Oracle的高级查询-分组、连接、子查询、分页
Oracle的高级查询
概述:Oracle作为一个老牌数据库,风风雨雨经历了二三十年。我们平时工作的时候,或多或少也会接触到Oracle数据库的使用。在数据库开发中,简单的单表操作,对大部分刚入行的新人来说,不会有太大的问题。
但是随着我们所开发业务系统的功能多样化,为了实现复杂的需求,我们就会使用的高级查询。Oracle高级查询中,比较难理解的是分组查询,连接查询以及子查询,以及基于子查询的分页查询。因为这些高级查询的结果会和原有的表结构差异很大,不太好理解。
下面我将结合Oracle中内置的Scott账号,对Oracle中的高级查询在进行一些回顾。
一.scott系统内置账号
Oracle数据库成就了拉里·埃里森,从埃里森32岁一无所有,到20年后的硅谷首富,钢铁侠原型,成就了一段传奇。
不过和拉里·埃里森同时期的技术人员Scott就没有像埃里森那样闪亮,Scott在Oracle中除了一个账号,就什么都没有留下。不过我们要练习Oracle数据库,使用Scott账号还是很不错的,通过Scott账号内置的几张表,我们就能实现出一些比较高级的查询。
1.开启scott账号
- 开启scott账号的方法,用system账号登录,因为system具有dba权限,通过解锁账号的sql命令
--解锁Scott账号
alter user scott account unlock;
账号解锁后,再给scott账号重置密码,这里密码我们用tiger
--重置scott密码,设置为tiger
alter user scott identified by tiger;
此时scott具有默认的两个角色分别是connect角色和resource角色,就可以用于对表进行基本操作。
系统切换到scott账号下
2.scott账号下的员工表和部门表
Scott账号下有员工表,员工表为:emp,要查看员工表的数据,可以采用查询语句
--查询所有员工
select * from emp;
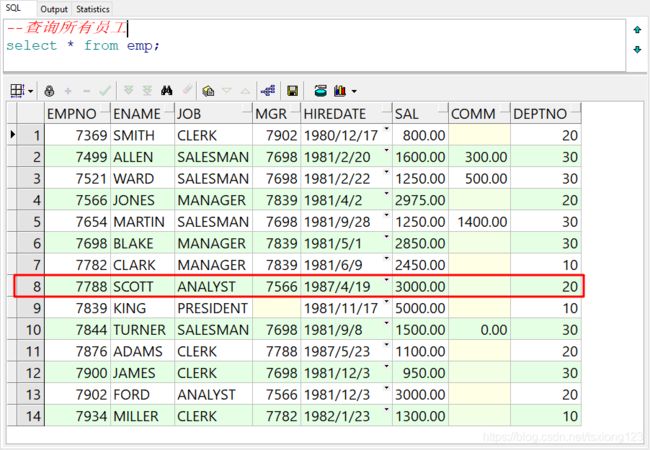
所用员工中,SCOTT的的工号是7788,他的岗位(Job)为分析师(Analyst),领导的工号是7566,入职日期是1987年4月19日,当时它的薪资是3000美元,没有奖金,在20号部门工作。
该账号下还有一个部门表,要查看部门表下面的数据
--查询所有部门
select * from dept;
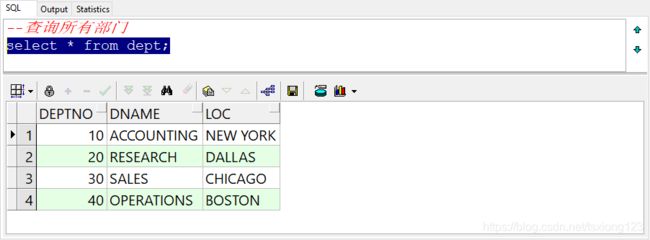
通过部门表,可以得知,scott所在的20号部门是研发部,位于达拉斯(美国得克萨斯州东北部城市),接下来我们将用这2张表进行Oracle的高级查询
二.聚合查询
我们要统计公司中有多少员工,刚才通过select * from emp语句,查询出得结果我们数了一下有14条记录,每行记录前面也有序号,数起来也比较方便。
难道以后我们都是通过数一数的方式得到员工总数的么?其实这个方法是可行的,就是有点弱智,不符合我们程序人员的身份。
1.聚合查询的应用场景
对于统计总数,平均数,最大值等操作,Oracle中为我们提供了专门的聚合函数。使用聚合函数查询就是聚合查询,聚合函数有个非常明显的特点,就是被查询的表,有多行记录,而查询出得结果,只有一行数据,简而言之就是将多行数据变为了一行数据,有的地方也称为多行函数。
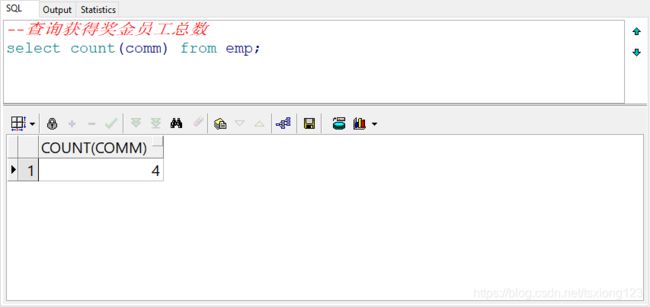
--查询员工总数
select count(1) from emp;
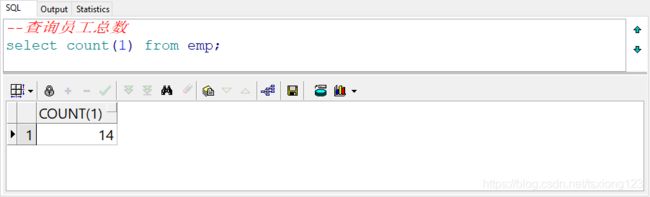
原始数据有14行,通过聚合查询,最终的表结构是一行一列的结果。count(1)同count(deptno)一样
2.聚合函数的空值处理
需要注意的地方,对于聚合函数中的count对空值得处理
聚合函数count只对不为null的列进行统计,这是Oracle数据库在使用count的一个特性,对单字段统计的时候,不同字段的统计会有不一样结果,因为表中存在为空的值,这点尤其要注意
3.聚合查询总结:
- 常用的聚合函数有五种,分别是count,max,min,avg,sum。其中count可以作用于任何字段,而后面的四种只能作用于数字型的字段(NUMBER);
- 在聚合函数中,一般使用count(1)比count(*)要好一些,count(1)的意思是只对第一列进行统计总数,第一列也通常为表格的主键,效率会高一些;
- count作用的列,不包含空值的数据,如select count(comm) from emp统计得到的结果是4,因为只有4名员工的奖金的不为空值;
- count可以和distinct组合使用,如统计该部门一共有多少种岗位,统计岗位种类数目的时候,要去除重复的列,得到的sql查询语句为:select count(distinct job) from emp 执行的结果为 5;这五个岗位分别为CLERK,SALESMAN,PRESIDENT,MANAGER,ANALYST,感兴趣的朋友可以去原始表中找一找。
三.分组查询
分组查询是数据库查询中一个难以理解的地方,因为分组查询改变了表的原始结构。先来说说什么是分组查询。
1.分组查询的机制
分组查询是根据某种规则,将数据分组,每组数据再通过聚合函数,转换成为一行数据,最后再将每行数据联合在一起,得到最终的数据呈现给用户。
分组查询常常用于统计。如查询每个部门的最高薪资:
--统计每个部门的最高薪资
select deptno,max(sal) from emp group by deptno order by deptno asc;
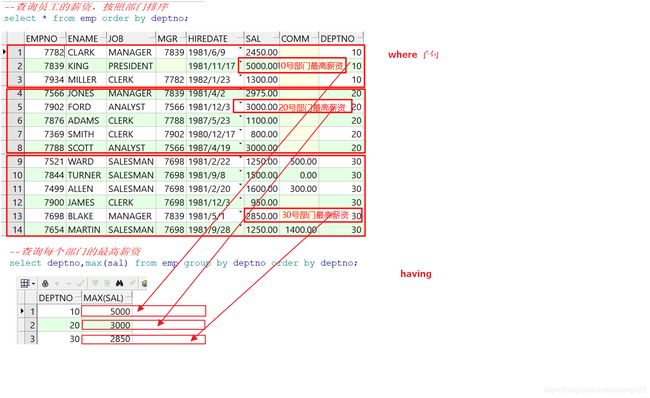
这里使用order by排序是为了方便我们查看原始数据,便于学习理解,实际使用中,不使用order by不会对分组的查询的最终结果产生影响。
2.分组查询的语法
select {column}, --group by后面的列select后面的列一致
聚合(聚合列) --其他字段采用聚合确保行数匹配
from {table} --需要被统计分组数据的原始表
where {before_condition} --分组前的数据进行筛选,使用where
group by {column} --被用于分组的那一列
having {after_condition} --对分组后的数据进行筛选
- 说明一哈
{column}:表示我们要分组的列,如我们依据部门进行分组,column就是deptno
聚合(聚合列):这里就要用到聚合函数,压缩行数,不然行数不匹配就报错了
{table}表示原始数据所在的表格,里面可以是一个返回多行多列的子查询,可以使是视图
{before_condition} 里面的筛选条件,对分组前的数据筛选
group by {column}:里面的column和select后面的column要一样
{after_condition}:对分组查询后的数据进行筛选
3.分组查询子句执行顺序
我们在开发中,使用的分组查询的语法顺序是:
select -> 聚合 -> from ->where ->group by ->having
而实际上,在Oracle中,对SQL中的每个子句,执行顺序和编写顺序是不同的,采用下列方式执行
from ->where ->group by ->聚合-> having ->select
正因为执行顺序的不同,在条件判断中,不能使用聚合函数中所用到的别名,这点在别名的使用的时候尤其要注意。
4.分组查询的应用场景
分组查询除了用于一般的统计,还有很多方便灵活的用法。
举一个开发中的例子:我们设计权限系统中的用户名必须唯一,但是因为起初设计的原因,并没有加入数据库的唯一性约束,Java逻辑中也没有做唯一性的验证判断,或者绕开了Java的唯一性校验规则,这个是很容易发生的,我们数据不小心进入到了系统,并没有被我们发现。程序大部分用户是没有问题的,可是一旦用了同名的账号登录,程序就会发生异常,系统容错没有做好的话,功能就失效了。
我们要找到这些重复的脏数据,就比较头疼了,因为这些坏数据时刻干扰着我们的逻辑,我们要清理掉坏数据的前提是能够找到这些重复的数据,这个时候,我们的分组查询就大显神威了。
这里用emp表的job字段模拟重复数据,我们的查询为
--得到job中不唯一的岗位,并统计在数据中出现的次数
select job,count(job) from emp group by job having count(job) >1;

那如果是找出重复的用户名,就更简单了
select username,count(username) from user group by username having count(username) >1;
通过这种分组查询,找出了用户名,再通过其他操作,对这些用户名重复的数据进行处理就简单多了。
5.分组查询总结
只要理解了分组查询的作用机制,使用规则,结合使用场景,分组查询的优势还是很明显的,使用的时候注意以下几点就没问题
- 1.被分组的那一个列要放在group by后面,同时要作为查询列,其他列采用聚合函数;
- 2.where后面跟着的查询条件为分组前的数据筛选,having分组后的数据筛选;
- 3.条件中,不能使用别名,因为条件子句是最先执行的;
四.连接查询
在学习连接查询的时候,我们要搞清楚连接查询的由来。根据数据库规范化设计理论,我们为了减少数据冗余,完成数据更新,修改的一致性,要对数据库表进行拆分。也就是出现了数据库一对多,多对多的关系。
但是我们在开发应用层面上,有需要用到这些数据,如我们想知道Scott的部门名称,就需要先去员工表中找到scott的部门号,再到部门表中根据部门号,找到部门名称。
我们最终得到的数据要通过员工表和部门表的拼接,这个时候我们要用到的连接查询。

连接查询中: 交叉连接是外连接的超集,外连接是内连接的超集。
如我们要得到部门以及部门员工信息,部门表中有4条记录,员工表中有14条记录,采用交叉连接,将会得到14*4=56条记录,这种交叉连接的方式,也叫笛卡尔集。
外连接就是要在这56条记录中,筛选出符合条件的数据。如查询部门以及部门下的员工信息
--查询部门以及部门下的员工信息
select * from dept left join emp on dept.deptno = emp.deptno
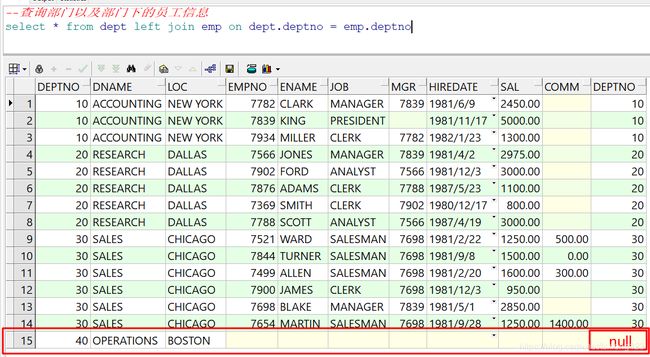
外连接分为2中,分别为左外连接,和右外连接,他们的作用原理一样的,只是方向不一样而已。
如上面的写法可以改写为:left join/right join
--查询部门以及部门下的员工信息
--左连接的方式
select * from dept left join emp on dept.deptno = emp.deptno;
--右连接的方式
select * from emp right join dept on dept.deptno = emp.deptno;
最终得到的数据,我们观察,是15条记录,可是员工总数有14条,因为40号部门底下没有员工,我们的需求是所有部门信息,所以最终结果要保留40号部门。是满足我们的需求的。
如果我们要在外连接的基础上,不保留40号部门,我们就要用到内连接,内连接是外连接数据结果集的子集。
内连接的写法关键字 inner join
select * from dept inner join emp on dept.deptno = emp.deptno;
此时,将自动过滤 结果集中deptno为空值的记录。
内连接还有一种简便的写法,即为逗号(,)写法
select * from dept,emp where dept.deptno = emp.deptno;
这里再做一个需求理解上的区分:
查询所有员工以及所在部门信息和查询所有部门以及部门下的员工信息,最终查询的结果是一样的么?
我们要认真审题:是不是所有的员工都有部门号?是不是所有的部门下面都有员工?
- 规律一:如果所有的员工都有部门号,所有的部门下都有员工
内连接,外连接,左连接以及右连接,最终查询的结果集的大小是一样的,只是结果集的字段顺序有些差异而已,我们通过对表起别名,可以最终控制字段显示的顺序,达到我们的效果。这个场景下,我们为了省事,不适用join关键字,采用逗号写法是完全没有问题的,也就是说,我们使用的内连接查询。 - 规律二:如果有的员工没有部门号,如刚到公司实习生还没有定部门,但也是公司的员工啊;或者有的部门底下没有员工,如刚成立的新部门,或者部门底下的员工都跑路了。这个时候尤其要注意我们的需求描述的差异,如果我们的需求描述中出现“所有员工”、“全部部门”、“每个”等字眼,要认真分析需求,或者隐含着查询所有等这层意思,就一定不能用内连接,此时的内连接,会自动过滤掉哪些连接字段为空值的哪些数据,最终数据时外连接查询的子集
五.子查询
子查询是我认为Oracle中还比较好理解的一种查询用法
1.什么是子查询
子查询就是把一个查询的结果作为另外一个查询的条件进行查询。
平时用子查询的地方还挺多的,在通俗一点,我认为子查询就是括号查询,因为子查询的语句中,都会有一个成对的小括号(),在小括号里面做内层子查询,括号外面的是外层查询,子查询也成为了SubQuery,我们如果用到了查询分析器Explain,查询分析器Explain会告诉我们是不是用到了SubQuery
2.子查询返回一行一列
这部分还是比较好理解的,子查询返回的是一行一列,将返回值作为条件进行判断,如我们的=,>,<
举个例子:我们查询比scott薪资高的员工信息
第一步:我们要得到scott的薪资 select sal from emp where ename = ‘SCOTT’,
第二步:就可以将第一步的结果作为条件了 select * from emp where sal > (step1)

通过上面的查询,我们得到了一个重要的信息:SCOTT当年在公司的待遇还是蛮不错的,毕竟比他薪资高的人也只有KING了
3.子查询返回多行一列
- 如果内层子查询返回的结果是多行一列的话,就要用到in,此时的内层子查询返回的就是一个结果集合,用in进行匹配的话,就是集合运算
4.子查询返回一张表
通过子查询返回一张表的特性,我们可以快速的创建、复制一张表操作
create table temp_table as {subquery};
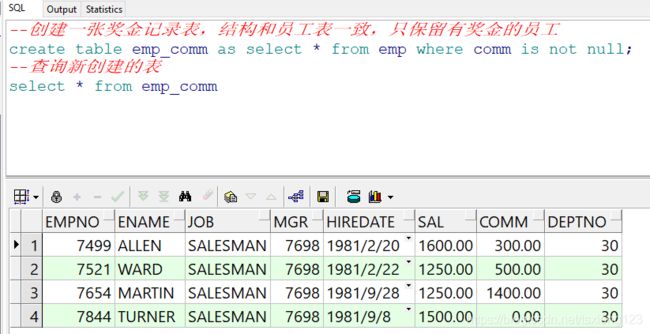
快速的备份、复制一张表,非常的方便
通过子查询返回的表,通过起别名,依然可以进行分组查询,连接查询,就如同真实存在的一张表一样进行操作,都是没问题的。
5.巧妙的实现排名的功能
--得到薪资排名
select e1.*,(select count(1)+1 from emp e2 where e2.sal > e1.sal) rk
from emp e1 order by rk;
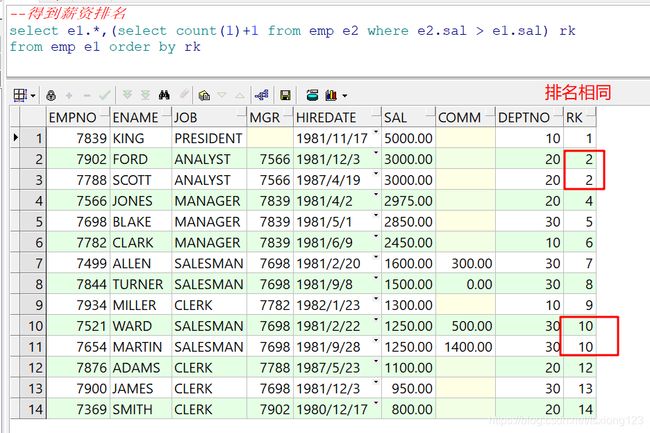
上述查询过程进行分析,匹配到比KING薪资高的人,有0人,所以排名第1。
比SCOTT薪资高的人只有1人,所以排名第2,同样比FORD薪资高的人,也只有KING一人,也是排名第2。
到JONES的时候,比JONES薪资高的人有3人,排名第4。按照这个规律,查询出比某个员工高的人的人数,在数目的基础上+1,就得到了此员工的排名,所以采用了count(1)+1的写法。
所以利用子查询,十分巧妙的实现了薪资的排名功能。
六.分页查询
1.ROWNUM的特性
Oracle的分页和MySQL数据库不一样,不支持limit关键字,但是Oracle有自身的特性,支持ROWNUM字段。Oracle在使用ROWNUM字段的时候,查询出结果集中,ROWNUM始终是从1开始的,这就需要我们在对ROWNUM进行条件筛选的时候,不能大于某个正整数。如果采用了ROWNUM大于某个正整数的写法,就会查询不到任何数据。
2.利用ROWNUM和子查询进行分页
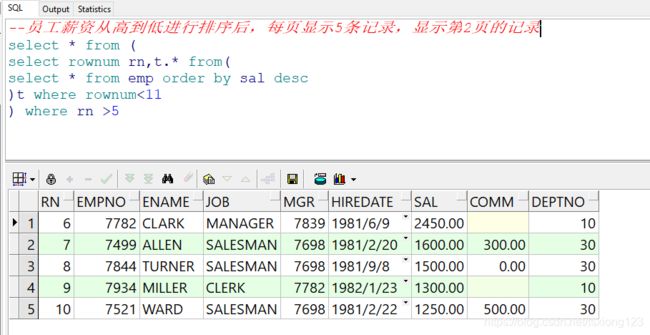
在ORACLE进行分页的时候,数据的开始行号和结束行号在分页之前已经计算完毕,如对员工薪资从高到低进行排序后,每页显示5条记录,显示第2页的记录。开始行就是6,结束行就是10.
--对员工薪资从高到低进行排序后,每页显示5条记录,显示第2页的记录
select * from (
select rownum rn,t.* from(
select * from emp order by sal desc
)t where rownum <= 10
) where rn => 6
分页查询还有一种写法,使用between关键字写法如下
select * from (
select rownum rn,t.* from(
select * from emp order by sal desc
)t
) where rn between 6 and 10
在数据量小的时候,两种查询差别不是很大。但是对于大数据量的分页,第二种的查询效率没有第一种查询效率高,因为Oracle会默认对子查询的条件进行优化,在CBO 优化模式下,将外层的查询条件推到内层查询中,以提高内层查询的执行效率。
对于第一种方式的查询语句,第二层的查询条件WHERE ROWNUM <= 10就可以被Oracle推入到内层查询中,这样Oracle查询的结果一旦超过了ROWNUM限制条件,就终止查询将结果返回了。
而第第二种查询语句,由于查询条件BETWEEN 6 AND 10是存在于查询的第三层,而Oracle无法将第三层的查询条件推到最内层(即使推到最内层也没有意义,因为最内层查询不知道RN代表什么)。
因此,对于第二个查询语句,Oracle最内层返回给中间层的是所有满足条件的数据,而中间层返回给最外层的也是所有数据。数据的过滤在最外层完成,显然这个效率要比第一个查询低得多。
总结一下分页的用法:
- 1.分页查询的时候,有排序需求的,需要在最内层子查询进行排序;
- 2.rownum不能大于某个正整数,只能小于某个正整数;
- 3.外层查询要用到内层查询的rownum列,要给rownum起别名;
- 4.数据量较大的情况下,采用内层子查询加条件限制,能提高分页查询效率。
注意点:在Java代码做分页的时候,特别是使用MyBatis分页插件的时候需要注意:
依据Oracle分页的原理,我们在业务sql后面不能写分号;如果写了分号,就要对分号进行处理,如果分页插件没有对分号进行处理,在对原有SQL语句进行解析的时候,就前后拼接Oracle分页语法规则,此时的分号就会执行不成功。不过,如果分页插件对原始SQL语句做了分号截断处理,就没有这个问题了。
---分页插件作用机理
select * from (select rownum rn,t.* from( ---分页插件帮我们在原来的sql语句前拼接
select * from emp order by sal desc --我们自己编写的业务代码,如果分页插件没有分号检测截取操作,就我们就不能再此后面加上分号
)t where rownum <= 10) where rn => 6 --分页插件帮我们在原来的sql语句后拼接
总结
Oracle的高级查询对比基本的单表查询看起来会显得复杂一些,但正是因为如此,Oracle的查询语句体现出自身非常灵活的地方。
我们在日常的数据库开发中,能够熟练的掌握高级查询技巧,就能够提高我们的开发效率,会有更多的时间陪伴我们的家人。
最后感谢我的女朋友李强妮同学对我工作的支持,鼓励我坚持技术博客的写作。
作者:熊鑫
邮箱:[email protected]
转载请告知