ICML2020-PowNorm:重新思考transformer中的batch-normalization

这篇论文由UCB的研究者提出,旨在研究transformer中新的正则化方法。
自然语言处理NLP中使用的神经网络模型的标准归一化方法是层归一化LN。与计算机视觉中广泛采用的批处理规范化BN不同。 LN在NLP中的首选原因主要是由于观察到使用BN会导致NLP任务的性能显着下降。本文对NLP transformer模型进行了系统研究,以了解为什么BN与LN相比性能较差。在整个训练过程中,整个批次维度上的NLP数据统计量都显示出较大的波动。如果实施BN,则会导致不稳定。为了解决这个问题,本文提出功率归一化(PN),它可以通过**(i)放松BN中的零均值归一化,(ii)结合运行的二次平均值而不是按批统计来稳定波动**,以及**(iii)使用近似反向传播,将运行统计信息并入正向传递**。从理论上讲,与BN相比,PN导致损失的Lipschitz常数更小。此外证明了近似的反向传播方案会导致有界梯度。在一系列NLP任务上对transformer的PN进行了测试,结果表明它显着优于LN和BN。特别是,在IWSLT14 / WMT14和5.6 / 3.0上,PN的性能优于LN 0.4 / 0.6 BLEU PTB / WikiText-103上的PPL。
注:所有关于引理的证明请见论文
1.引言
正则化已成为神经网络体系结构中用于各种机器学习任务的关键组件之一,尤其是在计算机视觉(CV)和自然语言处理(NLP)中。但是,目前在CV和NLP中使用的正则化形式不同。批归一化(BN)在CV中被广泛采用,但是当在NLP中使用时,它会导致明显的性能下降。取而代之的是,层归一化(LN)是NLP中使用的标准归一化方案。最近所有NLP体系结构(包括Transformer)已将LN代替BN作为其默认标准化方案。尽管如此,尚未阐明BN导致NLP失败的原因,也没有提出替代LN的更好方法。
这项工作对NLP的BN相关挑战进行了系统的研究,并在此基础上提出了功率归一化(PN),这是一种明显优于LN的新颖归一化方法。贡献如下:
1.NLP数据与CV数据的批处理统计数据存在明显差异。特别是**NLP数据的批处理统计信息在整个训练过程中差异很大。这种变化也存在于相应的梯度中。**相比之下,CV数据的方差小几个数量级。有关CV和NLP中BN的比较,请参见图2和3。
2.为了减少批次统计数据的变化,通过放宽零均值归一化来修改典型的BN,并用二次均值代替方差。将此方案称为PN-V。从理论上证明PN-V保留了BN中的一阶平滑性。参见引理2。
3.对二次均值使用运行统计数据可显着改善性能,与BN相比,IWSLT14 / WMT14上的1.5EU / BLEU和PTB / WikiText-103上的7.7 / 3.4 PPL。参见表1和2。将此方案称为PN。使用运行统计信息需要更正BN中的典型反向传播方案。作为替代方案提出一种近似反向传播来捕获运行统计数据。从理论上证明,这种近似的反向传播会导致有界梯度,这是收敛的必要条件;见定理4。
4.测试显示PN与LN相比,在机器翻译和语言建模任务方面也提高了性能。特别是,PN优于LN 0.4 / 0.6 BLEU 在IWSLT14 / WMT14上使用,在PTB / WikiText-103上使用5.6 / 3.0 PPL。与LN相比,PN的改进不会改变任何超参数。
5.通过计算所得嵌入层的奇异值分解来分析PN和LN的行为,并表明PN产生条件更好的嵌入层;参见图6。此外显示PN对小批量统计数据具有鲁棒性,并且与LN相比,它仍然可以实现更高的性能。参见图5。

图 1
2.Batch Normalization
符号 将归一化层的输入表示为 X ∈ R B × d X \in R^{B\times d} X∈RB×d,其中d是嵌入/特征尺寸,B是批处理尺寸。 将L表示为神经网络的损失函数。 矩阵的第i行(列)(例如X)用 X i , : ( X : , i ) X_{i ,:}(X:,i) Xi,:(X:,i)表示。 将矩阵的第i行写为小写形式,即 x i = X i , ; x_i =X_{i,;} xi=Xi,;。 对于向量y,yi表示y中的第i个元素。
在没有其他说明的情况下:(i)对于两个向量 x ∈ R d x \in R^{d} x∈Rd和 y ∈ R d y \in R^d y∈Rd,将xy表示为按元素乘积,将x+y表示为按元素求和,而将 < x , y >
2.1 BN的形式化
将X沿批次的平均值(方差)表示为 µ B ∈ R d µ_B\in R^d µB∈Rd(batch dimension如图1所示。)BN层首先强制执行零均值和单位方差,然后通过将结果缩放 γ , β ∈ R d γ, β\in R^d γ,β∈Rd来执行仿射变换。,如算法1所示。

算法 1
BN的前向传播(FP)如下执行。 用零均值和单位方差表示BN的中间结果为X:

最终输出的BN,Y是应用于X的仿射变换:
![]()
然后可以得出相应的后向传播(BP)如下。 假设已知L相对于Y的导数, ∂ L ∂ Y \frac{∂L}{∂Y} ∂Y∂L是已知的。 然后关于输入的导数可以计算为:

分别将 u B u_B uB和 σ B 2 \sigma^2_B σB2定义为 g u g_u gu和 g σ 2 g_{\sigma{^2}} gσ2。
总之,BN中有四个批处理统计信息,FP中有两个批处理统计信息,BP中有两个批处理统计信息。 训练的稳定性取决于这四个参数。 实际上,过分地针对transformer实施BN会导致性能下降。 例如,在IWSLT14和WMT14上,与带有LN的transformer(TransformerLN)相比,使用带有BN的transformer(表示为TransformerBN)导致BLEU得分低1.1和1.4; 参见表1。
这是显着的性能下降,源于与上述四个批处理统计信息相关的不稳定性。为了对此进行分析,使用Cifar-10上的ResNet20和IWSLT14上的TransformerBN的标准设置(分别使用128的标准批量和4K的token)研究了批次统计信息。在第一个实验中探究批处理统计信息 µ B / σ B µ_B /σ_B µB/σB和相应的BN运行统计信息µ /σ之间的波动。图2中显示了Cifar-10上ResNet20的第一个BN层和IWSLT14上的TransformerBN的第一个BN层。这里,y轴显示了批处理统计信息 ( µ B , σ B ) (µ_B,σ_B) (µB,σB)和运行统计信息(µ,σ)之间的平均欧几里得距离。x轴是不同的训练时期,将平均欧几里德距离定义为
d i s t ( u B , u ) = 1 d ∣ ∣ u B − u ∣ ∣ dist(u_B,u)=\frac{1}{d}||u_B-u|| dist(uB,u)=d1∣∣uB−u∣∣。
最初的观察结果是,与Cifar-10上的ResNet20相比,TransformerBN显示的批次统计信息与运行统计信息之间的距离明显更大,后者的波动几乎为零。重要的是,整个训练过程中 σ B σ_B σB和σ之间的距离会显着增加,但存在极端的异常值。在推断过程中必须使用运行统计信息。但是,如此大的波动将导致测试数据的统计数据与BN运行统计数据之间巨大的不一致性。
第二个来自探究 g µ g_µ gµ和 g σ 2 g_{σ^2} gσ2的范数的观察在等式3中定义。 有助于输入的梯度反向传播。这些结果显示在图3中,报告了ResNet20和TransformerBN这两个参数的范数。对于TransformerBN,可以看到非常大的异常值,这些异常值在训练过程中仍然存在。这与ResNet20相反,后者随着训练的进行离群值消失
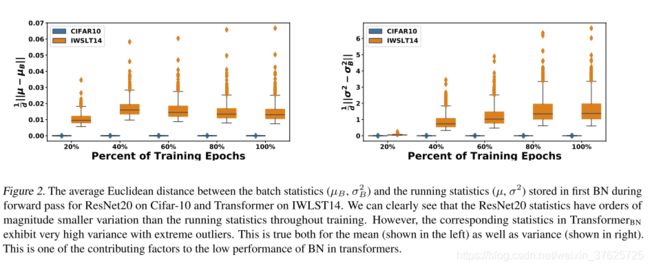
图 2
3.Power Normalization
基于经验观察提出了功率归一化(PN),可以有效解决BN的性能下降。这是通过对BN合并以下两个更改来实现的。首先,不是强制执行单位方差,而是对激活执行单位二次均值。原因是发现由于均值的较大差异,在BN中强制执行零均值和单位方差是有害的,如前部分所述。与均值/方差不同,单位二次均值对于transformer而言明显更稳定。其次结合了信号的二次方的运行统计信息,并且结合了近似反向传播方法来计算相应的梯度。即使使用相同的训练超参数,这两个变化的组合也导致归一化更有效,其结果超过LN。下面讨论这两个组件。
3.1 Relaxing Zero-Mean and Enforcing Quadratic Mean
描述PN中的第一个修改。 如图2和3所示, µ B µ_B µB和 g µ g_µ gµ表现出大量的大异常值,这导致训练与推理统计之间的不一致。 首先通过放松零均值归一化来解决这个问题,使用信号的二次均值而不是方差。 二次均值显示的波动较小,如图4所示。将此归一化(即无零均值和单位二次均值实施)称为PN-V,定义如下。

图3,4
**定义1 (PN-V)**定义批次的二次均值为 ϕ B 2 = 1 B ∑ i = 1 B x i 2 \phi_{B}^2=\frac{1}{B}\sum_{i=1}^{B}x_{i}^2 ϕB2=B1∑i=1Bxi2。更进一步,定义X为由 ϕ B \phi_B ϕB缩放的信号:
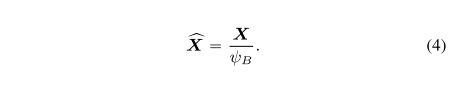
然后PN-V的输出定义为:
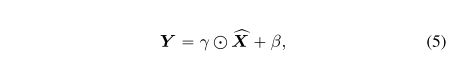
其中 γ ∈ R d \gamma \in R^d γ∈Rd和 β ∈ R d \beta \in R^d β∈Rd是PN-V的两个参数(与在BN中使用的仿射变换一样)。
注意这里使用与公式2中的输出相同的符号Y。
PN-V的相应BP如下:

其中, g ϕ 2 g_{\phi ^2} gϕ2是由属性 ϕ B 2 \phi_{B^2} ϕB2所标记的梯度。注意,与BN相比,在这里的FP和BP中只出现了两个批次统计量: g ϕ 2 g_{\phi ^2} gϕ2和 ϕ B 2 \phi_{B^2} ϕB2。
这种修改消除了对应于BN中的 µ B µ_B µB和 σ B σ_B σB的两个不稳定因素( g µ g_µ gµ,等式3中的 g σ 2 g_{σ^2} gσ2)。如表1中针对IWSLT14和WMT14所述,这种修改还可以显着提高性能。通过用PN-V(表示为TransformerPN-V)直接替换BN,BLEU分数在IWSLT14上从34.4上升到35.4,在WMT14上从28.1上升到28.5。这些改进对于这两项任务非常重要。
如前所述,与 σ B σ_B σB相比, ψ B ψ_B ψB的变化量小几个数量级。如图4所示,其中报告了σ, d i s t ( σ B 2 , σ 2 ) dist(σ^2_B,\sigma^2) dist(σB2,σ2)的运行统计之间的距离。类似地,在BP期间计算 g σ 2 g_{σ^2} gσ2和 g ψ 2 g_{ψ^2} gψ2的范数,在图4显示了整个训练过程。可以清楚地看到,在BP期间,与 g σ 2 g_{σ^2} gσ2相比, g ψ 2 g_{ψ^2} gψ2的范数表现出更少的离群值。
在(Santurkar et al 2018)中,作者提供了理论结果,表明在DNN中使用BN可以导致较小的Lipschitz常数损失。
Santurkar, S., Tsipras, D., Ilyas, A., and Madry, A. How
does batch normalization help optimization? In NeurIPS,
2018.
可以证明,PN-V也表现出类似的行为。将未经归一化的L表示为NN的损失。 (Santurkar et al 2018)表明 ∂ L ∂ x \frac{∂L}{∂x} ∂x∂L(带有BN)的范数小于 ∂ L b a r ∂ x \frac{∂Lbar}{∂x} ∂x∂Lbar的范数。 这里表明在相同的假设下,PN-V可以达到与BN相同的结果。 有关详细信息,请参见论文附录C,包括假设9的陈述。
引理 2 (PN-V对Lipschitz常数的影响损失)。 根据假设9,我们有
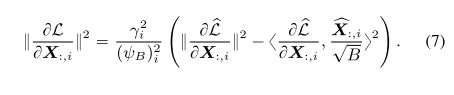
3.2 Running Statistics in Training
讨论PN中的第二种修改。 首先要注意的是,尽管TransformerPN-V的性能优于TransformerBN,但它仍然无法与LN的性能匹敌。 如图4所示,这可能与 ψ B ψ_B ψB中存在大量异常值有关。解决此问题的方法是将运行统计信息用于二次均值(表示为ψ2),而不是使用每批统计信息,因为后者在每次迭代中都会发生变化。 但是使用运行统计信息需要修改反向传播,将在下面介绍。
定义3 (PN) 用 ∗ ( t ) * ^{(t)} ∗(t)表示第t次迭代的输入/统计,例如 X ( t ) X^{(t)} X(t)是第t次迭代的输入数据。 在正向传播中,以下公式用于计算:

算法2 PN

在这里, 0 < α < 1 0<\alpha<1 0<α<1是前向传播的移动平均系数,而 ψ B ψ_B ψB是当前批次的统计量。 由于前向传播会生成运行统计信息,因此无法精确计算后向传播,即,精确的梯度计算需要追溯到第一次迭代。 在这里建议在反向传播中使用以下近似梯度:

这种反向传播实质上是通过计算损失函数的梯度来使用运行统计数据。 而不是使用计算上不可行的方法直接计算梯度的当前批次的二次平均值的运行统计信息。 重要的是,此公式会导致收敛所需的有界渐变,如下所示。

定理 4 (L w.r.t. X的梯度以PN为界)对于X的任何基准点(即 X i , : X_{i,:} Xi,:),由公式11计算出的梯度以常数为界。此外, X i , : X_{i ,:} Xi,:的梯度也有界,如给定等式 12
4 实验
4.1实验设置
将本文的PN方法与LN和BN进行比较,以完成各种序列建模任务:神经机器翻译(MT);和语言建模(LM)。使用fairseq-py来实现MT的代码,并针对LM任务来实现(Ma et al 2019)。为了公平起见,直接用BN替换了transformer(TransformerLN)中的LN(TransformerBN)或PN(TransformerPN),而无需更改每个正则化层的位置或更改训练超参数。
Ma, X., Zhang, P., Zhang, S., Duan, N., Hou, Y., Zhou,
M., and Song, D. A tensorized transformer for language
modeling. In NeurIPS, 2019.
对于所有实验,使用(Wang等人,2019)中的预正则化设置,其中正则化层位于多头注意力模块和逐点前馈网络模块之前。相对于常见的后归一化转换器,通常将学习率提高2.0倍。下面讨论任务的特定设置。
Wang, Q., Li, B., Xiao, T., Zhu, J., Li, C., Wong, D. F.,
and Chao, L. S. Learning deep transformer models for
machine translation. In ACL, 2019.
Neural Machine Translation 在两个公共数据集上评估本文的方法:IWSLT14德语到英语(De-En)和WMT14英语到德语(En-De)数据集。遵循(Ott,2018)中报告的设置。对WMT14使用大型transformer架构(450万个句子对),对IWSLT14使用小型架构transformer(16万个句子对)。为了进行推断,将最后10个检查点平均处理,然后将WMT / IWSLT的长度损失设为0.6 / 1.0,并将波束大小设为4/5,如下所示)。所有其他超参数(学习率,dropout,weight decay,预热步骤等)的设置与文献中针对LN的报告相同(即,对BN / PN使用相同的超参数)。
Ott, M., Edunov, S., Grangier, D., and Auli, M. Scaling neu-
ral machine translation. In Machine Translation, 2018.
Language Modeling 在PTB和Wikitext-103上进行实验,它们分别包含0.93M和100M tokens。对PTB使用三层张量transformer核心和六层张量transformer随后是Wikitext-103的core-1。此外将多线性注意力机制与masking一起应用,并报告最终的测试集困惑度(PPL)。
4.2 实验结果
Neural Machine Translation 使用BLEU作为MT的评估指标。按照标准惯例分别针对WMT14 En-De和IWSLT14 De-En测量标记化的区分大小写的BLEU和不区分大小写的BLEU。为了公平起见,不包括其他外部数据集。表1中的所有transformer都使用六个编码器层和六个解码器层。

表 1
结果报告在表1中。用不同类型的标准化报告结果。注意使用BN(34.4 / 28.1)时,与BLN(35.5 / 29.5)相比,BLEU分数显着下降。使用PN-V代替BN有助于缩小此差距,但LN仍然胜过。但是,与PN对应的结果比LN的结果超出0.4 / 0.6点,这对于这些任务。与DS-Init和Fixup-Init等其他并行工作相比,TransformerPN的改进仍然很重要。

表 2
Language Modeling 在这里,观察到使用BN会导致性能显着下降,对于PTB / WikiText-103数据集,测试PPL增加7.5 / 6.3以上(达到60.7 / 27.2,而不是53.2 / 20.9)。 但是,当合并PN归一化后,就可以针对这两个任务(对于这些模型大小且无需对其他数据集进行任何预训练)获得最新的结果。 特别是与LN相比,PN导致测试PPL降低5.6 / 3点。 重要的是使用PN可以达到更好的效果.
4.3 分析
The Effect of Batch Size for Different Normalization 为了更好地理解提出的方法PN和PN-V的效果,更改了用于收集BN,LN和PN中的统计信息的批次大小。为此将总批大小保持为4K tokens不变,并且将用于收集统计信息的最小批大小从512更改为4K。重要的是将批总大小保持恒定在4K,并对较小的小批量使用梯度累积。对于512的mini批处理,使用八个梯度累加。结果报告在图5中。可以观察到BN在不同的mini批次中表现不佳且异常。在放松了BN的零均值归一化并将方差估计替换为二次均值之后,PN-V与LN在4Kmini批处理中的性能相匹配,并且始终优于BN。但是它的表现不及LN。相反,在不同的小批量设置下,PN始终能获得更高的结果。

图5
Representation Power of learned Embedding 为了进一步研究PN的性能增益,计算了如(Gao et al 2019)所提出的,嵌入层的奇异值分布可以用作度量嵌入层的表示能力的代理。有人认为具有快速衰减的奇异值会导致将嵌入的表示能力限制在较小的子空间中。如果是这种情况,则最好具有更均匀的奇异值分布(Wang 2020)。计算LN和PN的词嵌入矩阵的奇异值,在图6中报告结果。与PN对应的奇异值的衰减比LN慢。对此的一种解释可能是PN通过标准化批次中的所有tokens来提供帮助。这会导致嵌入的分布更加均匀。这可能说明了PN胜过LN的原因之一。
Gao, J., He, D., Tan, X., Qin, T., Wang, L., and Liu, T.
Representation degeneration problem in training natural
language generation models. In ICLR, 2019.
Wang, L., Huang, J., Huang, K., Hu, Z., Wang, G., and Gu,
Q. Improving neural language generation with spectrum
control. In ICLR, 2020.

图 6
5 结论
这项工作系统地分析了transformer中的vanilla 批次归一化(BN)的无效性。比较NLP和CV,证明了NLP任务的transformer中的批次统计数据有较大的差异。这导致BN在transformer中的性能较差。通过将变体解耦到FP和BP计算中,提出PN-V和PN来缓解NLP中BN的变体问题。从理论和经验上体现了PN-V和PN的优势。从理论上讲,PN-V保留了BN中的一阶平滑度属性。 PN的近似反向传播导致有界渐变。从经验上讲,显示出PN在神经机器翻译(IWSLT14 / WMT14上为0.4 / 0.6 BLEU)和语言建模(PTB / WikiText-103上为5.6 / 3.0 PPL)方面的性能优于LN。对不同批次大小设置下PN-V / PN / BN / LN的影响进行了进一步分析,以显示统计估计的意义,并研究了LN / PN表示的学习嵌入矩阵的表示能力,以说明PN的有效性。
论文 https://arxiv.org/pdf/2003.07845.pdf
T14 / WMT14上为0.4 / 0.6 BLEU)和语言建模(PTB / WikiText-103上为5.6 / 3.0 PPL)方面的性能优于LN。对不同批次大小设置下PN-V / PN / BN / LN的影响进行了进一步分析,以显示统计估计的意义,并研究了LN / PN表示的学习嵌入矩阵的表示能力,以说明PN的有效性。
论文 https://arxiv.org/pdf/2003.07845.pdf
代码 https://github.com/sIncerass/powernorm
AI算法后丹修炼炉是一个由各大高校以及一线公司的算法工程师组建的算法与论文阅读分享组织。我们不定期分享最新论文,资讯,算法解析,以及开源项目介绍等。欢迎大家关注,转发,点赞。同时也欢迎大家来平台投稿,投稿请添加下方小助手微信。
QQ交流群:216912253
查看更多交流方式
微信公众号:AI算法后丹修炼炉
小助手ID:jintianandmerry
