机器学习必备之Numpy——数组和矢量计算
首先开始机器学习的入门学习,简单上手以后就可以开始数据分析的板砖工程了。先是要学习些Python的基础工具包,pandas,numpy,matplotlib等,主要在jupyter notebook交互式编译器进行编程训练。
Numpy是Python科学计算的一个基础包,许多内容都基于Numpy以及构建与其上的库。除了为Python提供了快速的数组处理能力,Numpy还在数据分析方面有另外一个作用,就是作为在算法之间传递数据的容器(Numpy使用低级语言C、Forturn等编写的,可以直接操作Numpy数组中的数据),无需进行任何的复制操作。
ndarray——多维数组对象
数组、Numpy数组、ndarray等都指ndarray对象
该对象是一个快速而灵活的数据集容器,运用这个对象可以对整块数据进行些数学运算。
ndarray是一个通用的同构数据多维容器,意思就是说,其中的所有元素都必须是相同类型的。shape(表示各维度大小的元组),dtype(用于说明数组数据类型的对象)。
创建见到的ndarray的办法就是array函数,他接受一切序列型的对象(可以数组中包括数组),然后产生一个新的含有传入数据的Numpy数组,如:
[In] data = [5,6,7.8]
[In] arr = np.array(data)
[In] arr
[Out] array([5.,6.,7.8])
数组嵌套数组的情况和以上的情况相似,只不过是成为多维数组。
如果不是显示说明数据类型,np.array会自动为新建的数组推断出一个合适的数据类型,比如说上面的:
[In] arr.dtype
[Out] dtype('float64')
这就是Python编程高级的一个体现。
还有些函数也可以新建数组,比如zeros和ones分别可以创建指定长度或形状的全为0或全为1的数组;empty可以创建一个没有任何具体值的数组(注意,np.empty不会返回全是0的数组,大多数情况下他返回的都是一些未进行初始化的垃圾值),要使用这些函数,仅仅需要传入一个表示形状和大小的元组即可。
arange是Python中内置随机函数range的数组版本:
[In] np.arange(8)
[Out] array([0, 1, 2, 3, 4, 5, 6, 7])

上面给出了一些常用的创建数组的函数,可以多加以训练。
ndarray的数据类型
dtype是一个特殊的对象,他含有ndarray将数组解释成特定数据类型所需的类型:
[In] arr1 = np.array([1,2,3], dtype = np.float64)
[In] arr1.dype
[Out] dtype('float64')
你也可以选择通过ndarray中的astype方法来显式的转换其dtype:
[In] arr2 = np.array([1, 2, 3, 4, 5])
[In] arr.dtype
[Out] dtype('int64')
[In] arr3 = arr2.astype(np.float64)
[In] arr3.dtype
[Out] dtype('float64')
如果转换过程因为某种原因失败了,就会引发一个TypeError,这时候需要检查数组中的数据类型了。
dtype中还要另外一个用法,就是可以将一个数组的数据类型移植到另外一个数组上面去:
[In] arr4 = np.arange(10)
[In] arr5 = np.array([.22, .45, .567, .56], dtype = np.float64)
[In] arr4.astype(arr5.dtype)
[Out] array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
也可以选择用简单的类型代码来表示dtype:
[In] arr6 = np.empty(8, dtype = 'u4' )
[In] arr6
[Out] array([64589321, 23749587, 80274628, 47382993,
18237463, 12848382, 93841834, 35235688], dtype = uint32)
只要使用astype函数就一定会创建出一个新的数组,即使和老数组相同也会对原始数组进行一份拷贝。
数组和标量之间的运算
Python中的数组很重要,因为不必编写循环语句即可对对数组中的数据进行批量运算,凡是维度大小相同的数组之间的任何算术运算都会直接作用到数组中的每一个元素上,比如相似的数组之间进行加减乘除运算,直接作用到这两个数组中的每一个元素上面,在元素级上进行运算。
[In] arr = ([[1,2,3],[4,5,6]])
[In] arr
[Out] array([1, 2, 3],
[4, 5, 6])
[In] arr * arr
[Out] array([1, 4, 9],
[16, 25, 36])
同样的,数组和标量的算术运算也会直接将那个标量作用到各个元素。
不同数组之间的运算叫做广播,后面会学习到。
基本的索引和切片
说白了就是调用某个数组中的某一个具体的元素,从表面上看,和Python列表的功能差不多,可以选择输出某一个或者某连续的多个。当你讲一个标量值赋给一个切片时,该值就会自动传播(即广播)到整个选区,数组切片和列表有一点不同的,就是切片是原始数据的视图,这意味着数据并不会被复制,在视图上的任何修改都会直接作用到原始数据上。这就是Python处理大数据的好处之一,如果对海量数据进行复制来复制去的操作,想想会占用多少内存呢。
对于多维数组来说,各个索引位置上的元素不再是标量,而是n-1维的数组:
[In] arr = np.array([1,2,3], [4,5,6], [7,8,9] )
[In] arr[2]
[Out] array([7, 8, 9])
所以可以对各个元素进行递归访问,也可以通过逗号隔开的索引列表来选取单个元素,就是说arr[0][2] 和arr[0, 2]这两种方式时等价作用的,下图就说明了二维数组的索引方式:
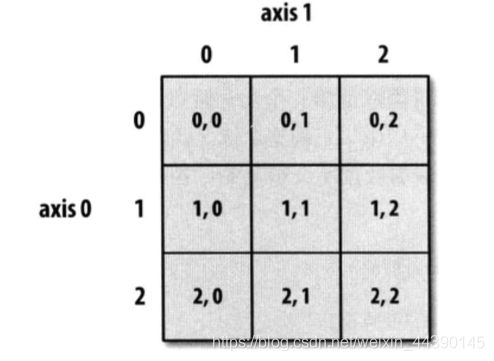
注意,在对多维数组选取索引的时候,返回的数组也全部都是视图。
在对切片进行索引时,“只有冒号”表示选取整个轴:
[In] arr
[Out] array([1,2,3],
[4,5,6],
[7,8,9])
[In] arr[ : , : 1]
[Out] array([[1],
[4],
[7]])
同样,对切片表达式的复制操作也会被扩展到整个切片选取的。
数组转换和轴对换
transpose转置函数是对数组的一种重塑的方法,返回的也是源数据的视图(不会进行任何复制的操作),其中还有一个.T方法能将数组的轴进行转换,这里有点类似矩阵中的转置
[In] arr.T
[Out] array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 4, 9, 14]])
同样的,swapaxes和transpose在对二位数组进行转置处理时,都具有相同的用法和作用,就是swapaxes(1, 0) 或者 transpose(1, 0),都能对数组进行处理,是一种轴变换。
但是在处理多维数组时,若使用函数transpose(1,0,2),即代表将轴0和1对换,轴2不变,亦即将 arr[x][y][z] 中x和y位置互换;
同理,swapaxes(1,0)即表示将轴1和0位置互换,轴2不变;即swapaxes(1,0)和transpose(1,0,2)具有相同的作用。
通用函数
以下就列举了一些常用的通用的函数,其实本质上和数学运算非常相似,就把常用的列举出来了:


上面的是一元的函数级别的运算,下面的是二元函数

利用数组进行数据处理
np.meshgrid函数接受两个一维数组,并产生两个二维矩阵,对应于两个数组中所有的(x, y)对

ply中的colorbar()函数的作用是显示出来右边的颜色条。
还能将条件逻辑转换成数组进行表达
[In] xs = np.array([1,2,3,4,5])
[In] ys = np.array([6,7,8,9,10])
[In] con = np.array([True,False, True,False, True])
[In] result = [(x if c else y)
for x,y,c in zip(xs,ys,con)]
[In] result
[Out] [1, 7, 3, 9, 5]
但是其中还存在几个问题,1.他没有办法对大数据进行处理,因为处理大数据的速度不是很快; 2.无法用于多维数组
如果使用np.where可以起到相同的作用,用法也差不多:
[In] result = np.where(con,xs,ys)
[In] result
[Out] array(1,7,3,4,5)
np.where的后两个参数不必须是数组,也可以是标量值,在实际分析数据的过程中,where的作用通常是根据一个数组产生另一个数组,比如:
result = np.where(arr > 0, 2, -2)
这句话就表示将数组中的正数换为2,将负数换为-2,若为:
result = np.where(arr > 0, 2, arr)
就表示仅仅将正数换成2,对负数不作处理。
数学和统计学方法
sum, mean, 以及标准差std等聚合计算(aggregation,通常叫做简约(reduction)),既可以当作数组的实例方法来使用,也可以当作顶级的Numpy来使用:
[In] arr = np.random.randn(5, 4)
[In] arr.mean()
[In] np.mean(arr)
以上两种方法的效果是相同的,用于接收一个axis参数,用于计算该轴方向上的统计值,最终结果是一个少一维的数组(即计算最低维度上的统计值)


上面就是一些基础的统计学的方法。
针对布尔数组的方法
在上面统计学的方法中,所有的布尔值会被转换成0和1,因此sum也会被用于对布尔值中的True来计数;还有2和方法分别叫any和all,any用于测试数组中是否存在一个或多个True;all用于检查是否所有的值都是True。
同时,这两个方法也可以用于非布尔型数组,只是其中所有的非0数都会被认为是True。
唯一化以及其他的集合逻辑
np.unique用于找出数组中的唯一值并返回的是已排序的结果,具体可以用在剔除一些重复的数据上面,这也是Python处理数据的一个好处,也相当于Python代码中的sort(set(names)).
其他的方法也不再多罗嗦了,这里直接给出相关用法。

以二进制的格式将数据保存到本地磁盘
np.save和np.load是Python读写文件的两个主要的函数,默认情况下,文件是以二进制格式保存在扩展名为.npy的文件中的。


通过np.savez可以将文件保存到一个压缩文件中

在读取文件时,会得到一个类似于字典的对象,该对象对各个数组进行延迟加载

Python常用的线性代数函数
在没有具体使用到时先把他们列举出来,等到使用时再加强对这些函数的使用。
随机数生成函数
np.random函数对Python内置的random函数进行了一些补充,增加了一些用于高效生成样本值的函数

