为何Google将几十亿行源代码放在一个仓库?

作者 | Rachel Potvin,Josh Levenberg
译者 | 张建军
编辑 | apddd
【AI科技大本营导读】与大多数开发者的想象不同,Google只有一个代码仓库——全公司使用不同语言编写的超过10亿文件,近百TB源代码都存放在自行开发的版本管理系统Piper中,只当项目开源且需要外部协作时,才会使用业界流行的Git。本文虽然发表于2016年,但是详细解读了Google采用这一方案背后的原因与经验,直到今天仍然有很大的借鉴意义,值得一读。
早期 Google 员工决定使用集中式源代码管理系统。这种方法已维持了19年以上,至今,绝大多数软件仍然存储在这个共享代码库中。与此同时,随着 Google 软件工程师数量稳步增加,代码库的规模呈指数增长(见图1)。 因此,用于托管代码库的技术也发生了显著变化。

关键点:
- Google展示了源代码管理的集中式模型可以扩展到包含10亿个文件,3500万次提交记录,由数以万计的开发者共用的单一代码库。
- 优点包括版本统一,广泛的代码共享,简化的依赖管理,原子性变动,大规模代码析构,跨团队协作,灵活的代码所有权和代码可见性。
- 缺点包括必须为开发和执行编写可扩展的工具,同时还需维护代码健壮性,解决潜在的代码库复杂性过高问题(例如不必要的依赖关系)。
Google的代码规模
Google 代码库包含大约十亿个文件,约3500万次提交记录。该代码库包含 86TB 的数据,包括分布在900 万个源文件的约 20 亿行代码。 文件总数还包括复制到发布分支的源文件、最新版本删除的文件、配置文件、文档和支持性数据文件。
2014 年,每周在 Google 代码库中约有1500 万行代码被修改,涉及文件数约25万个。Linux 内核是一个典型的大型开源软件代码库,该代码库包含 40,000 个文件,约 1500 万行代码。
Google 的代码库由来自世界各国数十个办事处的 25000 多名 Google 软件开发人员共享。 在工作日,他们通常会对代码库提交 16000 次更改,另有 24000 次更改由自动化系统提交。每天,代码库处理数十亿次文件读取请求,峰值每秒大约有 80 万次查询,工作日平均每秒大约有 50 万次查询。大部分流量来自 Google 内部的分布式编译系统bazel。
背景
在审视使用单一代码库的优缺点之前,需要了解一些 Google 使用的工具和工作流程。
Piper和CitC
Piper是一个大型单代码库,最初是基于 BigTable,现在是基于Spanner实现。Piper 分布在全球 10 个 Google 数据中心,依靠 Paxos算法来保证副本一致性。该架构提供了高冗余,并对延迟进行了优化。此外,缓存和异步操作可以隐藏大量网络延迟。
在推出Piper之前,Google 使用的是运行在一台机器上的Perforce(加上自定义缓存基础架构,提供服务超过10年)。Google 代码库规模不断变大是开发Piper的主要原因。
由于 Google 的源代码是公司最重要的资产之一,因此安全功能是 Piper 设计的关键考虑因素:
- 支持文件级访问控制列表。
- 所有Piper用户都可以看到大部分代码库;也可以对重要的配置文件或包含了关键业务算法的文件设置访问限制。
- 对文件的读写访问都进行日志记录。如果敏感数据被意外地提交给 Piper,可以清除有问题的文件。管理员可以通过读取日志确定谁访问过该文件。
在 Piper 工作流程中,开发人员在更改代码库之前会创建文件的本地副本。 这些文件存储在开发人员的工作区中。Piper 代码库中的更新可以根据需要被pull到工作区并与正在进行的工作进行合并。可以与其他开发人员共享工作区快照以供审查。工作区中的文件仅在经过 Google 的代码审查过程后才会被提交到主代码库。
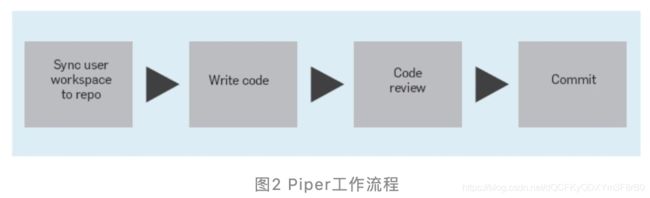
大多数开发人员通过名为Clients in Cloud 的系统或 CitC 访问Piper,该系统由基于云的存储后端和 Linux FUSE文件系统组成。开发人员的工作区是文件系统中的一个目录。
CitC支持:
- 代码浏览和使用Unix工具,无需本地克隆或同步状态。
- 可在Piper存储库中的任何地方浏览和编辑文件,只有修改的文件才存储在其工作区中。 意味着CitC工作区通常仅消耗少量存储(平均工作空间少于10个文件)即可向开发人员呈现整个代码库。
- 对文件的所有写入都作为快照存储在 CitC 中,使得可以根据需要恢复以前的状态。可以明确命名,恢复或标记快照以供审查。
- CitC 工作区可以在任何连接到云的机器上使用,使得开发人员可以在 CitC 工作区中查看彼此的工作。
Piper 也可以在没有 CitC 的情况下使用。开发人员可以将 Piper工作区存储在本地计算机上。 Piper 还可以和 Git 进行有限的互操作。目前,超过 80% 的 Piper 用户使用CitC,由于 CitC 有许多优势,使用率还在持续增长。
基于主干的开发
Google 在 Piper 源代码库之上实施基于主干的开发。绝大多数Piper用户在“头部”(head)进行开发,指“主干”(trunk)或者“主线”(mainline)代码最新版本的一份副本。对代码库的更改是单一串行的。在任何代码提交之后,其他所有开发人员都能看到并使用新代码。
在Google,通常只在发布上线时才会使用分支。发布分支是从代码库某次修改中分割出来的。漏洞修复和必须添加到发布版本的增强功能通常是在主干上进行开发,然后进行cherry-pick引入到发布分支(参见图3 )。由于需要保持稳定性并限制发布分支上的过多变动,所以发布版本通常是“头部”的快照,根据需要可以从“头部”进行cherry-pick更新代码。

当开发新功能时,新旧代码逻辑通常同时存在,通过使用条件标志来控制。这种技术避免了开发分支的需要,并且通过配置更新可以轻松启用或者关闭某项功能。虽然给开发人员增加了一些复杂性,但是避免了开发分支合并问题。标志翻转使得切换具有问题的新实现变得更加容易和快捷。该方法通常用于项目特定的代码,而不是通用的库代码,且最终会删除标志和旧代码。
Google工作流程
Google采用了几种最佳实践和支持系统,以避免在基于主干的开发模式中碰到的问题。
自动测试基础设施:Google内部的自动测试设施可以对几乎所有由于代码更改而受影响的依赖项重新编译。如果一次代码更改造成编译失败,系统就会自动回滚撤消更改。为了减少错误代码被提交到主代码库的可能性,Google采用了一个内部使用的“预提交”系统,可以在更改代码添加到代码库之前自动进行测试和分析。可以针对所有更改运行一组全局预提交分析,代码所有者也可以创建仅在其指定代码库中的目录上运行的自定义分析。
代码审查:代码审查者会对代码质量进行评价,包括设计,功能,复杂度,测试,命名,注释质量和代码风格(Google为不同语言编写了不同的风格指引文档)。Google编写了一个名为 Critique 的代码审查工具,允许审查者查看代码的演变,并对任何一行更改进行评价或吐槽。Google鼓励开发人员不断修改并与审查者进行交流,当审查者最终意见为“LGTM”(Looks Good To Me,我觉得可以)时,审查过程才算完成。
Google 代码库以树结构呈现:每个目录都有一组所有者控制,由他们决定是否接受对目录中文件的更改。变更通常会经过一位开发人员进行详细的代码审查,以衡量变更的质量,以及所有者的认可批准,以评估该变更是否适合他们所在的代码库位置。
静态分析系统(Tricorder )和预提交系统:这些系统在 Google 代码审查工具中自动提供有关代码质量,测试覆盖率和测试结果的数据。 这些密集检查会周期性地,或者当有代码修改需要审查时被触发。Tricorder 还为许多错误提供了一键修改建议。
代码清理:Google使用Rosie进行大规模清理和代码更改。开发人员可以创建一个大补丁,然后Rosie负责将大补丁分成较小的补丁进行独立测试,并进行代码审查,并在通过测试和代码审查后自动提交。Rosie 根据项目目录拆分补丁,依靠代码所有权层次结构将补丁发送给合适的审查者。
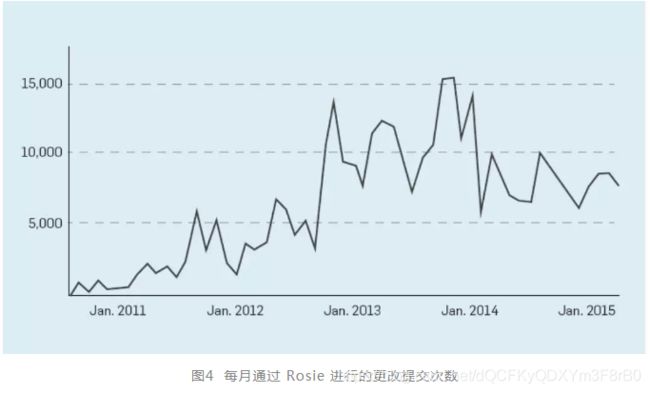
图4现实了每月通过 Rosie 进行的更改提交次数,表明 Rosie 作为 Google 大规模代码更改的工具的重要性。使用Rosie需要注意其使用成本。2013 年,Google 实施了正式的大规模代码更改-审查流程,导致了从 2013 年到 2014 年通过 Rosie提交更改的数量减少。在评估 Rosie提交的更改时,审查委员会需要在更改带来的收益和审查者时间、代码库大幅变动带来的成本之间权衡。
总而言之,Google 使用了许多策略和工具来支持其庞大的代码库,包括基于主干的开发,分布式源代码存储库 Piper,工作区客户端 CitC 以及工作流支持工具 Critique、CodeSearch、Tricorder和Rosie。下面我们讨论这个模型的利弊。
分析
优点(单代码库模型支持)
- 统一版本:单一代码库提供统一的版本控制和单一代码来源。
- 广泛的代码共享和复用:如果一个团队想要依赖另一个团队的代码,可以直接依赖。 Google代码库包含大量有用的库,而单一代码库可以支持广泛的代码共享和复用。
- 简化的依赖管理:Google编译系统可以轻松地在目录之间包含代码,从而简化依赖关系管理。对项目的依赖性更改会触发依赖代码的重建。由于所有代码都在相同的存储库中进行版本控制,所以只有一个版本,也无需关心依赖关系的独立版本。
- 原子性变动:开发人员可以用一致的操作对代码库中的数百或数千个文件进行重大更改;此外,在单代码库中,或至少在集中式服务器上,所有源代码的可用性使得核心库的维护者在提交高影响力更改之前可以更轻松地执行测试和性能基准测试。
- 大规模代码析构:单一代码仓库为查找和分析代码,提供了巨大的方便。
- 跨团队协作。
- 灵活的团队边界和代码所有权:工程师不需要对共享库进行分支开发,或者跨仓库合并来更新代码。当项目所有权更改或计划合并系统时,所有代码都已在同一个库中。
- 代码可见性和清晰的树结构,提供隐含的团队命名空间:每个团队在主树中都有一个目录结构,有效地充当项目自己的命名空间。 每个源文件都可以通过单个字符串唯一标识,该文件路径可选地包含修订版本号。
成本和权衡
开发和执行所需的工具投资
- 单代码库通常意味着更简单的工具因为工具只需和一个引用系统打交道。然而,这需要把工具拓展到能处理单代码库的规模。例如,Google为Eclipse编写了一个自定义插件,使IDE能够使用大型代码库。Google的代码索引系统支持静态分析,代码浏览工具中的交叉引用,以及为 Emacs、Vim和其他开发环境提供丰富的 IDE 功能。这些工具需要持续的投入来管理日益增长的Google代码库规模。此外,Google还需要承担运行这些系统的成本,因此必须权衡运行这些工具的执行成本与提供给工程师有用数据的好处。
- 代码库规模的增长使得代码查找变得愈加困难。开发人员必须能够探索代码库,找到相关的库,并了解如何使用它们以及谁编写它们。 库作者经常需要了解他们的 API 如何被使用。这需要对代码搜索和浏览工具的投资。
代码库复杂性,包括不必要的依赖性和代码查找的困难
- 访问整个代码库鼓励广泛的代码共享和复用。 有些人会认为,这种模式依赖于 Google 构建系统的可扩展性,使得添加依赖关系变得太容易,并且减少了软件开发人员设计稳定且考虑周全的 API 的动机。
- 由于创建依赖关系的轻松,通常团队不要考虑其依赖关系图,使代码清理更容易出错。此外,维护遗留项目会导致生产力下降。
为代码健壮性付出的心血
- Google 投入巨大的努力来维护代码健壮性,以解决与代码库复杂性和依赖关系管理相关的一些问题。 例如,专用工具会自动检测和删除死码,分割大的代码析构,并自动分配代码进行审查(如通过 Rosie),并将 API 标记为不推荐使用。 需要人力运行这些工具并管理相应的大规模代码更改。审查由代码清理和更新引致的简单代码析构也会产生成本。
备选方案
随着像Git这样的分布式版本控制系统(DVCS)的普及和使用越来越多,Google 曾考虑过是否将Piper转移到Git作为其主要的版本控制系统。 Google 有一个团队的任务是支持Git供 Google 的 Android 和 Chrome 团队在主代码库外使用。由于外部合作伙伴和开源协作,使用 Git 对于这些团队很重要。
要转移到基于 Git 的源代码托管,需要将 Google 的主代码库拆分成数千个独立的代码库才能实现相当的性能。这样的重组需要改变Google开发人员的文化和工作流程。作为比较,Google 用Git 托管的Android代码库被拆分为 800多个不同的代码库。
Google 源代码团队目前的投入主要集中在内部源代码系统的持续可靠性,可扩展性和安全性上。该团队目前正在试用Mercurial,这是一款类似Git的开源DVCS。目标是向Mercurial客户端添加可扩展性,以便高效地支持Google规模的代码库。这样,Google工程师可以通过流行的DVCS风格的工作流来使用单代码库。
结论
源代码管理的单一模型不适合所有人。它最适合像 Google 这样的组织——具有开放和协作的文化。而对于代码库中大部分是私有的,或者组与组之间代码不可见的组织来说并不适用。
原文链接