一文读懂 Jmeter - 你以为Jmeter只能用来做压力测试?
该文档写于 2017年上半年并落地了公司两个接口自动化项目,记得当时使用的好像还是 3.2版本,目前最新版本也已经更新到了 5.4.1 版本(Java8),放出来吧…纯当是纪念了。
该篇笔记篇幅较长,阅读起来及其浪费时间,有兴趣的同学可以参考下方的分篇幅阅读。
全干工程师神器 - Jmeter 01 - Jmeter基础与常见问题
全干工程师神器 - Jmeter 02 - Jmeter关于录制与简单实战
全干工程师神器 - Jmeter 03 - 常见逻辑控制器
全干工程师神器 - Jmeter 04 - 定时器
全干工程师神器 - Jmeter 05 - Jmeter配置元件
全干工程师神器 - Jmeter 06 - Jmeter后置处理器
全干工程师神器 - Jmeter 07 - Jmeter监听器
全干工程师神器 - Jmeter 08 - 如何利用Jmeter进行接口测试
全干工程师神器 - Jmeter 09 - Jmeter持续集成介绍及轻量级接口自动化测试框架
全干工程师神器 - Jmeter 10 - Jmeter持续集成介绍及轻量级接口自动化测试框架(思维导图)
文章目录
- 一、Jmeter基础与常见问题
-
- Jmeter基础知识与安装
-
- Jmeter安装
- Jmeter目录结构
- Jmetre 对比 Loadrunner
- Jmeter常用组件和概念介绍
-
- 基本概念
- Jmeter组件作用域和执行顺序介绍
-
- 组件作用域
-
- 作用域示例1 [参照下图]
- 作用域示例1 [参照下图]
- 执行顺序
- 最新版本Jmeter插件的安装方法
- Jmeter启动问题及使用切入点
-
- JDK版本问题
- JVM问题
- 使用的切入点
- 二、关于Jmeter录制
-
- 录制工具 badboy
-
- 录制-badboy
- 录制-代理
- 三、Jmeter脚本项目小实战
-
- 测试步骤
-
- HTTP请求设置-保持默认即可
- 线程组属性/设置
- 监听器-聚合报告
- Jmeter - 参数化
-
- 用户参数
-
- 察看结果树
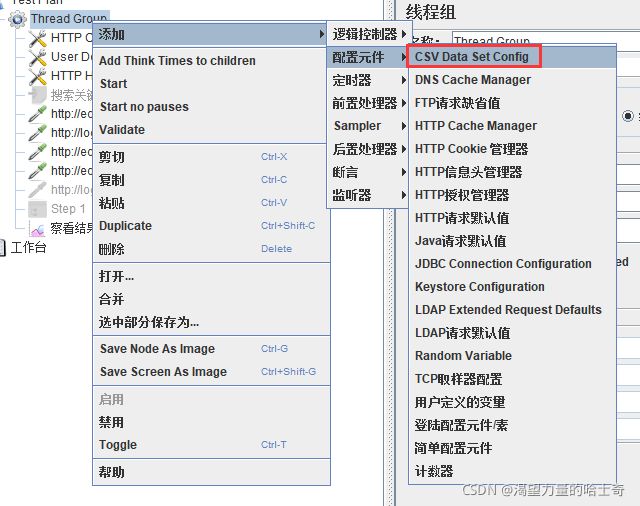
- CSV Data Set Config
-
- 多个变量参数化与单个变量参数化的区别
- 用户参数与CSV Data Set Config
- Jmeter - 集合点
-
- 操作步骤
- 作用域
- 注意点
- Jmeter---断言/检查点
-
- 断言/检查点
- 响应断言
- 响应断言的参数
-
- Apply to:响应作用范围
- 要测试的响应字段
- 模式匹配规则:
- 断言结果
-
- 增加"断言结果"
- 断言结果判定
- Jmeter---关联/动态关联
-
- 步骤
- Jmeter---web程序
-
- 项目背景
- 需求
- 场景
- 监控
- 步骤
- 注意点
- 监控内存及CPU等(jconsole)
- Jmeter--FTP程序
-
- 需求
- 步骤
- Jmeter---jdbc测试mysql数据库
-
- JDBC Connection Configuration
- 关于jdbc中文乱码的说明
- Jmeter---分布式性能测试
-
- 原理
- 步骤
- Jmeter 中的监听器以及测试结果分析
-
- 监听器
- 指标分析
- jtl文件分析 ---> 见test.jtl
- Jmeter 调用第三方jar包
- Jmeter - 测试webservice
- 概念
-
- Jmeter3.x测试webservice接口
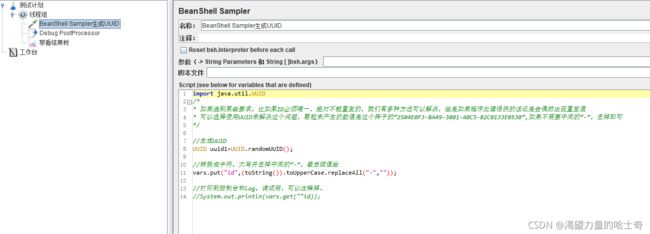
- 生成唯一数UUID
- 四、常见逻辑控制器
-
- 简单控制器
- ForEach控制器
- switch控制器
- 如果if控制器
- 事务控制器
- 循环控制器
- 吞吐量控制器
- 随机 / 随机顺序控制器
-
- 随机控制器
- 随机顺序控制器
- 五、Jmeter定时器
-
- 固定定时器
- 高斯随机定时器
- 同步定时器 Synchronizing Timer
- 均匀随机定时器(Uniform Random Timer)
- 固定吞吐量定时器(Constant Throughput Timer)
- BeanShell定时器(BeanShell Timer)
- 六、Jmeter配置元件
-
- HTTP请求默认值
- 作用域
- HTTP信息头管理器
- HTTP授权管理器
- HTTP Cookie管理器
-
- Cookies是什么
- Cookies的管理
-
- 自动管理Cookies
- 手动管理Cookies
- 用户定义的变量
-
- 实例
- 计数器
- 七、Jmeter后置处理器
-
- Debug Postprocessor
- 举例
- 作用域示例
- Json Extractor
- 八、Jmeter监听器
-
- 常用监听器报告
-
- 查看结果树
- Summary Report
- 聚合报告
-
- 聚合报告中的90%的理解
- 聚合图表(Aggregate Graph)
- Jmeter也有Loadrunner一样的图形监控扩展
-
- Jmeter的痛点
- 扩展插件
- PerfMon Metrics Collector
- Response Times Over Time
- Transactions per Second
- Hits per Second
- 邮件观察仪
-
- 在QQ/163邮箱中开启pop3/smtp服务,并生成授权码,备用
- 在jmeter中添加邮件观察仪,并配置如下
- 点击test mail则会在对应邮箱中收到邮件
- 九、什么是接口?
-
- 接口类型以及特点
-
- HTTP
- WebService
- 报文介绍
- 接口测试文档规范
-
- 文档重要性
- 接口文档规范
- 十、各类接口测试实战
-
- HTTP接口测试
-
- 第一种方法(需LR使用经验)
-
- Get接口
- Post接口
- 第二种方法(需Jmeter使用经验)
-
- Get接口
- Post接口
- 第三种方法(写代码_需要代码编写能力)
-
- 什么是jsoup?
- 环境准备
- WebService接口测试
- 十一、接口测试辅助工具以及thrift接口介绍
-
- thrift介绍
- 十二、Jmeter'持续集成介绍
-
- 定义
- 价值
- 持续集成工具介绍
- 为什么选择Jenkins
- Jenkins环境搭建及配置
-
- 介绍
- 使用Jenkins目的
- 安装
- 全局设置
- 十三、轻量级接口自动化测试(持续集成篇-概念)
-
- 一些思想和普及
- 接口测试的重要性
- 使用Jmeter做轻量级自动化测试
-
- 原因
- 十四、轻量级接口自动化测试(持续集成篇-实战)
-
- 实战
一、Jmeter基础与常见问题
Jmeter基础知识与安装
- Jmeter是开源的性能测试工具
[但我更觉得ta适合做接口的自动化测试] - 纯Java语言编写,可移植性好,解压即用,比Loadrunner轻量
- 支持的协议也越来越多,但报表统计方面确实不如Loadrunner好用
- Jmeter原理就是模拟真实用户的请求,发送给服务器端
- 官网:http://jmeter.apache.org/
- 历史版本库:http://archive.apache.org/dist/jmeter/binaries/
附:需对HTTP请求和响应的常识以及状态码等有一定的了解
Jmeter安装
- 前置条件:安装好JDK并配置好环境变量,可自行百度或google
- 官网下载Jmeter:http://jmeter.apache.org/download_jmeter.cgi
- 启动:解压jmeter,到bin目录下双击jmeter.bat
Jmeter目录结构
bin目录是可执行文件。
jmeter的log在jmeter.log中查看。
jmeter.properties是修改默认属性的文件。比如,属性log_lever.JMeter可以设置改变 日志详细度。默认是info,可改为debug。
dosc下是jmeter的java dosc
printable_docs的usermanual子目录下是jmeter用户手册,其中component_reference.html是最常用的核心元件帮助手册
Jmetre 对比 Loadrunner
| 对比项 | Jmetre | Loadrunner |
|---|---|---|
| 安装 | 简单,下载解压即用 | 复杂,安装包很大对硬件有一定要求,安装时长大于1小时 |
| 录制/回放模式 | 支持 | 支持 |
| 支持的测试协议 | 较少,但支持用户自行扩展 | 较多,不支持用户自行扩展 |
| 分布式大规模压力测试 | 支持 | 支持 |
| IP欺骗 | 不支持 | 支持 |
| 图形报表 | 支持(较弱,但可扩展) | 支持(很强,图形报表一直是商业工具的强项) |
| 测试的逻辑控制 | 支持 | 支持 |
| 服务器硬件资源监控 | 支持 | 支持 |
| 功能测试 | 支持 | 不支持 |
Jmeter常用组件和概念介绍
- 测试计划:是根、是老大。所有的内容都是基于这个计划,都需要在这个测试计划 下进行。
- 线程组:设置jmeter按照什么样的场景运行的地方,其中的线程,大家可以理解为Loadrunner中的虚 拟用户数 setup
- thread group:可用于执行预测试操作。类似Loadrunner中的init,可理解为 初始化。 teardown
- thread group:可用于测试后动作。类似Loadrunner的end,其实就是测试
- 结束完成之后的清理性动作。(该动作不是必须性的,场景中能用的可以使用;用 不到,不使用也没关系)
- sample:这里是创建各种请求类型的,用来模拟用户的请求。ta是在线程组下面创建 的,如果没有创建线程组,是看不到的。
- 逻辑控制器:类似编程语言里的if、for这些东东,后面会专门讲到。
- 定时器:用于设置操作之间的等待时间,类似Loadrunner中的思考时间。但不同的 是,Jmeter里的定时器,一旦设置,是对所有请求都生效的。
- 前置处理器:用于在实际的请求发出之前对即将发出的请求进行特殊处理,比如参 数化之类的。
- 后置处理器:对发出请求后得到的服务器响应进行处理,比如关联。
- 断言:就是Loadrunner中的检查点,用于检查测试中得到的相应数据等是否符合 预期。
- 监听器:对测试结果数据进行处理和可视化展示。如查看结果树、聚合报告。
基本概念
1、参数化
2、集合点
3、断言/检查点
4、关联
Jmeter组件作用域和执行顺序介绍
组件作用域
Jmeter并不像Loadrunner那样容易上手,ta里面杂乱的元件和不知道怎么弄的树形结构足以让很多初学者放弃学习热情了。
同时我们也发现里面有很多的元件,其实我们没必要把每个都弄的那么清楚,先把最重要的常用的吃透、搞清楚即可。后续碰到了再学习,这样学习成本会下降很多,同时也 不至于太受打击。
接下来,我们就看看元件及他们的执行顺序如何。
- 配置元件(config elements)会影响其作用范围内的所有元件。
- 前置处理程序(Per-processors)在其作用范围内的每一个sampler元件之前执行
- 定时器(timers)对其作用范围内的没一个sampler有效
- 后置处理程序(Post-processors)在其作用范围内的每一个sampler元件之后执行。
- 断言(Assertions)对其作用范围内的每一个sampler元件执行后的结果执行校验。
- 监听器(Listeners)收集其作用范围的每一个sampler元件的信息并呈现
- sampler元件不和其他元件相互作用,因此不存在作用域的问题。

作用域示例1 [参照下图]
- http1、2、3无作用域的概念
- 循环控制器:http2、3、图形结果
- 图形结果:http2、3
- 聚合报告:http1、2、3

作用域示例1 [参照下图]
- 固定定时器:http1
- 循环控制器:http2、3、图形结果、随机控制器
- 图形结果:http2、e
- 响应断言:jdbc
- 聚合报告:所有
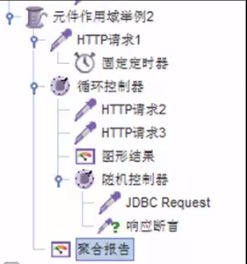
总结:记住一句话,从各个元件的层次结构判断判断每个元件的作用域。
执行顺序
- 配置元件
- 前置
- 定时器
- sampler
- 后置
- 断言
- 监听器
如果在同一个作用域范围内有多个同一类型的元件,则这些元件按照他们在测试计 划中的上下顺序一次执行。
最新版本Jmeter插件的安装方法
不知道现在的插件安装方式是不是还是这样,哪位同学如果知道的话,还请不吝赐教。
在jmeter3.0之前的版本中,插件的安装方法需要自行去找相应的jar包然后放到对应的目录中。
但是在jmeter3.0版本之后的,插件的安装方法变了,大致步骤为:
1、https://jmeter-plugins.org/downloads/all/ 下载plugins manager ,放到jmeter的lib下的ext目录中
2、重启jmeter才可以生效。
3、重启jmeter后,选择菜单“选项”>“plugins manager”>之后在此对话框中进行 选择安装,要比之前的操作简单很多,所有可用插件均可在这里找到。
PS:有童鞋说看不懂英文......这世界上有个软件叫有道词典......
Jmeter启动问题及使用切入点
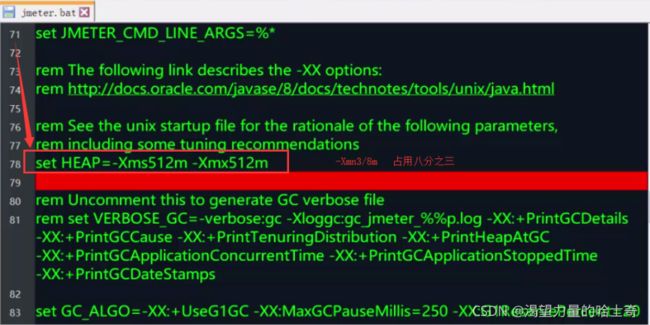
JDK版本问题
Jmetre 2.X版本 对应 JDK 1.6.XXXX 与 JDK 1.7.XXXX
Jmetre 3.X版本 对应 JDK 1.8.XXXX
JVM问题
参考下图
使用的切入点
问:Jmeter在什么情况下使用?
答:企业中真正应用场景比较多的是接口测试,既可以做接口的功能测试,也可以做接口的性能测试。
二、关于Jmeter录制
说实话,Jmeter对录制的支持不好,所以不建议过分依赖录制,建议大家慢慢的学会手写请求, 基本都是界面操作,程度不难。相反,录制看似简单,其实会给后期调试脚本增加很多麻烦。【关于录制、了解即可】
录制工具 badboy
- badboy上的操作,只限于badboy只限于badboy本身的操作软件
- 关于badboy录制时候脚本弹出的 alert ,一直点“确定”即可
- Jmeter的认知:一般情况下大家都会觉得jmeter是一款性能测试工具,其实在实际应用上,更偏向于功能上、接口上的自动化。对于没有脚本编程能力的测试人员来说,Jmeter是一款很好的选择。
- 自动重定向和跟随重定向 [这里不明白的话,可以参考 http://blog.51cto.com/xqtesting/1766130]
录制-badboy
简介:
BadBoy是一款免费WEB自动化测试工具,其实就是一个浏览器模拟工具,具有录制和回放功能,支持对录制出来的脚本进行调试。同时支持捕获表单数据的功能,所以能够进行自动化测试。但目前用的多的是用来进行脚本录制,BadBoy支持将脚本导出为JMeter脚本。
JMeter录制脚本有多种方法,其中最常见的方法是用第三方工具badboy录制,另外还有JMeter自身设置(Http代理服务器+IE浏览器设置)来录制脚本,但用的多就是通过Badboy进行录制。
1、下载地址:http://www.badboy.com.au/
2、默认安装即可,弹出选择“alert”选择“是”
3、打开badboy工具,点击工具栏上的红色圆形按钮,在地址栏目中输入被试项目地址
4、录制完成后,点击工具旁边的黑色按钮,结束录制。选择“文件”--Export to Jmeter
5、打开Jmeter工具,选择“文件”-->“打开”选择刚才保存的(.jmx类型)文件,将文件导入进来。
6、演示录制
录制-代理
不推荐使用带理:
1、配置比较复杂
2、因代理的问题造成无法正常上网,甚至会重装系统。
3、仅做了解即刻。
设置代理:
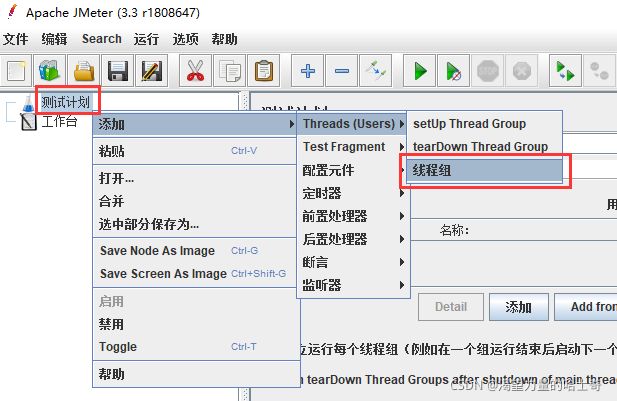
1、创建一个线程组(右键点击“测试计划”--->“添加”--->“线程组”)
2、在“工作台”-非测试原件-添加“HTTP带理服务器”
3、代理服务器的端口,默认8080,可自行修改,但不要与其他应用端口冲突。
4、目标控制器:录制的脚本存放的位置,可选择项为测试计划中的线程组(根据实际情况来选择即可)。
5、分组:对请求进行分组。“分组”的概念是将一批请求汇总分组,可以把URL请求理解为组。
· “不对样本分组”:所有请求全部罗列
· “在组间添加分隔”:加入一个虚拟的以分割线命名的动作,运行通“不对样本分组”,无实际意义。
· “每个组放入一个新的控制器”:执行时按控制器给输出结果
6、“只存储每个组的第一个样本”:对于一次URL请求,实际很多次http请求的情况
7、点击“启动”
三、Jmeter脚本项目小实战
1、被测试网站: xqtesting.blog.51cto.com
2、指标:响应时间及错误率
3、场景
测试步骤
1、测试计划
2、线程组
3、HTTP请求
4、监听器
5、运行脚本
6、查看报告
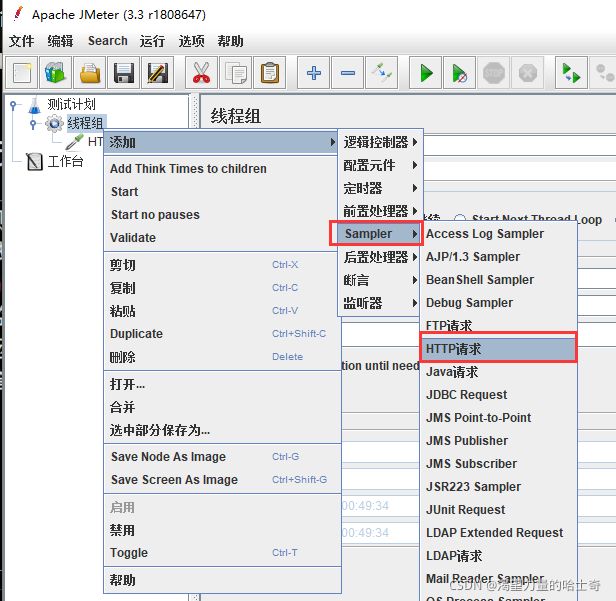
HTTP请求设置-保持默认即可
-
名称:本属性用于标识一个取样器,建议使用一个有意义的名称。
-
注释:对于测试没有任何作用,仅用户记录用户可读的注释信息
-
服务器名称或IP:HTTP请求发送的目标服务器名称或IP地址
-
端口号:目标服务器的端口号,默认值为“80”,后面的超时定义可以不用填写
-
协议:向目标服务器发送HTTP请求时的协议,可以是http亦或https,默认值是http
-
方法:发送HTTP请求的方法,可用方法包括GET、POST、HEAD、PUT、OPTIONS、TRACE、DELETE等。
-
Content encoding:内容的编码方式。
-
路径:目标URL路径(不包括服务器和端口)
-
自动重定向:如果选中该选项,当发送HTTP请求后得到的响应是302/301时,Jmeter 自动重定向到新的页面。
-
Use keep Alive:当该选项被选中时,jmeter和目标服务器之间使用 Keep-Alive方式
进行HTTP通信,默认选中。Keep-Alive:持久长连接
-
Use multipart/form-data for HTTP POST:当发送HTTP POST请求时,使用Use multipart/form-data方法发送,默认不选中。
-
同请求一起发送参数:在请求中发送URL参数,对于带参数的URL,jmeter提供了 一个简单的对参数化的方法。用户可以将URL中所有参数设置在本表中,表中的 每一行是一个参数值对(对应RUL中的名称1=值1)
-
同请求一起发送文件:在请求中发送文件,通常,HTTP文件上传行为可以通过这 种方式模拟。
-
从HTML文件获取所有有内含的资源:当该选项被选中时,jmeter在发出HTTP请 求并获得响应的HTML文件内容后,还对该HTML进行Parse并获取HTML中包含
的所有资源(图片、flash等),默认不选中,如果用户只希望获取页面中的特定资源,可以在下方的Embedded URLs must match 文本框中填入需要下载的特定资源表达式,这样,只有能匹配制定正则表达式的URL指向资源才会被下载。 -
用作监视器:此取样器被当成监视器,在Monitor Results Listener中可以直接看到 基于该取样器的图形化统计信息。默认为不选中。
-
Save response as MD5 hash : 选中该项,在执行时仅记录服务端响应数据的MD5值,
而不记录完整的响应数据。在需要进行数据量非常大的测试时,建议选中该项以减 少取样器记录相应数据的开销。
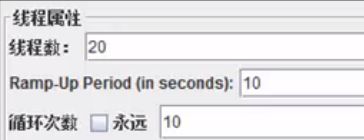
线程组属性/设置
- 线程数:虚拟用户数
- ramp up period:设置的虚拟用户数需要多长时间全部启动。如果线程数为20,时 间为10,也就是每秒钟启动2个线程。
参考:https://blog.csdn.net/sunwangdian/article/details/50738870 - 循环次数:每个线程发送请求的次数。如果线程数为20,循环次数为100,那么每 个线程发送100次请求。总请求数为20*100=2000.如果勾选了“永远”,那么所有 线程会一致发送请求,一到选择停止运行脚本。
- 调度器:可以更灵活的设置运行时间等。
监听器-聚合报告
附:保存文件的后缀 jtl 单位:毫秒
- Lable:定义HTTP请求名称
- Samples:表示这次测试中一共发出了多少个请求
- Average:平均响应时长—默认情况下是单个Request的平均响应时长,当使用了Transaction Controller时,也可以以Transaction为单位显示平均响应时长。
- Median:中位数,也就是50%用户的响应时长。
- 90%Line:90%用户的响应时长。
- Min:访问页面的最小响应时长。
- Max:访问页面的最大响应时长。
- Error%:错误请求的数量/请求的总数
- Throughput:默认情况下表示每秒完成的请求数(Request per Second),当使用了
Transaction Controller 时,也可以表示类似 LoadRunner 的Tranaction per Second数。 - KB/Sec:每秒从服务器端接收到的数据量。
Jmeter - 参数化
参数化的两种实现方式 用户参数 与 CSV Data Set Config
用户参数
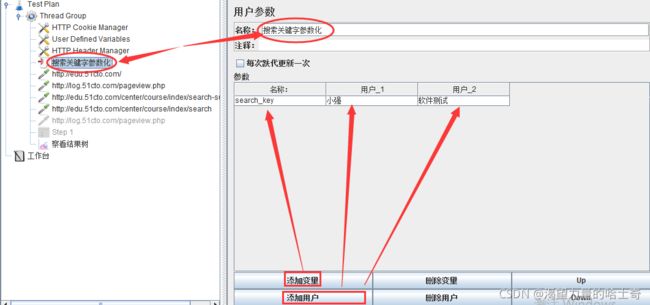

察看结果树
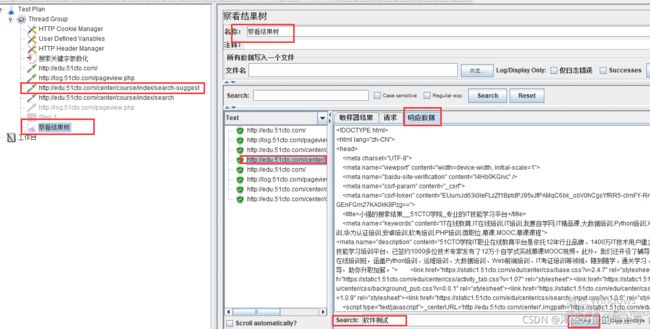
CSV Data Set Config
多个变量参数化与单个变量参数化的区别
单个变量

多个变量
- 多个变量的情况下,使用“,”【英文格式】逗号作为分隔符,将关键字进行分隔.

用户参数与CSV Data Set Config
关于"用户参数"与"CSV Data Set Config"哪个元件用来做参数化更有优势,没有标 准答案,"两者都可以用",主要看使用者更倾向于哪一个。
一般情况下,参数化数据量不是很大的情况下,使用用户参数更为简便些。
如果参数化数据量比较大的情况下,比如开发导出来的CSV文件,CSV Data Set Config
要比用户参数来说更有优势些。
Jmeter - 集合点
可以理解为“增加并发、模拟并发”
定义:
简单的说,虽然我们的“性能测试”理解为“多用户并发测试”,但真正的并发是不存在的, 为了更真实的实现并发这概念,我们可以在需要压力的地方设置集合点,每到输入用户 名和密码登录时,所有的虚拟用户都相互之间等一等,然后,一起访问。
如淘宝的秒杀,多个用户同时进行一个操作。
注意:
1、jmeter集合点通过添加定时器来完成。
2、JMeter里面的集合点通过添加定时器来完成。
3、Synchronizing timer仅作用于同一个JVM中的线程。
查看下文“注意点”处的补充。
操作步骤
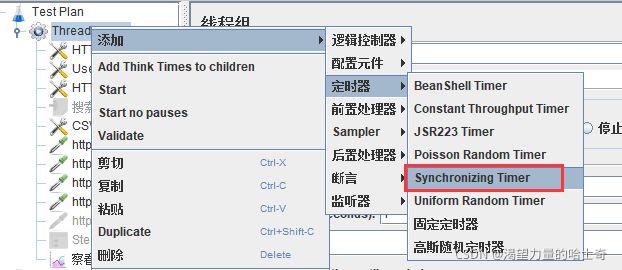
注意:
-
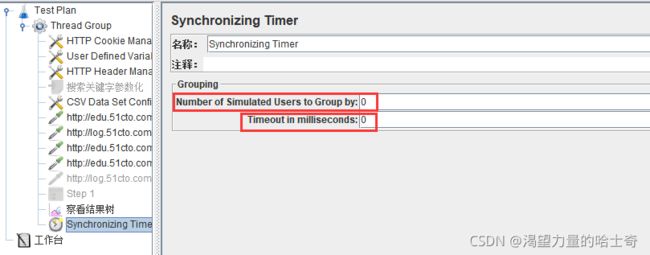
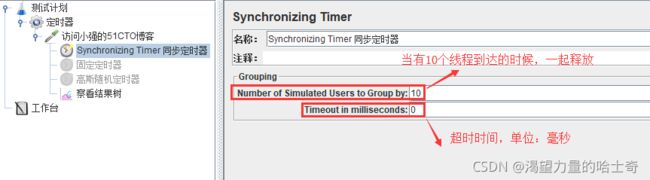
Number of Simulated Users to Group by:
每次释放的线程数量。如果设置为0,等同于设置为线程租中的线程数量。
可理解为集合多少人后再执行请求 -
Timeout in milliseconds:
如果设置为0,Timer将会等待线程数达到了"Number of Simultaneous Users to Group"中设置的值才释放。如果大于0,那么如果超过Timeout in milliseconds中设置的最大等待时间(毫秒为单位)后还没达到"Number of Simultaneous Users to Group"中设置的值,Timer将不再等待,释放已到达的线程。默认为0。 -
如果设置Timeout in milliseconds为0,且线程数量无法达到"Number of Simultaneous
Users to Group by” 中设置的值,那么Test将无限等待,除非手动终止。
作用域
如果希望定时器仅应用于其中一个sampler,则把该定时器作为子节点加入,如下图
定时器仅仅对HTTP请求1起作用,即仅在HTTP请求1执行前执行定时器,和HTTP请 求2无关。
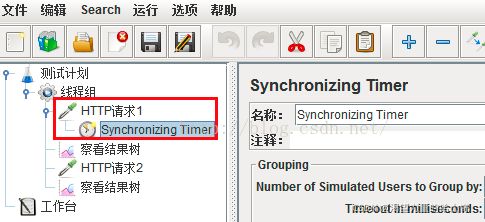
如果希望synchronizing timer应用于多个sampler.
如下,执行HTTP请求1和HTTP请求2前都会执行同步定时器1、2。当执行一个sampler 之前时,和sampler处于相同作用域的定时器都会被执行;

注意点
问:集合点的位置一定要在Sample(采样器)之前才能生效吗?
答:在Jmeter中,timer是在sampler之前执行的。不管这个定时器的位置放在sampler之 后,还是之前。当然,如果有多个timer的时候,在相同作用域下,会按上下顺序执行 timer,这个就需要慎重放置timer的顺序;不过,为了更好的可读性,还是建议将timer放在对应的sampler前面 或 子节点中;
关于Synchronizing timer补充: Synchronizing timer 仅作用于同一个JVM中的线程。
-
a.如果分布式测试时
synchronizing timer作用于所有jvm,那么jvm之间或者说监控jvm 工作的部件就需要频繁通讯,确定线程的数量及状态等,然后集结了足够的线程后,又要发送信号让Jmeter来发送测试请求,中间存在延时,这样就无法模拟更真实的高并发了,而且这个东西还会消耗测试机器的一部分性能,会给测试结果带来负面影响;所以暂时是只支持控制单个jvm,如果后面有办法解决上面那些问题后,就可以实现控制多个jvm,控制总并发量; -
b.如果分布式测试
并使用了Synchronizing timer,且设置的值是小于单个jvm的线程数量;但是,较难确保所有jvm都在同一时间点集结了同样数量的线程数,这样就很难下测试结论了,因为都不知道是多少并发下的性能表现;当然了,可以将线程的启用时间拉长,并将超时时间延长,这样就很可能会与同一时刻集结到足够的线程,达到超高并发的测试;所以,分布式测试与Synchronizing timer一般不是同时使用的;如果非要用,则需要慎重设置相关参数
关于集合点,在实际应用中基本上是不用的,或者说非常少非常少用。
其实,仅仅就集合点来说,影响性能么?答案:影响。那么影响大么?答案:其实也不是太大。
因为一个系统能够承受的并发数和压力取决于两点。
-
取决于业务脚本里的思考时间
同样的并发、同样压力情况下,若思考时间不同,能够承受的压力也是不同的。 -
取决于系统真正的处理能力,或者说 TPS【系统吞吐量,亦说QPS】,TPS每秒处理的能力越高,那么处理压力的能力相对来说就会多一些。
Jmeter—断言/检查点
按照Jmeter官方的翻译过来叫“断言”,其实功能与LoadRunner的“检查点”是一样 的,叫法不一样罢了(文字游戏)
断言/检查点
对响应的结果做一个判断。
响应断言
注意点
1、模式匹配规则
2、要测试的模式

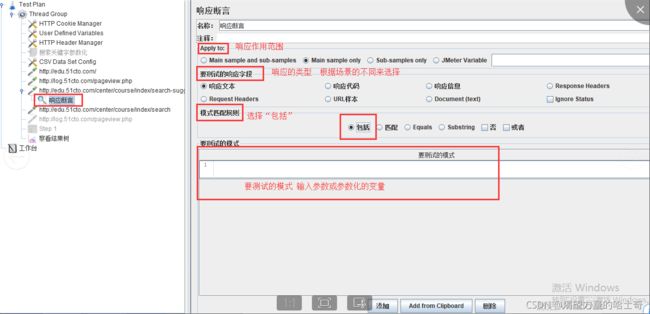
响应断言的参数
Apply to:响应作用范围
1、Main sample and sub-samples:断言应用于主采样器和子采样器。
2、Main sample only:断言仅应用于主采样器。
3、Sub-samples only:断言仅应用于子采样器。
4、Jmeter Variable:断言将被施加到命名变量的内容,变量值进行匹配
要测试的响应字段
1、响应文本:指页面返回的http文本内容 。
2、响应代码:指请求返回的状态,如200 。
3、响应信息:指请求返回的响应信息,如OK、not found 。
4、Response Headers : 响应头信息 。
5、Request Headers :请求头信息。
6、剩余几个还不了解~~
模式匹配规则:
1、包括=返回结果包括你指定的内容,支持正则匹配
2、匹配:
(1)相当于 equals 。当返回值固定时,可以返回值做断言,效果和equals相同
(2)正则匹配 。 用正则表达式匹配返回结果,但必须全部匹配。 即正则表达式 必须能匹配整个返回值,而不是返回值的一部分。
3、Equals ::返回结果与指定断言完全一致
4、SubString:与 “包括”差不多,都是指返回结果包括你指定的内容,但是SubString不支持正则字符串。
断言结果
对“响应断言”的“断言结果”进行再次的判断
增加"断言结果"

断言结果判定
- 成功
如果成功,“断言”一栏显示请求地址
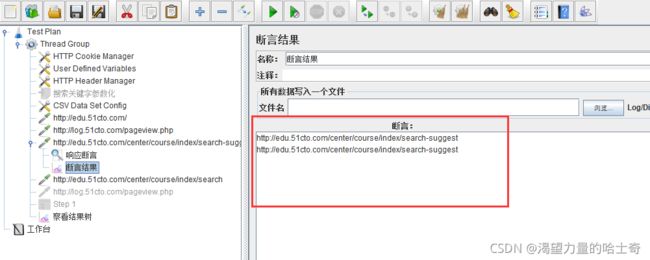
- 失败
如果失败,“断言”一栏请求地址下方显示报错原因。

Jmeter—关联/动态关联
1、和LoadRunner中的关联差不多
2、Jmeter中关联的两种方式:正则、xpath(一般xml的时候用的多)
正则:一般用的比较多的是正则
XML:返回的数据是XML格式的情况,用XML居多
3、以webtours登录威力进行演示 webtours.jmx
webtours:LoadRunner自带的
步骤
1、webtours开启关联
2、badboy录制
3、导入Jmeter
4、找出需要关联的请求(nav.pl)
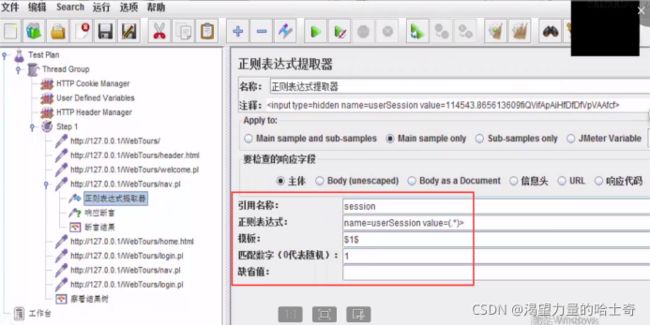
5、该请求 --> 后置处理器 --> 正则 --> 填入内容
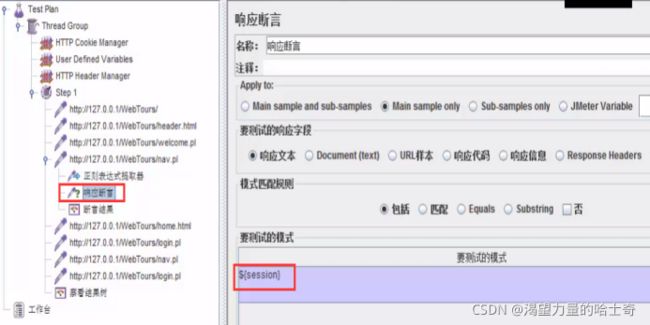
6、增加断言
7、增加断言结果
8、运行查看

-
模板:如果前面的正则表达式取了不止一个参数,那么这里需要制定参数的组别,如果该参数为$1$,则表示取得第一个值,$2$表示取得第二个值
-
匹配数字:0随机; -1取所有值,以数组形式存储; 1; 2…
-
缺省值:一般默认即可(为空)
Jmeter—web程序
项目背景
- XX网站
- 环境:Windows
需求
- 并发登录的性能
场景
- 1s增加2个线程;运行2000次。
- 分别查看20、40、60并发下的表现
监控
- 成功率、响应时间、标准差、CPU、MEM、IO等
- 资源监控需要在Windows / Linux下部署监控agent (server agent)
步骤
- badboy录制
- 导入jmeter
- 参数化、检查点、集合点
- 指标监控,资源监控
- 报告(可导出到xls,然后自行生成报表)
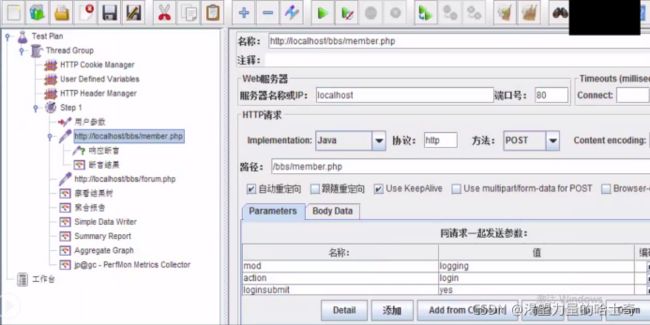
- 演示login.jmx
注意点
关于 “聚合报告 --> 响应数据” 中文乱码解决方法
监控内存及CPU等(jconsole)
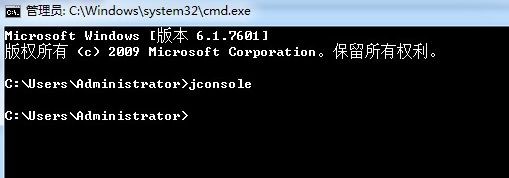
最近逛论坛的时候,发现了一个比较好的监控内存CPU等的小工具,本着开源小工具多 多益善的原则,记录一下。
打开这个小工具的步骤很简单,如果你已经配置好了Jmeter运行的环境,那么你也就 不用去做其他的配置,直接 点击:开始——》运行——》输入cmd——》然后在出现的 命令行界面输入“jconsole”即可弹出一个【java监视和管理控制台】

Jmeter–FTP程序
需求
- 上传一个文件到服务器(put)
- 下载一个文件到本地(get)
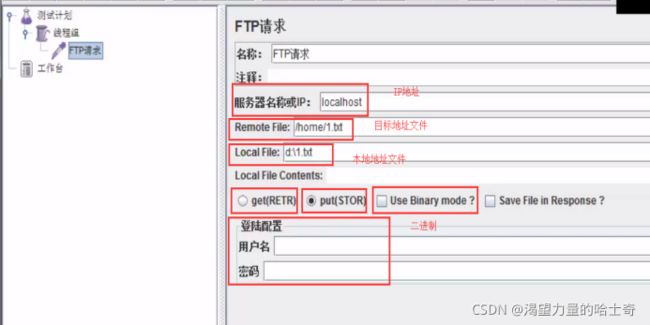
步骤
- 打开Jmeter
- 线程组
- ftp请求缺省值(可有可无)
- ftp请求(get和put两种)
- 如果有用户名和密码填上即可
Jmeter—jdbc测试mysql数据库
JDBC Connection Configuration
测试计划需加载Jar包

参考链接:https://blog.csdn.net/u012167045/article/details/72638507
参考链接:https://jingyan.baidu.com/article/f96699bbf5d092894e3c1b87.html
这张图好像有点失帧了,凑合吧…
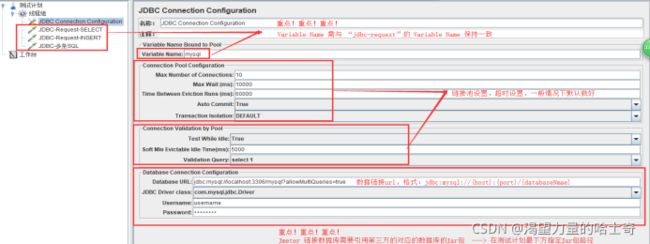

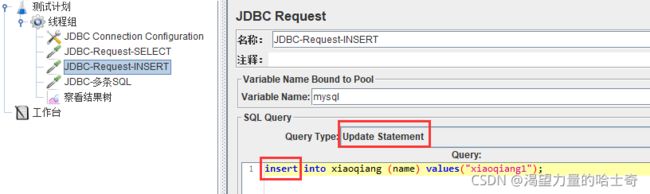
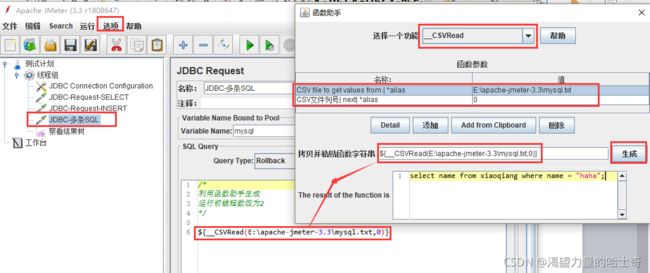
关于jdbc中文乱码的说明
第一步:请确认你在数据库中写sql出来的中文是正常显示的,并没有出现问号或乱码, 如果出现那是数据库编码的问题,和jmeter无关;
第二步:在第一步确认的前提下,修改jmeter jdbc databaseurl为
jdbc:mysql://localhost:3306/mysql?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true,前面的链接地址和端口以及数据库名根据实际情况修改,后面的参数固定,这样就可以解决问号乱码的问题了。
Jmeter—分布式性能测试
Jmeter由java开发,耗内存、cpu,所以大并发下还是需要分布式的。
原理
其实和LoadRunner的agent差不多,如下图所示。

- 调度机(Controller):主要负责性能测试脚本的分发,及各个执行机(Slave)的测试 结果收集汇总,报告产出。
- 执行机(Slave):主要负责执行性能测试脚本及断言等(命令行模式执行,无界面), 并将执行结果反馈给调度机(Controller),若断言执行成功则不返回请求响应数据及 详细断言信息。
步骤
-
关闭防火墙
-
在所要运行Jmeter并作为负载生成器的机器上安装Jmeter,并确定其中一台机器作
为主的controller,其他的机器作为agent。然后运行所有的agent机器上的
jmeter-server文件.【Win系统运行“jmeter-server.bat”、Linux运行“jmeter-server”】 -
在controller机器的jmeter的bin目录下,找到jmeter.properties文件
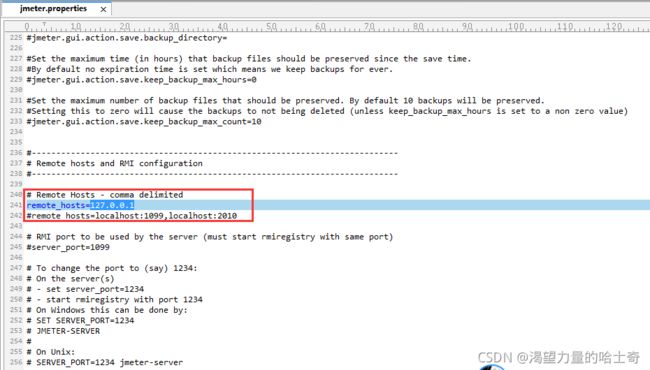
- 启动controller机器上的Jmeter应用,选择菜单“运行” —> “远程启动”,来
分别启动agent,也可以直接选择“远程全部启动”来将所有的agent启动。
Jmeter 中的监听器以及测试结果分析
监听器
-
种类繁多…看界面
-
常用的几个
- 断言结果
- 查看结果树
- 聚合报告
- 用表格查看结果
- 图形结果
- aggregate graph
- 等等…
指标分析
- Samples:表示本次场景中一共发出了多少个请求。
- Average:平均响应时间—默认情况下是单个Request的平均响应时长,当使用了
Transaction Controller时,也可以以Transaction为单位显示平均响应时长。 - Median:中位数,响应时间中值,也就是50%用户的响应时长。
- 90%Line:90%用户的响应时间。
- Min:访问页面的最小响应时间。
- Max:访问页面的最大响应时间。
- 以上时间单位为毫秒…不要弄错了
- Error%:出错率;错误请求的数量/请求的总数
- Throughput:吞吐量。默认情况下表示每秒完成的请求数(Request per Second),当使用了
Transaction Controller时,也可以表示类似 LoadRunner 的Tranaction per Second数。 - KB/Sec:流量。每秒从服务器端接收到的数据量。
jtl文件分析 —> 见test.jtl
- 在性能测试过程中,我们往往需要将测试结果保存在一个文件当中,这样既可以保
存测试结果,也可以为日后的性能测试报告提供更多的素材。 - Jmeter中,结果都存放在“.jtl”文件。这个“.jtl”文件可以提供多种格式的编写,
而一般我们都是将其以CSV文件格式记录。 - 只需要选择某个监听器,点击页面中的configure按钮。此时,一个设置页面就会弹
出来,建议都勾选如下项:Save Field Name , Save Assertion Failure Message - 经过了以上设置,此时保存下来的“.jtl”文件会有如下项:
- timeStamp,elapsed,lable,responseCode,responseMessage,threadName,
dataType,success,failureMessage,bytes,Latency - 请求发出的绝对时间,响应时间,请求的标签,返回码,返回消息,请求所属 的线程,数据类型,是否成功,失败信息,字节,延迟。
Jmeter 调用第三方jar包
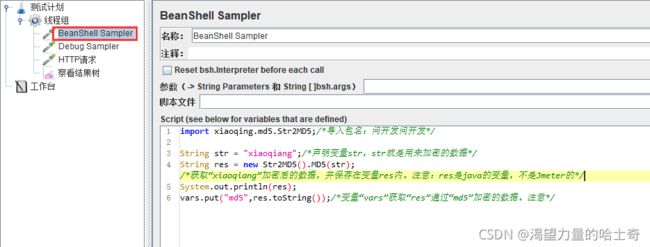
- 有时候我们在测试接口的时候需要调用第三方Jar包来完成。比如,某些数据的加密需要调用加密的Jar包,在Jmeter里可以很方便的完成。
- Jar包 找开发要!找开发要!找开发要!
- “测试计划”一栏下方调用Jar包
- 大致步骤如下:
- 获取需要调用的Jar包
- Jmeter的测试计划中天加Jar包
- 通过beanshell sample 进行调用并保存结果
- 在Jmeter中需要用到该值的地方直接使用即可
参考链接:jmeter完成md5加密的接口请求参数

Jmeter - 测试webservice
附:jmeter3.2版本之后就没有SOAP/XML-RPC Request插件了,所以没办法直接进行 webservice接口的测试。(了解即可)
概念
-
官方解释:Web Service是一种可以接收从Internet上的其他系统传递过来的请求,轻量级的独立的通讯技术。通过SOAP协议完成,使用WSDL文件进行描述内容。
-
粗暴解释:当作一个接口,和HTTP没区别。完成请求,请求的时候完成入参,响应的时候完成出参,响应的时候有返回及返回的参数。
- 接口请求中的一种。
- 接口的本质其实就是发送请求和响应的一个过程。
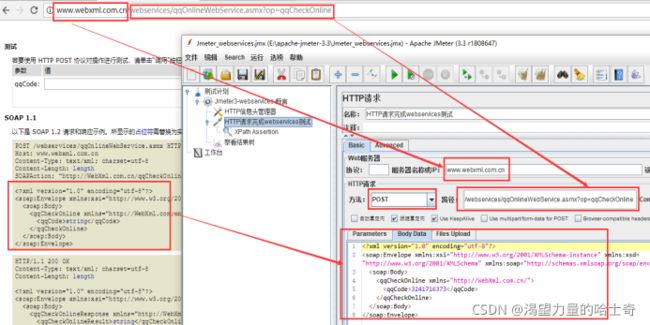
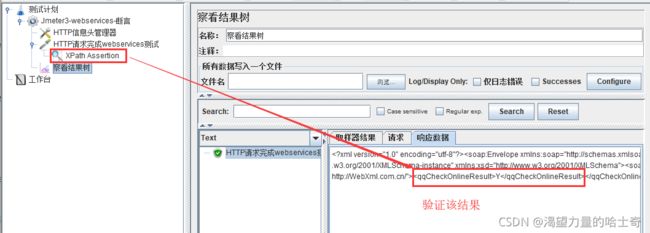
Jmeter3.x测试webservice接口
附:jmeter3.2版本之后就没有SOAP/XML-RPC Request插件了,所以没办法直接进行webservice接口的测试。


生成唯一数UUID
四、常见逻辑控制器
简单控制器
无任何实际作用,也不参与脚本运行,可以理解为就是一个分组或者打标签用的。
ForEach控制器
ForEach控制器在用户自定义变量中读取一系列相关的变量。该控制器下的采样器或控 制器都会被执行一次或多次,每次读取不同的变量值。
所以ForEach总是和(用户定义的变量)一起使用的。
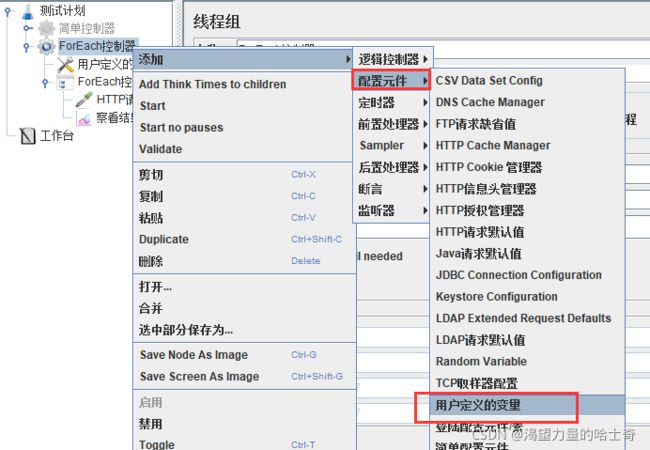
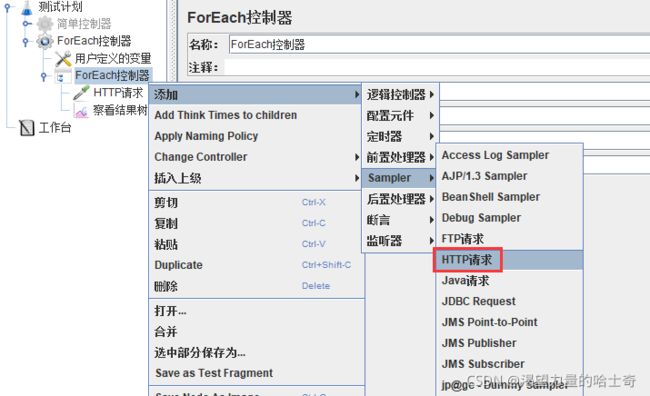
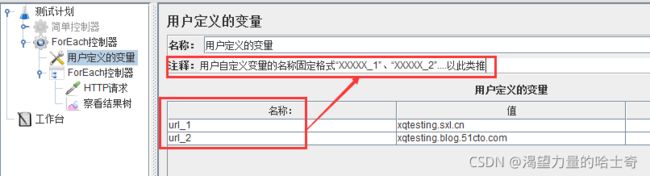
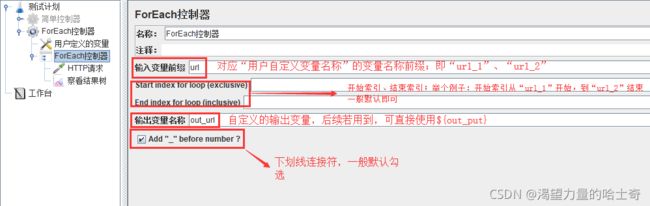
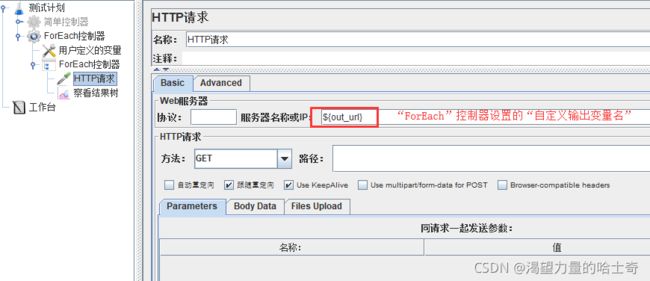
switch控制器


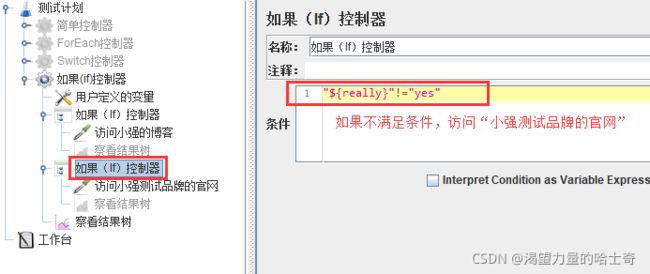
如果if控制器
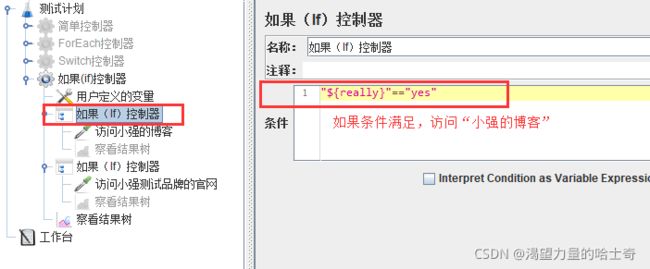
根据给定表达式的值决定是否执行该节点下的子节点,默认使用javascript的语法进行 判断。当满足一定的条件,运行指定的请求。
- 名称:IF逻辑控制器的简述。
- 注释:对逻辑控制器的详细描述。
- 条件:判断条件,可以引用变量。当为 true 时,执行响应的操作。

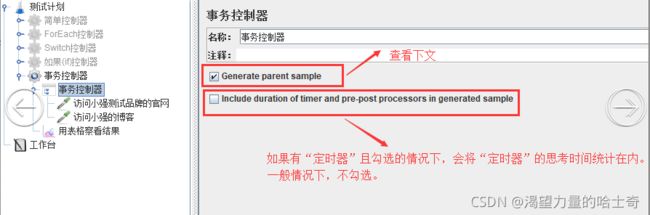
事务控制器
1、事务控制器会生产一个额外的采样器,用来统计该控制器子结点的所有时间。
2、会生成一个额外的采样器来测量其下测试元素的总体时间。值得注意的是,这个时间包含该控制
器范围内的所有处理时间,而不仅仅是采样器的。
3、统计事务控制器底下的子节点运行的时间
Generate Parent Sample不选中情况下,用表格察看结果显示为[下图]

其中事务采样器采集的数据排在子采样器数据之后,同时各列数据略大于子采样器数据之和。
Generate Parent Sample选中情况下,用表格察看结果显示为[下图]

其中仅显示事务采样器采集的数据,而不会显示子采样器采集的数据。
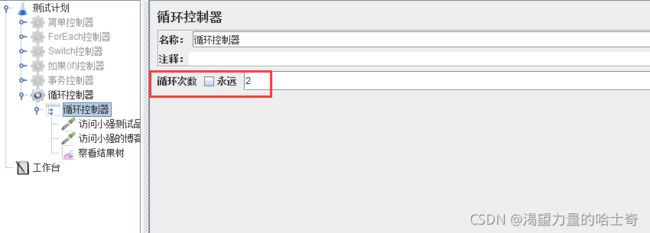
循环控制器
循环控制器下子节点的次数

“循环控制器"的“循环次数”等于子节点的请求次数。
当"线程组"也存在循环次数时,
请求的次数为"线程组-循环次数” *“循环控制器-循环次数”的"积”。
吞吐量控制器
控制子节点运行的次数


Per User选项的用处:
勾选:会按照每个线程单独计算吞吐量,如线程组设置了5个线程,循环次数为2的情 况,吞吐量为1时,吞吐量的子节点每个线程执行一次,总共会执行5次。
不勾选:按照全局的执行数次进行计数,如线程组设置了5个线程,循环次数为2的情 况,吞吐量为1时,吞吐量的子节点仅会执行一次。
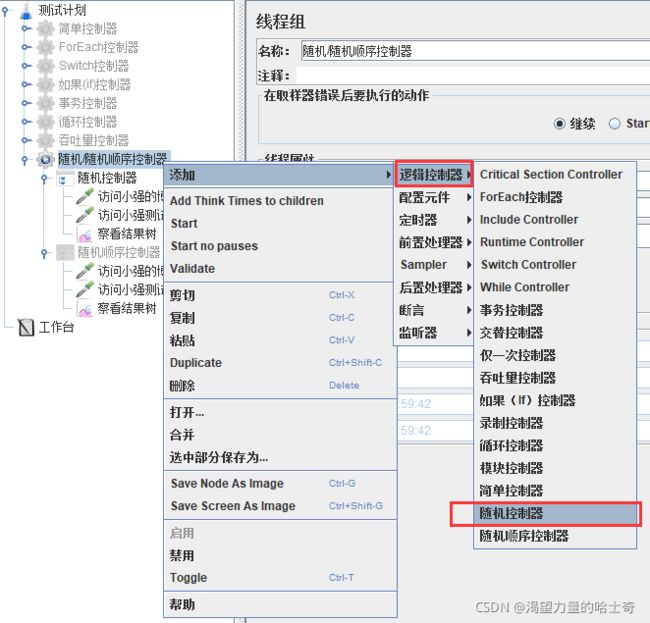
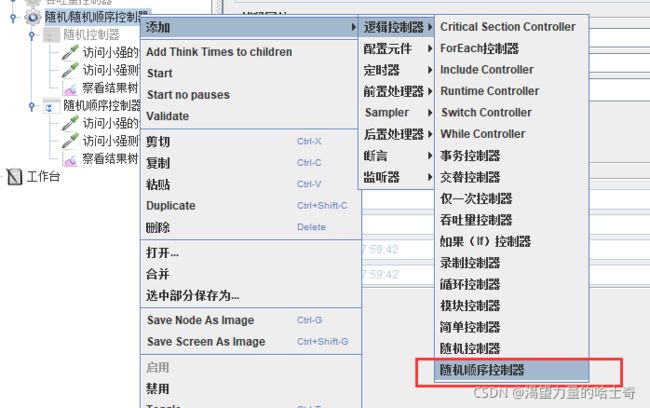
随机 / 随机顺序控制器
随机控制器
随机的选择子节点下的请求去运行

随机顺序控制器
子节点下的请求都执行,但是执行的请求是随机的。
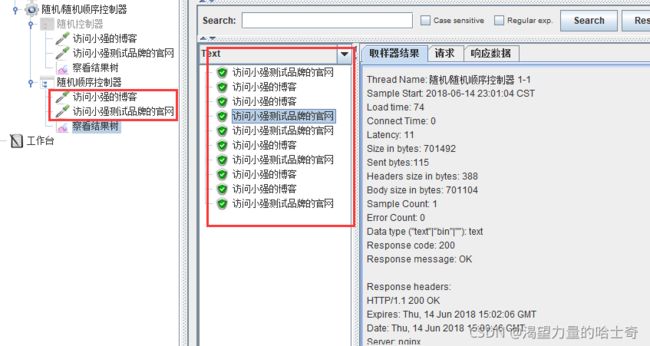
例:如果“随机顺序控制器”下的请求有两个、循环5次。那么请求共执行10次,顺序随机。
五、Jmeter定时器
可以理解为间隔时间、停留时间、思考时间
规则:
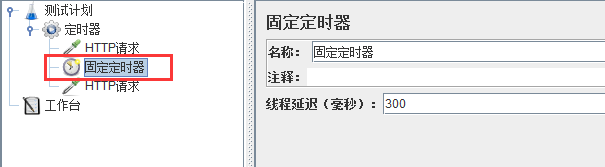
- 1、定时器执行于每一个sampler(HTTP请求) 之前,如有多个sampler(HTTP请求),在同一层级的情况下,作用于多个sampler。
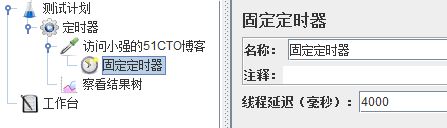
- 2、若定时器作为子节点,则该定时器仅作用于某一个sampler。
固定定时器
设置一个固定的停顿时间,停顿时间过后,才会执行下一步请求。
单位:毫秒

设置循环2次,执行过程中能够明显看到两次,请求之间的时间间隔。

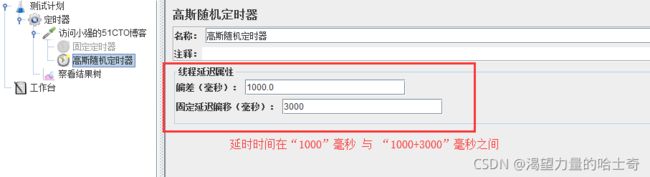
高斯随机定时器
基本同上,只是定时器的延时时间是在指定范围内的正态分布。
同步定时器 Synchronizing Timer
类似LoadRunner的集合点,和(rendezvous point)差不多的功能。
在该定时器处,使线程等待,一直到指定的线程个数达到后,再一起释放。可以在瞬间 制造出很大的压力。

均匀随机定时器(Uniform Random Timer)
同上,延时时间是在指定范围内,并且每个时间取值的概率相同。
固定吞吐量定时器(Constant Throughput Timer)
可以让JMeter以指定数字的吞吐量(即指定TPS,只是这里要求指定每分钟的执行数, 而不是每秒)执行。吞吐量计算的范围可以为指定为当前线程、当前线程组、所有线程 组,并且计算吞吐量的依据可以是最近一次线程的执行时延。
这种定时器在特定的场景下,还是很有用的。
BeanShell定时器(BeanShell Timer)
这个定时器,平时用不上。但实际上,它是最强大的,因为可以自己编程实现想要干的 任何事。
有复杂需求时,就要靠它了。例如,希望在每个线程执行完等待一下,或者希望在某个 变量达到指定值的时候等待一下。
六、Jmeter配置元件
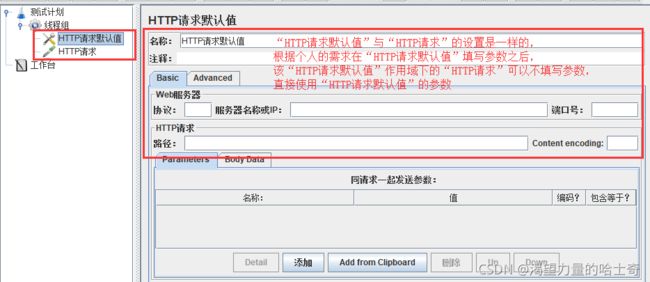
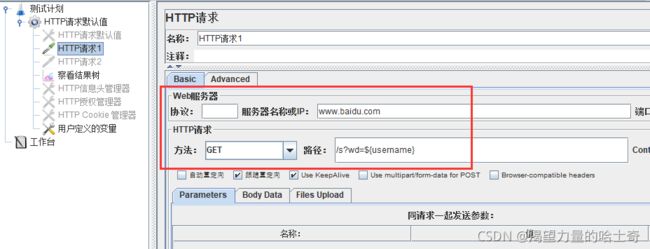
HTTP请求默认值
设定一些缺省值、默认值
假如,我们创建一个测试计划有很多个HTTP请求,且都是发送到相同的server,这时 我们只需添加一个 Http request defaults组件(HTTP请求默认值)并设置“Server Name or IP”(服务器名称或IP),然后添加多个HTTP请求且不设置"server name or ip",这些 HTTP请求会默认使用Http request defaults组件(HTTP请求默认值)设置的值。
作用域
可以设置成全局变量,也可以设置成局部变量,当在线程外设置,线程内也设置了,使 用线程内的默认值。

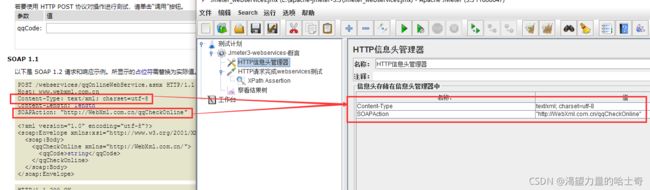
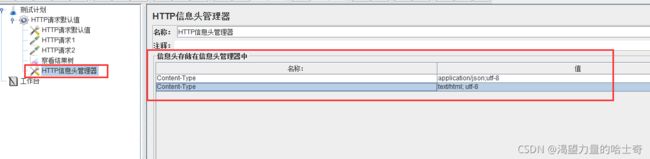
HTTP信息头管理器
使用HTTP信息头管理,可以帮助测试人员设定JMeter发送的HTTP请求头所包含的信 息。HTTP信息头中包含有”User-Agent"、“Pragma"、”Referer"等属性。尽可能放在线程 组一级。除非因为某些原因,测试人员希望不同的HTTP请求使用不同的HTTP信息头。
一般请求格式:
1、类似form表单---不填
2、参数json格式---application/json
3、参数是xml---text/xml
Content-Type
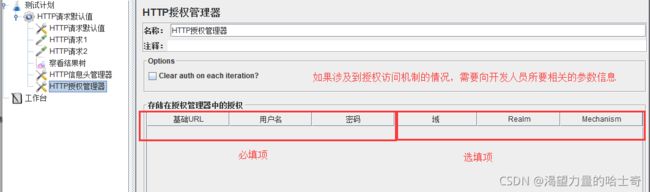
HTTP授权管理器
可以理解为一个用户名、密码的验证过程
在与客户端浏览器、服务器之间发生交互发生请求的时候,提供一个凭证。

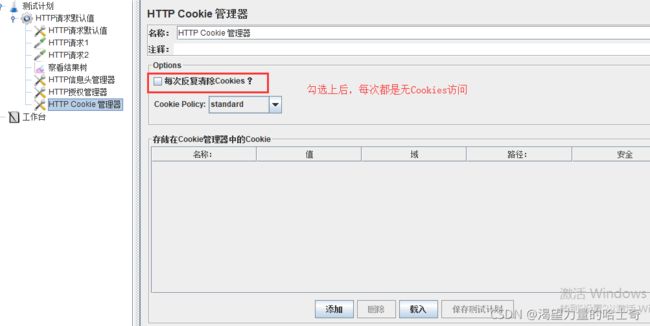
HTTP Cookie管理器
Cookies是什么
-
储存在用户本地终端上的数据
- session
- 相对的session是存储在远程服务器上的数据
-
通常情况下,当用户结束浏览器会话时,系统将终止所有的Cookie。当Web服务
器创建了Cookie后,只要在其有效期内,当用户访问同一个Web服务器的时,浏
览器首先要检查本地的Cookies,并将其原样发送给Web服务器 -
Cookies 最典型的应用是判断注册用户是否已经登陆网站,用户可能会得到提示,
是否在下一次进入此网站时保留用户信息以便简化登陆手续,这些都是Cookies的
功用。另一个重要应用场合是“购物车”之类处理。用户可能会在一段时间内在同
一家网站的不同页面中选择不同的商品,这些信息都会写入Cookies,以便在最后付
款时提取信息。
Cookies的管理
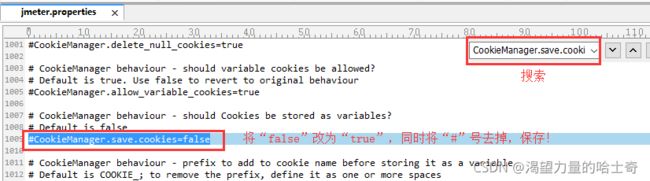
自动管理Cookies
- 在Jmeter配置文件中找到“jmeter.properties”配置文件
- 在文件中搜索“#CookieManager.save.cookies=false”,将“false”改为“true”
并将“#”号去掉,否则不会生效,然后重启Jmeter即可。
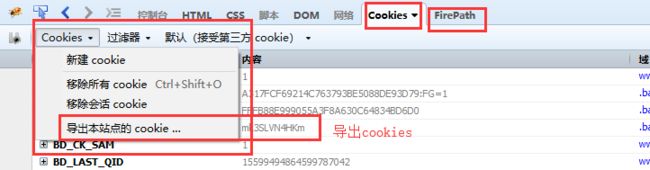
手动管理Cookies
- 可以利用firefox中的导出cookies之后,再导入Jmeter中,轻松完成。
- 前提是FireFox浏览器安装好“FirePath”插件,具体安装方法自行百度。
- 通过FireFox的FirePath插件将Cookies导出,再在Jmeter载入即可。

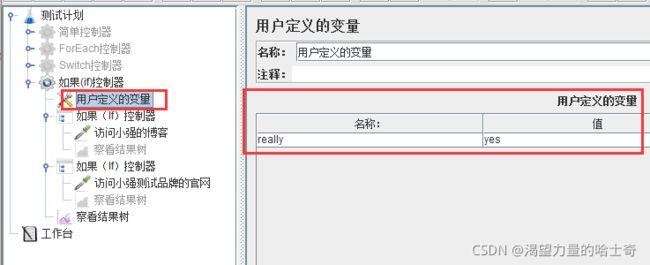
用户定义的变量
类似于公共的元素公共的值。
前期自己定义好一个变量,后续可以直接引用变量的名称。
使用场景:一组API根据业务流程制作成测试脚本,想要移植到其他测试环境时,由于 数据库发生了变更,有些初始化数据也相应发生了变化,例如环境地址、请求路径等等。 甚至可以把服务器地址和接口的部分共同请求路径都做成了自定义变量。
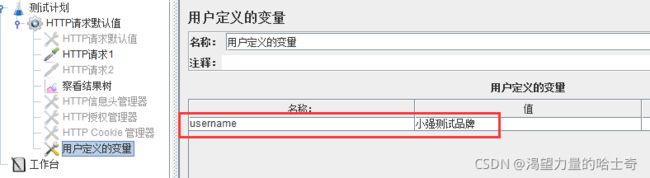
实例
jmeter的自定义变量可以让我们随机选取变量,从而达到在性能测试过程中可以随机选 取变量的目的。但是在实际使用中发现一个问题,并不试用于所有场景,比如登录
我的自定义变量如图:

在登录表单中的随机变量取值方式为:

运行完后结果为:
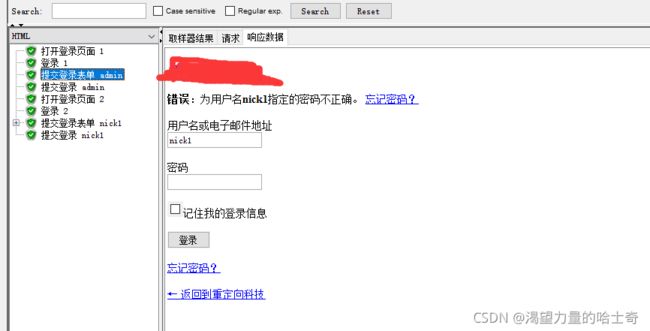
可以看到,两个用户有一个登录成功,有一个失败,这是因为在取值时${__RandomFromMultipleVars(user1|user2)},用户名是随机取一个,而密码 ${__RandomFromMultipleVars(password1|password2)}也是随机取一个,而密码与用户名 取的时候是独立的,有可能取到的用户名与密码不匹配,这是只有两个用户,要是用户 多的话可能会导致大量的登录失败。此种情况有两种解决方案,
第一:
不使用${__RandomFromMultipleVars(password1|password2)}这个方法来取变量, ${__V(user${__threadNum})},换为这个方法,这个方法取的时候是第一个用户的 __threadNum就是1,这样就能取到user1,密码同理也是取到password1,这样就能保证密码与用户名完全匹配了。
第二:
不用用户自定义变量,而是从csv文件中读取,在csv中取值是按行从左到右取值的, 把一个用户名密码写在同一行,这样取值的时候也能保证用户名与密码保持一致。
参考链接:https://blog.csdn.net/shuimengzhen/article/details/54410965
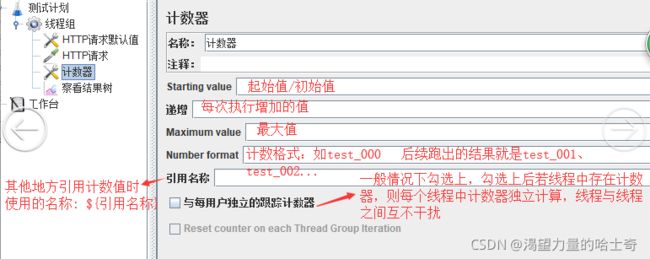
计数器
做数字记录的功能

----
七、Jmeter后置处理器
在Sampler运行后执行。
在测试过程中,经常需要从请求的响应数据汇总,找到某些参数,作为下一个请求的参 数,这时候需要用到后置处理器。
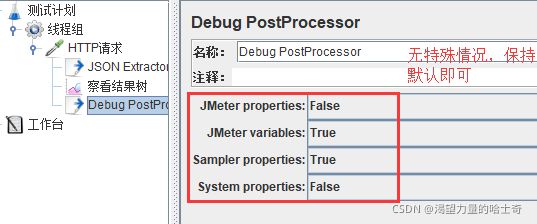
Debug Postprocessor
Debug PostProcessor(调试后置处理器)使用前面的采样属性的详细信息创建了一个子 样例,jmeter变量、属性和系统属性。
结果的值可以在监听器—观察结果树中查看返回值。

举例

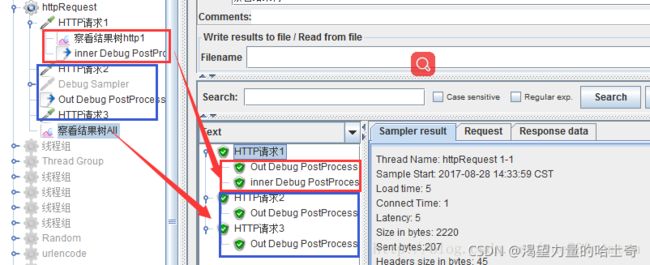
作用域示例
-
请求外(out Debug PostProcessor):
- 所有请求对Debug PostProcessor都是上一个请求,可获取当前请求之前所有测试计划、 用户定义的变量、参数化变量、 请求产生的变量数据。但无法获取请求内的前、后置 处理器定义生成的变量;
-
请求内(inner Debug PostProcessor):
- 当前所属请求为其上一个请求,可获取当前线程之前所有测试计划、用户定义的变量、 参数化变量、 请求产生的变量数据,以及当前 请求产生的变量数据。
Json Extractor
获取Json格式响应数据的
$.error_code 、 $.result 、$.result.id
比如某一请求的返回值为:
{"statusCode":200,"data":{"userId":"4a2cbe616eb74f0d99190af072c8dea6","token":"37e7a9e198186f5a443e50e6138a5bd20bd"}}
这里因为返回的是json数据,$.data.token,获取token的值
但是有碰到一个坑
另外一个接口请求返回值为:
{"statusCode":200,"data":[{"code":"407949","id":"aa477ad2085d492a99b877d14343d68d","name":"90一中4545"}]}
同样,使用$.data.id去提取id的值时,发现获取到的数据为空
原来这个responses 的data为数组,故应为 $.data[0].id 提取第1个值
如下:

备注:
JSON中 data 是一个对象数组,data[0] 代表取的是第一个数组的对象,data[*] 代表取全部对象。
.id 取的是id的值 .name取的是name的值。
例如,返回值为:
{
: "status":0,
: "data":
: {
: : "resources":
: : [
: : : {
: : : : "id":1,
: : : : "name":"广告位"
: : : },
: : : {
: : : : "id":2,
: : : : "name":"优惠券"
: : : },
: : : {
: : : : "id":3,
: : : : "name":"实物赞助"
: : : }
: : ],
: : "trades":
: : [
: : : {
: : : : "id":546,
: : : : "tradeName":"IT/互联网"
: : : },
: : : {
: : : : "id":547,
: : : : "tradeName":"游戏/动漫"
: : : },
: : ]
: }
}
这里要分别取resources 和 trades 的所有id值,表达式可以写:$.data.trades[*].id 。(代表trades下所有子集中的id)

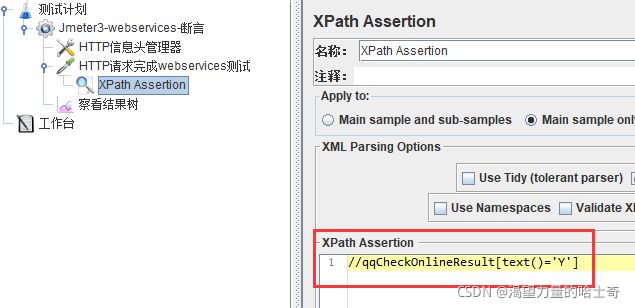
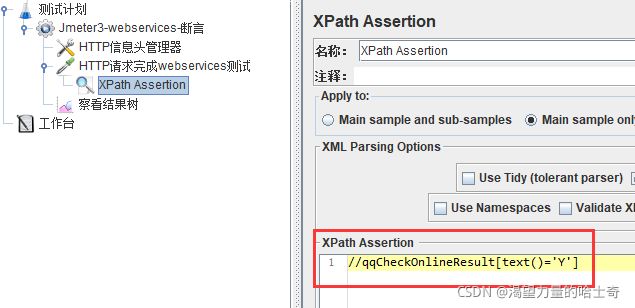
获取XML格式相应数据的
以“Jmeter_webservices.jmx”为例

APPly to:作用范围(返回内容的断言范围)
Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
Main sample only:仅作用于父节点的取样器
Sub-samples only:仅作用于子节点的取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称
XML Parsing Options:要解析的XML参数
Use Tidy:当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式(例如RSS返回),则取消选中;
Quiet表示只显示需要的HTML页面,Report errors表示显示响应报错,Show warnings表示显示警告;
Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨;
Validate XML:根据页面元素模式进行检查解析;
Ignore Whitespace:忽略空白内容;
Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容;
Return entire XPath fragment of text content:返回文本内容的整个XPath片段;
Reference Name:存放提取出的值的参数;
XPath Query:用于提取值的XPath表达式;
Default Value:参数的默认值;
八、Jmeter监听器
利用监听器监控执行过程中的数据;如执行次数、响应时间、吞吐量、错误率等等…
在jmeter中,通过监听器组件来提供查看、保存、和读取已保存的测试结果功能。
默认情况下,测试结果将被存储为xml格式的文件,文件的后缀: “.jtl”。另外一种存储 格式为CSV文件,该格式的好处就是效率更高,但存储的信息不如xml格式详细。
常用监听器报告
查看结果树
使用Jmeter测试过程中使用最多的监听器
可以在测试过程中可以看到请求的参数、响应的结果,方便对测试脚本的结果做出判断
但是在实际项目过程中,不论是接口自动化测试还是性能测试,在真正运行测试脚本的 时候。一般情况下,查看结果树是需要关闭的。
附:一般只运用于调试脚本。
Summary Report
概要报表;概要信息报告
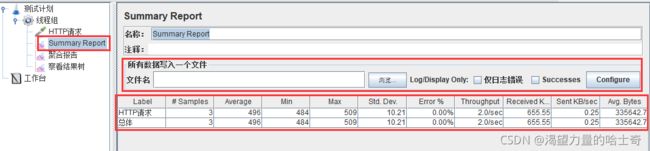
所有数据写入一个文件:保存测试结果到本地。
文件名:指定保存结果。
仅日志错误:仅保存日志中报错的部分。
Successes:保存日志中成功的部分。
Configure:设置结果属性,即保存哪些结果字段到文件。一般保存必要的字段 信息即可,保存的越多,对负载机的IO会产生影响。
Label:取样器/监听器名称 [最好改成业务名称]
Samples :事务数量
Average:平均一个完成一个事务消耗的时间(平均响应时间)
Median:所有响应时间的中间值,也就是 50% 用户的响应时间,大概是这个意思
Min:最小响应时间
Max:最大响应时间
以上单位都是ms
Std.Dev:偏离量/标准差,值越小表示越稳定
Error %:错误事务率
Throughtput:每秒事务数,即tps 吞吐量
Received KB/sec:网络吞吐量;接收和发送的网络流量 单位是KB
Avg.Bytes:平均数据流量,单位是Byte。
聚合报告

Label:请求对应的name属性值。
Samples : 具有相同标号的样本数,总的发出请求数。
Average :请求的平均响应时间。
Median - 50%:50%的样本都没有超过这个时间。这个值是指把所有数据按由小到大将其排列,就是排列在第50%的值。
90% Line :90%的样本都没有超过这个时间。这个值是指把所有数据按由小到大将其排列,就是排列在第90%的值。
95% Line :95%的样本都没有超过这个时间。这个值是指把所有数据按由小到大将其排列,就是排列在第95%的值。
99% Line :99%的样本都没有超过这个时间。这个值是指把所有数据按由小到大将其排列,就是排列在第99%的值。
Min : 最小响应时间。
Max : 最大响应时间。
Error % :本次测试中,有错误请求的百分比。
Throughput : 吞吐量是以每秒/分钟/小时的请求量来度量的。这里表示每秒完成的请求数。
Received KB/sec : 收到的千字节每秒的吞吐量测试。
Sent KB/sec : 发送的千字节每秒的吞吐量测试。
聚合报告中的90%的理解
90% Line :90% of the samples took no more than this time. The remaining samples at leastt as long as this.
一组数由小到大进行排列,找到他的第90%个数(假如是12),那么这个数组中有90% 的数将小于等于12 ,也就是90%用户响应时间不会超过12 秒。
聚合图表(Aggregate Graph)
一般情况下使用不多,出图表的效率与LoadRunner 还是又一定的差距的。
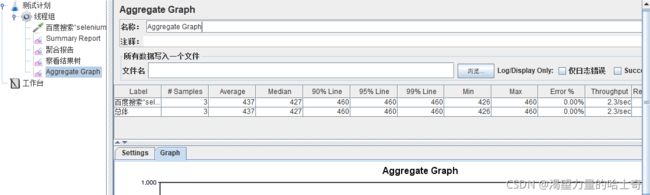
Jmeter也有Loadrunner一样的图形监控扩展
Jmeter的痛点
1、图形监控,相比Loadrunner还是是逊色不少的
2、能监控Windows或Linux吗?就想Loadrunner一样。
扩展插件
- 下载
plugins-manager.jar并将其放入lib / ext目录,然后重新启动JMeter - 下载地址:https://jmeter-plugins.org/downloads/old/
- 我们需要将serverAgent目录下面的文件复制到我们的测试的服务器上,然后点击打
开(我这里是本机,直接在本机上面打开这个应用系统即可,它的默认端口:4444) 下载地址:https://jmeter-plugins.org/wiki/PerfMonAgent/ 该链接地址已经失效
百度云盘链接:http://pan.baidu.com/s/1skZS0Zb 密码:isu5
其中JMeterPlugins-Standard和JMeterPlugins-Extras是客户端的插件,ServerAgent是服务端的插件。
下载成功后,复制JmeterPlugins-Extras.jar和JmeterPlugins-Standard.jar两个文件,放到jmeter安装文件中的lib/ext中,重启jmeter,即可看到该监视器插件。如下图:
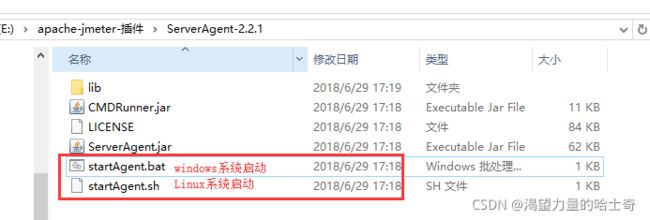
将ServerAgent-2.2.1.jar上传到被测服务器,解压,进入目录,Windows环境,双击
ServerAgent.bat启动;linux环境执ServerAgent.sh启动,默认使用4444端口。
如出现如下图所示情况,即表明服务端配置成功:

- 服务端启动校验
- CMD进入命令框,观察是否有接收到消息,如果有,即表明ServerAgent成功启动。
- 客户端监听测试
- 给测试脚本中添加jp@gc - PerfMon Metrics Collector监听器,然后添加需要监控的服务 器资源选项,启动脚本,即可在该监听器界面看到资源使用的曲线变化。如下图所示:

在脚本启动后,即可从界面看到服务器资源使用的曲线变化,Chart表示主界面显示, Rows表示小界面以及不同资源曲线所代表的颜色,Settings表示设置,可选择自己需要 的配置。
PerfMon Metrics Collector
即服务器性能监控数据采集器。在性能测试过程中,除了监控TPS和TRT,还需要监控 服务器的资源使用情况,比如CPU、memory、I/O等。该插件可以在性能测试中实时监 控服务器的各项资源使用。
使用方法参照上述的 “客户端监听测试”
Response Times Over Time
即TRT:事务响应时间,性能测试中,最重要的两个指标的另外一个。该插件的主要作 用是在测试脚本执行过程中,监控查看响应时间的实时平均值、整体响应时间走向等。
使用方法如上,下载安装配置好插件之后,重启jmeter,添加该监视器,即可实时看到 实时的TRT数值及整体表现。
某次压力测试TRT变化展示图:

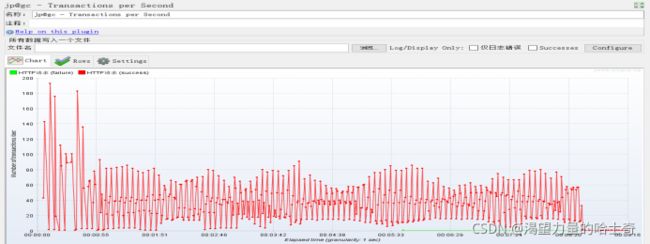
Transactions per Second
即TPS:每秒事务数,性能测试中,最重要的2个指标之一。该插件的作用是在测试脚 本执行过程中,监控查看服务器的TPS表现————比如 JU
某次压力测试TPS变化展示图:
Hits per Second
点击率
在做性能测试的时候,不建议添加太多的监听器,在并发量高得情况下
会出现问题,毕竟Jmeter 是需要读取文件的。
邮件观察仪
在QQ/163邮箱中开启pop3/smtp服务,并生成授权码,备用

在jmeter中添加邮件观察仪,并配置如下


说明信息:
1、文件名:只需要给出路径和保存的文件名称即可,给定之后将会把测试结果的数据写入到文件中
注:它不会将此文件已附件的形式在邮件中,只是将测试结果写入到了定的此目录文件中,如果你运行完脚本,
直接在此路径下打开此文件就可以看到运行结果
2、Address(s):收件人,添加多个收件人邮箱时,中间用逗号隔开,
如:lucky@iberhk.com,bob@iberhk.com
3、Success Limit与Failure Limit:当成功数与失败数为几时进行邮件的发送,我写的1,则失败1次后将发送邮件通知我
4、SMTP的配置见下文
SMTP的配置
重要信息:
HOST:smtp.exmail.qq.com
Port:465
Login:登录的邮箱,填写自己的邮箱即可
Password:16位的授权密码
Connection Security:一定要选SSL
如何获取授权码自行百度。
点击test mail则会在对应邮箱中收到邮件
在测试过程,需要配置success limit failure limit的值

九、什么是接口?
官方定义:
接口泛指实体把自己提供给外界的一种抽象化物(可以为另一实体),用以由内部操作 分离出外部沟通方法,使其能被内部修改而不影响外界其他实体与其交互的方式。
人类与电脑等信息机器或人类与程序之间的接口称为用户界面。电脑等信息机器硬件组 件间的接口叫硬件接口。电脑等信息机器软件组件间的接口叫软件接口。
在计算机中,接口是计算机系统中两个独立的部件进行信息交换的共享边界。这种交换 可以发生在计算机软、硬件,外部设备或进行操作的人之间,也可以是它们的结合。
白话文理解:
通过测试程序模拟客户端向服务器发送请求报文,服务器接收请求报文后对相应的报文
做出处理然后再把应答报文发送给客户端,客户端接收应答报文这一过程(request(请
求)→response(响应));
类似我们的黑盒共嗯那个测试,即内部具体结构你不知道,但你需要知道我输入的什么,
之后输出什么才是对的,什么才是错的。这就是白话解释的接口。
接口类型以及特点

HTTP
1、基于HTTP协议,通过post和get得到想要的东西
2、处理数据效率较高
3、当你需要调用一个你本服务的内容的时候,不涉及到跨域的问题,使用HttpService的方式
WebService
1、使用soap协议得到想要的东西
2、能处理比较复杂的数据类型 (一般都是xml)
3、如果,你需要在后台调用一个其他应用的服务,这时候用WebService的方式来调用。
报文介绍
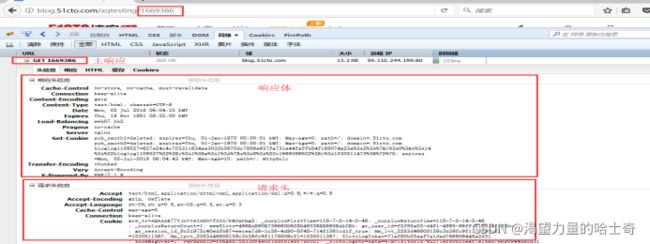
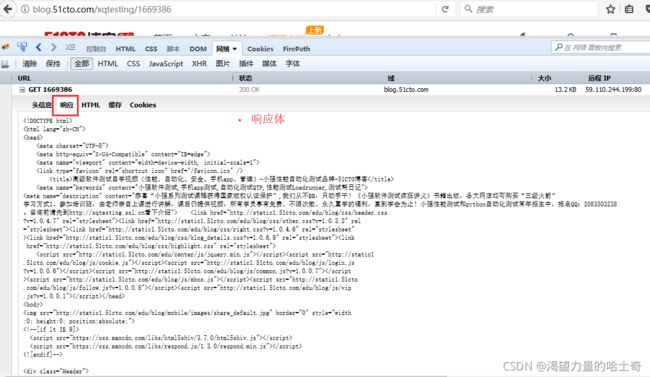
以访问 http://xqtesting.blog.51cto.com/4626073/1669386 为例
妈蛋 真不想写这玩意儿!

接口测试文档规范
文档重要性
没有文档就没有根据,就好比没有需求的产品最后做出来的都是垃圾一样。
接口文档规范
以 微博API/获取当前登录用户及其所关注用户的最新微博 为例
微博APIhttp://open.weibo.com/wiki/微博API
获取当前登录用户及其所关注用户的最新微博http://open.weibo.com/wiki/2/statuses/home_timeline
接口名:接口的解释
请求类型:get/post
数据传递格式:json/xml
前置条件:是否登陆
请求参数:多少参数;可选还是必选;类型/含义;
返回参数:返回参数有哪些;类型/含义;
错误代码解释:不同的错误代码,不同的解释。
十、各类接口测试实战
讲道理这一小章节着实有点水,真心不想写了!完全可以忽略!
HTTP接口测试
第一种方法(需LR使用经验)
Get接口
什么是get接口?
可以理解为去服务器上取数据;再白话一些就是 输入url地址,成功访问一个页面。
LR实战
地址:http://www.juhe.cn/docs/api/id/39/aid/132
Post接口
LR实战
地址:http://www.juhe.cn/docs/api/id/39/aid/132
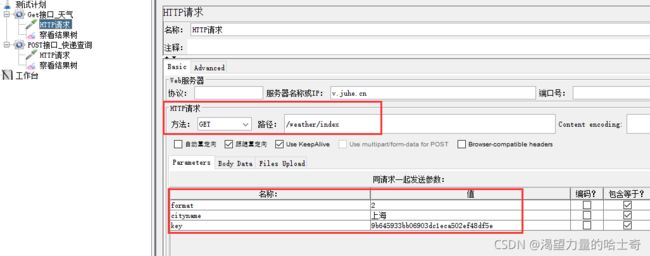
第二种方法(需Jmeter使用经验)
Jmeter实战
地址:http://www.juhe.cn/docs/api/id/39/aid/132
Get接口
Post接口
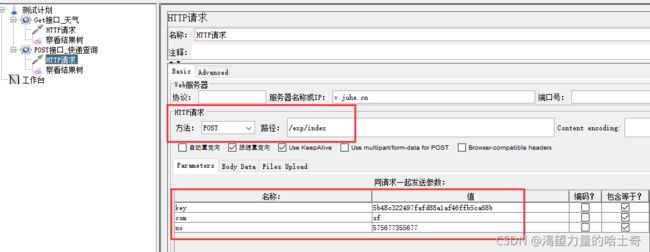
第三种方法(写代码_需要代码编写能力)
什么是jsoup?
Jsoup是一款Java的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提
供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操
作数据。
说白一点,其实就是可以用来抓取网页数据的,但我们今天却要用它来做接口测试,所
以说很多东西看你怎么用了,用对了小刀都可以杀了老虎,那些讲着五百年前就有的技
术的人非得宣称自己讲的是五百年后才有的,我也是醉了。
环境准备
1、Jdk
2、eclipse
3、jsoup的jar包


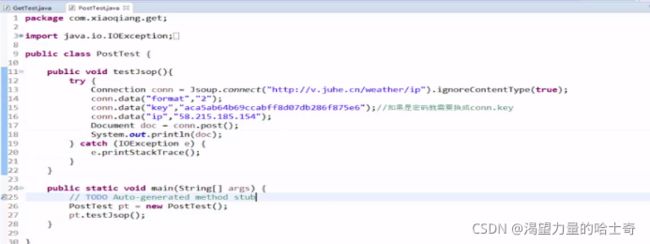
WebService接口测试
这一段不想写了,蛋疼!
十一、接口测试辅助工具以及thrift接口介绍
小巧型接口测试工具
火狐:httpclient
Chrmoe:postman
thrift介绍

十二、Jmeter’持续集成介绍
定义
持续集成是一种软件开发实践,即团队开发成员经常集成他们的工作,通常每个成员每
天至少集成一次,也就意味着每天可能会发生多次集成。
每天集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽快的发
现集成错误。
许多团队发现这个过程可以大大减少集成的问题,让团队能够更快的开发内聚的软件。
开源、免费
入门容易(其实也不容易)
易用性不错
发展迅猛
插件丰富等等。
价值
减少风险:一天中进行多次的集成,并做了相应的测试,这样有利于检查缺陷,了解软
件的健康状况,减少假定。
及时暴露问题。
减少重复过程:通过自动化的持续集成可以将这些重复的动作都变成自动化的,无需太
多人工干预,让人们的时间更多的投入到动脑筋的、更高价值的事情上。
任何时间、任意地点生成可部署的软件。
增强项目的可见性:注意到趋势
持续部署改进。
持续集成工具介绍
- Jenkins(前身是hudson)—最流行的
- Apche Continuum
- ThoughtWorks Go
- TeamCity,比较强大,包括客户端和服务端 商业版
- QuickBuild
- CruiseControl .NET 针对于.NET平台的
- Atlassian Bamboo
- 还有很多…
为什么选择Jenkins
- 因为最流行
- 因为开源、好用
- 因为得过奖
- 因为容易配置
- 因为插件丰富 (插件安装需要-科-学-上-网-,否则安装不成功)
- 因为先入为主吧…
- 因为太多了…
Jenkins环境搭建及配置
这个配置可能有些老了、说实话,我自己都不太想用这个配置了。
介绍
以下内容摘自某一篇网络文章,稍有改动:
Jenkins是一个持续集成工具。它可以根据设定持续定期编译,运行相应代码;运行UT
或集成测试;将运行结果发送至邮件,或展示成报告…
使用Jenkins目的
让项目保持健康的状态。如果有任何变动,每个人都会在最短的时间内通知到,然后问
题被fix掉。接下来的开发将是建立在一个健康正确的基础上,而不是人有问题累积,
最后失控。
Jenkinsshi 开源项目,简洁实用的用户界面设计,完善的文档,丰富的插件。
官方介绍文档:https://wiki.jenkins-ci.org/display/JENKINS/Home
安装
-
JDK1.7,安装并配置环境变量
-
maven3.3:http://maven.apache.org/download.cgi#
-
MAVEN_HOME:是安装目录,Path的值为%MAVEN_HOME%\bin
-
验证:mvn -version
-
ANT_HOME:是安装目录,Path的值为%ANT_HOME%\bin;%ANT_HOME%\lib
-
验证:ant -version
-
tomcat7:http://tomcat.apache.org/download-70.cgi
-
Jenkins1.6:http://jenkins-ci.org
-
双击安装,安装好后访问:http://ip:8080
全局设置
· 配置
· 添加JDK、ANT、MAVEN,其他保持默认

邮件地址
----
十三、轻量级接口自动化测试(持续集成篇-概念)
一些思想和普及
轻量级:做的不是很重的,比较轻巧的东西,轻量级接口自动化测试在企业中使用率是
比较高的,是接口测试必须要掌握的核心技能之一。(掌握了薪资可以很高)
接口测试的重要性
Robot、Appium是基于UI层的自动化测试。
UI层自动化测试的坏处:页面变化过快、界面效率是很低的。
退而求其次,接口层面的自动化测试是性价比非常高的,这也是大部分企业做接口自动
化测试的原因;
另一个原因就是很多时候,在一个产品开发的过程中,界面是最后才出来的,但是接口
是最先出来的。因为如果接口不通、有问题,那么出界面也是没有意义的。所以接口是
非常重要的,也是做接口自动化测试的重要的原因。
使用Jmeter做轻量级自动化测试
原因
· 开源、免费、足够轻量
· 对HTTP协议的支持非常强大
· 扩展性也比较好
· 编程能力强的情况下,可以自己写插件
· 同时支持各种断言
· 可以和很多构建的工具进行融合
· 比如可以和ant融合产出比较漂亮的测试报告
十四、轻量级接口自动化测试(持续集成篇-实战)
实战
· Jmeter解压到本地、ant解压到本地
· 完成一个Jmeter接口脚本,并确保是正确的
· 以访问51cto博客为例。
· 将Jmeter所在目录下extras子目录里的ant_Jmeter-1.1.1 复制到 Ant所在目录lib
子目录之下
· 将jmeter.resuils.shanhe.me.xsl 放到Jmeter的extras目录下
· 修改jmeter目录下的bin/jmeter.oroperties ,找到
jmeter.save.saveservice.output_format,去掉注释并设置为xml
· 脚本目录结构如下
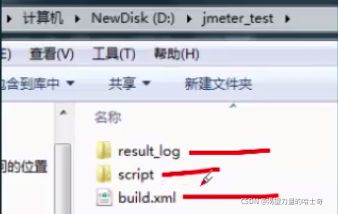
· 切换到创建好的脚本目录下(D:\jmeter_test),输入ant 查看运行结果
· html目录下可以查看报告
· 想看更详细的信息需要,修改“jmeter.oroperties”
不想写了,把我的思维导图贴上来吧…