(笔记)yolov5训练自己数据集
一、环境
代码版本:yolov5-5
Pytorch:1.9.0
Cuda:10.2
Python:3.8
通过pip install -r requirements.txt安装依赖包。
二、准备自己的数据集(VOC)
第一步
创建Mydata文件夹,里面要包含三个文件夹,
Annotations里面放我们的标签文件xml,
images里面放标签文件所对应的图片,
ImageSets文件夹下面有个Main子文件夹,其下面存放训练集、验证集、测试集的划分,通过脚本生成,可以在根目录下创建一个makeTXT.py文件,代码内容如下:
import os
import random
trainval_percent = 1
train_percent = 0.9
xmlfilepath = 'Mydata2/Annotations'
txtsavepath = 'Mydata2/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('Mydata2/ImageSets/trainval.txt', 'w')
ftest = open('Mydata2/ImageSets/test.txt', 'w')
ftrain = open('Mydata2/ImageSets/train.txt', 'w')
fval = open('Mydata2/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
生成如下四个txt文件:
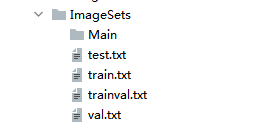
这样就完成了数据集的划分,其中百分之90作为训练集,百分之10作为验证集,在这里我没有进行测试集的划分,我最后单独设置一个测试集文件夹进行测试。
第二步
接下来开始弄labels,也就是将xml文件转换为我们需要的yolo格式的标签文件
这就是yolo格式的标签文件

在根目录下创建VOC_labels.py,代码如下:
# xml解析包
import xml.etree.ElementTree as ET
import pickle
import os
# os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ['person','cat','dog']
# 进行归一化操作
def convert(size, box): # size:(原图w,原图h) , box:(xmin,xmax,ymin,ymax)
if size[0] != 0 or size[1] != 0:
dw = 1./size[0] # 1/w
dh = 1./size[1] # 1/h
else:
dw = 0
dh = 0
x = (box[0] + box[1])/2.0 # 物体在图中的中心点x坐标
y = (box[2] + box[3])/2.0 # 物体在图中的中心点y坐标
w = box[1] - box[0] # 物体实际像素宽度
h = box[3] - box[2] # 物体实际像素高度
x = x*dw # 物体中心点x的坐标比(相当于 x/原图w)
w = w*dw # 物体宽度的宽度比(相当于 w/原图w)
y = y*dh # 物体中心点y的坐标比(相当于 y/原图h)
h = h*dh # 物体宽度的宽度比(相当于 h/原图h)
return (x, y, w, h) # 返回 相对于原图的物体中心点的x坐标比,y坐标比,宽度比,高度比,取值范围[0-1]
# year ='2012', 对应图片的id(文件名)
def convert_annotation(image_id):
'''
将对应文件名的xml文件转化为label文件,xml文件包含了对应的bunding框以及图片长款大小等信息,
通过对其解析,然后进行归一化最终读到label文件中去,也就是说
一张图片文件对应一个xml文件,然后通过解析和归一化,能够将对应的信息保存到唯一一个label文件中去
labal文件中的格式:calss x y w h 同时,一张图片对应的类别有多个,所以对应的bunding的信息也有多个
'''
# 对应的通过year 找到相应的文件夹,并且打开相应image_id的xml文件,其对应bund文件
in_file = open('Mydata2/Annotations/%s.xml' % (image_id), encoding='utf-8')
# 准备在对应的image_id 中写入对应的label,分别为
#
out_file = open('Mydata2/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
# 解析xml文件
tree = ET.parse(in_file)
# 获得对应的键值对
root = tree.getroot()
# 获得图片的尺寸大小
size = root.find('size')
# 如果xml内的标记为空,增加判断条件
if size != None:
# 获得宽
w = int(size.find('width').text)
# 获得高
h = int(size.find('height').text)
# 遍历目标obj
for obj in root.iter('object'):
# 获得difficult ??
difficult = obj.find('difficult').text
# 获得类别 =string 类型
cls = obj.find('name').text
# 如果类别不是对应在我们预定好的class文件中,或difficult==1则跳过
if cls not in classes or int(difficult) == 1:
continue
# 通过类别名称找到id
cls_id = classes.index(cls)
# 找到bndbox 对象
xmlbox = obj.find('bndbox')
# 获取对应的bndbox的数组 = ['xmin','xmax','ymin','ymax']
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
print(image_id, cls, b)
# 带入进行归一化操作
# w = 宽, h = 高, b= bndbox的数组 = ['xmin','xmax','ymin','ymax']
bb = convert((w, h), b)
# bb 对应的是归一化后的(x,y,w,h)
# 生成 calss x y w h 在label文件中
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# 返回当前工作目录
wd = getcwd()
print(wd)
for image_set in sets:
'''
对所有的文件数据集进行遍历
做了两个工作:
1.将所有图片文件都遍历一遍,并且将其所有的全路径都写在对应的txt文件中去,方便定位
2.同时对所有的图片文件进行解析和转化,将其对应的bundingbox 以及类别的信息全部解析写到label 文件中去
最后再通过直接读取文件,就能找到对应的label 信息
'''
# 先找labels文件夹如果不存在则创建
if not os.path.exists('Mydata2/labels/'):
os.makedirs('Mydata2/labels/')
# 读取在ImageSets/Main 中的train、test..等文件的内容
# 包含对应的文件名称
image_ids = open('Mydata2/ImageSets/%s.txt' % (image_set)).read().strip().split()
# 打开对应的2012_train.txt 文件对其进行写入准备
list_file = open('Mydata2/%s.txt' % (image_set), 'w')
# 将对应的文件_id以及全路径写进去并换行
for image_id in image_ids:
list_file.write('Mydata2/images/%s.jpg\n' % (image_id))
# 调用 year = 年份 image_id = 对应的文件名_id
convert_annotation(image_id)
# 关闭文件
list_file.close()
# os.system(‘comand’) 会执行括号中的命令,如果命令成功执行,这条语句返回0,否则返回1
# os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
# os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
这个代码的原始代码是我用别人的,不过我一直会报错
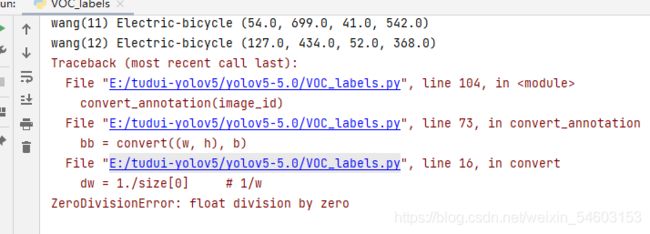
原因是标签文件中有某几个中的w、h是0,所以报错,于是我加上了
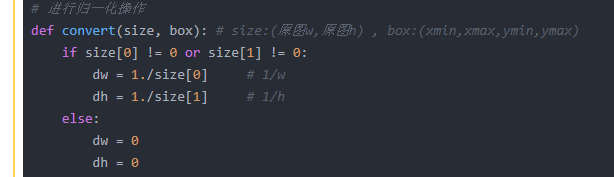
这样就解决了报错
经过运行代码我们生成了以下几个文件
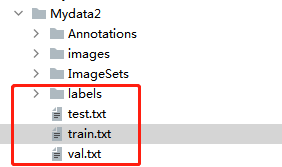
其中labels中就是所有的yolo格式的标签文件,test.txt、train.txt、val.txt是对应图片的位置。
通过以上步骤我们的数据集就建立完成。
三、配置参数
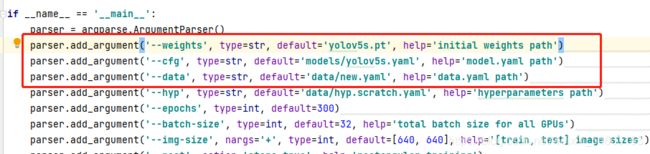 刚开始学习训练步骤主要是设置我画框的三个参数
刚开始学习训练步骤主要是设置我画框的三个参数
首先是选择预训练模型,也就是迁移学习的道理,在原作者已经训练好的模型的基础上再进行对我们的数据集训练,已达到更好的效果,在default=' '中填入我们所选择的模型,我这里选择的是yolov5s.pt
其次是设置预训练模型的参数,因为我们选择的是yolov5s.pt模型,所以要修改yolov5s.yaml文件,并在default=' '中选择它的路径。
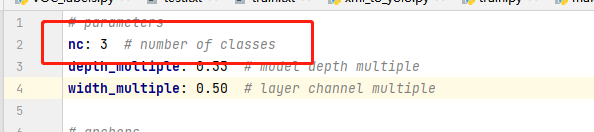
这里原本是80,因为我要训练的模型共有三个分类,所以这里就改为3即可。
最后在yolov5目录下的data文件夹下新建一个new.yaml文件(可以自定义命名),这个yaml文件用来存放训练集和验证集的划分文件(train.txt和val.txt),这两个文件是通过运行voc_label.py代码生成的,然后是目标的类别数目和具体类别列表,网络训练时要根据这个文件来找到我们的数据集和验证集图片和对应标签位置,并在default=' '填入new.yaml的路径,new.yaml内容如下:
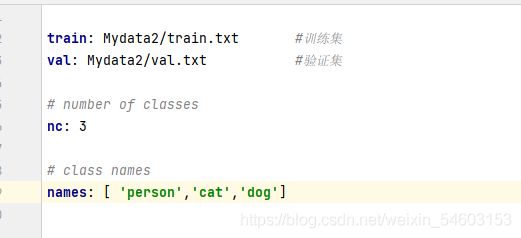
这样就完成了训练前所有的准备工作
四、开始训练
运行train.py

Namespace显示了我们在train.py中设置的一些参数
在训练的过程中我们可以在终端里运行tensorboard --logdir=runs/train
然后打开网站就可以实时的观看我们训练的一些情况
其中runs/train是我们训练文件所保存的位置
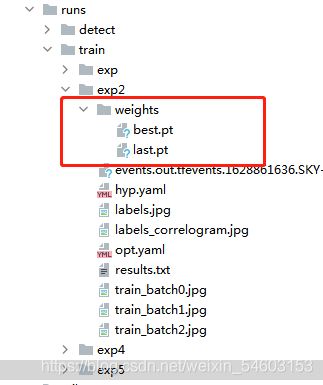
如果不更改训练结果所产生的路径的话,训练好后会在runs/train/exp文件夹得到如下文件,其中,我们训练好的权重为weights文件夹中的best.pt和last.pt文件,顾名思义,best.pt是训练300轮后所得到的最好的权重,last.pt是最后一轮训练所得到的权重。
五、开始预测
经过上面步骤我们已经训练出自己的网络模型,现在开始测试图片
打开detect.py
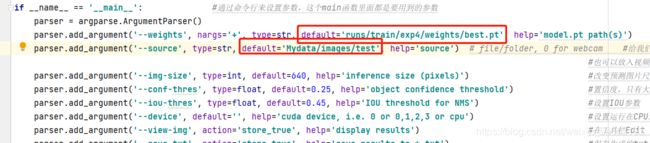
在第一个框中选择我们训练好的模型路径
在第二个框中选择我单独建立的测试集
运行即可开始测试,最后测试结果保存在
以上就是我自己在训练和测试yolov5的一个过程
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
补充
当每次训练完我们设定的轮数,且中途不中断训练,会生成可视化训练结果
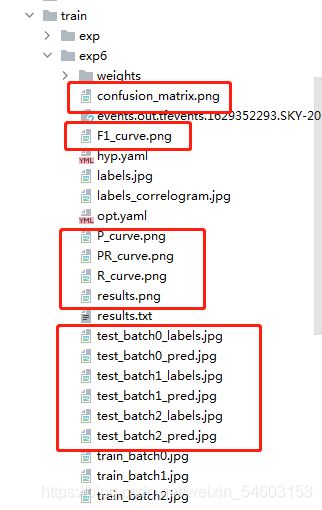
其中最下面test红框我原本以为是对测试集的预测,在我查看这几张图片对照测试集时发现不是,这是对我们设置的验证集的预测。
也就是说运行train.py当训练完毕之后会自动对我们设置的验证集进行一个预测,而非对我们设置的测试集进行预测。
我现在给我的数据集结构换一种划分(这种划分和我在上面说的数据集划分,这两种哪一种都可以),如下

此时我们在yaml文件中填入如下位置即可在训练中自动读取图片和对应的标签
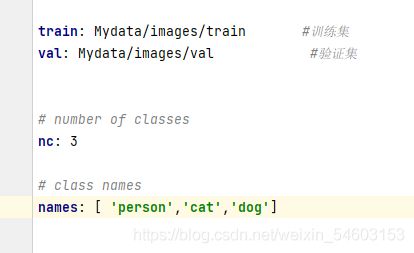
最后我想用我训练出来的模型来测试一下我的测试集,来看看效果,那就再创建我的测试集

测试集是只需要放置图片即可,不过我这里也放入了标签文件,标签文件在预测过程中不起作用