这篇文章主要介绍 Z. Dai 等人的论文 CoAtNet: Marrying Convolution and Attention for All Data Sizes。(2021 年)。
2021 年 9 月 15 日,一种新的架构在 ImageNet 竞赛中的实现了最先进的性能 (SOTA)。CoAtNet(发音为“coat”net)在庞大的 JFT-3B 数据集上实现了 90.88% 的 top-1 准确率。CoAtNet 在使用(相对)较差的数据集 ImageNet-21K(13M 图像)进行预训练时,达到了 88.56% 的 top-1 准确率。
CoAtNet 中的“coat”来源于卷积和自注意力。我一直在努力弄清楚这件“外套”可能象征着什么,但还没有找到解决办法。不过这是一个非常合适的首字母缩略词。
CoAtNet 同时利用了卷积神经网络 (CNN) 和 Transformer 的超强能力,基于 MBConv 块和相对自注意力将平移同变性(translation equivariance)、输入自适应加权(input-adaptive Weighting)和全局感受野(Global Receptive Field)融合在一起,构建了一个强大的新架构家族。
Convolution的简单介绍和MBConv块
在深入研究 CoAtNet 的架构之前,首先对 CNN 做一个简单的介绍,如果你熟悉这部分可以跳过。CNN 源于 1980 年代对大脑视觉皮层的研究,由两位诺贝尔奖获得者 David Hubel 和 Torsten Wiesel 进行。这两位科学家表明,神经元的局部感受野很小,它们只对视野的特定区域做出反应,并且这些不同的区域可能会重叠。此外一些神经元只对特定模式(即水平线)作出反应,而一些神经元对特定复杂模式作出反应而这些复杂模式是低级模式的组合。受到这些想法的启发,1998 年Yann LeCun 引入了 LeNet 架构,该架构首次利用了卷积层和池化层。刚开始并未收到很大的关注,但是在几年之后AlexNet 的出现让CNN在 ImageNet 比赛中的获得了亮眼的表现。并且随着计算能力的提高使得CNN有了更大的发展,计算机视觉研究的很大一部分转向了 CNN,并且多年来引入了几个网络,例如 VGG、ResNet、Inception、EfficientNet、MobileNet 等。
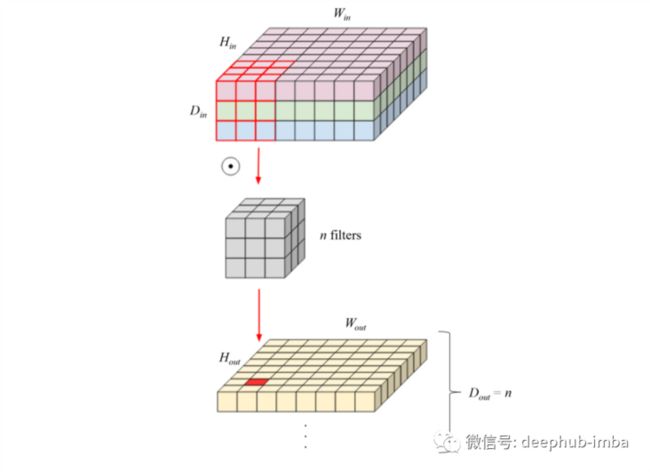
CNN 的基本块是卷积层。在卷积层中神经元并不连接到其输入图像中的每个像素,而只是连接到其感受野中的像素。在训练期间,使用在图像上卷积的可学习滤波器或核。每个过滤器都学习识别特定模式,而低级过滤器为更复杂的模式提供底层的支持。给定一张 224 × 224 × 3 的 RGB 图像,使用具有 3 个 3 × 3 × 3 过滤器的卷积层。这意味着在图像上滑动 n 个过滤器中的每一个并执行卷积操作,如下图所示。卷积的结果堆叠在一起形成 Hₒᵤₜ × Wₒᵤₜ × n 输出。输出的宽度 Wₒᵤₜ 和高度 Hₒᵤₜ 取决于核大小和步长(内核步长在图像上移动时的大小)和填充(如何处理图像的边界)的值。
Depthwise Separable Convolution 深度可分离卷积
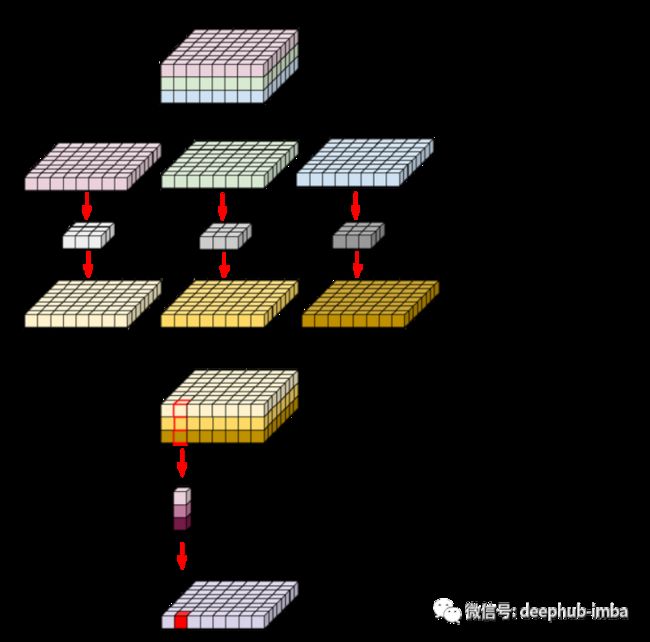
正常卷积可能需要大量的计算工作。出于这个原因,谷歌的人(总是他们)在他们的 MobileNet 架构中引入了深度可分离卷积。这种类型的卷积将过程分为两个步骤:第一个深度卷积,然后是逐点卷积。最终输出与经典卷积的输出具有相同的大小,但由于 1 × 1 卷积,需要的计算量要少得多。
在第二个版本 MobileNetv2 中,同一作者介绍了关于深度可分离卷积的两个主要思想:
Inverted residuals:这种技术允许较低层通过跳过连接访问前一层的信息。第一步使用 1 × 1 卷积扩展输入,因为随后的深度卷积已经大大减少了参数的数量。后面的1 × 1 卷积执行压缩,以匹配初始通道数。这种残差连接所连接的是狭窄的层,而不是原始残余块的宽层,所以被命名为Inverted (反向/倒置)。
Linear Bottleneck:使用上面的倒置残差块,是可以压缩跳过连接链接的层加快计算速度,但这会损害网络的性能。所以作者引入了线性瓶颈的想法,其中残差块的最后一个卷积在添加到初始激活之前会包含一个线性输出。

这就是MobileNetv2 中的MBConv块也是CoAtNet的基本块(扩展率为 4 )。除了效率之外,使用这个模块的另一个原因是相同的扩展和缩减概念也用于 Transformers 的前馈网络(FFN)模块。
self-attention简单介绍和理解Vision Transformer
Transformer是在论文 Attention Is All You Need 中首次介绍的。这些架构基于学习序列元素之间关系的自注意力机制。
具体来说,Transformer 的 Encoder 架构如下图所示(解码部分不涉及,与本文目的无关)。在输入嵌入中输入被标记化,每个标记映射到词汇表中的一个整数,然后每个整数映射到模型将在训练期间学习的 k 维向量,下一步是添加基于正弦函数的位置编码来处理句子中的词序。最后通过 Nₓ 个添加了多头自注意力和前馈网络、残差连接和层归一化层的块得到输出。

多头注意力块使用不同的权重矩阵多次计算自注意力,然后将结果连接在一起,使用另一个可训练矩阵将其大小调整为嵌入维度,这样可以输出与输入大小相同的向量,并其传递到下一个块。每个嵌入必须具有三个关联的表示,查询 (Q)、键 (K) 和值 (V),它们是通过将输入乘以三个可训练的权重矩阵获得的。直观地说,Q 是当前单词的表示,用于对所有其他单词进行评分(我们只关心正在处理的查询)。K 就像我们在搜索相关词时与 Q 匹配的一堆标签。V 包含实际的单词表示。
可以把这个模块的操作想象成在档案中搜索:查询 (Q)就像主题研究的便签。键 (K) 就像文件夹的标签。当匹配时就取出该文件夹的内容,这些内容就是值 (V)向量。
计算Q和K的标量积,得到Score(S)矩阵,它表示每个key与每个query的相关程度,这个矩阵被缩放并通过一个row-wise softmax函数。计算 S 和 V 之间的标量积以获得上下文嵌入,即 自注意力矩阵。这个矩阵在通过 dropout、和残差连接和层归一化之后,被传递给 position-wise(意味着它一次需要一个token,但权重是共享的,并且不同的结果堆叠在一个矩阵中)FFN ,它首先扩展输入,然后再压缩它,这与上面的 MBConv 块的类似(这种相似性, 也是CoAtNet 的一个特点),最后通过 ReLU 激活。

这种架构的特点是:
- 可以处理完整的序列,从而学习远程关系
- 可以轻松并行化
- 可以扩展到高复杂度模型和大规模数据集。
所以在NLP 领域 Transformer 网络的发现引起了计算机视觉界的极大兴趣。视觉数据遵循典型的结构,因此需要新的网络设计和训练方案。不同的作者提出了他们自己的应用于视觉的 Transformer 模型的实现,但 SOTA 还是Vision Transformer (ViT) 。这种架构专注于图像的小块,它们被视为token。输入图像中的每个patch都使用线性投影矩阵进行展平,并向其中添加可学习的位置嵌入。这种位置嵌入是一维的,并将输入视为光栅顺序中的patch序列。在CoAtNet中patch之间的相对位置会替代绝对位置,这就是相对自注意的定义。为了进行分类,会将一个可额外学习的分类标记添加到序列中(在下图中用 * 表示)。其他部分与 ViT的编码器的原始版本相同,由多个自注意、归一化和具有残差连接的全连接层组成。在每个注意力块中,多个头可以捕获不同的连接模式。分类输出处的全连接多层感知器头提供所需的类预测。

CoAtNet
以上两个简短的介绍就是CoAtNet 架构的基础,现在我们看看怎么整合他们
混合深度卷积和自注意力
论文中提到了的 ViT 的主要限制之一是其令人印象深刻的数据需求。虽然 ViT 在庞大的 JFT300M 数据集上显示出令人兴奋的结果,但它在数据量少的情况下性能仍然不如的经典 CNN。这表明 Transformers 可能缺少 CNN 拥有的泛化能力,因此需要大量数据来弥补。但是与 CNN 相比,注意力模型具有更高的模型容量。
CoAtNet 的目标是将 CNN 和 Transformer 的优点融合到一个单一的架构中,但是混合 CNN 和 Transformer 的正确方法是什么?
第一个想法是利用已经讨论过的 MBConv 块,它采用具有倒置残差的深度卷积,这种扩展压缩方案与 Transformer 的 FFN 模块相同。除了这种相似性之外,depthwise convolution 和 self-attention 都可以表示为一个预定义的感受野中每个维度的加权值之和。其中深度卷积可以表示为:
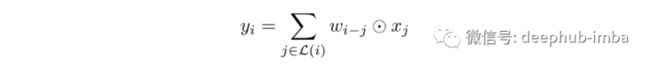
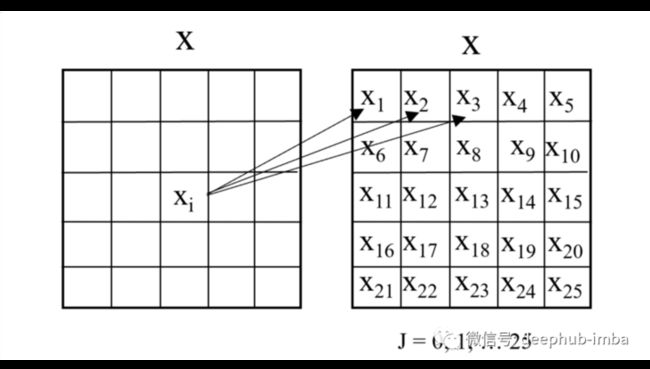
其中 xᵢ 和 yᵢ 分别是位置 i 的输入和输出, wᵢ ₋ ⱼ 是位置 (i - j) 的权重矩阵, L (i) 分别是 i. 通道的局部邻域。在下图中,显示了如何计算 yᵢ 的示例,其中 i = (3,3),对于一个通道,上述公式的结果如下:

相比之下,self-attention 允许感受野不是局部邻域,并基于成对相似性计算权重,然后是 softmax 函数:
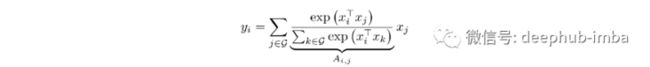
其中 G 表示全局空间,xᵢ, xⱼ 是两对(例如图像的两个patch)。为了便于理解一个简化的版本(省略了多头 Q、K 和 V 投影)如下所示:将每个patch与同一图像中的每个其他patch进行比较,以产生一个自注意力矩阵。
让我们尝试分析这两个公式的优缺点:
- Input-Adaptive Weighting:矩阵 wᵢ an 是一个与输入无关的静态值,而注意力权重 Aᵢⱼ 取决于输入的表示。这使得 self-attention 更容易捕获输入中不同元素之间的关系,但代价是在数据有限时存在过度拟合的风险。
- Translation Equivariance:卷积权重 wᵢ ⱼ ⱼ 关心的是 i 和 j 之间的相对偏移,而不是 i 和 j 的具体值。这种平移不变性可以在有限大小的数据集下提高泛化能力。
- Global Receptive Field:与 CNN 的局部感受野相比,self-attention 中使用的更大感受野提供了更多的上下文信息。
综上所述,最优架构应该是自注意力的输入+自适应加权和全局感受野特性+ CNN 的平移不变性。所以作者提出的想法是在softmax初始化之后或之前将全局静态卷积核与自适应注意力矩阵相加:

论文中使用的预归一化版本也对应于我们之前已经提到的相对自注意力的特定变体。
CoAtNet的架构设计
有了上面的理论基础,下一步就是弄清楚如何堆叠卷积和注意力块。作者决定只有在特征图小到可以处理之后才使用卷积来执行下采样和全局相对注意力操作。并且执行下采样方式也有两种 :
- 像在 ViT 模型中一样将图像划分为块,并堆叠相关的自注意力块。该模型被用作与原始 ViT 的比较。
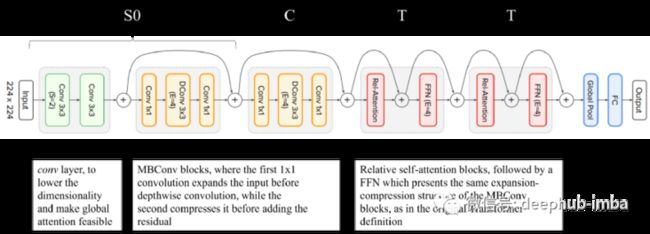
- 使用渐进池化的多阶段操作。这种方法分为5个阶段,但是前两个阶段,即经典的卷积层和用于降低维度的MBConv块。为了简单起见这里将其合并为一个阶段命名为S0。后面三个阶段可以是卷积或Transformer块,产生 4 种组合:S0-CCC、S0-CCT、S0-CTT 和 S0-TTT
这样产生的 5 个模型在泛化方面(训练损失和评估准确度之间的差距)和使用 1.3M 图像、超过 3B 图像的模型容量(拟合大型训练数据集的能力)进行了比较。
泛化能力:S0-CCC ≈ S0-CCT ≥ S0-CTT> S0-TTT ≫ ViT
模型容量:S0-CTT≈S0-TTT>ViT>S0-CCT>S0-CCC
对于泛化来说:卷积层越多,差距越小。
对于模型容量:简单地添加更多的 Transformer 块并不意味着更好的泛化。下图所示的 S0-CTT 被选为这两种功能之间的最佳折衷方案。
总结
这种配置的惊人结果在本文开头已经描述过,下面是图表的展示。

CoAtNet在 ImageNet21K 小规模数据集(左)上与 CNN 性能相当,并随着 JFT3B 数据集(右)的数据量增加而获得更加可观的收益。
这里有一个pytorch的CoAtNet实现,有兴趣的可以看看代码学习
https://www.overfit.cn/post/b59e840f6eb74bb38785a7210c1d58f5
引用:
CoAtNet: Marrying Convolution and Attention for All Data Sizes [arxiv 2106.04803v2]
Attention Is All You Need [arxiv1706.03762]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale [arxiv 2010.11929]
作者:Leonardo Tanzi