r 函数返回多个值_R语言之数据处理(二)

我们继续来总结一下R语言数据处理的第二部分——维度处理。在R语言中,常见的多维数据的存储形式有矩阵、数据框、列表和数组等,其中向量是特殊的矩阵,矩阵是特殊的数据框,数据框又是特殊的数组。对于不同的数据形式,有对应的不同方法处理,下面会分别介绍apply类函数、dplyr拓展包、reshape2包和tidyr包中的相关函数及其运用情况。
一、apply类函数
1.apply
若想对一个数组的行或者列按指定函数去计算的话,可以使用apply(x,margin,Fun,....),其中,x为一个数据,margin可取1(按行计算)或者2(按列计算),Fun是一个函数名,表示对数据的行或列而使用的函数。下面用简单的例子说明:

2.tapply
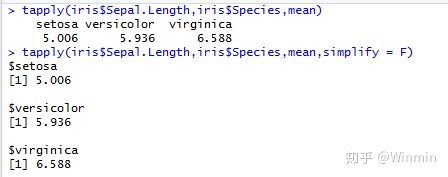
但大多数的时候,我们不会遇到这么简单的计算要求,现实更多的是分类汇总的思想。映射到R语言就是因子的概念。比如R语言中自带的iris数据集,其中的一个变量Species就是因子,因子简单理解就是分类变量,也就是我们分类汇总时参考的维度。如果想计算三种不同类型花

瓣长度的平均值,此时就需要用到tapply(x,index,Fun,...,simplify =T)。x为数组,index就是我们需要分类汇总参考的元素,Fun仍然是函数,simplify为T时,输出结果为数组,若为F时结果以list形式输出。下面看一下计算过程:
3. lapply及其变形
(1)当我们所处理的数据不是数据的时候,而是列表形式(list),可以使用lapply(),其功能与apply()相近且结果会以列表形式返回。
(2)如果想结果以矩阵或向量形式输出,则可是使用lapply的特殊版sapply(),两者的区别在于sapply中的参数simplify,当simplify=F时,sapply等价于lapply,当为F时,结果以向量或矩阵形式输出。
(3)若想控制结果输出的行名,sapply()的升级版函数vapply(),其用法与前者基本一致,其中的参数FUN.VALUE就能控制结果的行名。
(4)如果输入的列表数据中还存在列表形式的数据,此时就需要用到lapply()的升级版rapply()。其用法与lapply()用法一致,但是能够历遍输入的列表数据集中的列表数据。
二、dplyr拓展包中的常用函数
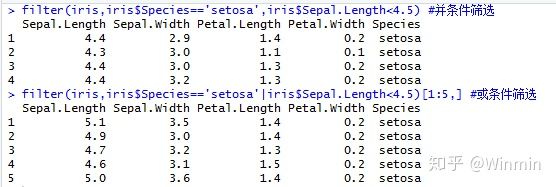
1.筛选函数filter(数据集,条件)
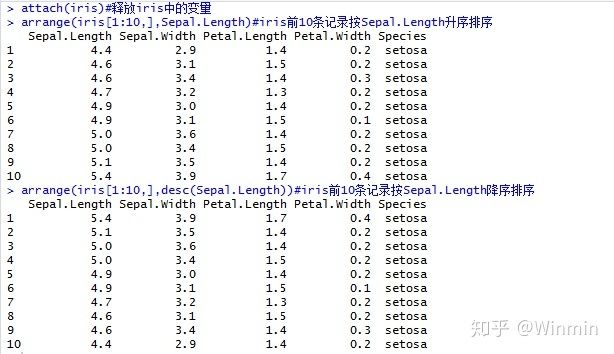
2.排序函数arrange(数据集,变量,排序变量)
3.分组函数group_by(数据集,变量)和聚和函数summarise()
之前在介绍apply类函数时,tapply函数能按照因子分类之后计算,其实group_by函数就相 当于分类的部分,接下来计算的部分可以通过summarise函数实现。

summarise函数返回的一种tibble格式的数据,此处暂时不介绍这种数据格式了。
4.数据关联join类函数
数据关联其实简单来理解就是按照多个数据集都包含的一个变量作为连接的依据,将多个数据集聚合成一个数据集。这个用数据库中主键和外键等概念比较容易理解,数据关联也是数据库中经常使用的操作。R语言中的关联函数用数学上集合(交集、并集、补集、全集)的概念也比较容易理解。
inner_join(x = data1,y=data2,by = "var1") / full_join(...) #内/全联函数left_join(x = data1,y = data2,by = "var1") / right_join(...) #左/右联函数semi_join:返回能够与y表匹配的x表的所有记录anti_join:返回无法与y表匹配的x表的所有记录
具体内容可以参考下面的连接:
5.合并函数
bind_rows(data1, data2) # 数据表需要有相同的列数
bind_cols(data1, data2) # 数据表需要有相同的行数
6.管道函数 %>% :即通过%>%将上一个函数的输出作为下一个函数的输入,免写数据名。
三、reshape包的melt函数
reshape包中有挺多有用的函数,但是melt函数在拆分数据,处理数据维度上是很适合的,它会根据不同的输入数据类型(数据框、数组、列表等等)进行实际的操作。下面就分情况介绍一下melt函数。
1.数据框
melt函数在处理数据框时,理解上会稍微有些复杂,下面是它的使用形式:
melt(data,id.vars,measure.vars,variable.name='variable',na.rm=F,value.name='value')
·id.vars:需要保留数据框的变量名(或者变量名的位置),每个变量都在输出结果占一列·measure.vars:选择的变量名会构成新的一列变量(或者位置),且改变量原本的值也会构
成新的一列变量,两列数据分别记为variable 和 value两列。·variable.name / value.name : 控制variable 和 value两列的名称。
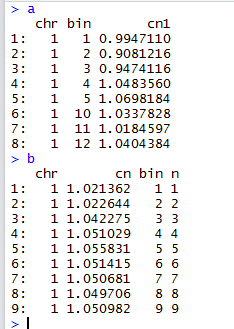
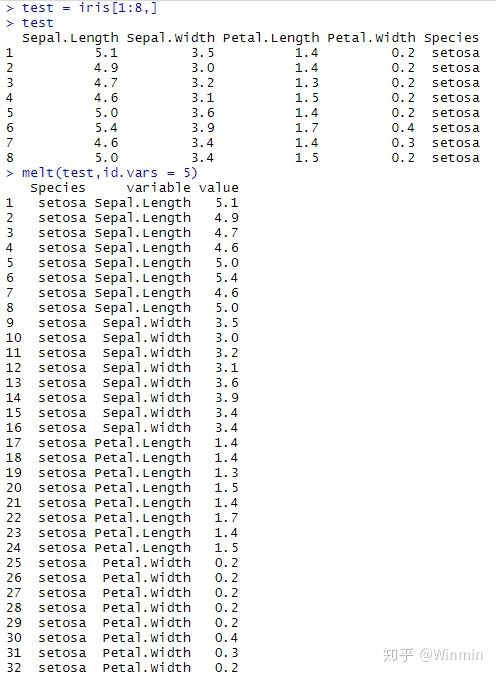
其实id.vars和measure.vars只需传入一个,因为剩下的变量就会被视为另外一个参数的值。下面就大致看一下melt函数对数据框的"整形":
2.数组
melt函数在处理数组类型时,用法就比较简单了,它会数组中的每个元素的维度信息,依次地进行识别,根据数组的维数会生产对应数量的变量用于记录维度信息,且会将原始元素的值作为最后的变量与之前的维度变量合并成新的数据集。具体可看下面的过程:
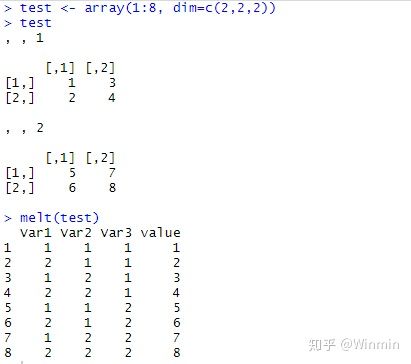
生成的数据集前三个变量就是数组元素的维度信息,最后的value列就是原始值。
3.列表
如果是处理列表数据,melt函数会将列表中的数据分成两列,一列记录列表元素的值,另一列记录列表元素的名称。如果列表中的元素是列表,则增加列变量存储元素名称。元素值排列在前,名称在后,越是顶级的列表元素名称越靠后。具体可见下面的过程:

四、tidyr拓展包的常用函数
tidyr包主要的功能是实现数据框的变形,实现行或列的分割和合并,处理数据框中的空值,根据一个表格衍生出其他表格。
1.gather函数
gather函数的功能是将宽数据准换为长数据:
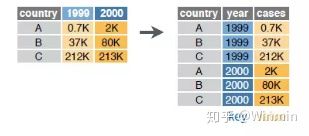
函数形式:gather(data,key,value,...,na.rm=F)key:将原数据框中的所有列赋给一个新变量keyvalue:将原数据框中的所有值赋给一个新变量value…:指定变量聚到同一列中,可通过变量在数据集中的列数,也可以使用"-"排除特定的变量na.rm:是否删除缺失值
上图的数据转换过程,可通过下面的代码实现:

2.spread函数
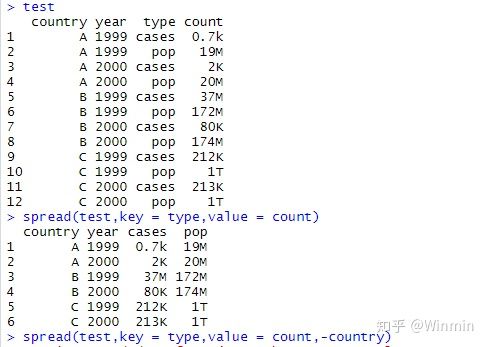
spread函数的功能是将长数据准换为宽数据:
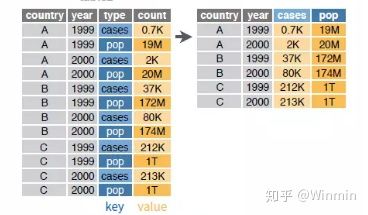
函数形式:spread(data, key, value, fill = NA, convert = FALSE, drop = TRUE)key:指定转换的某列,其观测值作为转换后的列名 value:其他列的观测值分散到相对应的各个单元 fill:对于缺失值,可将fill的值赋值给被转型后的缺失值
上图的数据转换过程,可通过下面的代码实现:
3.unit函数
unit函数能让数据框中多列合并为一列。其形式如下:
unit(data ,col ,... ,sep ,remove)col:指定组合为新列的名字...:指定数据中哪些列组合在一起sep:组合后新列中数据之间的分隔符remove:逻辑值,是否保留参与组合的列
4.separate函数
separate函数的功能与unit相反,即将数据框中的某列按照分隔符拆分为多列,形式如下:
separate(data ,col,into,sep,remove,...)col:待拆分的某列into:定义拆分后新的列名sep:分隔符remove:逻辑值,是否删除拆分后的列
大概地将R语言数据维度处理的常用方法都理了一遍,希望能对入门的小伙伴有帮助,最近有点忙,更新得比较慢,下次会更新R语言数据处理最后的一个部分—— 特殊文本处理,希望不拖更,大家也可以多交流一下,期待大家的意见。