【强化学习纲要】5 策略优化基础
【强化学习纲要】5 策略优化基础
-
- 5.1 基于策略优化的强化学习
-
- 5.1.1 Value-based RL versus Policy-based RL
- 5.1.2 Two types of Policies
- 5.1.3 优化策略的客观函数
- 5.1.4 直接计算policy gradient
- 5.2 Monte-Carlo policy gradient
-
- 5.2.1 Policy Gradient for One-Step MDPs
- 5.2.2 Policy Gradient for Multi-Step MDPs
- 5.2.3 Likelihood Ratio Policy Gradient
- 5.3 policy gradient中减小方差的问题
-
- 5.3.1 与Maximum Likelihood estimator(极大似然)的对比
- 5.3.2 Large Variance of Policy Gradient
- 5.3.3 用时序的因果关系减少variance
- 5.3.4 引入Baseline减小variance
- 5.4 Actor-critic
-
- 5.4.1 Reducing Variance Using a Critic(评论家)
- 5.4.2 Reducing the Variance of Actor-Critic by a Baseline
- 5.4.3 强化学习的两个学派
- 5.4.4 Policy gradient code example
周博磊《强化学习纲要》
学习笔记
课程资料参见:https://github.com/zhoubolei/introRL.
教材:Sutton and Barton
《Reinforcement Learning: An Introduction》
5.1 基于策略优化的强化学习
5.1.1 Value-based RL versus Policy-based RL
机器学习更多关注的是策略函数,策略函数和分类模型类似,给一个输入,需要一个在所有行为上的概率分布直接取最大的概率就可以得到相应的策略。但是决定一个状态的价值是机器学习所没有的。
- 之前基于价值函数的强化学习都是有确定的策略(deterministic policy),做法是学习q 函数,q函数表征如果是离散化的可以用table表示,横轴是所有状态,纵轴是可能的动作,在某一个状态的时候,取那一列最大的那个值就是对应的策略。
所以在学习好q 函数后,利用greedy策略直接取极大的action。

- 但是我们真正需要的是一个策略函数,来估计一个policy function π θ ( a ∣ s ) {\pi}_{\theta}(a|s) πθ(a∣s), θ \theta θ是这个策略函数可以学习的参数,输出是一个概率,在可能action上的可能性。这样再对它进行采样,就可以得到具体的行为了。
Policy Optimization
在强化学习的diagram里面,环境会把状态传回给agent,如果有policy function,过程就较容易,因为策略函数本身输入就是状态,输出就是概率,与机器学习类似,之后取一个argmax就可以得到action;所以基于策略函数优化的强化学习过程较为容易。
当我们得到策略函数后,就可以直接利用策略函数与环境进行交互。
Value-based RL versus Policy-based RL
- 基于价值函数的强化学习
- 学习的是价值函数。
- 在得到q函数后,等于隐式地得到了policy。用q函数取greedy policy得到策略。
- 基于策略函数的强化学习
- 没有学习价值函数,并没有评估每个状态的收益
- 直接学习策略函数。
- Actor-critic
- 两种方式的结合。既要学习策略函数也要学习价值函数。

- 两种方式的结合。既要学习策略函数也要学习价值函数。
基于策略函数强化学习的优势
- 更好的convergence properties(收敛性):不管怎么训练,数据多少,都一定可以得到一个策略函数,数据少得到local optimum,数据多得到global optimum。利用这个策略函数就可以与环境进行交互了,这是价值函数估计里面没有的优点,因为价值函数如果要估计整个table需要很多数据。
- 基于策略函数的policy gradient在高维空间里面更有效。
- 基于策略函数的policy gradient会学出stochastic policies(随机策略),stochastic policies意思是输出是个概率。
基于策略函数强化学习的不足
- 经常收敛到一个局部最优解。因为对策略函数进行建模的时候,用的函数并不是最优的函数。
- 评估策略函数的时候,有很高的variance(方差)使得结果并不是很稳定。
5.1.2 Two types of Policies
两种策略函数:
- Deterministic policy:策略会直接给我们一个确定的行为
- Stochastic policy:策略函数会返回一个基于行为的概率(比如针对某个状态,40%的概率往左走,60%概率往右走)或者如果行为是连续行为,概率是高斯分布,直接针对高斯分布进行采样会得到行为,行为根据概率具有随机性。
Example: Rock-Paper-Scissors

- 在剪刀石头布游戏种最佳策略是随机策略(uniform random policy)。
Example: Aliased Gridworld(走迷宫)
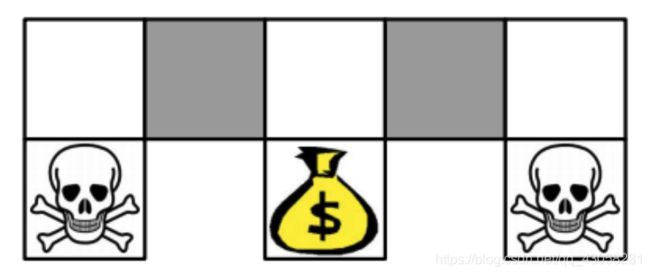
- 规则:agent目标是钱袋,而避免走到骷髅头;当agent走到灰色区域的时候没法确定自己是在左边的区域还是右边的区域,在这两个任意一个区域里面的时候,都会采取采取同一个行为。
- 如果学习的是基于价值函数的学习,就可以得到q函数,q函数的意义是在每一个状态(格子)里面都会选定一个确定的策略。
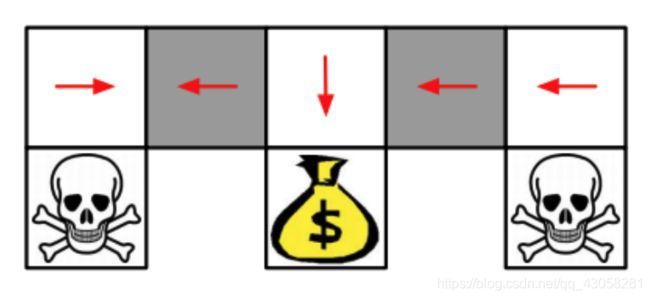
但是由于agent在两个灰色的格子不太能确定自己是在左边还是右边,所以对于两个格子会一视同仁,采取相同的策略,所以就有可能失败。 - 如果采取policy-based学习,就可以学习到stochastic policy(随机性的策略)。
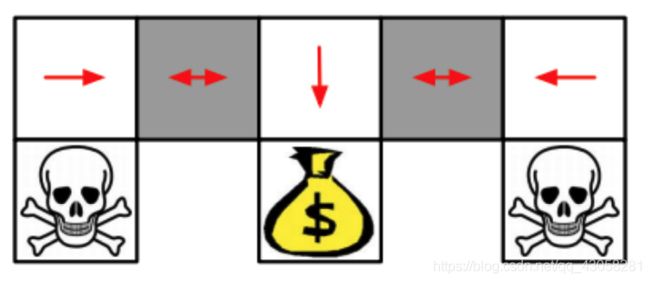
有可能采取stochastic policy,在某一个状态它可能有50%概率往左走,50%概率往右走。这样可以保证在每一个状态出现的时候都可以到达钱袋的位置。随机的策略会帮助它极大化奖励。
5.1.3 优化策略的客观函数
- 近似函数approximator π θ ( a ∣ s ) {\pi}_{\theta}(a|s) πθ(a∣s), θ \theta θ,参数 θ \theta θ。优化 θ \theta θ。
- 如何衡量策略 π θ {\pi}_{\theta} πθ的价值呢?
- 如果是可以结束的环境里,可以用开头状态的值(start value)

取关于策略的期望, v 1 v_1 v1为第一个开始的状态,用最开始的这个值来决定策略好不好。因为这个开始的value决定了它后面所有可能得到的奖励。 - 如果是连续的环境(没有终止的环境)
- 选择average value作为客观函数去优化 θ \theta θ

d π θ d^{{\pi}{\theta}} dπθ是关于一个到达稳定状态的马尔科夫链,每一个状态随机出现的概率点乘每个状态的价值。 - 用每一步可能获得的平均奖励作为客观函数去优化 θ \theta θ
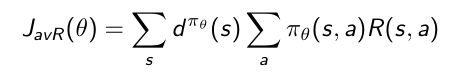
- 选择average value作为客观函数去优化 θ \theta θ
- 价值的策略还可以从轨迹的角度来看,轨迹 τ \tau τ是从策略 π θ {\pi}_{\theta} πθ采样出来的;假设已知策略 π θ {\pi}_{\theta} πθ,用这个策略跟环境进行交互,会产生一条轨迹,我们说这条轨迹就是 τ \tau τ。

用轨迹上每个状态得到的轨迹把它加和起来再除以我们采样出来的轨迹,比如说采样了 m m m条,用这 m m m条轨迹取平均值作为它的价值。 - 有些轨迹是要等到结束过后才有奖励,但是对于这个轨迹总会知道一个reward。每个轨迹都是一个sample,就会知道它的价值,用这个价值去优化。
- 对策略函数优化的目标,使得下面这个等式极大化:

这里的期望是针对策略采样的轨迹,我们希望任意采样一条 τ \tau τ轨迹都可以得到极大化的奖励,把每个奖励加起来得到需要优化的客观函数。
优化客观函数的时候有几种做法
- 假设 J ( θ ) J(\theta) J(θ)是客观函数
- 如果 J ( θ ) J(\theta) J(θ)是可微(可导的,就可以用gradient-based的方法去优化它
- gradient ascend(梯度上升)。因为是让 J ( θ ) J(\theta) J(θ)极大化,让奖励尽可能的多。
- conjugate gradient(共轭梯度法)
- quasi-newton(拟牛顿法)
- 有时候 J ( θ ) J(\theta) J(θ)是==不可微(可导)==的,或者说比较难算derivative(导数),可以使用derivative-free 黑箱优化方法。当函数没法算导数时,就可以采取黑箱优化方法,
- Cross-entropy method (CEM)(进化策略优化算法)
- Hill climbing(爬山算法)
- Evolution algorithm(进化算法)
基于gradient derivative进行策略优化的方法

- 函数 J ( θ ) J(\theta) J(θ), θ \theta θ时策略函数的参数
- 希望找到一个 θ ∗ \theta^* θ∗可以极大化 J ( θ ) J(\theta) J(θ),采样gradient ascend方法,从一个点使得客观函数极大(爬坡)到达红色区域

- 算出gradient加到原来的参数上就可以逐步的进行优化。
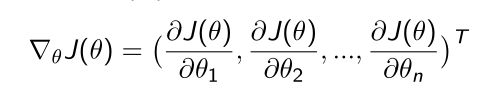
如果没法算出关于 θ \theta θ的导数,可以采用Derivative-free的方法。
Derivative-free Method: Cross-Entropy Method
![]()
假设 J ( θ ) J(\theta) J(θ)是要优化的函数,函数本身是不可导的,可以用类似于采样的方法。

- 假设参数是个集合,有关于参数 θ \theta θ的分布,刚开始的时候可能是个随机的高斯分布。
- 然后对分布进行采样,就会得到很多组 θ \theta θ,比如100;
- 接着让100个策略函数都与环境进行交互,对于每一个策略函数都算 J ( θ ( e ) ) J({\theta}^{(e)}) J(θ(e))后存入 C C C。
- 因为有100个策略函数,就有100个 J ( θ ) J(\theta) J(θ)值,最简单的方法是进行排序,取前10%的那10个参数。
- 然后再用极大似然优化重新对这个参数分布进行优化得到 μ ( i + 1 ) {\mu}^{(i+1)} μ(i+1);
- 重复这个过程后, P μ ( i ) ( θ ) P_{{\mu}^{(i)}}(\theta) Pμ(i)(θ)也随之更新,再重新采样得到100个,再放进去evaluate。
- 与进化算法类似,并没有算 J ( θ ) J(\theta) J(θ)的倒数,直接把 J ( θ ) J(\theta) J(θ)当作函数来用,每次放个函数进去
- Example of CEM for a simple RL problem:
https://github.com/cuhkrlcourse/RLexample/blob/master/my_learning_agent.py
Approximate Gradients by Finite Difference
Finite Difference:另一种黑箱优化的方法。
- 没法算gradient,但是可以用近似的方法算。
- θ \theta θ可能是很高维的,在每一个维度 k k k上加一个很小的扰动 ϵ \epsilon ϵ。
每个维度:

- 加了扰动后,再减去原来的值,再除以这个很小的扰动 ϵ \epsilon ϵ。这样就可以近似element那个维度的梯度,重复这个做法,就会得到近似的梯度。

- 加了扰动后,再减去原来的值,再除以这个很小的扰动 ϵ \epsilon ϵ。这样就可以近似element那个维度的梯度,重复这个做法,就会得到近似的梯度。
- 用这个类似的梯度优化,就类似于算了梯度优化( J ( θ ) J(\theta) J(θ)优化),就可以进一步对参数进行优化了。
- 产生的gradient是近似的,效率较低噪声较大,但是针对任何policy都可以起作用。
5.1.4 直接计算policy gradient
- 给定了一个policy function π θ {\pi}_{\theta} πθ是可微分的
- 目标是计算gradient,从而优化策略函数
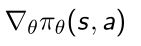
- Likelihood ratios tricks(似然比)

先把策略函数取log,再算gradient。这个过程再概率论里面叫做score function(评分函数),对于任意给定的概率函数, π θ {\pi}_{\theta} πθ是个概率,取log后是likelihood,然后取关于参数的gradient,就会得到score function。
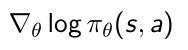
score function定义,就是说score function是求最大对数似然函数中让对数似然函数梯度等于0的梯度。
策略函数形式:Softmax Policy
- 当得到并定义好feature ϕ ( s , a ) \phi(s,a) ϕ(s,a)后,模型的参数就是把feature加和。
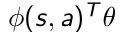
- 再把它放到softmax里面,这样就使得 π θ {\pi}_{\theta} πθ变成一个概率函数,因为取了softmax后,输入是个状态输出总是个概率。
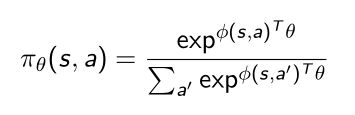
- score function
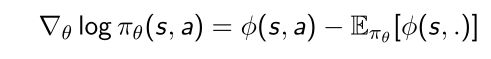
策略函数形式:Gaussian Policy
- 有些时候策略是连续的,比如机器人控制问题,动作空间是个连续的过程,需要连续控制变量。对于连续策略变量,高斯是一个比较好的定义方式。
- 高斯函数的Mean是状态特征量的加和。

- Variance既可以把它参数化也可以把它设为固定的 σ 2 {\sigma}^2 σ2。
- 所以当我们要得到一个策略的时候,就直接对高斯函数进行采样

当你状态不同的时候Mean会不同,对于function进行采样就可以得到连续的值。 - score function
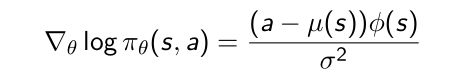
5.2 Monte-Carlo policy gradient
5.2.1 Policy Gradient for One-Step MDPs
- Policy Gradient是策略优化的一个经典算法,先说MDP最简单的形式——只走一步
- 从stationary distribution中采样起始状态
- 一步后算出reward就结束了
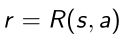
- 从stationary distribution中采样起始状态
- 定义objective function

根据策略函数的期望可以展开写成:reward乘以策略函数,再将所有可能的action marginalized(边缘化),再乘以stationary distribution,这样就得到了客观函数。 - 极大化 J ( θ ) J(\theta) J(θ)
由
推导得到
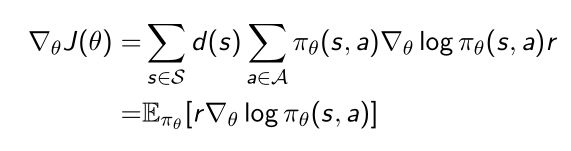
5.2.2 Policy Gradient for Multi-Step MDPs
- 多步MDP,策略函数会和环境进行连续的交互,所以实际产生的是个轨迹 τ \tau τ

τ \tau τ包含:初始状态 s 0 s_0 s0,对应初始状态产生的action a 0 a_0 a0,得到的奖励 r 1 r_1 r1,直到最后结束。策略函数与环境交互就会产生这样的轨迹。 - 定义reward τ \tau τ

在每个状态把它的奖励加和。 - policy objective
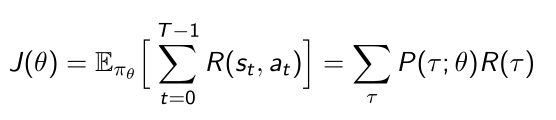
- J ( θ ) J(\theta) J(θ)等于关于策略的期望,表示让策略对环境进行交互,对策略进行采样,任意采样出来一个 τ \tau τ都会得到很高的奖励。
- 所以这里可以把expectation再写成一个加和的形式,希望整个连续量尽可能大。
- 把 τ \tau τ放到外面,用一个 τ \tau τ的概率代替, P ( τ , θ ) P(\tau,\theta) P(τ,θ)包含了:

- 可以把它想象成策略函数和环境交互的一个概率过程(轨迹产生的过程)。先从 μ ( s 0 ) \mu(s_0) μ(s0)采样初始状态,得到初始状态后就可以扔给 π θ {\pi}_{\theta} πθ,对它采样就会产生新的action;得到新的action后,就可以传还给环境,环境就会利用transition dynamics(也是一个概率) p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t,a_t) p(st+1∣st,at), p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t,a_t) p(st+1∣st,at)就会采样产生下一个状态 s t + 1 s_{t+1} st+1.
- 连×的符号表示把每一个状态的交互都乘起来,可以用 P ( τ , θ ) P(\tau,\theta) P(τ,θ)来表示这个关于 τ \tau τ的概率函数。
- 所以变成优化 θ \theta θ关于 τ \tau τ的这个值尽可能大。

现在 θ \theta θ已经包含在关于轨迹的概率函数里面了,所以怎么优化这个函数呢? - gradient的推导过程

大致意思是:目标是算关于 θ \theta θ的导数,右式只有 P P P是关于 θ \theta θ的,所以导数求导是在 P P P上面;同样采用之前likelihood ratio trick的方法,还原成log的形式。
这个形式有什么好处呢? - 因为 P ( τ ; θ ) P(\tau;\theta) P(τ;θ)是一个很长的连乘,有了log以后就可以把连乘变成加和的形式。

- 在有了导数这个式子后,因为 τ \tau τ的分布本身是不知道的,我们可以用MC的办法,用实际采样的轨迹去近似它,比如采样 m m m条轨迹就有 m m m个 τ \tau τ,然后取平均就可以得到gradient,得到下式:
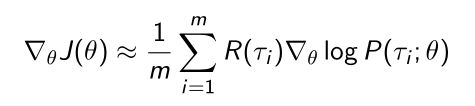
- 现在可以把 l o g P ( τ ; θ ) logP(\tau;\theta) logP(τ;θ)再进行一个分解

- 首先先带入 P ( τ ; θ ) P(\tau;\theta) P(τ;θ),因为有了log我们可以把每一个项分开,变成连加的形式。
- 为什么要连加呢?因为关于 θ \theta θ的导数我们就可以再把它放到里面去;因为这三项只有中间那项是与 θ \theta θ有关的,所以在求导的时候就直接消去了。
- 这就是policy gradient很神奇的地方,通过简单的likelihood ratio trick,就可以消去很多不用的量。而且这里本身transition dynamic也不知道,所以这个操作过后唯一剩下的就是score function。score function的加和就对应了客观函数的gradient。
5.2.3 Likelihood Ratio Policy Gradient

5.3 policy gradient中减小方差的问题
Score Function Gradient Estimator
- 策略函数的客观函数 E τ ~ π θ [ R ( τ ) ] E_{\tau~{{\pi}_{\theta}}}[R(\tau)] Eτ~πθ[R(τ)],参数是 θ \theta θ, τ \tau τ是采样产生的。
- 写成更广义的形式:

- reward function 是 f ( x ) f(x) f(x),本身是个函数,我们要极大化这个函数。但是这个函数的 x x x是从 p ( x ; θ ) p(x;\theta) p(x;θ)采样产生的,假设 p ( x ; θ ) p(x;\theta) p(x;θ)是概率函数,参数是 θ \theta θ。现在需要优化概率函数里面的 θ \theta θ使得 f ( x ) f(x) f(x)能尽可能大。这就是policy gradient在做的事情。
- 然后用likelihood ratio trick把log放入,转化成log likelihood gradient;接着用采样MC的方法,从 p ( x ; θ ) p(x;\theta) p(x;θ)里面采样后放入函数 f ( x s ) f(x_s) f(xs)和似然函数likelihood function里面,这样就可以近似它的gradient。
- 写成更广义的形式:
- p ( x ) p(x) p(x)即样本,从 p ( x ) p(x) p(x)里面进行采样出x使得 f ( x ) f(x) f(x)尽量的大。gradient优化的过程就是去优化这个函数的形状。

蓝色的箭头是 l o g p ( x ) log p(x) logp(x)的gradient,每个箭头对应了一个gradient,每个点都对应了一个值; - f ( x ) f(x) f(x)是另外一个函数,会对分布采样出来的值给一个权重,得到下图:
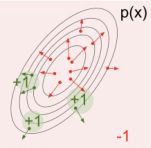
绿色这些点(采样 x x x的点)放到 f ( x ) f(x) f(x)里面,值就很大,就是个值比较大的样本;红色的这些点,采样出来的 x x x放到 f ( x ) f(x) f(x)里面,是负的值;所以我们现在要使得 p ( x ) p(x) p(x)的分布尽量往绿色区域移。 - 当gradient产生后,把概率函数的参数更新一次,得到下图:

可以看到概率函数 p ( x ) p(x) p(x)的形状变了,整个形状变得往能得到更高分数的区域走;第二次采样的时候,采样出来的 x x x都是在这些高分数的过程。所以score function gradient estimator就可以通过这样一个几何解释来理解。
5.3.1 与Maximum Likelihood estimator(极大似然)的对比
- Maximum Likelihood estimator是机器学习常用的estimator。给定一个概率函数,函数里有一些参数,用极大似然的方法估计参数。
- 极大似然:

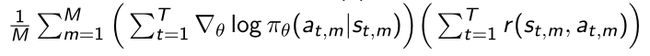
把直接采样的这些样本扔到似然函数里面去,希望似然函数极大化,写成gradient的形式。 - policy gradient estimator:

这两者其实是比较类似的,这里也是似然likelihood取gradient,唯一的不同是这里有一个reward function,reward function我们可以把它假设成正负的值,这样就可以把log likelihood进行加权。所以可以把它看成一个加权后的极大似然估计。 - 在优化的过程中,鼓励策略进入到得到奖励尽可能多的区域里面。supervised learning是直接有个标签去优化函数;策略函数是优化策略概率函数使得能够尽可能进入到能够采样产生更高奖励的区域里面。

- 可视化:

- 现在产生的policy gradient,是使得这些轨迹进入到得到更多奖励的区域。刚开始的时候是随机采样与环境交互得到很多轨迹,每一条轨迹把它放到reward function里面去就会得到一个值。
- 这个热力图展示的是对于不同的轨迹,它轨迹上面得到的奖励程度是不一样的。优化的过程就是使得轨迹的分布尽可能往红色的区域平移。
5.3.2 Large Variance of Policy Gradient
- 现在policy gradient是采样产生的,MC gradient(基于样本得到的gradient),方差(variance)是非常大的。
- unbiased但是噪声非常大。用MC方法就是实际用采样得到的,本身sample estimator是没有偏置的。但是噪声非常大,比如采样 R ( τ ) R(\tau) R(τ)有时候没有奖励,有时候又得到奖励。所以我们希望能够尽可能减少variance,这样也会使得整个强化学习优化的过程更稳定。
- 两种改进办法:

- 对时序上面的因果关系运用进去,这样可以使得它不必要的项可以被去掉。
- 包含一个baseline(基线),对reward做一个简单的normalization(归一化),可以使得R这一项本身的variance减小一些。
5.3.3 用时序的因果关系减少variance
- policy gradient

由两部分加和组成,第一部分表示一个轨迹上面的所有有奖励的点都加和起来,第二部分表示每个点可以算出它的log likelihood以及取gradient的score function,把在每个点的score function也加起来。 - 加入时序因果后使得reward变得更小。因为这里存在一个问题,第一个加和里面是很多奖励,第二个加和是每个点的likelihood,相当于把后面的likelihood做了个normalization。然而,在前面做的log likelihood,并不会对后面的奖励造成影响。这样就相当于一个时序的因果性。所以我们就想去掉这种影响。

- 所以这样有一个简单的推导:

- 大致意思是:
- 对这个gradient,我们log likelihood只需要加和到 t ′ t' t′这个时间点,奖励从时间点 t ′ t' t′加到时间结束。第一部分 t ′ t' t′到 T − 1 T-1 T−1是说reward undergo(奖励经历)。
- 这样就对早期的等式做了个简化, G t G_t Gt是说当前时刻在后面得到的所有加和对前面是没有任何关系的,每个点都要likelihood,后面得到的奖励对于前面的奖励得到与否并没有关联,所以最终是把没有必要加上去的奖励去掉了, G t G_t Gt指的是在某一个时刻它所有之后的奖励乘以它的score function。
- 通过这样的操作,variance就更多的降低了。
- Causality:策略在time t ′ t' t′并不影响它在 t < t ′ t

G t G_t Gt是只在当前时刻,把当今时刻之后全部奖励都加起来。
Reinforce: A Monte-Carlo policy gradient algorithm
- 基于蒙特卡洛policy gradient

倒过来算得到return,乘以score function,作为gradient加上去优化 θ \theta θ参数。 - Classic paper: Williams (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning: introduces REINFORCE algorithm
5.3.4 引入Baseline减小variance
- The original update
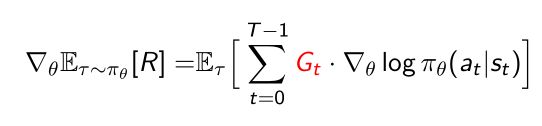
- G t G_t Gt是当前时刻得到的return,return本身是实际采样出来的量,所以本身是具有high variance的。
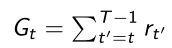
- G t G_t Gt是当前时刻得到的return,return本身是实际采样出来的量,所以本身是具有high variance的。
- 因为是实际得到的样本,我们可以要他直接减去baseline的值 b ( s t ) b(s_t) b(st),这样就可以使得 G t − b ( s t ) G_t-b(s_t) Gt−b(st)这一项的variance要小于 G t G_t Gt本身。
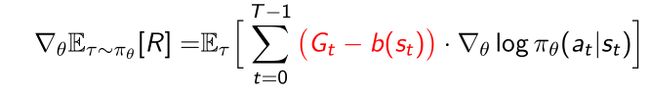
- 用expected return作为baseline,采样到了很多 G t G_t Gt,直接取平均值,用平均值做baseline的参数。
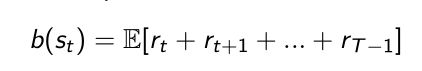
- 推导过程:
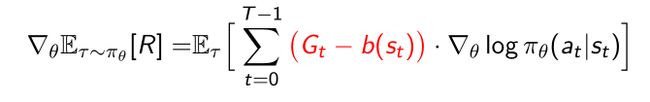
- 当我们引入了baseline过后,可以证明引入的这一项(拆分开后)并不会改变gradient这个值,baseline是直接等于0的。

- 带来很多好处:
- mean是保持不变的
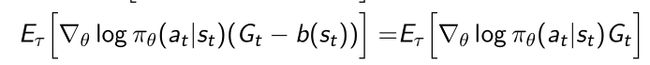
- variance变小,gradient变得更稳定,强化学习过程更稳定。

- 当我们引入了baseline过后,可以证明引入的这一项(拆分开后)并不会改变gradient这个值,baseline是直接等于0的。
- baseline也可以用一种参数去拟合
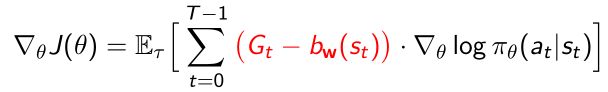
b w ( s ) b_w(s) bw(s)使得baseline本身带有参数,在优化过程中同时优化 θ \theta θ和 w w w。
Vanilla Policy Gradient Algorithm with Baseline

- 引入advantage estimate的量。
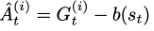
- baseline本身是带有参数 w w w的, b ( s t ) b(s_t) b(st)去估计 G t G_t Gt。有一个loss是估计 b ( s t ) b(s_t) b(st)去优化它的参数。

- policy gradient 去优化策略函数,利用advantage function优化策略函数。

- Sutton, McAllester, Singh, Mansour (1999). Policy gradient methods
for reinforcement learning with function approximation
5.4 Actor-critic
5.4.1 Reducing Variance Using a Critic(评论家)
- 进一步我们可以替换掉 G t G_t Gt,引入Critic(评论家),评论policy function这个函数自身的表现。
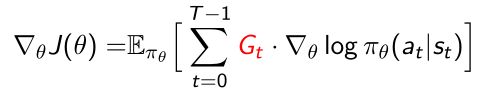
- 之前看到policy gradient的 G t G_t Gt是实际采样得到的,是通过MC实际得到的sample,sample本身可以直接和 Q π θ ( s t , a t ) Q^{\pi\theta}(s_t,a_t) Qπθ(st,at)建立一个联系,因为 G t G_t Gt是 Q π θ ( s t , a t ) Q^{\pi\theta}(s_t,a_t) Qπθ(st,at)的实现(采样得到)。
- 所以现在可以定义一个critic来估计Q函数。

- 所以 G t G_t Gt可以用Q函数来替代。

- Q函数代表的意思是在当前的状态采取某个行为会得到多少的价值,和 G t G_t Gt概念是一样的, G t G_t Gt是noisy estimate for Q。
- 由两部分组成,既有了policy function,也有了Q function(action-value function estimation)
Actor-Critic Policy Gradient
- 把value function和policy function结合起来的方法
- 包含两个成分
- Actor:意思就是现在的policy function,因为policy function是实际和环境交互,产生训练数据的角色的函数。
- Critic:意思就是现在的value function,要去估计 Q π θ ( s t , a t ) Q^{\pi\theta}(s_t,a_t) Qπθ(st,at),评论表演者表演的好坏(做出这个动作实际会得到多少的价值)
- 参数
- Actor: θ \theta θ是actor的参数
- Critic: w w w是value function的参数
所以在优化过程中要同时优化 θ \theta θ和 w w w。
- 所以critic和policy evaluation是做的一样的事情,给定当前policy function后计算它可能获得的价值。
- 估计critic的参数的方法,可以重用之前policy evaluation的方法
- Monte-Carlo(MC) policy evaluation
- Temporal-Difference(TD) learning
- Least-squares policy evaluation
Action-Value Actor-Critic Algorithm
- 最简单的QAC算法
- Critic:value function,用TD(0)的方法优化 w w w
- Actor:用policy gradient的方法优化 θ \theta θ
- Q函数用线性的近似
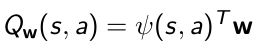
得到feature ϕ ( s , a ) \phi(s,a) ϕ(s,a)过后,用线性叠加的方法得到Q函数。

3:TD error δ \delta δ:TD target(reward function + Q函数本身) - 上一个状态的Q函数
4:有了TD error后更新价值函数的参数 w w w,因为是线性的价值函数的估计,所以取gradient过后直接是feature✖ δ \delta δ再加上去
5:在估计策略函数参数的时候,直接用了policy gradient, Q w ( s , a ) Q_w(s,a) Qw(s,a)直接bootstrapping有了价值函数的拟合,乘以score function,就可以加到策略函数的参数 θ \theta θ上进行估计
再重复这个步骤,就是actor-critic算法。
Actor-Critic Function Approximators
- 因为Value function estimation和policy function是两个函数。
- 一种方法是可以用两个不相关的函数分别拟合。

上面是Value function,输入是状态,输出是当前的价值函数;下面是policy function,输入是状态,输出是概率。 - 一种结合计算的方法是把这两个拟合函数组合起来。

让它分享特征提取的部分,有两个输出:一个输出价值函数,一个输出策略函数。这样就可以节省开支,这样的设计在actor-critic里面是非常常见的。
5.4.2 Reducing the Variance of Actor-Critic by a Baseline
- Q函数
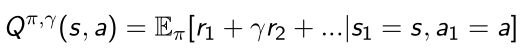
- Q函数和V函数的关系
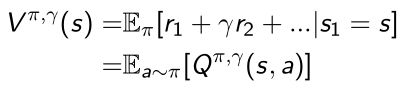
Q函数对于行为进行加和,算出期望得到V函数 - 定义Advantage function: Q函数和V函数结合起来

定义advantage function的意义是,引入baseline来减少policy gradient的variance(方差)。定义以后价值函数可以做Q函数的baseline。 - 因此,policy gradient变成

现在面临的问题是,Q函数和V函数都有自身的参数。
policy gradient的一个非常好的应用:克服不可微分的计算成分
- 有些时候网络的forward-pass是由多段组成的。

- 从input出发,前面半段是可微分的结构,中间不可微分(比如采用了sample),第三段可微。
- 所以面对这样一个网络的时候,进行back propagation(反向传播)是比较困难的,因为中间无法微分,gradient就无法传到前半段去。
- 方法一:用Reparameterization trick(VAE变分编码器中使用的trick)的方法。
- 方法二:用采样的方法,中间不可微的阶段可以用样本来替代。

- 从不可微分的这一点开始,用MC方法采样,采样后产生很多样本,用样本传下去就会产生很多分支的第三阶段。
- 因为第三阶段是可微的,所以可以算它的loss,从而算回不可微的地方。
- 然后可以转化成policy gradient的方法,因为policy gradient reinforce本身是MC policy gradient,是基于sample样本叠加起来的,所以可以把每个样本传回来的gradient做一个加和来近似它在第二阶段开始点的gradient,这样就可把不可微分的这一段传回去,从而继续算第一段的gradient。
- 这个操作其实是和Reparameterization trick(VAE变分编码器中使用的trick)是类似的。
Policy Gradient扩展
- A2C和A3C:Asynchronous Methods for Deep Reinforcement Learning, ICML’16. Representative high-performance actor-critic algorithm: https://openai.com/blog/baselines-acktr-a2c/
- TRPO:Schulman, L., Moritz, Jordan, Abbeel (2015). Trust region policy optimization: deep RL with natural policy gradient and adaptive step size
- PPO: Schulman, Wolski, Dhariwal, Radford, Klimov (2017). Proximal policy optimization algorithms: deep RL with importance sampled policy gradient
5.4.3 强化学习的两个学派
- Value-based RL:利用dynamic programming和bootstrapping的方法去优化它的价值函数,得到价值函数后,从Q函数里面采取行为。
- 代表算法:Deep Q-learning and its variant
- 代表人物:Richard Sutton (no more than 20 pages on PG out of the 500-page textbook), David Silver, from DeepMind
- 从控制论背景出发
- Policy-based RL:只需要少量样本,就可以拟合出策略函数。
- 代表算法: PG, and its variants TRPO, PPO, and
others - 代表人物:Pieter Abbeel, Sergey Levine, John
Schulman, from OpenAI, Berkelely - 从机器人,机器学习背景出发
- 代表算法: PG, and its variants TRPO, PPO, and
- DeepMind和OpenAI两大RL流派区别:
https://www.zhihu.com/question/316626294/answer/627373838
殊途同归,都往Actor-critic发展。
DeepMind主要研究游戏领域,主要跑仿真对样本本身不挑剔;OpenAI研究机器人,更注重sample effectioncy(有效性),减少采样。
5.4.4 Policy gradient code example
- policy gradient算法总结:
https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html - REINFORCE code on CartPole:
https://github.com/cuhkrlcourse/RLexample/blob/master/policygradient/reinforce.py - Policy Gradient on Pong :
https://github.com/cuhkrlcourse/RLexample/blob/master/policygradient/pg-pong-pytorch.py - Policy Gradient with Baseline on Pong:
https://github.com/cuhkrlcourse/RLexample/blob/master/policygradient/pgb-pong-pytorch.py
REINFORCE代码
import argparse
import gym
import numpy as np
from itertools import count
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
parser = argparse.ArgumentParser(description='PyTorch REINFORCE example')
parser.add_argument('--gamma', type=float, default=0.99, metavar='G',
help='discount factor (default: 0.99)')
parser.add_argument('--seed', type=int, default=543, metavar='N',
help='random seed (default: 543)')
parser.add_argument('--render', action='store_true',
help='render the environment')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='interval between training status logs (default: 10)')
args = parser.parse_args()
env = gym.make('CartPole-v1')
env.seed(args.seed)
torch.manual_seed(args.seed)
class Policy(nn.Module):
def __init__(self):
super(Policy, self).__init__()
self.affine1 = nn.Linear(4, 128)
self.dropout = nn.Dropout(p=0.6)
self.affine2 = nn.Linear(128, 2)
self.saved_log_probs = []
self.rewards = []
def forward(self, x):
x = self.affine1(x)
x = self.dropout(x)
x = F.relu(x)
action_scores = self.affine2(x)
#输出:softmax,激活变成概率,对它进行采样就可以得到具体的action
return F.softmax(action_scores, dim=1)
policy = Policy()
optimizer = optim.Adam(policy.parameters(), lr=1e-2)
eps = np.finfo(np.float32).eps.item()
def select_action(state):
#当得到环境状态
state = torch.from_numpy(state).float().unsqueeze(0)
#放入policy function里面,得到probability(stachastic policy)
probs = policy(state)
m = Categorical(probs)
#对它进行采样,得到action
action = m.sample()
#训练需要保留log likelihood function,因此存起来
policy.saved_log_probs.append(m.log_prob(action))
return action.item()
#具体的优化过程
#当结束了episode后
def finish_episode():
R = 0
policy_loss = []
returns = []
#反算的过程,为了算每一步实际的return
for r in policy.rewards[::-1]:
R = r + args.gamma * R
returns.insert(0, R)
returns = torch.tensor(returns)
#normalization归一化
returns = (returns - returns.mean()) / (returns.std() + eps)
#得到function
for log_prob, R in zip(policy.saved_log_probs, returns):
policy_loss.append(-log_prob * R)
#进行policy gradient优化
optimizer.zero_grad()
policy_loss = torch.cat(policy_loss).sum()
policy_loss.backward()
optimizer.step()
del policy.rewards[:]
del policy.saved_log_probs[:]
def main():
running_reward = 10
for i_episode in count(1):
state, ep_reward = env.reset(), 0
for t in range(1, 10000): # Don't infinite loop while learning
action = select_action(state)
state, reward, done, _ = env.step(action)
if args.render:
env.render()
policy.rewards.append(reward)
ep_reward += reward
if done:
break
running_reward = 0.05 * ep_reward + (1 - 0.05) * running_reward
finish_episode()
if i_episode % args.log_interval == 0:
print('Episode {}\tLast reward: {:.2f}\tAverage reward: {:.2f}'.format(
i_episode, ep_reward, running_reward))
if running_reward > env.spec.reward_threshold:
print("Solved! Running reward is now {} and "
"the last episode runs to {} time steps!".format(running_reward, t))
break
if __name__ == '__main__':
main()
Policy Gradient with Baseline on Pong代码
import os
import argparse
import gym
import numpy as np
from itertools import count
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.distributions import Categorical
import pdb
is_cuda = torch.cuda.is_available()
parser = argparse.ArgumentParser(description='PyTorch PG with baseline example at openai-gym pong')
parser.add_argument('--gamma', type=float, default=0.99, metavar='G',
help='discount factor (default: 0.99')
parser.add_argument('--decay_rate', type=float, default=0.99, metavar='G',
help='decay rate for RMSprop (default: 0.99)')
parser.add_argument('--learning_rate', type=float, default=3e-4, metavar='G',
help='learning rate (default: 1e-4)')
parser.add_argument('--batch_size', type=int, default=20, metavar='G',
help='Every how many episodes to da a param update')
parser.add_argument('--seed', type=int, default=87, metavar='N',
help='random seed (default: 87)')
parser.add_argument('--test', action='store_true',
help='whether to test the trained model or keep training')
args = parser.parse_args()
env = gym.make('Pong-v0')
env.seed(args.seed)
torch.manual_seed(args.seed)
D = 80 * 80
test = args.test
if test ==True:
render = True
else:
render = False
def prepro(I):
""" prepro 210x160x3 into 6400 """
I = I[35:195]
I = I[::2, ::2, 0]
I[I == 144] = 0
I[I == 109] = 0
I[I != 0 ] = 1
return I.astype(np.float).ravel()
# Pong RGB作为input,输出是行为
#PGbaseline:定义的policy function
class PGbaseline(nn.Module):
def __init__(self, num_actions=2):
super(PGbaseline, self).__init__()
self.affine1 = nn.Linear(6400, 200)
self.action_head = nn.Linear(200, num_actions) # action 1: static, action 2: move up, action 3: move down
self.value_head = nn.Linear(200, 1)
self.num_actions = num_actions
self.saved_log_probs = []
self.rewards = []
def forward(self, x):
#feature
x = F.relu(self.affine1(x))
#输出由两个head
#第一个head输出action probability
action_scores = self.action_head(x)
#第二个head输出state_value就value function输出的值
state_values = self.value_head(x)
#输出取softmax
#policy function输出两部分:一部分状态的实际价值,一部分输出应该采取的策略
return F.softmax(action_scores, dim=-1), state_values
def select_action(self, x):
x = Variable(torch.from_numpy(x).float().unsqueeze(0))
if is_cuda: x = x.cuda()
probs, state_value = self.forward(x)
m = Categorical(probs)
#采样得出action
action = m.sample()
self.saved_log_probs.append((m.log_prob(action), state_value))
return action
# built policy network
policy = PGbaseline()
if is_cuda:
policy.cuda()
# check & load pretrain model
if os.path.isfile('pgb_params.pkl'):
print('Load PGbaseline Network parametets ...')
if is_cuda:
policy.load_state_dict(torch.load('pgb_params.pkl'))
else:
policy.load_state_dict(torch.load('pgb_params.pkl', map_location=lambda storage, loc: storage))
# construct a optimal function
optimizer = optim.RMSprop(policy.parameters(), lr=args.learning_rate, weight_decay=args.decay_rate)
def finish_episode():
R = 0
policy_loss = []
value_loss = []
rewards = []
for r in policy.rewards[::-1]:
R = r + args.gamma * R
rewards.insert(0, R)
# turn rewards to pytorch tensor and standardize
rewards = torch.Tensor(rewards)
#MC得到的reward
rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-6)
if is_cuda: rewards = rewards.cuda()
for (log_prob, value), reward in zip(policy.saved_log_probs, rewards):
#advantage function
advantage = reward - value
#两部分loss
#第一部分policy gradient的loss
policy_loss.append(- log_prob * advantage) # policy gradient
#第二部分value function approximation的loss
value_loss.append(F.smooth_l1_loss(value, reward)) # value function approximation
optimizer.zero_grad()
policy_loss = torch.stack(policy_loss).sum()
value_loss = torch.stack(value_loss).sum()
#同时优化policy function和policy function
loss = policy_loss + value_loss
if is_cuda:
loss.cuda()
loss.backward()
optimizer.step()
# clean rewards and saved_actions
del policy.rewards[:]
del policy.saved_log_probs[:]
# Main loop
running_reward = None
reward_sum = 0
for i_episode in count(1):
state = env.reset()
prev_x = None
for t in range(10000):
if render: env.render()
cur_x = prepro(state)
x = cur_x - prev_x if prev_x is not None else np.zeros(D)
prev_x = cur_x
action = policy.select_action(x)
action_env = action + 2
state, reward, done, _ = env.step(action_env)
reward_sum += reward
policy.rewards.append(reward)
if done:
# tracking log
running_reward = reward_sum if running_reward is None else running_reward * 0.99 + reward_sum * 0.01
print('Policy Gradient with Baseline ep %03d done. reward: %f. reward running mean: %f' % (i_episode, reward_sum, running_reward))
reward_sum = 0
break
# use policy gradient update model weights
if i_episode % args.batch_size == 0 and test == False:
finish_episode()
# Save model in every 50 episode
if i_episode % 50 == 0 and test == False:
print('ep %d: model saving...' % (i_episode))
torch.save(policy.state_dict(), 'pgb_params.pkl')
进阶:
- Policy Gradient→TRPO→ACKTR→PPO
- TRPO: Trust region policy optimization. Schulman, L., Moritz,Jordan, Abbeel. 2015
- ACKTR: Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation. Y. Wu, E. Mansimov, S. Liao, R. Grosse, and J. Ba. 2017
- PPO: Proximal policy optimization algorithms. Schulman, Wolski,Dhariwal, Radford, Klimov. 2017
- Q-learning→DDPG→TD3→SAC
- DDPG: Deterministic Policy Gradient Algorithms, Silver et al. 2014
- TD3: Addressing Function Approximation Error in Actor-Critic Methods, Fujimoto et al. 2018
- SAC: Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor, Haarnoja et al. 2018
课后作业:
https://github.com/cuhkrlcourse/ierg6130-assignment/tree/master/assignment3