使用策略梯度解决离散action space问题。
一、导入包,定义hyper parameter
import gym import tensorflow as tf import numpy as np from collections import deque #################hyper parameters################、 #discount factor GAMMA = 0.95 LEARNING_RATE = 0.01
二、PolicyGradient Agent的构造函数:
1、设置问题的状态空间维度,动作空间维度;
2、序列采样的存储结构;
3、调用创建用于策略函数近似的神经网络的函数,tensorflow的session;初始或神经网络的weights和bias。
def __init__(self, env): #self.time_step = 0 #state dimension self.state_dim = env.observation_space.shape[0] #action dimension self.action_dim = env.action_space.n #sample list self.ep_obs, self.ep_as, self.ep_rs = [],[],[] #create policy network self.create_softmax_network() self.session = tf.InteractiveSession() self.session.run(tf.global_variables_initializer())
三、创建神经网络:
这里使用交叉熵误差函数,使用神经网络计算损失函数的梯度。softmax输出层输出每个动作的概率。
tf.nn.sparse_softmax_cross_entropy_with_logits函数先对 logits 进行 softmax 处理得到归一化的概率,将lables向量进行one-hot处理,然后求logits和labels的交叉熵:

其中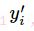 为label中的第i个值,
为label中的第i个值,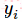 为经softmax归一化输出的vector中的对应分量,由此可以看出,当分类越准确时,所对应的分量就会越接近于1,从而
为经softmax归一化输出的vector中的对应分量,由此可以看出,当分类越准确时,所对应的分量就会越接近于1,从而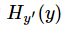 的值也就会越小。
的值也就会越小。
因此,在这里可以得到很好的理解(我自己的理解):当在time-step-i时刻,策略网络输出概率向量若与采样到的time-step-i时刻的动作越相似,那么交叉熵会越小。最小化这个交叉熵误差也就能够使策略网络的决策越接近我们采样的动作。最后用交叉熵乘上对应time-step的reward,就将reward的大小引入损失函数,entropy*reward越大,神经网络调整参数时计算得到的梯度就会越偏向该方向。
def create_softmax_network(self): W1 = self.weight_variable([self.state_dim, 20]) b1 = self.bias_variable([20]) W2 = self.weight_variable([20, self.action_dim]) b2 = self.bias_variable([self.action_dim]) #input layer self.state_input = tf.placeholder(tf.float32, [None, self.state_dim]) self.tf_acts = tf.placeholder(tf.int32, [None, ], name='actions_num') self.tf_vt = tf.placeholder(tf.float32, [None, ], name="actions_value") #hidden layer h_layer = tf.nn.relu(tf.matmul(self.state_input,W1) + b1) #softmax layer self.softmax_input = tf.matmul(h_layer, W2) + b2 #softmax output self.all_act_prob = tf.nn.softmax(self.softmax_input, name='act_prob') #cross entropy loss function self.neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.softmax_input,labels=self.tf_acts) self.loss = tf.reduce_mean(self.neg_log_prob * self.tf_vt) # reward guided loss self.train_op = tf.train.AdamOptimizer(LEARNING_RATE).minimize(self.loss) def weight_variable(self, shape): initial = tf.truncated_normal(shape) #truncated normal distribution return tf.Variable(initial) def bias_variable(self, shape): initial = tf.constant(0.01, shape=shape) return tf.Variable(initial)
四、序列采样:
def store_transition(self, s, a, r): self.ep_obs.append(s) self.ep_as.append(a) self.ep_rs.append(r)
五、模型学习:
通过蒙特卡洛完整序列采样,对神经网络进行调整。
def learn(self): #evaluate the value of all states in present episode discounted_ep_rs = np.zeros_like(self.ep_rs) running_add = 0 for t in reversed(range(0, len(self.ep_rs))): running_add = running_add * GAMMA + self.ep_rs[t] discounted_ep_rs[t] = running_add #normalization discounted_ep_rs -= np.mean(discounted_ep_rs) discounted_ep_rs /= np.std(discounted_ep_rs) # train on episode self.session.run(self.train_op, feed_dict={ self.state_input: np.vstack(self.ep_obs), self.tf_acts: np.array(self.ep_as), self.tf_vt: discounted_ep_rs, }) self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data
六、训练:
# Hyper Parameters ENV_NAME = 'CartPole-v0' EPISODE = 3000 # Episode limitation STEP = 3000 # Step limitation in an episode TEST = 10 # The number of experiment test every 100 episode def main(): # initialize OpenAI Gym env and dqn agent env = gym.make(ENV_NAME) agent = Policy_Gradient(env) for episode in range(EPISODE): # initialize task state = env.reset() # Train for step in range(STEP): action = agent.choose_action(state) # e-greedy action for train #take action next_state,reward,done,_ = env.step(action) #sample agent.store_transition(state, action, reward) state = next_state if done: #print("stick for ",step, " steps") #model learning after a complete sample agent.learn() break # Test every 100 episodes if episode % 100 == 0: total_reward = 0 for i in range(TEST): state = env.reset() for j in range(STEP): env.render() action = agent.choose_action(state) # direct action for test state,reward,done,_ = env.step(action) total_reward += reward if done: break ave_reward = total_reward/TEST print ('episode: ',episode,'Evaluation Average Reward:',ave_reward) if __name__ == '__main__': main()
reference:
https://www.cnblogs.com/pinard/p/10137696.html
https://github.com/ljpzzz/machinelearning/blob/master/reinforcement-learning/policy_gradient.py