Python正则表达式
正则表达式(regular expression,re)是由字符和特殊符号组成的字符串,其实际上是一种字符串模式,对于符合模式的多个字符串常用数据检索、地址匹配、文本处理等方面。
文章目录
-
- 正则表达式特殊符号
- 正则表达式构建
- 正则表达式应用
正则表达式特殊符号
Python标准库中的re模块中定义了很多正则表达式特殊符号,可归纳为以下几个方面:
定义匹配字符的特殊符号:
| 符号 | 解释 | 示例 |
|---|---|---|
| [] | 方括号,用于产生一个字符集合,表示字符集合中的任意一个字符。 方括号内的“-”符号表示某个范围内的字符集合, 方括号开头的“^”符号表示除方括号内已列出的字符以外的其他字符集合 |
[agiser]表示a,g,i,s,e,r中任何一个字符 [a-z]表示任何一个小写字母 [0-9]表示任何一个十进制数字 [^agister]表示除a,g,i,s,e,r外的任何一个字符 |
| . | 点符号,表示除换行符之外的任何一个字符(如果是一般的点符号,则前面加\表示) | b.b 表示三个字符组成的字符串,前后为b,中间字符为除换行符之外的任何一个字符 |
| \ | 与其他字符组合表示具有特定意义的特殊字符 | \d 表示任意数字字符,同[0-9] \D 表示任意非数字字符 \w 表示任意数字字母字符,同[A-Za-z0-9] \W 表示任意非数字字母字符 \s 表示空字符 \S 表示非空字符 |
定义匹配字符串(或正则表达式)出现次数的特殊符号:
| 符号 | 解释 | 示例 |
|---|---|---|
| | | 多个字符(或正则表达式)中的任何一个 | A|B表示A和B中任何一个 |
| * | 前面定义字符(或正则表达式)0个或多个 | [0-9]*表示任何一个数字0个或多个 |
| + | 前面定义字符(或正则表达式)1个或多个 | [0-9]+表示任何一个数字0个或多个 |
| ? | 前面定义字符(或正则表达式)0个或1个 | [0-9]表示任何一个数字0个或1个 |
| {N} | 前面定义字符(或正则表达式)N个 | [0-9]{3}表示任何一个数字3个 |
| {M,N} | 前面定义字符(或正则表达式)M~N个 | [0-9]{3,5}表示任何一个数字3~5个 |
定义匹配字符串位置的特殊符号:
| 符号 | 解释 | 示例 |
|---|---|---|
| ^ | 匹配对象的开始位置 | ^Dear 表示匹配字符串以Dear开头 |
| $ | 匹配对象的结尾位置 | sh$ 表示匹配字符串以sh结尾 |
| \b | 单词边界(需要在前面加\进行转义) | \\bthe\\b 表示匹配字符串为the,前面没有其他字符 |
| \B | 非单词边界 | \\Bthe\\B 表示匹配字符串包含the,前后要有其他字符 |
定义前后字符串的特殊符号:
| 符号 | 解释 | 示例 |
|---|---|---|
| (?=…) | 定义后面紧接的字符串 | abc(?=def) 表示 abc 后面紧接 def |
| (?!..) | 定义后面不能紧接的字符串 | abc(?!def) 表示 abc 后面不能紧接 def |
| (?<=…) | 定义前面紧接的字符串 | (?<=abc)def 表示 def 前面紧接 abc |
| (? | 定义前面不能紧接的字符串 | (? |
正则表达式构建
正则表达式的构建首先需要考虑正则表达式由几部分构成,其次构建每部分对应的正则表达式,然后再把各部分的正则表达式连接在一起。
示例(根据电子邮箱地址规则构建电子邮箱地址的正则表达式):
电子邮箱地址具有以下几条规则:
(1)邮箱地址的第一部分由若干数字、字母或下划线字符组成。
[A-Za-z0-9_]+
(2)邮箱地址第二部分是一个@符号。
@
(3)邮箱地址第三部分由若干数字、字母或点符号组成,但第一个字符不能是点符号。
(?<!\.)[A-Za-z0-9\.]+
(4)邮箱地址最后部分是顶级域名,可以是com、org、edu、net和cn等等(这里构建正则表达式仅认为以这几种常用的为结尾),并且域名前有个点符号。
\.(com|org|edu|net|cn)$
连接后,完整的表达式是:
[A-Za-z0-9_]+@(?<!\.)[A-Za-z0-9\.]+\.(com|org|edu|net|cn)$
正则表达式可以先编译成正则表达式对象(regex 对象),以提高字符串匹配速度。re模块中的compile函数用于把正则表达式编译成正则表达式对象,
如:
expr = re.compile("[A-Za-z0-9_]+@(?)
正则表达式应用
re模块提供了多个基于正则表达式的字符串匹配函数,用于检验、提取、分隔及替代字符串操作。
re模块的字符串匹配函数:
| 函数 | 解释 |
|---|---|
| match(pattern, string [,flags]) | 用正则表达式模式pattern匹配字符串string(从字符串的起始位置开始匹配),如果匹配成功,则返回一个匹配对象,否则,返回None |
| search(pattern, string [,flag]) | 用正则表达式模式pattern匹配字符串string(从任何位置开始匹配),如果匹配成功,则返回一个匹配对象,否则,返回None |
| findall(pattern, string [,flag]) | 用正则表达式模式pattern搜索字符串string中所有匹配,返回匹配字符串列表。如没有匹配则返回空列表 |
| split(pattern, string [,maxsplit=0]) | 用正则表达式模式pattern作为分隔符,对字符串string进行分隔,返回一个字符串列表 |
| sub(pattern, repl, string [,count]) | 用正则表达式模式pattern搜索字符串string中所有匹配,并替换成repl字符串 |
示例:
m1 = re.match("world", "helloworld")
print(m1) # 输出 None
m2 = re.search("world", "helloworld")
print(m2) # 输出
此外,字符串匹配函数中的flags参数是可选标识符,具体见下表。
re模块中定义的标识符:
| 标识符 | 解释 |
|---|---|
| IGNOREACASE | 忽略大小写 |
| LOCALE | 处理字符集本地化 |
| MULTILINE | 支持多行匹配 |
| DOTALL | 点符号匹配所有字符(包括换行符) |
| VERBOSE | 忽略空格或换行等字符 |
| UNICODE | 使用Unicode编码 |
示例:
f = re.findall("b[aiu]t", "BUT,bet,bit,buat,butter,bIT", re.IGNORECASE)
print(f) # 忽略大小写,输出 ['BUT', 'bit', 'but', 'bIT']
由前面可知,match函数和search函数返回的是匹配对象,可利用匹配对象的属性和方法进一步操作。
匹配对象的主要属性和方法:
| 属性和方法 | 解释 |
|---|---|
| group() | 返回匹配字符串 |
| start() | 返回匹配字符串在原字符串中的起始位置 |
| end() | 返回匹配字符串在原字符串中的结束位置 |
| span() | 返回匹配字符串在原字符串中的起始和结束位置 |
示例:
s = re.search("me", "watermelon")
print("匹配字符串:", s.group()) # 输出 匹配字符串: me
print("起始位置:", s.start()) # 输出 起始位置: 5
print("结束位置:", s.end()) # 输出 结束位置: 7
print("起始和结束位置:", s.span()) # 输出 起始和结束位置: (5, 7)
如果要对一个字符串进行分隔,可以采用分组匹配的方法。
分组匹配的正则表达式由圆括号分隔的多个正则表达式组成,字符串按照顺序与每一个正则表达式进行匹配与分隔,已匹配的子串后面不再匹配,如果有一组不能匹配,则返回None值。
分组匹配的匹配对象可以通过 group(i) 返回第i个匹配的字符串或通过 groups() 返回所有匹配字符串的元组。
示例(分组匹配):
w = re.match("(water)(melon)", "watermelon")
print(w.group()) # 输出 watermelon
print(w.group(1)) # 输出 water
print(w.group(2)) # 输出 melon
print(w.groups()) # 输出 ('water', 'melon')
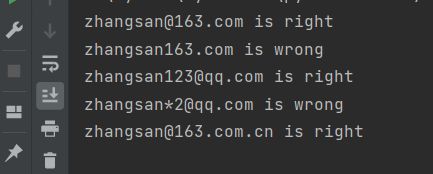
示例(检验电子邮箱地址是否正确):
import re
address = ["[email protected]",
"zhangsan163.com",
"[email protected]",
"zhangsan*[email protected]",
"[email protected]"]
expr = re.compile("[A-Za-z0-9_]+@(?)
for addr in address:
m = re.match(expr, addr)
if m:
print("%s is right" % addr)
else:
print("%s is wrong" % addr)
输出:
以上内容参考整理自《地理数据处理与分析》一书,作学习笔记。
进一步学习→https://docs.python.org/zh-cn/3/library/re.html