Squeeze-and-Excitation Networks -翻译
Squeeze-and-Excitation Networks
翻译前言:由于英语阅读水平不佳以及术语掌握不完全,部分描述性语言为机翻然后修改得到,同时部分地方加了博主自己的注释(注释会删除线表明),翻译的不好见谅,本文仅供参考。
摘要—卷积神经网络(CNN)的核心模块是卷积块,它使网络能够融合每层局部感受野内的空间和通道信息构建信息特征。 大量的先前研究已经研究了这种关系的空间结构,试图通过在整个特征层次上提高空间编码的质量来增强CNN的表示能力。 在这项工作中,我们将重点放在通道关系上,并提出一个新颖的体系结构单元,我们称之为“挤压和激励”(SE)块,该模块通过显式建模通道之间的相互依赖性来自适应地重新校准通道方式的特征响应。 我们展示了模块堆叠在一起以形成的SENet架构,该架构可以非常有效地概括不同数据集。我们进一步证明,SE块用略微的额外计算成本为现有的最新CNN带来了性能上的显着改善。
挤压和激励网络构成了我们ILSVRC 2017类别提交的基础,该类别获得了第一名,并将前5名的错误减少到2.251%,相对于2016年的获胜作品有了约25%的相对改善。 有关模型和代码,请访问https://github.com/hujie-frank/SENet。
索引词—压缩和激励,图像表示,注意力,卷积神经网络。
1简介
进化神经网络(CNN)已被证明是解决各种视觉任务的有用模型[1],[2],[3],[4]。 在网络的每个卷积层,一组过滤器沿输入通道表达邻域空间连通性模式-在本地接收域内将空间和通道信息融合在一起。 通过将一系列卷积层与非线性激活函数和下采样运算符进行交织,CNN可以生成捕获分层模式并获得全局理论接收场的图像表示。 计算机视觉研究的中心主题是寻找更强大的表示形式,这些表示形式仅捕获对给定任务最重要的图像属性,从而提高性能。
作为用于视觉任务的广泛使用的模型系列,新的神经网络体系结构设计的开发现在代表了此搜索的关键领域。 最近的研究表明,可以通过将学习机制集成到网络中来增强CNN产生的表示,以帮助捕获要素之间的空间相关性。 一种这样的方法,由Inception系列体系结构[5],[6]推广,将多尺度过程合并到网络模块中以实现更高的性能。进一步的工作试图更好地对空间依赖性进行建模[7],[8],并将空间注意力纳入网络的结构[9]。
在本文中,我们研究了网络设计的另一个通道之间的关系。 我们引入了一个新的体系结构单元,我们称之为“挤压和激发”(SE)块,其目的是通过显式修改其卷积特征的通道之间的相互依赖性来提高网络产生的表示的质量。 为此,我们提出了一种机制,该机制允许网络执行特征重新校准,通过该机制,它可以学习使用全局信息来选择性地强调信息特征并抑制不太有用的特征。
SE构造块的结构如图1所示。对于任何给定的变换Ftr,将输入X映射到特征图U,其中U∈R(H×W×C),例如一个卷积,我们可以构造一个相应的SE块来执行特征重新校准。 首先将特征U传递给挤压操作,该操作通过在其空间维度(H×W)上聚合特征图来生成通道描述符。 该描述符的功能是产生对信道方式特征响应的全局分布的嵌入,从而允许来自网络全局接收域的信息被其所有层使用。 聚合之后是激励操作,该激励操作采用简单的自选通机制的形式,该机制将嵌入作为输入并产生每通道调制权重的集合。 将这些权重应用于特征图U,以生成SE块的输出,可以将其直接馈送到网络的后续层中。
这个结构可以通过简单地堆叠SE块的集合来构建SE网络(SENet)。 而且,这些SE块还可以在网络体系结构的一定深度范围内用作原始块的替代品(第6.4节)。【一个SE block,Ftr是一个转换操作,并且![]() (定义输入输出),具体U,X的值见下文】
(定义输入输出),具体U,X的值见下文】

虽然构建模块的模板是通用的,但它在不同深度执行的角色在整个网络中都不同。 在较早的层中,它以类不可知的方式激发信息功能,从而增强了共享的低级表示。 在随后的层中,SE块变得越来越专业化,并以高度特定于类的方式响应不同的输入(第7.2节)。结果,可以通过网络累积SE块执行的功能重新校准的好处。
新的CNN架构的设计和开发是一项艰巨的工程任务,通常需要选择许多新的超参数和层配置。 相比之下,SE块的结构很简单,可以通过用SE对应部件替换组件来直接在现有的最新体系结构中使用,从而可以有效地提高性能。 SE块在计算上也很轻巧,并且在模型复杂性和计算负担上仅增加了一点点。
为了提供这些主张的证据,我们开发了多个SENet,并对ImageNet数据集进行了广泛的评估[10]。 我们还提供了ImageNet以外的结果,这些结果表明我们的方法的好处并不局限于特定的数据集或任务。 通过使用SENets,我们在ILSVRC 2017分类竞赛中排名第一。 我们最好的模型集合在测试set1上达到2.251%的top-5误差。 与上一年的获奖者相比,这意味着大约25%的相对改善(前5名错误为2.991%)。
2相关工作
更深层次的体系结构。VGGNets [11]和Inception模型[5]表明,增加网络深度可以显着提高其能够学习的表示质量。 通过调节输入到每一层的分布,批量归一化(BN)[6]为深度网络中的学习过程增加了稳定性,并产生了更平滑的优化表面[12]。 在这些工作的基础上,ResNets证明了通过使用基于身份的跳过连接来学习更深入,更强大的网络是可能的[13],[14]。
Highway networks [15]引入了一种门控机制来调节沿捷径连接的信息流。
在完成这些工作之后,网络层之间的连接有了进一步的重新设计[16],[17],这表明对深层网络的学习和表示特性有希望的改进。
替代的但密切相关的研究领域集中在改善网络中包含的计算元素的功能形式的方法上。事实证明,分组卷积是增加学习变换基数的流行方法[18],[19]。 可以使用多分支卷积[5],[6],[20],[21]来实现运算符更灵活的组合,这可以看作是分组运算符的自然扩展。 在先前的工作中,跨通道相关性通常被映射为特征的新组合,从而独立于空间结构[22],[23]或通过使用具有1×1卷积的标准卷积滤波器[24]进行联合。 这项研究大部分集中在降低模型和计算复杂度的目标上,反映了一个假设,即可以将通道关系表示为具有局部接受域的实例不可知功能的组合。 相比之下,我们声称,为该单元提供一种机制,以使用全局信息显式建模通道之间的动态,非线性依存关系,可以简化学习过程,并显着增强网络的表示能力。
算法架构搜索。 除上述工作外,还有丰富的研究历史,旨在放弃手动体系结构设计,而是寻求自动学习网络的结构。这个领域的许多早期工作是在神经进化社区中进行的,该社区建立了使用进化方法搜索网络拓扑的方法[25],[26]。 进化搜索虽然经常需要计算,但取得了显著成功,其中包括为序列模型[27],[28]找到良好的存储单元,以及为大规模图像分类学习复杂的体系结构[29],[30],[31] 。 为了减轻这些方法的计算负担,基于拉马克继承[32]和可微体系结构搜索[33]提出了该方法的有效替代方案。
通过将架构搜索表述为超参数优化,可以使用随机搜索[34]和其他基于模型的更复杂的优化技术[35],[36]解决该问题。 拓扑选择作为通过可能的设计的架构的路径[37]和直接架构预测[38] [39]已被提议为其他可行的架构搜索工具。 通过强化学习[40],[41],[42],[43],[44]的技术已经获得了特别强劲的结果。 SE块可以用作这些搜索算法的原子构建块,并在并行工作中被证明在此功能上非常有效[45]。
注意和门控机制。 可以将注意力理解为将可用的计算资源的分配偏向信号的最有用的组件的一种方法。注意机制已经证明了它们在许多任务中的效用,包括序列学习,图像中的定位和理解,图像标题,和唇读。 在这些应用中,它可以作为操作员并入一个或多个层,这些层代表用于模态之间适应的高层抽象。 一些工作对空间和渠道注意力的组合使用提供了有趣的研究[58],[59]。 Wang等[58]引入了一个强大的基于沙漏(hourglass)模块[8]的躯干和面具注意机制,该机制插入深层残差网络的中间阶段之间。 相比之下,我们提出的SE块包括一个轻量级选通机制,该机制着重于通过以计算有效的方式对各个通道之间的关系进行建模来增强网络的表示能力。
3挤压和激励块
挤压和激励块是可以基于将输入X∈R(H‘×W’×C)映射到特征图U∈![]() 的变换Ftr上构建的计算单元。 在下面的符号中,我们将Ftr用作卷积,并使用V = [v1,v2,… ,vc]表示第c个卷积核,其中xc表示第c个输入。 然后,我们可以将输出写为U = [u1,u2,… ,uc]
的变换Ftr上构建的计算单元。 在下面的符号中,我们将Ftr用作卷积,并使用V = [v1,v2,… ,vc]表示第c个卷积核,其中xc表示第c个输入。 然后,我们可以将输出写为U = [u1,u2,… ,uc](U:tensor uc:大小为H*W的feature map),其中
 (1)
(1)
此处,∗表示卷积,![]() ,X = [x 1,x 2,…,x C’]和uc∈
,X = [x 1,x 2,…,x C’]和uc∈![]() 。
。![]() 是一个二维卷积核,代表作用在X对应通道上Vc的单个通道。为简化表示法,省略了bais。 由于输出是通过所有通道的求和产生的,因此通道相关性隐式嵌入vc中,但与滤波器捕获的局部空间相关性纠缠在一起。 通过卷积建模的通道关系固有地是隐式的和局部的(最顶层的通道除外)。 我们期望通过显式改变通道的相互依赖性来增强卷积特征的学习,以便网络能够提高其对信息特征的敏感性,这些特征可以被后续的转换所利用。 因此,我们希望向其提供全局信息的访问权,并在压缩和激励分两步将其反馈到下一个转换之前,以两个步骤重新校准滤波器的响应。图1示出了说明SE块的结构的图。
是一个二维卷积核,代表作用在X对应通道上Vc的单个通道。为简化表示法,省略了bais。 由于输出是通过所有通道的求和产生的,因此通道相关性隐式嵌入vc中,但与滤波器捕获的局部空间相关性纠缠在一起。 通过卷积建模的通道关系固有地是隐式的和局部的(最顶层的通道除外)。 我们期望通过显式改变通道的相互依赖性来增强卷积特征的学习,以便网络能够提高其对信息特征的敏感性,这些特征可以被后续的转换所利用。 因此,我们希望向其提供全局信息的访问权,并在压缩和激励分两步将其反馈到下一个转换之前,以两个步骤重新校准滤波器的响应。图1示出了说明SE块的结构的图。
3.1压缩:全局信息嵌入
为了解决利用通道依赖性的问题,我们首先在输出功能中考虑到每个通道的信号。 每个学习到的滤波器都使用局部接收场进行操作,因此,转换输出U的每个单元都无法利用该区域之外的上下文信息。
为了减轻这个问题,我们建议将全局空间信息压缩到一个通道中。使用全局平均池化生成按通道统计信息来实现的。形式上,统计量z∈Rc是通过将U缩小其空间尺寸H×W来生成的,因此z的第c个元素可通过以下公式计算: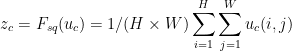 (2)
(2) (Squeeze操作得到z)
讨论。 变换U的输出可以解释为局部描述符的集合,这些描述符的统计量表示整个图像。 在现有的特征工程工作中[60],[61],[62]普遍使用这种信息。 我们选择最简单的聚合技术,即全局平均池化,并注意到这里也可以采用更多复杂的策略。
3.2激励:自适应重新校准
为了利用压缩操作中汇总的信息,我们紧随其后的是第二个操作,该操作旨在完全捕获通道方式的依存关系。 为了实现这一目标,该功能必须满足两个条件:首先,它必须具有灵活性(特别是,它必须能够学习通道之间的非线性相互作用);其次,它必须学习一个非互斥的关系,因为我们将确保允许强调多个渠道(而不是强制执行一次热激活)。为了满足这些条件,我们采用具有S型激活的简单门控机制:【W1乘以z:一个全连接层操作,s为U中C个feature map的权重】
![]() (3)
(3)
其中δ表示ReLU [63]函数, ![]() 和
和![]()
(不知道为什么除号下面那个r显示不出来)。 为了限制模型的复杂性和辅助概括,我们通过在非线性周围形成两个完全相连的(FC)层形成瓶颈层,即降压比为r的降维层【用来减少channel个数】,来对门控机制进行参数化(此参数选择将在6.1章节中讨论),然后是ReLU,然后是返回到转换输出U的通道维的维数增加层。通过sigmoid函数重新缩放U,可以得到块的最终输出:【对tensor U进行操作:uc二维矩阵,sc为权重,uc矩阵中每个值乘sc】
![]() (4)
(4)
其中 表示标量Sc与特征图Uc∈R(H×W)之间的通道方向乘法。
讨论。 激励运算符将输入的特定描述符z映射到一组信道权重。 在这方面,SE块从本质上引入了取决于输入的动态特性,可以将其视为通道上的自关注函数,这些通道的关系不限于卷积滤波器响应的局部接收场。


图2.原始Inception模块(左)和SE Inception模块(右)的模式。
图3.原始残差模块(左)和SE ResNet模块(右)的架构。(ResNet中添加SE block)
【注:图2中Inception部分对应Figure1中的Ftr操作!】
3.3实例化
SE块可以通过在每次卷积之后的非线性之后插入而集成到标准体系结构中,例如VGGNet [11]。 此外,SE块的灵活性意味着它可以直接应用于标准卷积以外的转换。 为了说明这一点,我们通过将SE块合并到一些更复杂的体系结构示例中来开发SENet,如下所述。
我们首先考虑为接收网络构建SE块[5]。 在这里,我们仅将变换Ftr当作一个完整的Inception模块(参见图2),并通过对体系结构中的每个此类模块进行此更改,就可以获得SE-Inception网络。 SE块也可以直接用于剩余网络(图3描绘了SE-ResNet模块的架构)。 在此,SE块变换Ftr被认为是残差模块的非同一性分支。 挤压和激励在与身份分支求和之前都起作用。 可以通过类似的方案来构建将SE块与ResNeXt [19],Inception-ResNet [21],MobileNet [64]和ShuffleNet [65]集成在一起的其他变体。 对于SENet体系结构的具体示例,表1中给出了SE-ResNet-50和SE-ResNeXt-50的详细说明。
SE块具有灵活性的结果之一是,有几种可行的方法可以将其集成到这些体系结构中。 因此,为了评估对用于将SE块合并到网络体系结构中的集成策略的敏感性,我们还提供了消融实验,以探索第6.5节中针对块包含的不同设计。
4模型和计算复杂性
为了使拟议的SE块设计具有实际用途,必须在改进的性能和增加的模型复杂性之间做出良好的权衡。 为了说明与模块相关的计算负担,我们以ResNet-50和SE-ResNet-50之间的比较为例。 对于224×224像素的输入图像,ResNet-50在单次向前通过中需要约3.86 GFLOPs。 每个SE块在压缩阶段使用全局平均池化操作,在激发阶段使用两个小FC层,然后进行廉价的按通道缩放操作。 总体而言,将缩减比r(在第3.2节中介绍)设置为16时,SE-ResNet-50需要约3.87 GFLOP,相当于相对于原始ResNet-50的0.26%相对增加。 为了弥补这种微小的计算负担,SE-ResNet-50的精度超过了ResNet-50的精度,实际上接近了需要约7.58 GFLOP的更深的ResNet-101网络的精度(表2)。
实际上,通过ResNet-50进行一次单程前进和后退需要190毫秒,而SE-ResNet-50则需要209毫秒,并且具有256幅图像的训练小批量(两个定时都在具有8个NVIDIA Titan X GPU的服务器上执行) 。 我们建议,这代表了合理的运行时开销,随着全局池和小的内部产品操作在流行的GPU库中得到进一步的优化,可以进一步降低此开销。 由于它对于嵌入式设备应用程序的重要性,我们进一步对每种型号的CPU推理时间进行基准测试:对于224×224像素的输入图像,ResNet-50需要164毫秒,而SE-ResNet-50则需要167毫秒。 我们认为,SE块对模型性能的贡献可以证明SE块产生的少量额外计算成本是合理的。
接下来,我们考虑提议的SE块引入的其他参数。 这些附加参数仅来自门控机制的两个FC层,因此仅占总网络容量的一小部分。 具体而言,这些FC层的权重参数引入的总数由下式给出:
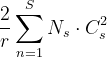 (5)
(5)
其中r表示缩小率,S表示级数(一个级表示在公共空间尺寸的特征图上操作的块的集合),Cs表示输出通道的尺寸,Ns表示 阶段s的重复块数(当在FC层中使用偏差项时,引入的参数和计算成本通常可以忽略不计)。 SE-ResNet-50在ResNet-50所需的约2500万个参数之外引入了约250万个附加参数,相当于增加了约10%。 实际上,这些参数中的大多数来自网络的最后阶段,在该阶段中,在最大数量的通道上执行激励操作。 但是,我们发现可以以很小的性能代价(相对于ImageNet,Top-5误差<0.1%)将SE块的这一成本相对较高的最后阶段删除,从而将相对参数的增加幅度降低至约4%,这可能是有用的 在参数使用是关键考虑因素的情况下(有关更多讨论,请参见第6.4和7.2节)。
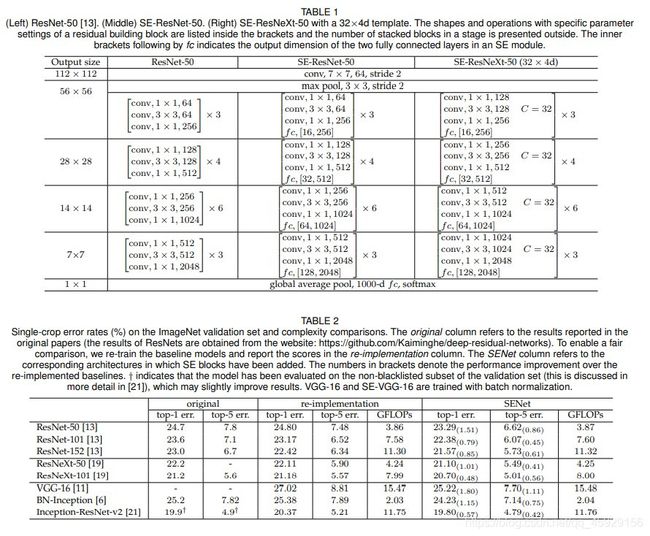
- (左)ResNet-50 [13]。 (中)SE-ResNet-50。 (右)带有32×4d模板的SE-ResNeXt-50。 括号内列出了带有剩余构建块的特定参数设置的形状和操作,并在外部显示了阶段中堆叠块的数量。 fc后面的内括号表示SE模块中两个完全连接的层的输出尺寸。
- ImageNet验证集和复杂度比较上的单次裁剪错误率(%)。 原始列指原始论文中报告的结果(ResNets的结果可从以下网站获得:https://github.com/Kaiminghe/deep-residual-networks)。 为了进行公平的比较,我们对基线模型进行了重新训练,并在重新实施列中报告了得分。 SENet列指的是已添加SE块的相应体系结构。 括号中的数字表示在重新实施的基准上的性能改进。 †表示该模型已经在验证集的非黑名单子集中进行了评估(在[21]中进行了更详细的讨论),这可能会稍微改善结果。 VGG-16和SE-VGG-16经过批量归一化训练。
5实验
在本节中,我们进行实验以研究SE块在一系列任务,数据集和模型体系结构中的有效性。
5.1图像分类
为了评估SE块的影响,我们首先对ImageNet 2012数据集[10]进行实验,该数据集包含128万个训练图像和来自1000个不同类别的50K验证图像。 我们在训练集上训练网络,并报告验证集上的top-1和top-5错误。
每个基准网络体系结构及其对应的SE对应对象都使用相同的优化方案进行训练。 我们遵循标准做法,并使用比例和宽高比[5]进行随机裁剪,将数据增强为224×224像素(对于Inception-ResNet-v2 [21]和SE-Inception-ResNet- v2)并执行随机水平翻转。 通过平均RGB通道减法对每个输入图像进行归一化。
所有模型都在我们的分布式学习系统ROCS上进行训练,该系统旨在处理大型网络的有效并行训练。使用动量0.9和最小批量大小为1024的同步SGD进行优化。初始学习率设置为0.6,每30个周期减少10倍。使用[66]中所述的权重初始化策略,从零开始训练模型100个纪元。 减速比r(在3.2节中)默认设置为16(除非另有说明)。
在评估模型时,我们应用中心裁剪,以便在将短边的大小首先调整为256的情况下从每个图像裁剪224×224像素(对于每张图像,将短边的大小首先调整为352的299×299,用于Inception-ResNet- v2和SE-Inception-ResNet-v2)。
网络深度。 我们首先将SE-ResNet与具有不同深度的ResNet架构进行比较,并在表2中报告结果。我们观察到SE块可以在不同深度上不断提高性能,而计算复杂度却极小地提高。 值得注意的是,SE-ResNet-50的单作物top-5验证误差为6.62%,超过ResNet-50(7.48%)的0.86%,接近更深层次的ResNet-101网络所实现的性能(6.52%的前5位错误)仅占总计算负担的一半(3.87 GFLOP vs. 7.58 GFLOPs)。 这种模式会在更大的深度上重复出现,其中SE-ResNet-101(6.07%top-5错误)不仅匹配,而且比更深的ResNet-152网络(6.34%top-5错误)高0.27%。 应该注意的是,SE块本身会增加深度,但是它们以极高的计算效率来实现,即使在扩展基本体系结构深度实现递减收益的点上,也能产生良好的收益。 此外,我们看到增益在一系列不同的网络深度范围内是一致的,这表明SE块引起的改进可能与通过简单增加基础架构深度获得的改进是互补的。
与现代架构的集成。
接下来,我们研究将SE块与另外两种最新的体系结构Inception-ResNet-v2 [21]和ResNeXt(使用32×4d的设置)[19]集成的效果,这两种方法都引入了额外的计算功能。 构建基础网络的基础。 我们构建了SE-Inception-ResNet-v2和SE-ResNeXt(表1中给出了SE-ResNeXt-50的配置)这些网络的SENet等效项,并在表2中报告了结果。 将SE块引入这两种体系结构可提高性能。 特别是SE-ResNeXt-50的top-5误差为5.49%,优于其直接竞争对手ResNeXt-50(5.90%的top-5误差)以及更深的ResNeXt-101(5.57%的top) -5错误),该模型的参数和计算开销几乎是总数的两倍。 我们注意到,在重新实现Inception-ResNet-v2与[21]中报告的结果之间,性能存在细微差异。
但是,我们在SE块的效果方面观察到了类似的趋势,发现SE对应项(4.79%的top-5错误)也比我们重新实现的Inception-ResNet-v2基准(5.21%的top-5错误)还要高0.42% 作为[21]中报告的结果。
通过使用VGG-16 [11]和BN-Inception体系结构[6]进行实验,我们还评估了SE块在非残留网络上运行时的效果。 为了便于从头开始训练VGG-16,我们在每次卷积后添加了“批量归一化”层。 我们对VGG-16和SE-VGG-16使用相同的训练方案。 比较的结果显示在表2中。与报告的残留基线体系结构的结果类似,我们观察到SE块在非残留设置上带来了性能上的提高。
为了提供一些关于SE块对这些模型优化的影响的见解,在图4中描述了基线体系结构运行的示例训练曲线及其各自的SE对应物。我们观察到SE块在整个优化过程中均产生了稳定的改进。 安装程序。 而且,这种趋势在被视为基准的一系列网络体系结构中是相当一致的。
移动设置。 最后,我们从移动优化网络的类别中考虑两种具有代表性的体系结构,即MobileNet [64]和ShuffleNet [65]。 对于这些实验,我们使用的最小批处理大小为256,而积极的数据扩充和正则化则稍差于[65]。 我们使用SGD在动量(设置为0.9)和初始学习率0.1的情况下在8个GPU上训练了模型,每次验证损失趋于平稳时,其初始学习率降低了10倍。 整个培训过程需要约400个周期(使我们能够重现[65]的基准绩效)。 表3中报告的结果表明,SE块以最小的计算成本来不断提高精度。
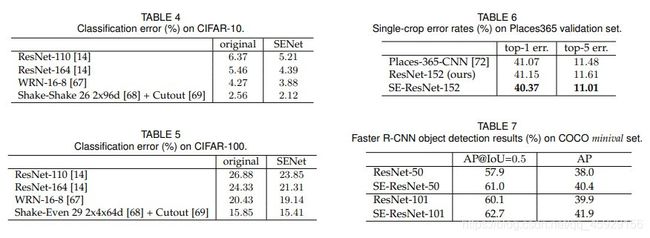
其他数据集。 接下来,我们研究SE块的优势是否可以推广到ImageNet以外的数据集。 我们使用几种流行的基准架构和技术(ResNet-110 [14],ResNet-164 [14],WideResNet-16-8 [67],Shake-Shake [68]和Cutout [69])进行实验。 CIFAR-10和CIFAR-100数据集[70]。 这些包括50k训练和10k测试的32×32像素RGB图像的集合,分别用10和100类标记。 SE块集成到这些网络中的方式与第3.3节中所述的方法相同。 每个基线及其对应的SENet都使用标准的数据增强策略进行了培训[24],[71]。 在训练期间,在随机进行32×32裁切之前,将图像随机水平翻转并在每一侧用四个像素进行零填充。还应用了均值和标准差归一化。训练超参数的设置(例如小批量大小,初始学习率,权重下降)与原始论文建议的设置相匹配。 我们观察到,在每个比较中,SENet的性能都优于基线体系结构,这表明SE块的好处并不局限于ImageNet数据集。
5.2场景分类
我们还对Places365-Challenge数据集[73]进行了实验,以进行场景分类。 该数据集包含800万个训练图像和365个类别中的36、500个验证图像。 相对于分类,场景理解的任务为模型的良好概括和处理抽象的能力提供了另一种评估方法。因为它通常要求模型处理更复杂的数据关联,并且对于更大程度的外观变化具有鲁棒性。
我们选择使用ResNet-152作为评估SE区块有效性的强大基准,并遵循[72],[74]中所述的训练和评估协议。 在这些实验中,模型是从头开始训练的。 我们将结果报告在表6中,并与先前的工作进行了比较。 我们观察到SE-ResNet-152(11.01%的top-5误差)提供了证据,表明SE块也可以改善场景分类。 该SENet超越了以前的最新模型Places-365-CNN [72],该模型在此任务上的前5个误差为11.48%。
5.3关于COCO的对象检测
我们进一步使用COCO数据集评估SE块在对象检测任务上的一般化[75]。 与以前的工作[19]一样,我们使用最小协议,即在80k训练集和35k val子集的联合上训练模型,并对剩余的5k val子集进行评估。 权重由ImageNet数据集上训练的模型的参数初始化。 我们使用Faster R-CNN [4]检测框架作为评估模型的基础,并遵循[76]中描述的超参数设置(即,采用“ 2x”学习时间表进行端到端训练)。 我们的目标是评估用SE-ResNet替换对象检测器中的中继体系结构(ResNet)的效果,以便性能的任何变化都可以归因于更好的表示形式。
表7报告了使用ResNet-50,ResNet-101及其SE对应物作为中继线体系结构的对象检测器的验证集性能。 在COCO的标准AP指标上,SE-ResNet-50优于ResNet-50 2.4%(相对6.3%的改善),在AP@IoU=0.5时,SE-ResNet-50优于ResNet-50。 SE块还受益于更深的ResNet-101体系结构,在AP指标上实现了2.0%的提高(相对于5.0%的相对改进)。 总之,这组实验证明了SE嵌段的通用性。 可以在广泛的体系结构,任务和数据集上实现改进。
5.4 ILSVRC 2017年分类竞赛
SENets为我们向ILSVRC竞赛提交的作品奠定了基础,在那里我们获得了第一名。 我们的获奖作品包括一个小型的SENet,它采用了标准的多尺度和多作物融合策略,在测试集上获得了2.251%的top-5误差。
作为本次提交的一部分,我们通过将SE块与修改后的ResNeXt [19]集成在一起,构建了一个附加模型SENet-154(该体系结构的详细信息在附录中提供)。 我们将该模型与使用标准作物尺寸(224×224和320×320)在表8中对ImageNet验证集的先前工作进行了比较。 我们观察到,使用224×224中心作物评估,SENet-154的top-1误差达到18.68%,top-5误差达到4.47%,这代表了最强的报告结果。
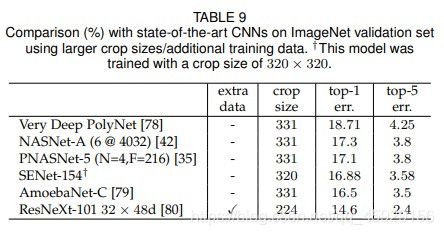
迎接挑战之后,ImageNet基准有了很多进一步的进步。 对于比较,我们在表9中包含了我们目前知道的最强结果。[79]最近仅使用ImageNet数据报告了最佳性能。 这种方法使用强化学习来为培训期间的数据扩充制定新的策略,以提高[31]搜索的架构的性能。 [80]使用ResNeXt-101 32×48d架构报告了最佳的整体性能。 这是通过在大约十亿个弱标签图像上预训练他们的模型并在ImageNet上进行微调来实现的。 通过更复杂的数据增强[79]和广泛的预训练[80]所产生的改进可能是我们对网络体系结构提出的更改的补充。

6消融实验
在本节中,我们进行消融实验,以更好地理解在SE块的组件上使用不同配置的效果。 所有烧蚀实验均在一台机器(具有8个GPU)上在ImageNet数据集上执行。 ResNet-50被用作骨干架构。 从经验上我们发现,在ResNet架构上,在激励操作中消除FC层的偏差有助于对通道相关性进行建模,并在以下实验中使用此配置。 数据扩充策略遵循第5.1节中描述的方法。 为了让我们研究每种变体的性能上限,将学习率初始化为0.1,并继续训练直到验证损失平稳2(总共约300个epochs)。 然后将学习率降低10倍,然后重复此过程(总共3次)。 训练期间使用标签平滑正则化[20]。
6.1减速比
Eqn中引入的减速比r。 5是一个超参数,它使我们能够改变网络中SE块的容量和计算成本。 为了研究此超参数介导的性能与计算成本之间的平衡,我们使用SE-ResNet-50对一系列不同的r值进行了实验。 表10中的比较表明,该性能对于一定范围的减速比具有鲁棒性。 增加的复杂度不会单调地提高性能,而较小的比率会极大地增加模型的参数大小。 设置r = 16可以在精度和复杂度之间达到良好的平衡。 实际上,在整个网络中使用相同的比率可能不是最佳的(由于不同层执行的角色不同),因此可以通过调整比率以满足给定基础体系结构的需求来实现进一步的改进。
6.2挤压运算符
我们研究了使用全局平均池而不是全局最大池作为挤压运算符的选择的重要(因为这很好用,所以我们没有考虑更复杂的替代方法)。结果报告在表11中。虽然最大合并和平均合并均有效,但平均合并的性能稍好一些,这证明了将其选择为挤压操作的基础。但是,我们注意到SE块的性能对于选择特定的聚合运算符而言相当可靠。
6.3励磁算子
我们接下来评估励磁机制的非线性选择。 我们考虑了另外两个选择:ReLU和tanh,并尝试用这些替代性非线性代替S形。 结果报告在表12中。我们看到,将S型交换为tanh会稍微降低性能,而使用ReLU会大大降低性能,实际上会导致SE-ResNet-50的性能下降到ResNet-50基线以下 。 这表明为了使SE块有效,精心构造激励算子非常重要。
2.作为参考,使用270个固定时期的时间表进行培训(降低125、200和250个时期的学习率),ResNet-50和SE-ResNet-50的top-1和top-5错误率达(23.21%, 6.53%)和(22.20%,6.00%)
6.4不同阶段
通过将SE块一次集成到ResNet-50中,我们探索了SE块在不同阶段的影响。
具体来说,我们将SE块添加到中间阶段:第2阶段,第3阶段和第4阶段,并在表13中报告结果。我们观察到,在体系结构的这些阶段中的每一个阶段引入SE块都会带来性能优势。
此外,从不同意义上讲,SE块在不同阶段产生的增益是互补的,因为它们可以有效地组合在一起以进一步增强网络性能。
6.5集成策略
最后,我们进行消融研究,以评估将SE模块集成到现有架构中时其位置的影响。 除了建议的SE设计之外,我们还考虑三种变体:
(1)SE-PRE块,其中SE块移动到残差单元之前;
(2)SE-POST块,其中SE单元在与标识分支求和之后(在ReLU之后)移动;
(3)SE-Identity块,其中SE单元与ID并行地放置在标识连接上 剩余单位。
这些变体如图5所示,每种变体的性能列于表14。我们观察到SE-PRE,SE-Identity和建议的SE块的性能相似,而SE-POST块的使用会导致性能下降。 该实验表明,如果SE单元在分支聚合之前应用,则SE单元所产生的性能改进对其位置是相当可靠的。
在上面的实验中,每个SE块都放置在残差单元的结构外部。 我们还构造了一种设计变体,将SE块移动到剩余单元内,将其直接放置在3×3卷积层之后。 由于3×3卷积层具有较少的通道,因此相应的SE块引入的参数数量也减少了。 表15中的比较表明,与标准SE块相比,SE 3×3变体以较少的参数实现了可比的分类精度。 尽管这超出了这项工作的范围,但我们预计通过针对特定架构量身定制SE块使用,可以进一步提高效率。
7 SE块的作用
尽管已证明拟议的SE块可改善多种视觉任务的网络性能,但我们也想了解挤压操作的相对重要性以及激励机制在实践中的工作方式。 对深度神经网络学习到的表示进行严格的理论分析仍然具有挑战性,因此,我们采用一种经验方法来检查SE块所起的作用,以期至少对它的实际功能有一个初步的了解。
7.1挤压的效果
为了评估挤压操作产生的全局嵌入是否对性能起重要作用,我们尝试了SE块的变体,该变体添加了相同数量的参数,但不执行全局平均池化。 具体来说,我们删除池化操作,并在激励算子(即NoSqueeze)中将两个FC层替换为具有相同通道尺寸的相应1×1卷积,其中激励输出将空间尺寸保持为输入。与SE块相反,这些逐点卷积只能根据本地运算符的输出来重新映射通道。

图5.消融研究中探讨的SE块集成设计。

图6.激励操作员在ImageNet上SE-ResNet-50中不同深度引起的激活。 每个激活集均根据以下方案命名:SE_stageID_blockID。 除了SE_5_2处的异常行为之外,随着深度的增加,激活变得越来越特定于类。
在实践中,深层网络的后续层通常将具有(理论上的)全局接受域,而NoSqueeze变体中的全局嵌入不再可以在整个网络中直接访问。
表16中将这两个模型的准确性和计算复杂性与标准ResNet-50模型进行了比较。我们观察到,全局信息的使用对模型性能具有重大影响,强调了挤压操作的重要性。 此外,与NoSqueeze设计相比,SE块允许以计算上的简化方式使用此全局信息。
7.2激励的作用
为了更清楚地了解SE块中激励算子的功能,在本节中,我们研究来自SE-ResNet-50模型的示例激活,并检查它们在不同类别和不同输入图像下的分布情况。 网络的深度。 尤其是,我们想了解激发在不同类别的图像之间以及类别内的图像之间如何变化。我们首先考虑不同类别的激励分布。 具体来说,我们从ImageNet数据集中采样了四个表现出语义和外观差异的类,即金鱼,哈巴狗,平面和悬崖(这些类的示例图像在附录中显示)。 然后,我们从验证集中为每个类别抽取五十个样本,并在每个阶段的最后一个SE块中(紧接在降采样之前)计算五十个均匀采样通道的平均激活,并在图6中绘制它们的分布图。作为参考,我们还绘制了所有1000个类别中平均激活的分布。
关于激励操作的作用,我们进行了以下三个观察。 首先,不同类别的分布在网络的较早层(例如网络)非常相似。 SE_2_3.这表明功能通道的重要性很可能在早期由不同类别的人共享。 第二个观察结果是,在更大的深度上,每个通道的值变得更加特定于类,因为不同的类对特征的判别值表现出不同的偏好,例如, SE_4_6和SE_5_1.这些观察结果与以前的工作[81],[82]中的发现一致,即,较早的图层特征通常更通用(例如,在分类任务中与类无关),而较晚的图层特征 表现出更高的特异性[83]。
接下来,我们在网络的最后阶段观察到某种不同的现象。 SE_5_2表现出一种有趣的趋向饱和状态的趋势,在该状态中,大多数激活都接近一个。 在所有激活取值为1的点上,SE块简化为身份运算符。 在SE_5_3的网络末端(紧随其后的是全局池,然后是分类器),在不同的类上出现了类似的模式,规模的变化不大(可以由分类器进行调整)。 这表明SE_5_2和SE_5_3在为网络提供重新校准方面不如以前的模块重要。 该发现与第4节中的经验研究结果一致,该结果表明,通过删除最后一个阶段的SE块,仅会降低性能,可以显着减少额外的参数数量。
最后,我们在图7中显示了同一类别中两个样本类别(金鱼和平面)的图像实例的激活的平均值和标准偏差。我们观察到了与类别间可视化一致的趋势,表明动态行为 SE块的数量在类和类中的实例之间都不同。 尤其是在网络的较后一层中,考虑到单个类中的表示能力具有多样性,网络会学习利用特征重新校准来提高其区分性能[84]。 总而言之,SE块会产生特定于实例的响应,这些响应仍可在架构的不同层上支持模型日益增长的特定于类的需求。

图7. SE-ResNet-50的不同模块中的励磁引起的激活,这些模块来自ImageNet的金鱼和平面类的图像样本。 该模块名为“ SE_stageID_blockID”。
8结论
在本文中,我们提出了SE模块,这是一种架构单元,旨在通过使其能够执行动态通道特征重新校准来提高网络的表示能力。 大量的实验表明SENet的有效性,它可以跨多个数据集和任务实现最先进的性能。 此外,SE块还说明了以前的体系结构无法对通道方式的功能依赖关系进行充分建模。 我们希望这种见解对其他需要强大区分功能的任务可能有用。 最后,由SE块产生的特征重要性值可能会用于其他任务,例如用于模型压缩的网络修剪。
致谢作者
要感谢Momenta的Li Chao和Wang Guangyuan在培训系统优化和CIFAR数据集实验方面所做的贡献。 我们还要感谢Andrew Zisserman,Aravindh Ma hendran和Andrea Vedaldi进行的许多有益的讨论。
国家自然科学基金资助(61632003,61620106003,61672502,61571439),中国国家重点研发计划(2017YFB1002701)和澳门FDCT资助(068/2015 / A2)部分支持这项工作。 Samuel Albanie得到EPSRC AIMS CDT EP / L015897 / 1的支持。
附录:SENET-154的详细信息
SENet-154是通过将SE块合并到64×4d ResNeXt-152的修改版本中而构造的,该版本通过采用ResNet-152的块堆叠策略扩展了原始的ResNeXt-101 [19]。 [13]。 除使用SE块之外,此模型的设计和训练的其他区别如下:(a)每个瓶颈构建块的前1×1卷积通道数减少了一半,以减少模型的计算成本 并以最小的性能降低。 (b)将第一个7×7卷积层替换为三个连续的3×3卷积层。 (c)用步长为2的卷积的1×1下采样投影替换为步长为2的3×3的卷积以保留信息。 (d)在分类层之前插入一个滤除层(滤除率为0.2),以减少过度拟合。 (e)在训练过程中使用标签平滑规则化(如[20]中介绍的那样)。 (f)在最后几个训练时期中冻结所有BN层的参数,以确保训练和测试之间的一致性。 (g)并行使用8台服务器(64个GPU)进行了培训,以实现大批量(2048)。 初始学习率设置为1.0。
参考:
REFERENCES [1] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” in Conference on Neural Information Processing Systems, 2012.
[2] A. Toshev and C. Szegedy, “DeepPose: Human pose estimation via deep neural networks,” in CVPR, 2014.
[3] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in CVPR, 2015.
[4] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Conference on Neural Information Processing Systems, 2015.
[5] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in CVPR, 2015.
[6] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in ICML, 2015.
[7] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick, “Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks,” in CVPR, 2016.
[8] A. Newell, K. Yang, and J. Deng, “Stacked hourglass networks for human pose estimation,” in ECCV, 2016. [9] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu, “Spatial transformer networks,” in Conference on Neural Information Processing Systems, 2015.
[10] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei, “ImageNet large scale visual recognition challenge,” International Journal of Computer Vision, 2015.
[11] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in ICLR, 2015.
[12] S. Santurkar, D. Tsipras, A. Ilyas, and A. Madry, “How does batch normalization help optimization? (no, it is not about internal covariate shift),” in Conference on Neural Information Processing Systems, 2018.
[13] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016.
[14] K. He, X. Zhang, S. Ren, and J. Sun, “Identity mappings in deep residual networks,” in ECCV, 2016.
[15] R. K. Srivastava, K. Greff, and J. Schmidhuber, “Training very deep networks,” in Conference on Neural Information Processing Systems, 2015.
[16] Y. Chen, J. Li, H. Xiao, X. Jin, S. Yan, and J. Feng, “Dual path networks,” in Conference on Neural Information Processing Systems, 2017.
[17] G. Huang, Z. Liu, K. Q. Weinberger, and L. Maaten, “Densely connected convolutional networks,” in CVPR, 2017.
[18] Y. Ioannou, D. Robertson, R. Cipolla, and A. Criminisi, “Deep roots: Improving CNN efficiency with hierarchical filter groups,” in CVPR, 2017.
[19] S. Xie, R. Girshick, P. Dollar, Z. Tu, and K. He, “Aggregated ´ residual transformations for deep neural networks,” in CVPR, 2017.
[20] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in CVPR, 2016.
[21] C. Szegedy, S. Ioffe, V. Vanhoucke, and A. Alemi, “Inceptionv4, inception-resnet and the impact of residual connections on learning,” in AAAI Conference on Artificial Intelligence, 2016.
[22] M. Jaderberg, A. Vedaldi, and A. Zisserman, “Speeding up convolutional neural networks with low rank expansions,” in BMVC, 2014.
[23] F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” in CVPR, 2017.
[24] M. Lin, Q. Chen, and S. Yan, “Network in network,” in ICLR, 2014.
[25] G. F. Miller, P. M. Todd, and S. U. Hegde, “Designing neural networks using genetic algorithms.” in ICGA, 1989.
[26] K. O. Stanley and R. Miikkulainen, “Evolving neural networks through augmenting topologies,” Evolutionary computation, 2002.
[27] J. Bayer, D. Wierstra, J. Togelius, and J. Schmidhuber, “Evolving memory cell structures for sequence learning,” in ICANN, 2009.
[28] R. Jozefowicz, W. Zaremba, and I. Sutskever, “An empirical exploration of recurrent network architectures,” in ICML, 2015.
[29] L. Xie and A. L. Yuille, “Genetic CNN,” in ICCV, 2017.
[30] E. Real, S. Moore, A. Selle, S. Saxena, Y. L. Suematsu, J. Tan, Q. Le, and A. Kurakin, “Large-scale evolution of image classifiers,” in ICML, 2017.
[31] E. Real, A. Aggarwal, Y. Huang, and Q. V. Le, “Regularized evolution for image classifier architecture search,” arXiv preprint arXiv:1802.01548, 2018.
[32] T. Elsken, J. H. Metzen, and F. Hutter, “Efficient multi-objective neural architecture search via lamarckian evolution,” arXiv preprint arXiv:1804.09081, 2018.
[33] H. Liu, K. Simonyan, and Y. Yang, “DARTS: Differentiable architecture search,” arXiv preprint arXiv:1806.09055, 2018.
[34] J. Bergstra and Y. Bengio, “Random search for hyper-parameter optimization,” JMLR, 2012.
[35] C. Liu, B. Zoph, J. Shlens, W. Hua, L.-J. Li, L. Fei-Fei, A. Yuille, J. Huang, and K. Murphy, “Progressive neural architecture search,” in ECCV, 2018.
[36] R. Negrinho and G. Gordon, “Deeparchitect: Automatically designing and training deep architectures,” arXiv preprint arXiv:1704.08792, 2017.
[37] S. Saxena and J. Verbeek, “Convolutional neural fabrics,” in Conference on Neural Information Processing Systems, 2016.
[38] A. Brock, T. Lim, J. M. Ritchie, and N. Weston, “SMASH: one-shot model architecture search through hypernetworks,” in ICLR, 2018.
[39] B. Baker, O. Gupta, R. Raskar, and N. Naik, “Accelerating neural architecture search using performance prediction,” in ICLR Workshop, 2018.
[40] B. Baker, O. Gupta, N. Naik, and R. Raskar, “Designing neural network architectures using reinforcement learning,” in ICLR, 2017.
[41] B. Zoph and Q. V. Le, “Neural architecture search with reinforce[1]ment learning,” in ICLR, 2017.
[42] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, “Learning transfer[1]able architectures for scalable image recognition,” in CVPR, 2018.
[43] H. Liu, K. Simonyan, O. Vinyals, C. Fernando, and K. Kavukcuoglu, “Hierarchical representations for efficient architecture search,” in ICLR, 2018.
[44] H. Pham, M. Y. Guan, B. Zoph, Q. V. Le, and J. Dean, “Efficient neural architecture search via parameter sharing,” in ICML, 2018.
[45] M. Tan, B. Chen, R. Pang, V. Vasudevan, and Q. V. Le, “Mnas[1]net: Platform-aware neural architecture search for mobile,” arXiv preprint arXiv:1807.11626, 2018.13
[46] B. A. Olshausen, C. H. Anderson, and D. C. V. Essen, “A neurobio[1]logical model of visual attention and invariant pattern recognition based on dynamic routing of information,” Journal of Neuroscience, 1993.
[47] L. Itti, C. Koch, and E. Niebur, “A model of saliency-based visual attention for rapid scene analysis,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998.
[48] L. Itti and C. Koch, “Computational modelling of visual attention,” Nature reviews neuroscience, 2001.
[49] H. Larochelle and G. E. Hinton, “Learning to combine foveal glimpses with a third-order boltzmann machine,” in Conference on Neural Information Processing Systems, 2010.
[50] V. Mnih, N. Heess, A. Graves, and K. Kavukcuoglu, “Recurrent models of visual attention,” in Conference on Neural Information Processing Systems, 2014.
[51] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Conference on Neural Information Processing Systems, 2017.
[52] T. Bluche, “Joint line segmentation and transcription for end-to[1]end handwritten paragraph recognition,” in Conference on Neural Information Processing Systems, 2016.
[53] A. Miech, I. Laptev, and J. Sivic, “Learnable pooling with context gating for video classification,” arXiv:1706.06905, 2017.
[54] C. Cao, X. Liu, Y. Yang, Y. Yu, J. Wang, Z. Wang, Y. Huang, L. Wang, C. Huang, W. Xu, D. Ramanan, and T. S. Huang, “Look and think twice: Capturing top-down visual attention with feedback convolutional neural networks,” in ICCV, 2015.
[55] K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y. Bengio, “Show, attend and tell: Neural image caption generation with visual attention,” in ICML, 2015.
[56] L. Chen, H. Zhang, J. Xiao, L. Nie, J. Shao, W. Liu, and T. Chua, “SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning,” in CVPR, 2017.
[57] J. S. Chung, A. Senior, O. Vinyals, and A. Zisserman, “Lip reading sentences in the wild,” in CVPR, 2017.
[58] F. Wang, M. Jiang, C. Qian, S. Yang, C. Li, H. Zhang, X. Wang, and X. Tang, “Residual attention network for image classification,” in CVPR, 2017.
[59] S. Woo, J. Park, J.-Y. Lee, and I. S. Kweon, “CBAM: Convolutional block attention module,” in ECCV, 2018.
[60] J. Yang, K. Yu, Y. Gong, and T. Huang, “Linear spatial pyramid matching using sparse coding for image classification,” in CVPR, 2009.
[61] J. Sanchez, F. Perronnin, T. Mensink, and J. Verbeek, “Image classi[1]fication with the fisher vector: Theory and practice,” International Journal of Computer Vision, 2013.
[62] L. Shen, G. Sun, Q. Huang, S. Wang, Z. Lin, and E. Wu, “Multi[1]level discriminative dictionary learning with application to large scale image classification,” IEEE TIP, 2015.
[63] V. Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” in ICML, 2010.
[64] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “MobileNets: Efficient convolutional neural networks for mobile vision applications,” arXiv:1704.04861, 2017.
[65] X. Zhang, X. Zhou, M. Lin, and J. Sun, “ShuffleNet: An extremely efficient convolutional neural network for mobile devices,” in CVPR, 2018.
[66] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification,” in ICCV, 2015.
[67] S. Zagoruyko and N. Komodakis, “Wide residual networks,” in BMVC, 2016.
[68] X. Gastaldi, “Shake-shake regularization,” arXiv preprint arXiv:1705.07485, 2017.
[69] T. DeVries and G. W. Taylor, “Improved regularization of convolutional neural networks with cutout,” arXiv preprint arXiv:1708.04552, 2017.
[70] A. Krizhevsky and G. Hinton, “Learning multiple layers of fea[1]tures from tiny images,” Citeseer, Tech. Rep., 2009.
[71] G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Q. Weinberger, “Deep networks with stochastic depth,” in ECCV, 2016.
[72] L. Shen, Z. Lin, G. Sun, and J. Hu, “Places401 and places365 mod[1]els,” https://github.com/lishen-shirley/Places2-CNNs, 2016.
[73] B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, “Places: A 10 million image database for scene recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
[74] L. Shen, Z. Lin, and Q. Huang, “Relay backpropagation for effec[1]tive learning of deep convolutional neural networks,” in ECCV, 2016.
[75] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, and C. L. Zitnick, “Microsoft COCO: Common objects in ´ context,” in ECCV, 2014.
[76] R. Girshick, I. Radosavovic, G. Gkioxari, P. Dollar, and K. He, “De- ´ tectron,” https://github.com/facebookresearch/detectron, 2018.
[77] D. Han, J. Kim, and J. Kim, “Deep pyramidal residual networks,” in CVPR, 2017.
[78] X. Zhang, Z. Li, C. C. Loy, and D. Lin, “Polynet: A pursuit of structural diversity in very deep networks,” in CVPR, 2017.
[79] E. D. Cubuk, B. Zoph, D. Mane, V. Vasudevan, and Q. V. Le, “Autoaugment: Learning augmentation policies from data,” arXiv preprint arXiv:1805.09501, 2018.
[80] D. Mahajan, R. Girshick, V. Ramanathan, K. He, M. Paluri, Y. Li, A. Bharambe, and L. van der Maaten, “Exploring the limits of weakly supervised pretraining,” in ECCV, 2018.
[81] H. Lee, R. Grosse, R. Ranganath, and A. Y. Ng, “Convolutional deep belief networks for scalable unsupervised learning of hierar[1]chical representations,” in ICML, 2009.
[82] J. Yosinski, J. Clune, Y. Bengio, and H. Lipson, “How transferable are features in deep neural networks?” in Conference on Neural Information Processing Systems, 2014.
[83] A. S. Morcos, D. G. Barrett, N. C. Rabinowitz, and M. Botvinick, “On the importance of single directions for generalization,” in ICLR, 2018.
[84] J. Hu, L. Shen, S. Albanie, G. Sun, and A. Vedaldi, “Gather-excite: Exploiting feature context in convolutional neural networks,” in Conference on Neural Information Processing Systems, 2018