【Python百日基础系列】Day03 - Python 数据类型
文章目录
-
- 一、Python中的数据类型
-
- 1.1 数据类型系统是编程语言的核心
- 1.2 Python中的数据类型种类
- 1.3 数据类型的可变性
- 1.4 数据类型查看函数 - type()
- 二、Number - 数字
-
- 2.1 整型(int)
- 2.2 浮点型(float)
- 2.3 布尔型(bool)
- 2.4 复数(complex)
- 2.5 数字类型转换函数
- 2.6 数字运算
- 三、String - 字符串
-
- 3.1 字符串的定义
- 3.2 字符串的常用操作
- 3.3 字符串的转码
- 四、List - 列表
-
- 4.1 列表的定义
- 4.2 列表的常用操作
- 4.3 列表的常用函数
- 4.4 列表的常用方法
- 五、Tuple - 元组
-
- 5.1 元组的定义
- 5.2 元组的索引
- 5.3 访问元组
- 5.4 删除元组
- 5.5 元组运算操作
- 5.6 元组的常用函数
- 5.7 元组常用方法
- 六、Dictionary - 字典
-
- 6.1 字典的定义
- 6.2 访问字典
- 6.3 修改字典
- 6.4 删除字典
- 6.5 字典相关函数
- 6.6 字典相关方法
- 七、Sets - 集合
-
- 7.1 集合定义
- 7.2 集合的常用操作
- 7.4 集合的常用函数
- 7.4 集合的常用方法
视频讲解1:数据类型 数字 字符串 列表
D03-Python数据类型 01 简介 数字 字符串 列表
视频讲解2:元组 字典 集合
Day03-Python数据类型 02 元组 字典 集合
一、Python中的数据类型
1.1 数据类型系统是编程语言的核心
数据类型一般指数据元。数据元( Data Element),也称为数据元素,是用一组属性描述其定义、标识、表示和允许值的数据单元,在一定语境下,通常用于构建一个语义正确、独立且无歧义的特定概念语义的信息单元。数据元可以理解为数据的基本单元。
1.2 Python中的数据类型种类
Python 3 中有六个标准的数据类型:
- Number(数字):数字类型是顾名思义是用来存储数值的,包括int(整型)、float(浮点型)、bool(布尔型)和complex(复数)。
- String(字符串):引号包裹的一串字符。
- List(列表):中括号[]包裹的,逗号分隔的元素序列。
- Tuple(元组):小括号()包裹的,逗号分隔的元素序列。元组不能修改,元组的元素不能重复。
- Sets(集合):大括号{}包裹的,逗号分隔的元素序列。集合的元素不能重复。
- Dictionary(字典):字典是一种映射类型,它的元素是键值对,字典的键必须为不可变数据类型且不能重复。
1.3 数据类型的可变性
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
可变数据(3 个):List(列表)、Set(集合)、Dictionary(字典)。
1.4 数据类型查看函数 - type()
- 查看对象类型:type(obj)
- 判断对象是否为某种类型:type(obj) == int / str / tuple / list /set / dict
二、Number - 数字
数字视频讲解:
2.1 整型(int)
通常被称为是整型或整数,是正或负整数,不带小数点。Python 3 整型是没有限制大小的。
a = 100
a = 12345 ** 123
print(a)
print(type(a))
print(type(a) == int)
输出结果:
179227478536797075276952162319434197129926964430623405351403914666844095303193142386105303128935260661331482166609669142646381589155256961299625923906846736377224598990446854741893321648522851663303862851165879753724272728386042804116173040017014488023693807547724950916588058455499429272048326934098750367364004488112819439755556403443027523561951313385041616743787240003466700321402142800004483416756392021359457461719905854364181525061772982959380338841234880410679952689179117442108690738677978515625
<class 'int'>
True
2.2 浮点型(float)
浮点型由整数部分与小数部分组成
a = 100.3
a = 12345.5 ** 12.3
print(a)
print(type(a))
print(type(a) == float)
输出结果:
2.1162004909718374e+50
<class 'float'>
True
2.3 布尔型(bool)
bool 类型就是用于代表某个事情的真(对)或假(错),如果这个事情是正确的,用 True(或 1)代表;如果这个事情是错误的,用 False(或 0)代表。
布尔类型可以当做整数来对待,即 True 相当于整数值 1,False 相当于整数值 0。
a = 2 > 1
print(a)
print(type(a))
print(type(a) == bool)
print(a + 2)
print(True + 2)
print((not a) - 10)
print(False - 10)
输出结果:
True
<class 'bool'>
True
3
3
-10
-10
2.4 复数(complex)
复数由实数部分和虚数部分构成,可以用 a+bj 或者 complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
a = 123 - 12j
print(a.real) # 实部
print(a.imag) # 虚部
输出结果:
123.0
-12.0
2.5 数字类型转换函数
- 转为整型:int()
- 转为浮点型:float()
- 转为布尔型:bool(),0为False,其他均为True
- 转为复数型:complex()
print(int(123.56))
print(float(123))
print(bool(10.5))
print(bool(-10.5))
print(bool(0))
print(complex(123))
print(complex(123, 56))
输出结果:
123
123.0
True
True
False
(123+0j)
(123+56j)
2.6 数字运算
数字运算包括:
- 加:+
- 减:-
- 乘:*
- 除:/
- 整除://
- 取余:%,不同于除法和整除,取余结果的符号与被除数保持一致
- 乘方:**
print(5 + 4) # 加法,输出 9
print(4.3 - 2) # 减法,输出 2.3
print(3 * 7) # 乘法,输出 21
print(6 / 2) # 除法,得到一个浮点数 输出 3.0
print(6 // 2) # 整除,得到一个整数 输出 3
print(17 % 3) # 取余,输出 2
print(17 % -3) # 取余,输出 -1
print(-5 % -2) # 取余,输出 -1
print(2 ** 5) # 乘方,输出 32
三、String - 字符串
3.1 字符串的定义
字符串的定义可以使用单引号、双引号、三单引号和三双引号,其中三引号可以多行定义字符串。
s1 = '我是单引号定义的字符串'
s2 = "我是双引号定义的字符串"
s3 = '''我是三单引号定义的字符串,
可以输入好多行
!!!'''
s4= """我是三双引号定义的字符串
可以输入好多行\
!!!"""
print(s1)
print(s2)
print(s3 + '\n')
print(s4)
输出结果:
我是单引号定义的字符串
我是双引号定义的字符串
我是三单引号定义的字符串,
可以输入好多行
!!!
我是三双引号定义的字符串
可以输入好多行!!!
3.2 字符串的常用操作
- 字符串的长度:len(str)
- 字符串的连接:+
- 字符串的重复:*
- 字符串的切片:[]
- 字符串的分隔:str.split()
- 字符串的替换:str.replace()
- 字符串的查找:str.find(),str.index()
s1 = 'Hello '
s2 = 'world'
print(len(s1))
print(s1 + s2) # 连接
print(s1 * 3) # 重复
print(s1[0], s1[2], s1[-1]) # 单个切片
print(s1[0:2], s1[:2], s1[1:-1], s1[1:]) # 连续切片
print(s2[0:4:2], s2[::-1]) # 步长切片
print(s2.split('r')) # 分割结果为列表['wo', 'ld']
print(s1.replace('H', 'h')) # 替换
print(s1.find('l')) # 查找第一个l
print(s1.find('l', s1.find('l')+1)) # 从第一个l后索引开始查找第一个l
print(s1.find('abc')) # 找不到返回-1
print(s1.index('l')) # 查找第一个l,能找到同find
print(s1.index('abc')) # 找不到抛出ValueError
输出结果:
6
Hello world
Hello Hello Hello
H l
He He ello ello
wr dlrow
['wo', 'ld']
hello
2
3
-1
2
Traceback (most recent call last):
File "E:\python_100\py_100\Day03 - Python 数据类型.py", line 78, in <module>
print(s1.index('abc')) # 找不到抛出ValueError
ValueError: substring not found
- 字符串大小转换和判断, upper()、lower()、swapcase()、capitalize()、istitle()、isupper()、islower()
s1 = 'Hello '
s2 = 'world'
print(s1.upper()) # 转大写
print(s1.lower()) # 转小写
print(s1.swapcase()) # 大小写交换
print(s2.capitalize()) # 首字母大写
print(s1.istitle()) # 判断是否是首字母大写的样式
print(s1.isupper()) # 判断是否全为大写
print(s1.islower()) # 判断是否全为小写
输出结果:
HELLO
hello
hELLO
World
True
False
False
- 字符串去除首尾空格,strip()、lstrip()、rstrip()
s1 = 'Hello '
s2 = 'world'
print(s1.strip(), len(s1.strip())) # 去除首尾空格
print(s1.lstrip(), len(s1.lstrip())) # 去除首空格
print(s1.rstrip(), len(s1.rstrip())) # 去除尾空格
输出结果:
Hello 5
Hello 6
Hello 5
- 字符串格式化输出,有%、.format和f字符串三种方法,第三种最简单、可读性强,此处只介绍第三种
name = 'Tom' # 字符串
age = 18 # 整型
print(f'我是:{name},今年{age}岁。')
输出结果:
我是:Tom,今年18岁。
3.3 字符串的转码
- encode 将字符转换为字节
- decode 将字节转换为字符
s1 = '你好,Tom!'
print(s1.encode()) # 转换为字节,默认编码utf-8
print(s1.encode('utf-8')) # 转换为字节,默认编码utf-8
print(s1.encode('gbk')) # 转换为字节,编码gbk
print('前后默认编码', s1.encode().decode()) # 转换为字节,再转回字符串,默认编码utf-8
print('前默认,后utf-8', s1.encode().decode('utf-8')) # 转换为字节,再转回字符串,默认编码utf-8
print('前后gbk', s1.encode('gbk').decode('gbk')) # 转换为字节,再转回字符串,编码gbk
print('前gbk,后utf-8', s1.encode('gbk').decode()) # 转换为字节,再转回字符串,编码gbk
输出结果:
b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8cTom\xef\xbc\x81'
b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8cTom\xef\xbc\x81'
b'\xc4\xe3\xba\xc3\xa3\xacTom\xa3\xa1'
前后默认编码 你好,Tom!
前默认,后utf-8 你好,Tom!
前后gbk 你好,Tom!
Traceback (most recent call last):
File "E:\python_100\py_100\Day03 - Python 数据类型.py", line 111, in <module>
print('前gbk,后utf-8', s1.encode('gbk').decode()) # 转换为字节,再转回字符串,编码gbk
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc4 in position 0: invalid continuation byte
四、List - 列表
列表是Python最常用的数据类型,它由中括号[]和内部用逗号分隔的元素组成。
- 列表的元素不需要具有相同的类型
- 列表的元素可以重复
- 列表的元素是有序的,列表的每个元素对应一个隐含的索引值,从0开始。
4.1 列表的定义
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。
4.2 列表的常用操作
- 列表的连接:+
- 列表的重复:*
- 列表的切片:[]
- 列表的成员运算:in
- 列表的迭代:for
lst1 = ['1', '8', 'x', 'A', '5']
lst2 = [200, 10.5, True, 123+12j, 'Tom', lst1, (1, 2, 3), {1, 2, 3}, {'name': 'Tom', 'age': 18}]
print(lst2) # 查看定义的列表
print(lst1 + lst2) # 列表元素的连接,元素级操作
print(lst1 * 3) # 列表元素的重复,元素级操作
print(lst2[-4:]) # 列表的切片,操作同字符串
print(lst2[::-1])
print('1' in lst1) # 成员运算
print('--------------')
for item in lst2: # 列表迭代
print(item)
输出结果:
[200, 10.5, True, (123+12j), 'Tom', ['1', '8', 'x', 'A', '5'], (1, 2, 3), {1, 2, 3}, {'name': 'Tom', 'age': 18}]
['1', '8', 'x', 'A', '5', 200, 10.5, True, (123+12j), 'Tom', ['1', '8', 'x', 'A', '5'], (1, 2, 3), {1, 2, 3}, {'name': 'Tom', 'age': 18}]
['1', '8', 'x', 'A', '5', '1', '8', 'x', 'A', '5', '1', '8', 'x', 'A', '5']
[['1', '8', 'x', 'A', '5'], (1, 2, 3), {1, 2, 3}, {'name': 'Tom', 'age': 18}]
[{'name': 'Tom', 'age': 18}, {1, 2, 3}, (1, 2, 3), ['1', '8', 'x', 'A', '5'], 'Tom', (123+12j), True, 10.5, 200]
True
--------------
200
10.5
True
(123+12j)
Tom
['1', '8', 'x', 'A', '5']
(1, 2, 3)
{1, 2, 3}
{'name': 'Tom', 'age': 18}
4.3 列表的常用函数
- len(lst):列表元素个数
- max(lst):返回列表元素最大值
- min(lst):返回列表元素最小值
- list(seq):将元组、集合转换为列表
lst1 = ['1', '8', 'x', 'A', '5']
lst2 = [200, 10.5, True, 123+12j, 'Tom', lst1, (1, 2, 3), {1, 2, 3}, {'name': 'Tom', 'age': 18}]
print(len(lst1), len(lst2)) # 查看列表元素个数(长度)
print(max(lst1))
print(min(lst1))
print(list((1, 2, 3)), list({1, 2, 3}))
输出结果:
5 9
x
1
[1, 2, 3] [1, 2, 3]
4.4 列表的常用方法
- lst.append(obj):在列表末尾添加新的对象
- lst.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
- lst.insert(index, obj):将对象插入列表
- lst.remove(obj):按值删除元素,无返回值
- lst.pop([index=-1]):按索引移出元素(默认最后一个元素),返回移出的元素
- del lst[index]:# 按索引删除元素
- lst.index(obj):从列表中找出某个值第一个匹配项的索引位置
- lst.count(obj):统计某个元素在列表中出现的次数
- lst.reverse():反向列表中元素
- lst.sort(cmp=None, key=None, reverse=False):对原列表进行排序
lst1 = ['1', '8', 'x', 'A', 5]
lst2 = [200, 5, 10]
lst1.append(lst2)
print(lst1)
lst1.extend(lst2)
print(lst1)
lst1.insert(2, 200)
print(lst1)
print('----------------')
res = lst1.remove(200) # 按值删除元素,无返回值
print(lst1)
print(res)
res = lst1.pop(2) # 按索引移出元素,返回移出的元素
print(lst1)
print(res)
del lst1[2] # 按索引删除元素
print(lst1)
print('==============')
print(lst1.index(5))
print(lst1.count(5))
lst1.reverse()
print(lst1)
lst2.sort()
print(lst2)
输出结果:
['1', '8', 'x', 'A', 5, [200, 5, 10]]
['1', '8', 'x', 'A', 5, [200, 5, 10], 200, 5, 10]
['1', '8', 200, 'x', 'A', 5, [200, 5, 10], 200, 5, 10]
----------------
['1', '8', 'x', 'A', 5, [200, 5, 10], 200, 5, 10]
None
['1', '8', 'A', 5, [200, 5, 10], 200, 5, 10]
x
['1', '8', 5, [200, 5, 10], 200, 5, 10]
==============
2
2
[10, 5, 200, [200, 5, 10], 5, '8', '1']
[5, 10, 200]
五、Tuple - 元组
5.1 元组的定义
- Python 的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号 ( ),列表使用方括号 [ ]。元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
tuple = ("google", "Runoob", "Taobao")
print(tuple)
print(type(tuple))
输出结果:
('google', 'Runoob', 'Taobao')
<class 'tuple'>
元组不能修改
tp = ("google", "Runoob", "Taobao", 100, 200.5, [1, 2, 3])
lst = list(tp)
lst[0] = 'first'
print(lst)
tp[0] = 'first'
print(tp)
输出结果:
['first', 'Runoob', 'Taobao', 100, 200.5, [1, 2, 3]]
Traceback (most recent call last):
File "E:\python_100\py_100\03.py", line 5, in <module>
tp[0] = 'first'
TypeError: 'tuple' object does not support item assignment

2. 创建空元组:tp = ()
3. 创建单元素元组,必须在元素后面加一个逗号,否则括号会被当作运算符使用。这一点与列表不同,列表可加可不加。
tp = (50)
print(tp, type(tp))
tp1 = (50,)
print(tp1, type(tp1))
输出结果:
50 <class 'int'>
(50,) <class 'tuple'>
5.2 元组的索引
元组与字符串类似,下标索引从 0 开始,可以进行截取,组合等。
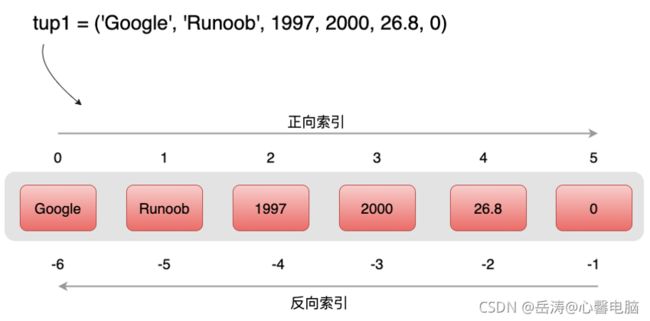
5.3 访问元组
和列表一样,元组可以使用下标索引来访问元组中的值
tp = ("google", "Runoob", "Taobao", 100, 200.5, [1, 2, 3])
print(tp[2])
print(tp[-1][1])
print(tp[::-1])
输出结果:
Taobao
2
([1, 2, 3], 200.5, 100, 'Taobao', 'Runoob', 'google')
5.4 删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,其实是删除变量
tp = ('单元素元组',)
del tp
print(tp)
输出结果:
Traceback (most recent call last):
File "E:\python_100\py_100\03.py", line 3, in <module>
print(tp)
NameError: name 'tp' is not defined
5.5 元组运算操作
与字符串一样,元组之间可以使用 + 号和 * 号进行运算,运算后会生成一个新的元组。
- 连接:+
- 复制:*
- 成员运算:in
- 循环迭代:for
tp1 = ("google", "Runoob", "Taobao", 100, 200.5, [1, 2, 3])
tp2 = ('单元素元组',)
tp3 = tp1 + tp2
print(tp3)
tp4 = tp2 * 3
print(tp4)
print(100 in tp1)
print(100 in tp2)
print('--------------------')
for item in tp1:
print(item)
输出结果:
('google', 'Runoob', 'Taobao', 100, 200.5, [1, 2, 3], '单元素元组')
('单元素元组', '单元素元组', '单元素元组')
True
False
--------------------
google
Runoob
Taobao
100
200.5
[1, 2, 3]
5.6 元组的常用函数
与列表同名函数功能完全一样
- len(tuple):计算元组元素个数。
- max(tuple):返回元组中元素最大值。
- min(tuple):返回元组中元素最小值。
- tuple(iterable):将可迭代系列转换为元组。
tp = ("google", "Runoob", "Taobao")
lst = [1, 2, 3]
print(len(tp),)
print(max(tp))
print(min(tp))
print(tuple(lst))
输出结果:
3
google
Runoob
(1, 2, 3)
5.7 元组常用方法
- tuple.count():统计元组中指定值的个数
- tuple.index():查找指定值在元组中的索引,不存在会报错
tp = ("google", "Runoob", "Taobao")
print(tp.count('google'))
print(tp.index('google'))
print(tp.index('a'))
输出结果:
1
0
Traceback (most recent call last):
File "E:\python_100\py_100\03.py", line 4, in <module>
print(tp.index('a'))
ValueError: tuple.index(x): x not in tuple
六、Dictionary - 字典
字典也是Python中的常用类型,因为字典key的唯一性,可以按key索引,所以对于大量数据,字典的运算速度远高于列表和元组这种无序序列。
整个字典包括在花括号 {} 中,由>=0个键值对组成;每个键值对的key和value中间用冒号 : 分割;若干键值对之间用逗号(,)分割,形如:
d = {key1 : value1, key2 : value2, key3 : value3 }

6.1 字典的定义
- 字典的key需要满足两个条件:
- 必须是不可变数据类型,如字符串、数字和元组,最常用的是字符串。
- 唯一性,不能重复。
- 字典的value没有要求,可以是任意数据类型,并且可以嵌套。
- 定义空字典
dt1 = { 'abc': 456, 'abc': 789}
dt2 = { 'abc': 123, 98.6: 37, (1, 2): (1, 2) }
dt3 = {'name': 'Tom',
'sex': 'male',
'age': 18,
'likes': {1: 'study', 2: 'play'},
'address': ['Shandong', 'China']}
u4 = {}
print(dt1)
print(dt2)
print(dt3)
print(u4, type(u4))
输出结果:
{'abc': 789}
{'abc': 123, 98.6: 37, (1, 2): (1, 2)}
{'name': 'Tom', 'sex': 'male', 'age': 18, 'likes': {1: 'study', 2: 'play'}, 'address': ['Shandong', 'China']}
{} <class 'dict'>
6.2 访问字典
- 访问字典的键列表
- 访问字典的值列表
- 按键取值
dt = {'name': 'Tom',
'sex': 'male',
'age': 18,
'likes': {1: 'study', 2: 'play'},
'address': ['Shandong', 'China']}
print(dt.keys())
print(type(dt.keys()))
print(list(dt.keys()))
print('-------------')
print(dt.values())
print(type(dt.values()))
print(list(dt.values()))
print('------------')
print(dt['name'], dt['likes'])
print(dt['score'])
输出结果:
dict_keys(['name', 'sex', 'age', 'likes', 'address'])
<class 'dict_keys'>
['name', 'sex', 'age', 'likes', 'address']
-------------
dict_values(['Tom', 'male', 18, {1: 'study', 2: 'play'}, ['Shandong', 'China']])
<class 'dict_values'>
['Tom', 'male', 18, {1: 'study', 2: 'play'}, ['Shandong', 'China']]
------------
Tom {1: 'study', 2: 'play'}
Traceback (most recent call last):
File "E:\python_100\py_100\03.py", line 15, in <module>
print(dt['score'])
KeyError: 'score'
6.3 修改字典
- 新增键值对
- 按键修改值
dt = {'name': 'Tom',
'sex': 'male',
'age': 18,}
print(dt)
dt['score'] = 100
print(dt)
dt['age'] = 20
print(dt)
输出结果:
{'name': 'Tom', 'sex': 'male', 'age': 18}
{'name': 'Tom', 'sex': 'male', 'age': 18, 'score': 100}
{'name': 'Tom', 'sex': 'male', 'age': 20, 'score': 100}
6.4 删除字典
- 删除一个键值对
- 清空字典
- 删除字典变量
dt = {'name': 'Tom',
'sex': 'male',
'age': 18,}
del dt['age']
print(dt)
dt.clear()
print(dt)
del dt
print(dt)
输出结果:
{'name': 'Tom', 'sex': 'male'}
{}
Traceback (most recent call last):
File "E:\python_100\py_100\03.py", line 9, in <module>
print(dt)
NameError: name 'dt' is not defined
6.5 字典相关函数
- len(dict):返回字典元素个数(长度)
- str(dict):返回字典字符串
dt = {'name': 'Tom',
'sex': 'male',
'age': 18,}
print(len(dt))
if type(dt) == dict:
print(dt, len(dt))
if type(str(dt)) != str:
print('str(dt) 不是字符串!')
else:
print('str(dt)是字符串!')
print(str(dt), len(str(dt)))
输出结果:
3
{'name': 'Tom', 'sex': 'male', 'age': 18} 3
str(dt)是字符串!
{'name': 'Tom', 'sex': 'male', 'age': 18} 41
6.6 字典相关方法
- key in dict:成员运算
- dict.get(key):按键取值
dt = {'name': 'Tom',
'sex': 'male',
'age': 18,}
print('name' in dt)
print('score' in dt)
print(dt.get('age'))
输出结果:
True
False
18
七、Sets - 集合
集合(set)是一个无序的不重复元素序列。集合中的元素会随机排列,与输入顺序无关。
7.1 集合定义
- 非空集合用{value,…}定义,或者用set()来转换,set()仅接受一个参数
- 空集合必须用set()定义,因为{}定义的是空字典
st1 = set('abc')
print(st1)
st2 = {'abc', 456, 789}
print(st2)
st3 = { 'abc', 123, 98.6, 37, (1, 2), (1, 2) }
print(st3)
st4 = {}
print(st4, type(st4))
st5 = set('abc', 456, 789)
输出结果:
{'a', 'c', 'b'}
{456, 789, 'abc'}
{98.6, (1, 2), 37, 123, 'abc'}
{} <class 'dict'>
Traceback (most recent call last):
File "E:\python_100\py_100\03.py", line 9, in <module>
st5 = set('abc', 456, 789)
TypeError: set expected at most 1 argument, got 3
7.2 集合的常用操作
- 成员运算:in
- 并集运算:| 或 st1.union(st2)
- 交集运算:& 或 st1.intersection(st2)
- 差集运算:- 或 st1.difference(st2)
- 对称差集:^ 或 st1.symmetric_difference(st2)
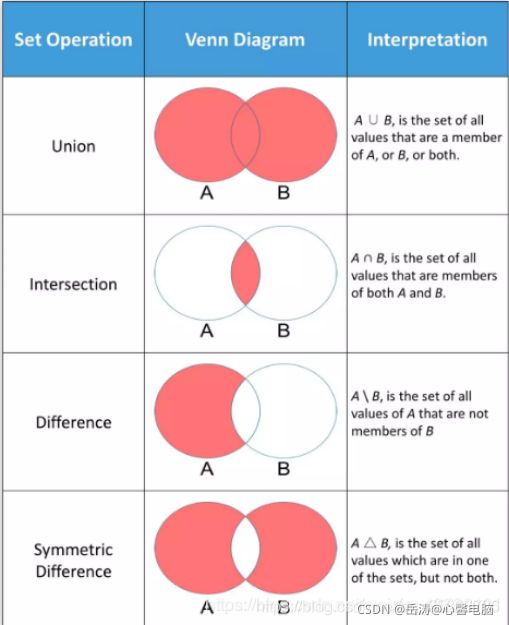
st1 = set('abcdr')
st2 = set('aclmz')
print(st1, st2)
print('并集', st1 | st2, st1.union(st2))
print('交集',st1 & st2, st1.intersection(st2))
print('差集',st1 - st2, st1.difference(st2))
print('对称差集',st1 ^ st2, st1.symmetric_difference(st2))
输出结果:
{'b', 'd', 'c', 'a', 'r'} {'c', 'a', 'l', 'z', 'm'}
并集 {'b', 'd', 'c', 'a', 'l', 'r', 'z', 'm'} {'b', 'd', 'c', 'a', 'l', 'r', 'z', 'm'}
交集 {'c', 'a'} {'c', 'a'}
差集 {'b', 'd', 'r'} {'b', 'd', 'r'}
对称差集 {'b', 'd', 'z', 'l', 'm', 'r'} {'b', 'd', 'z', 'l', 'm', 'r'}
7.4 集合的常用函数
- len(s):集合元素个数(长度)
7.4 集合的常用方法
- 添加单个元素:s.add(x),参数可以是任意数据类型
- 添加多个元素:s.update(x,…),参数可以是字符串、列表、元组、字典、集合等可迭代对象,不能是数字。会先迭代出所有底层元素,再添加。
- 移除一个元素:s.remove(x),如果元素不存在会报错
- 移除一个元素:s.discrd(x),如果元素不存在会报错,不做任何操作
- 随机移除一个元素:s.pop(),不接受任何参数
- 清空集合:s.clear()
st1 = {'abc', 456,}
st1.add('789')
print(st1)
st1.update('100', [1, 2], (8, 9), {'name': 'tom'},{'hello'})
print(st1)
st1.remove('abc')
print(st1)
st1.discard('abc')
print(st1)
st1.pop()
print(st1)
st1.clear()
print(st1)
输出结果:
{456, 'abc', '789'}
{1, 2, 456, 8, 9, 'hello', 'name', '789', '1', '0', 'abc'}
{1, 2, 456, 8, 9, 'hello', 'name', '789', '1', '0'}
{1, 2, 456, 8, 9, 'hello', 'name', '789', '1', '0'}
{2, 456, 8, 9, 'hello', 'name', '789', '1', '0'}
set()