最详细的spring-data-jpa入门(二)
前言
时隔一月,夏日渐离,秋风起兮,气温渐凉下,断更者忽觉不妥,似有事相忘,却不得要领,夜深,作罢,而转入被中,方得温暖,正欲入眠,忽闻窗外歌声,唱曰:断更有脸,鸽者无罪。吾大怒:谁断更啊?程序员的事,那能叫断更吗?
咕咕咕~
上一节我们讲解了spring-data-jpa最基础的架构和最简单的增删查改的实现,可以发现spring-data-jpa在简单增删查改的实现是非常友好的,甚至根本见不着sql语句的存在,让人直呼NB。
还记得上一节埋的几个坑吗,这一节就先把坑填了。
填坑1:实体类的主键生成策略详解
上一节讲到实体类时,介绍了很多注解的作用及其属性,举的例子是oracle数据库的实体类。
我们知道,oracle数据库的主键不是自增的,而是依靠序列来实现主键增长,要想实现一个表的主键是自增长的,我们首先要新建一个此表的序列,让它从1开始(或者从你想要开始的数字开始),每次调用都让序列+1,那么也就实现了主键的自增长。
上一节oracle的主键自增长的注解是这样的:
1.Oracle自增长主键策略: GenerationType.SEQUENCE
使用如下:
@Id
@Column(name = "ID")
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "JPA_USER_S")
@SequenceGenerator(sequenceName = "JPA_USER_S", name = "JPA_USER_S", allocationSize = 1)
private Long id;
解释一下这几个注解如何理解:
-
当生成策略为
SEQUENCE时,@GeneratedValue要配合@SequenceGenerator使用 -
首先
@Id代表它下方的属性是实体类的主键属性,也就是数据库的主键; -
其次
@Column(name = "ID")代表此实体类属性对应的数据库的列名是什么,需要进行关系映射; -
再看
@SequenceGenerator(sequenceName = "JPA_USER_S", name = "JPA_USER_S", allocationSize = 1),它代表着需要从数据库找到一个序列并在java中映射。sequenceName属性值:数据库中的序列名name属性值:这个序列名在java中要映射成的名字allocationSize属性值:这个序列的自增长步长是几
-
最后看
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "JPA_USER_S"),它代表着这个主键采取什么样的生成策略。strategy属性值:采取的主键策略是什么generator属性值:使用的序列的映射名是什么,这个映射名就是@SequenceGenerator中name的值
从上到下理解后有没有理顺这几个注解的先后呢?尤其是@SequenceGenerator和@GeneratedValue的关系。
至此oracle的主键策略注解才算基本讲完,然而并没有结束!
我们知道以序列作为自增长的数据库有Oracle、PostgreSQL、DB2,不过还有一个耳熟能详的数据库Mysql是可以不需要序列,直接定义主键自增长的,那么它就需要另一种生成策略。
2.Mysql自增长主键策略:GenerationType.IDENTITY
使用如下:
@Id
@Column(name = "ID")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
解释一下:
-
当生成策略为
IDENTITY时,@GeneratedValue单独使用 -
@GeneratedValue(strategy = GenerationType.IDENTITY),只需要这一个注解就可以实现mysql的主键自增长,我们知道mysql建表的时候可以给主键声明auto_increment,这就实现了自增长了,所以注解也相对简单。
在@GeneratedValue注解中我们只需要生成策略为IDENTITY,即可完成mysql数据库的主键自增长。
3.万能自增长主键策略:GenerationType.TABLE
使用如下:
@Id
@Column(name = "ID")
@GeneratedValue(strategy = GenerationType.TABLE, generator = "sequence_table")
@TableGenerator(name = "sequence_table",
allocationSize = 1,
table = "sequence_table",
pkColumnName = "sequence_name",
valueColumnName = "sequence_count")
private Long id;
解释一下:
- 当生成策略为
TABLE时,@GeneratedValue要配合@TableGenerator使用 @TableGenerator(name = "id_sequence", allocationSize = 1, table = "sequence_table",pkColumnName = "sequence_max_id", valueColumnName = "sequence_count"),它代表着需要在数据库建立一张索引表来帮助我们实现主键自增name属性值:建立的索引表在java中要映射成的名字allocationSize属性值:这个序列的自增长步长是几table属性值:建立的序列表的表名,缺省值:SEQUENCEpkColumnName属性值:建立的序列表的第一个列的列名,此列自动填充需要序列作为主键自增长的表的表名,缺省值:SEQ_NAMEvalueColumnName属性值:建立的序列表的第二个列的列名,此列自动填充pkColumnName所代表的表的下一个序列值,缺省值:SEQ_COUNT
@GeneratedValue(strategy = GenerationType.TABLE, generator = "id_sequence"),代表着这个主键采取什么样的生成策略,和Oracle中的解释一样strategy属性值:采取的主键策略是什么generator属性值:使用的映射名是什么,这个映射名就是@SequenceGenerator中name的值
一通解释看下来,可能会有点蒙,用示例来解释会更加直观:
TABLE生成策略示例:
3.1 新建一个部门实体类:JpaDepartment(属性很简单:id、部门名、五个系统字段)
@Data
@Entity
@Table(name = "JPA_DEPARTMENT")
@EntityListeners(AuditingEntityListener.class)
public class JpaDepartment {
@Id
@Column(name = "ID")
@GeneratedValue(strategy = GenerationType.TABLE, generator = "sequence_table")
@TableGenerator(name = "sequence_table",
allocationSize = 1,
table = "sequence_table",
pkColumnName = "sequence_name",
valueColumnName = "sequence_count")
private Long id;
@Column(name = "NAME")
private String name;
@Column(name = "OBJECT_VERSION" )
@Version
private Long objectVersion;
@Column(name = "CREATED_BY")
@CreatedBy
private String createdBy;
@Column(name = "CREATED_DATE")
@CreatedDate
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date createdDate;
@Column(name = "LAST_UPDATED_BY" )
@LastModifiedBy
private String lastUpdatedBy;
@Column(name = "LAST_UPDATED_DATE" )
@LastModifiedDate
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date lastUpdatedDate;
}
3.2 其他的respository、service、controller的代码略过,实现的还是和用户类一样的简单的增删查改;
这一次我并没有使用sql来新建一张表,仅仅是建立了一个实体类,这时候前面写的yml配置就开始发挥它的作用了,我们对jpa的配置如下:
spring:
jpa:
hibernate:
ddl-auto: update #自动更新
show-sql: true #日志中显示sql语句
解释一下:
-
ddl-auto: create:启动时删除上一次生成的表,并根据实体类生成表,表中数据会被清空ddl-auto: create-drop:启动时根据实体类生成表,程序关闭时表会被删除ddl-auto: update:启动时会根据实体类生成表,当实体类属性变动的时候,表结构也会更新,在初期开发阶段使用此选项ddl-auto: validate:启动时验证实体类和数据表是否一致,在数据结构稳定时采用此选项ddl-auto: none:不采取任何措施建议只使用update和none,前者适合初期建表,后者适合建表完成后保护表结构
-
show-sql: true,这个属性代表是否开启显示sql语句,为true我们就可以在每一次对数据库的操作在控制台看到所使用的sql语句了,方便找错,很方便的属性,建议开发时开启,上线后关闭
ddl-auto: update时,jpa会根据实体类帮助我们创建表~
3.3 有了部门实体类JpaDepartment,让我们启动看一下实际效果:
3.3.1 控制台的输出:
Hibernate: create table jpa_department (id number(19,0) not null,
created_by varchar2(255 char),
created_date timestamp,
last_updated_by varchar2(255 char),
last_updated_date timestamp,
name varchar2(255 char),
object_version number(19,0),
primary key (id))
Hibernate: create table sequence_table (sequence_name varchar2(255 char) not null, sequence_count number(19,0), primary key (sequence_name))
Hibernate: insert into sequence_table(sequence_name, sequence_count) values ('jpa_department',0)
-
1.创建了一张名为
jpa_department的表,各个列名皆为实体类属性名,长度取的默认值 -
2.创建了一张名为
sequence_table序列表(table属性的值),- 列名1:
pkColumnName的值(sequence_name),代表此行索引值所属表, - 列名2:
valueColumnName的值(sequence_count),代表下一次插入的索引值(在插入前会提前+1)
- 列名1:
-
3.根据
@TableGenerator所在类映射的表名插入了一行数据,分别为('jpa_department',0),也就是代表jpa_department这张表下一次插入的索引值是1(0+1)
3.3.2 借助DateBase工具可以看到表全貌:
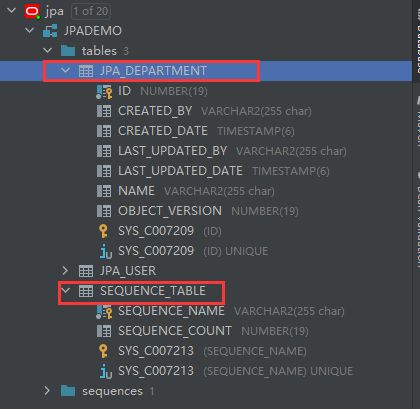
缺少的表,jpa通过实体类对表的映射补全了。
新增了我们所需的JPA_DEPARTMENT表和一张对主键实现自增长的序列表SEQUENCE_TABLE
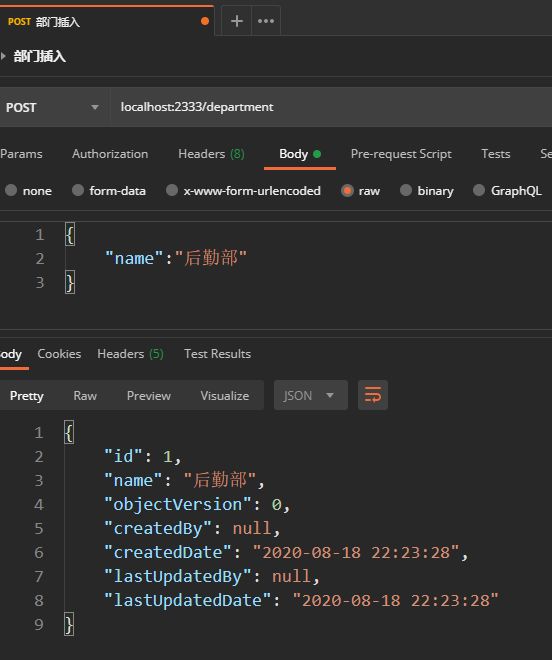
3.3.3 进行一次插入操作
postman:
控制台输出:
Hibernate: select tbl.sequence_count from sequence_table tbl where tbl.sequence_name=? for update
Hibernate: update sequence_table set sequence_count=? where sequence_count=? and sequence_max_id=?
Hibernate: insert into jpa_department (created_by,
created_date,
last_updated_by,
last_updated_date,
name,
object_version,
id)
values (?, ?, ?, ?, ?, ?, ?)
一次插入拥有三条sql语句
- 1.会等待行锁释放之后,返回
sequence_table表的查询结果,返回jpa_department的当前索引值 - 2.更新操作,把
sequence_table表中的sequence_count的值+1 - 3.把更新后的
sequence_count值当成主键值插入到jpa_department表中作为主键值
在这三条sql语句执行后,显然jpa_department这一次插入的主键值为1,postman返回的json数据也证实了这一点
4.AUTO自动判断主键策略(缺省策略):
使用如下:
@Id
@Column(name = "ID")
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
解释一下:
-
当生成策略为
AUTO时,@GeneratedValue单独使用 -
@GeneratedValue(strategy = GenerationType.AUTO),JPA会自己从从Table 策略,Sequence 策略和Identity 策略三种策略中选择合适的主键生成策略;strategy属性值:主键生成策略,什么都不写即缺省值即为AUTO
AUTO生成策略示例:
4.1 仍然使用的是刚刚的部门类JPA_DEPARTMENT,把已创建的表删除,修改生成策略为auto
@Data
@Entity
@Table(name = "JPA_DEPARTMENT")
@EntityListeners(AuditingEntityListener.class)
public class JpaDepartment {
@Id
@Column(name = "ID")
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(name = "NAME")
private String name;
@Column(name = "OBJECT_VERSION" )
@Version
private Long objectVersion;
@Column(name = "CREATED_BY")
@CreatedBy
private String createdBy;
@Column(name = "CREATED_DATE")
@CreatedDate
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date createdDate;
@Column(name = "LAST_UPDATED_BY" )
@LastModifiedBy
private String lastUpdatedBy;
@Column(name = "LAST_UPDATED_DATE" )
@LastModifiedDate
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date lastUpdatedDate;
}
4.2 运行程序看一下jpa自动帮助我们做了什么
Hibernate: create table jpa_department (id number(19,0) not null,
created_by varchar2(255 char),
created_date timestamp,
last_updated_by varchar2(255 char),
last_updated_date timestamp,
name varchar2(255 char),
object_version number(19,0),
primary key (id))
Hibernate: create sequence hibernate_sequence start with 1 increment by 1
- 创建了
jpa_department这张表 - 创建了一个名为
hibernate_sequence的序列
显然jpa识别到了我连接的数据库是oracle数据库,所以采取的是SEQUENCE生成策略,它帮助我们建立了一个名为hibernate_sequence的序列,但是这个名字显然是无法一眼看出来是属于谁的序列的,不方便对序列的维护,所以不推荐使用auto策略哦
5.总结-主键策略:
1.主键生成策略分为四种:SEQUENCE策略、IDENTITY策略、TABLE策略、AUTO策略;
2.SEQUENCE策略适合拥有序列的数据库,比如Oracle;
3.IDENTITY策略适合拥有主键自增长的数据库,比如Mysql;
4.TABLE策略是通过一张序列表来维护主键插入的值的,所以适合所有数据库;
5.AUTO策略是jpa自行判断使用上面三个中的哪一个作为主键生成策略;
6.推荐使用SEQUENCE和IDENTITY策略,开发人员应该自行判断使用的是何种数据库,而不是由jpa进行判断。
填坑2:系统字段:注入创建人和更新人
1.复习
1.1 上一节讲到修饰五个系统字段的注解:
@Version:版本号;进行update操作时启动乐观锁,@Version修饰的字段值与数据库中字段值一致才能进行修改@CreatedDate:创建时间;进行insert操作时,将当前时间插入到@CreatedDate修饰字段中;进行update操作时,会随实体类中的@CreatedDate修饰的字段值进行修改@CreatedBy:创建人;进行insert操作时,将当前用户名插入到@CreatedBy修饰字段中;进行update操作时,会随实体类中的@CreatedBy修饰的字段值进行修改@LastModifiedDate:最后一次修改时间;进行update操作时,将当前时间修改进@LastModifiedDate修饰字段中;进行insert操作时,将当前时间插入到@LastModifiedDate修饰字段中@LastModifiedBy:最后一次修改的修改人;进行update操作时,将当前修改人修改进@LastModifiedBy修饰的字段中;进行insert操作时,将当前用户名插入到@LastModifiedBy修饰字段中
1.2 启动审计:
1.2.1 在Springboot启动类上加上启动审计注解:@EnableJpaAuditing
@EnableJpaAuditing
@SpringBootApplication
public class SpringContextApplication {
public static void main(String[] args) {
SpringApplication.run(SpringContextApplication.class, args);
}
}
1.2.2 在实体类上方加上监听注解:@EntityListeners(AuditingEntityListener.class)
@Data
@Entity
@Table(name = "JPA_USER")
@EntityListeners(AuditingEntityListener.class)
public class JpaUser {
//...
}
@EntityListeners该注解用于指定Entity或者superclass上的回调监听类;AuditingEntityListener这个类是一个JPA Entity Listener,用于捕获监听信息,当Entity发生新增和更新操作时进行捕获。
当设置完这两个注解后@CreatedDate、@LastModifiedBy这两个注解对于创建时间和修改时间的注入就ok了,但是对创建人、修改人的注入却为null,毕竟jpa并不知道当前是谁在操作数据,需要我们来进行提供;
2.注入创建人和更新人
那么jpa从哪里得到它想要注入的创建人或者更新人信息呢?
我们需要一个配置类,并且实现AuditorAware接口
2.1 测试
2.1.1 建立配置文件夹config,创建配置类UserAuditor
@Configuration
public class UserAuditor implements AuditorAware<String> {
/**
* 获取当前创建或修改的用户
*
* @return 获取当前创建或修改的用户Uid
*/
@Override
public Optional<String> getCurrentAuditor() {
return Optional.of("俺是测试创建者");
}
}
很容易理解的一个配置,它返回一个Optional对象,对象内的String值便是创建人和更新人根据实际情况去注入的值。
关于
Optional,不了解的同学可以去度娘,java8很好的一个防止空指针的类
2.1.2 去postman调用新增用户的接口
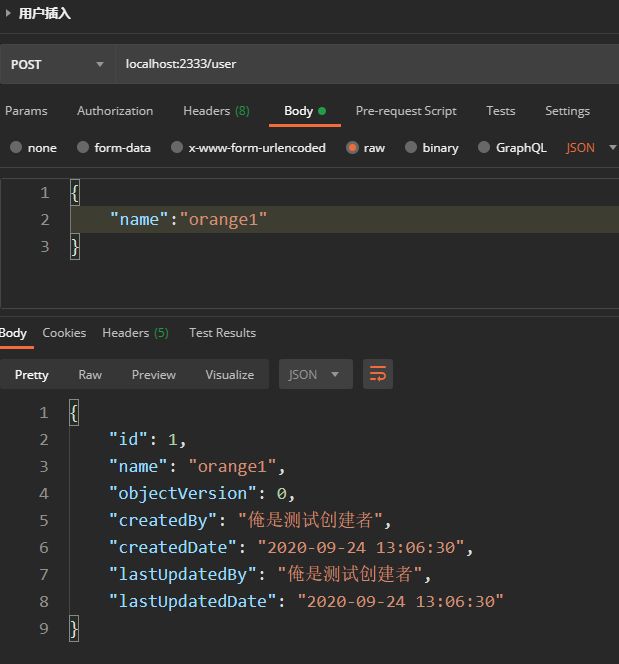
分析:
可以看到,createdBy和lastUpdatedBy都进行了自动注入,全部变成了在UserAuditor中设置的返回值
2.1.3 调用更新用户接口
我们手动将UserAuditor中的返回值改变,重启应用再试试更新用户接口
@Configuration
public class UserAuditor implements AuditorAware<String> {
/**
* 获取当前创建或修改的用户
*
* @return 获取当前创建或修改的用户Uid
*/
@Override
public Optional<String> getCurrentAuditor() {
return Optional.of("俺是测试更新者");
}
}
更新接口调用:

分析:
可以看到,我只将name的值改变为orange1-update,其他不变,调用接口后name、objectVersion、lastUpdatedBy、lastUpdatedDate的值被改变了,系统字段的改变很符合我们的需求;
更新时对更新者的注入也是从UserAuditor中拿取的,jpa自动判断是不是更新操作,是就把当前UserAuditor获取到的返回值注入更新人字段中;
2.2 session保存用户信息并进行审计注入
2.2.1 具体思路
正式项目当然不像测试那样可以把UserAuditor的返回值给改了再重启项目,我们需要实时获取到用户的uid并注入到创建人和更新人字段中,这时候我们就需要一个东西帮助我们认知当前用户是谁,而http协议是无状态的,不能像服务器一样一直保存一个东西,于是出来了很多对于用户认证的解决方案,比如session,cookie,token等;
我们这里使用最简单session存储用户登录信息,当用户登录完后,进行新增和修改操作时,再从seesion中获取到用户数据,将其通过UserAuditor类来返回给jpa的审计功能
2.2.2 实现登录功能
登录需要什么呢?账号和密码,这里我们再简单一点,不需要密码,只要输对了用户名就给这个用户一个session。(小声嘀咕:毕竟我数据库设计忘了密码字段了)
2.2.2.1 在JpaUserController添加
/**
* 登录
* @param session 拿到session
* @param jpaUser 前端传来的数据:有效字段只有name
* @return 有此用户名返回ok,没有则error
*/
@PostMapping("/login")
public String login(HttpSession session,@RequestBody JpaUser jpaUser){
return jpaUserService.login(session,jpaUser);
}
2.2.2.2 JpaUserServiceImpl实现逻辑:从JpaUser表根据name查找用户,有就生产session,返回ok;没有就不生成session,返回error
@Override
public String login(HttpSession session, JpaUser jpaUser) {
// 查询
JpaUser user = jpaUserRepository.findByName(jpaUser.getName());
if (user !=null){
session.setAttribute("jpaUser",jpaUser);
return "ok";
}else {
return "error";
}
}
2.2.2.3 jpaUserRepository.findByName()实现:jpa的单表查询很香,此篇不细讲,自己体会
public interface JpaUserRepository extends JpaRepository<JpaUser, Long> {
// 根据name查询用户,无需sql
JpaUser findByName(@Param("name") String name);
}
2.2.3 修改UserAuditor逻辑
@Configuration
public class UserAuditor implements AuditorAware<String> {
/**
* 获取当前创建或修改的用户
*
* @return 获取当前创建或修改的用户Uid
*/
@Override
public Optional<String> getCurrentAuditor() {
// request声明
HttpServletRequest request;
// 工号
String username = "anonymous";
// 拿到Session
ServletRequestAttributes requestAttributes= (ServletRequestAttributes)RequestContextHolder.getRequestAttributes();
if (requestAttributes !=null){
request = requestAttributes.getRequest();
HttpSession session = request.getSession();
Object obj = session.getAttribute("jpaUser");
if (obj instanceof JpaUser){
JpaUser jpaUser = (JpaUser) obj;
username = jpaUser.getName();
}
}
return Optional.of(username);
}
}
session大家应该耳熟能详,但一般我们是在controller层拿到request,再拿session,或者直接在controller层拿到session,在其他非controller类中如何拿session呢,使用RequestContextHolder上下文容器
我具体解析一下代码:
- 声明一个
HttpServletRequest对象request,声明一个username字符串,默认值为anonymous(匿名) - 通过
RequestContextHolder拿到request的属性,转换成可以得到request对象的ServletRequestAttributes - 判断是否当前线程的请求属性为空,为空则直接返回username默认值,不为空继续
- 不为空就可以拿到我们熟悉的request对象啦,它里面存着session信息
- 用Object类接收约定好的key值(我这里叫jpaUser),如果存储了session,那么拿到的对象类型一定是
JpaUser,进行强转后拿到存储在其中的name值 - 再返回拥有真实用户名的username,接下来就交给jpa审计去注入了
就是酱紫~
2.2.4 升级后的测试
由于没有前端页面,我懒的写了哈哈,用postman模拟数据的同时还要模拟cookie信息,这样才能让程序知道你是哪个session
2.2.4.1 去数据库看一眼有哪些用户
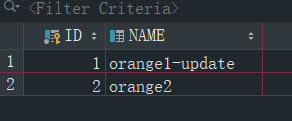
2.2.4.2 就用orange2来登录

2.2.4.3 返回ok代表登录成功,那么服务器此时已经存储了orange2的session信息了,我们需要让服务器知道我们是这个session的拥有者,那么查看这次返回的headers信息
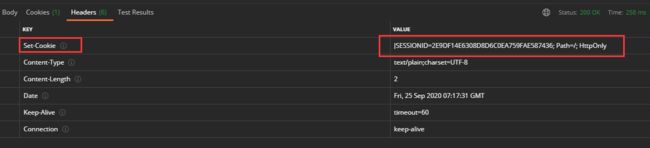
2.2.4.4 可以看到cookie附带了JSESSIONID=2E9DF14E6308D8D6C0EA759FAE587436; Path=/; HttpOnly这一串信息,JSESSIONID表示你这个用户的sessionId,它就是服务器如何知道你是谁的原因,浏览器会自动带上这个cookie去访问服务器,服务器会自动解析,拿到属于你的那个session;
知道了这点,我们就可以模拟浏览器的做法,把JSESSIONID的键值放到cookie就可以模拟了
2.2.4.5 点击右上角的cookies
2.2.4.6 添加域名信息:本地自然是localhost
2.2.4.7 在其下添加cookie,只需要改变第一个键值就行
![]()
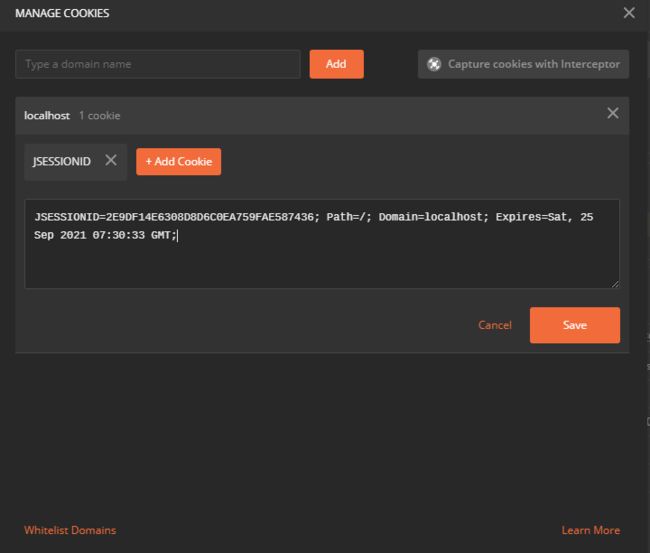
配置一次后,以后会自动设置JSESSIONID的值,一劳永逸
2.2.4.8 使用用户插入接口
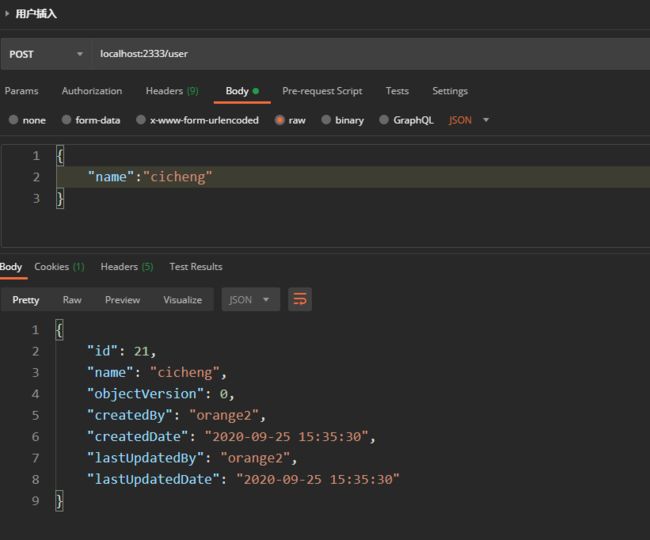
可以看到创建者和修改者都是orange2,证明程序正确,至此Jpa审计内容大致结束,这里仅使用了session来存储用户信息,之后可能会对sping-security进行详细讲解(挖坑挖坑!)
3.总结-注入创建人和更新人:
1.通过对配置类UserAuditor(继承了AuditorAware进行返回值的逻辑加工,就可以实现jpa对5个系统字段的审计注入,非常nice
2.通过session、token、cookie等方式可以保存用户的信息,配合jpa审计功能达到自动注入的效果,非常nice
鸽鸽复鸽鸽,鸽子何其多~