] = itemY;
pts[innerIndex * 8 + 6] = itemX;
pts[innerIndex * 8 + 7] = nextY;
}
if (innerIndex == count - 1) {
//绘制坐标
canvas.drawText(String.valueOf(innerIndex + 2), itemX - 5, startY + mItemPadding + mItemTopHeight + itemCoordHeight + 20, mFontPaint);
}
}
//绘制坐标
canvas.drawText(String.valueOf(innerIndex + 1), itemX - itemWidth - 5, startY + mItemPadding + mItemTopHeight + itemCoordHeight + 20, mFontPaint);
// mWaveShadowPaint.set
//渐变色
// canvas.drawRect(itemX - itemWidth, itemY, itemX, startY + mItemPadding + mItemTopHeight + itemCoordHeight, mWaveShadowPaint);
//绘制虚线
canvas.drawLine(itemX, startY + mItemPadding + mItemTopHeight, itemX, startY + mItemPadding + mItemTopHeight + itemCoordHeight, mEffectPaint);
}
//绘制最大值
if (!StringUtil.emptyOrNull(setting.showMaxValueShow)) {
canvas.drawText(setting.showMaxValueShow, startX + mItemPadding + 5, startY + mItemPadding + mItemTopHeight + 30, mFontPaint);//ok
}
//todo 绘制描述
canvas.drawText(setting.showDesc, startX + mItemPadding, startY + mItemPadding + 30, mDescPaint);
//todo 描述当前值
String currentStr = String.valueOf(mCurrents[index]);
float v = mCurrentPaint.measureText(currentStr);
canvas.drawText(currentStr, startX + mItemPadding + itemCoordWidth - v, startY + mItemPadding + 30, mCurrentPaint);
//绘制方形图的线
canvas.drawLines(pts, mWavePaint);
if (index % mAttr.widthCount == (mAttr.widthCount - 1)) {
startX = mMargin;
startY += itemViewHeight;
} else {
startX += itemViewWidth;
}
}
// canvas.restore();
}
} 3.6 案例6.一屏加载几百条数据的页面优化
需求和问题场景:
有的场景下,我们一个页面就是要加载大量的数据给用户看。如下图所示,一屏显示了大量的数据。原来是使用RecyclerView实现的,我们发现,每次进入到这个页面的都是,都要卡顿2-3S的时间才会进入。如下图所示:

排查过程:
同样是用检测工具来检查,我们发现大多数的耗时堆栈,都显示是onCreateViewHolder这个方法。一平米几百个itemView,就需要创建几百个ItemView,自然是耗时操作。当然,并不仅仅只是创建itemView耗时,几百个itemView都需要各自执行measure,layout,draw等方法,耗时也是相当巨大的。
解决方案:
方案一,自定义View
创建几百个View,渲染几百个肯定是耗时的。能否我们只创建一个,渲染一个,就显示所有数据呢。当然可以,方案就自定义View。
在自定义View中,我们可以分别计算每个Item数据的位置,是用canvas直接进行绘制。这样就只需要创建一个布局,measure/layout/draw各自只执行一遍。实践下来,果然效率大幅提升。
完整示例代码链接:
具体的自定义View的代码就不贴了,可以参考我的一个开源项目,里面会有更为详细的功能实现。
GitHub - September26/ExcelView: android项目,仿照WPS中excel的功能进行的实现,并进行进一步的功能扩展。
3.7 案例7.复杂长屏页面的优化
需求和问题场景:
一个内容复杂的页面,首先外层是RecyclerView,包含若干个模块。每个模块中又有RecyclerView包含若干个最终的控件。
首先,使用的是瀑布流式的布局方式,所以最终控件的变化会影响到整体模块的布局。
最终我们发现,数据频繁变化进行频繁刷新的时候,页面不流畅,有明显的卡顿感。
排查过程:
同样的,我们使用检测工具检测的时候,发现大多数的堆栈,都是打印到了notify的流程当中。所以我们可以简单推断,由于调用了太多的notifyChanged导致的卡顿。
解决方案:
那么如何减少notifyChanged的次数呢?技术上好像没有什么可优化的点,除非全部使用自定义view实现,但是那样的话开发成本太高了。
方案一,数据变化才通知
我们可以通过新旧数据做对比,知道那些发生变化的数据,并且只对这些数据进行通知刷新。
方案二,分级别刷新
两级RecyclerView,如果可以的话,自然要刷新实现最小颗粒度。我们可以把数据的变化分为两种。一种是会导致模块高度发生变化的,一种是影响范围只是自身这一行的。
对于第一种,我可以调用使用外层RecyclerView所对应的adapter通知刷新。
mRecyclerViewAdapt.data[positionMajor].items.clear()
mRecyclerViewAdapt.data[positionMajor].items.addAll(arrayList)
mRecyclerViewAdapt.notifyItemChanged(positionMajor)第二种,我们只需要获取内层RecyclerView所对应的adapter通知刷新即可。
val recyclerView: RecyclerView = mRecyclerViewAdapt.getViewByPosition(positionMajor, R.id.recycler_view) as RecyclerView
val adapter = recyclerView.getTag(R.id.tag_adapter) //as GasWidgetDashboard.MultipleItemQuickAdapter
when (adapter) {
is GasWidgetDashboard.MultipleItemQuickAdapter -> adapter.notifyItemChanged(positionMinor)
is GasWidgetForm.QuickAdapter -> adapter.notifyItemChanged(positionMinor)
}四、总结
4.1.先找原因在去解决
界面性能优化多种多样,但最重要的还是找到问题的原因。然后根据原因再去讨论如何解决性能上的问题。一味的照搬各种优化模式,是行不通的。比如明明是一个主线程IO操作导致卡顿,却一味的进行内存方面的优化,那自然是无法解决问题的。
4.2.界面性能优化必背知识点
想要比较完美的解决界面性能问题,还是要有一定的知识储备的,有了这些知识储备,可以快速的帮我们排查到问题点,并且相处合理的解决方案。
4.2.1 了解Handler机制
这样可以帮助我们进行主线程卡顿的排查。
4.2.2 View的整个绘制流程也需要清楚
从改变数据发出通知,到每个子View进行measure等操作。
4.3.3 常用的ViewGroup级别的容器实现原理要掌握
这一类的容器比如RecyclerView,RelativeLayout,ConstraintLayout等等。
4.3.4 最后也需要一定的抽象和逻辑思维能力。
上面举例的那些自定义View,都需要一定的抽象能力和逻辑思维能力才能知道如何去实现。
以上是我的个人建议,有兴趣的可以针对性的准备一下。
五、备注
5.1 声明
由于本文当中优化的方案是基于公司现有项目进行的,为避免敏感内容外泄,所以相关代码和图例均使用demo进行演示,导致某些界面有些丑陋,尽请谅解。
5.2 本文涉及到项目地址
https://github.com/sollyu/3a5fcd5eeeb90696
https://github.com/aa5279aa/android_all_demo
https://github.com/aa5279aa/CommonLibs
5.3 本文引用的参考资料链接:
android源码学习-Handler机制及其六个核心点_分享+记录-CSDN博客
5.4 鸣谢
感谢
@sollyu (sollyu) · GitHub
对本文创作的支持。
作者GitHub:@ https://github.com/aa5279aa/