反向传播网络(BP-ANN)的python实现
文章首发及后续更新:https://mwhls.top/2592.html
新的更新内容请到mwhls.top查看。
无图/无目录/格式错误/更多相关请到上方的文章首发页面查看。
没写完。
用法会单独开一篇,不过就是整个对象然后整个数据集然后整进train里面再整进test或者predict里,类似sklearn。
算法简介
BP网络(Back Propagation network, BP)是一种人工神经网络(Artificial Neural Network, ANN),可分为前向传播与反向传播两个过程,利用梯度下降法来实现对不同神经层权重的调整,以实现输入特征向量,输出类别的效果。
代码框架
代码框架流程图
- 注:这个流程图很不标准,但是但是但是但是,mermaid真的很乱,这是最好看的一版了。
- 注2:这个配色很丑我知道,但我不知道怎么改。
- 注3:CSDN好像不支持我这款的mermaid流程图,感兴趣请移步我博客https://mwhls.top/2592.html
flowchart TB
subgraph initialize[初始化]
step1[[数据预处理]] --> step2[[模型初始化]]
end
initialize --> epoch
subgraph epoch[epoch训练循环]
step4[[epoch训练开始]] --> s41[打乱数据集]
s41 --> batch
subgraph batch[使用batch数量的数据进行训练]
step5d[\结束?/] --> |还有剩余batch|step5
step5[[batch训练开始]] -->s51
subgraph s51[前向传播]
s511[权重求和] -->s512[激活函数]
end
s51-->s52
subgraph s52[后向传播]
s521[梯度计算] -->s522[权重更新]
end
s52-->step5d
end
batch --> test
subgraph test[测试]
s61[预测] --> s62[获取mAP]
end
test --> output[记录日志]
output --> step4d[\结束?/]
step4d -->|还有剩余epoch| s41
end
代码框架图解释
- 数据预处理
- 载入数据集文件,分割文件为特征矩阵与类别向量。
- 模型初始化
- 参数设定。
- 权重列表、输出列表、损失列表初始化。
- 临时变量、中间变量初始化。
- 训练
- 参数设置。
- 临时变量初始化。
- 开始epoch循环。
- 保存日志。
- 输出处理信息。
- epoch训练循环
- 打乱训练集。
- 循环取出batch大小的数据。
- 进入batch训练。
- 输出当前批次时间。
- 若经过quiet_epoch次训练,则进行测试一次训练集,获取mAP。
- 保存模型及日志。
- batch训练
- 权重求和,得到layer_output。
- 激活函数,对layer_output使用激活函数,得到activate_output。
- 输入整理,根据各层输入,设置input。
- 梯度计算,对activate_output计算损失函数的梯度,得到loss。
- 计算学习率,根据step与batch计算学习率influence。
- 权重更新,根据influence、loss以及input更新权重。
- 偏置更新,根据influence、loss更新偏置。
- 测试
- 预测训练集,获得预测结果predict。
- 与训练集真实类别比较,获取mAP。
- 预测
- 前向传播,获得输出矩阵。
- 查字典以获取对应类别,将输出矩阵转为预测类别矩阵。
算法性能分析
数据集
| Dataset | #class | #feature | #train | #test |
|---|---|---|---|---|
| Letter | 26 | 16 | 16000 | 4000 |
10000次训练下,不同参数的训练效果
- 经过多次训练,发现神经层数,神经元节点的提高会使得训练效果的提高,但同时耗时也会大大升高。
- 针对单一变量对训练的影响,后面会单独列出。
- 注:耗时仅供参考,训练环境没有进行控制,经常是多训练同时跑。
- 注2:这里的每次训练没有打乱数据集,当时忘了这个步骤,但后面的测试及代码是由这步骤的。
| epoch | layer | sigmoid_h | step | batch | train best mAP | test mAP | time/s |
|---|---|---|---|---|---|---|---|
| 训练次数 | 神经层 | 激活函数放缩 | 学习率 | 训练批量 | 训练集最优mAP | 测试集mAP | 耗时/s |
| 10000 | [200, 200] | 100 | 0.5 | 2000 | 0.040 | 0.036 | 16802 |
| 10000 | [200] | 100 | 0.5 | 2000 | 0.040 | 0.036 | 7912 |
| 10000 | [200] | 1 | 0.5 | 2000 | 0.686 | 0.6585 | 7954 |
| 10000 | [500] | 100 | 0.5 | 2000 | 0.767 | 0.74375 | 20378 |
| 10000 | [200] | 10 | 0.1 | 2000 | 0.880 | 0.86375 | 8083 |
| 10000 | [200] | 10 | 0.9 | 2000 | 0.919 | 0.89375 | 4711 |
| 10000 | [200] | 10 | 0.5 | 2000 | 0.928 | 0.89075 | 4699 |
| 10000 | [200, 200] | 10 | 0.5 | 2000 | 0.969 | 0.92375 | 15877 |
| 10000 | [500] | 1 | 0.5 | 2000 | 0.975 | 0.94575 | 15145 |
| 10000 | [500] | 10 | 0.5 | 2000 | 0.976 | 0.95525 | 20651 |
| 10000 | [1000] | 10 | 0.5 | 2000 | 0.983 | 0.95875 | 24470 |
- 下面各图中,图2.1.1为大多数参数的图像,区别仅在于变化的快慢。
- 图2.2.2为layer=[200], sigmoid_h=10, step=0.9, batch=2000时的mAP图,后面的阶段突然下滑可能是学习率太大,出现了过拟合,因为很多参数跑到最后,mAP都慢慢下降了。
- 图2.2.3为layer=[200], sigmoid_h=1, step=0.5, batch=2000时的mAP图,可能是因为sigmoid_h太小,求导之后的导数太大,而产生抖动。
- 图2.2.4为layer=[200,200], sigmoid_h=10, step=0.5, batch=2000时的mAP图,后续我用batch=50,可以在50代左右开始提升效果,猜测可能是多层神经层需要更多的训练样本。
| 图2.2.1 | 图2.2.2 |
|---|---|
 |
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tbFGQMJg-1627092643620)(https://i.loli.net/2021/06/17/UqODtZ9kl1dQb5X.png)] |
| 图2.2.3 | 图2.2.4 |
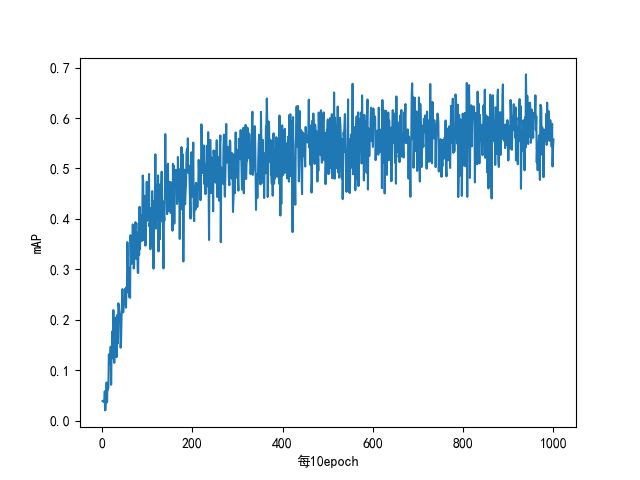 |
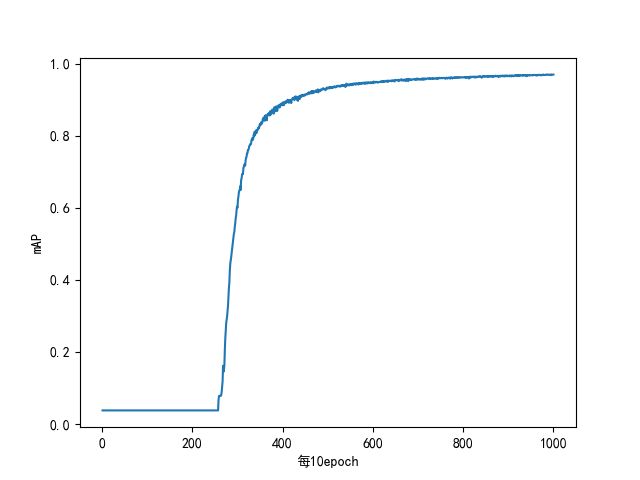 |
Batch对训练效果的影响
- 图2.3.1中,显示了不同batch对训练的影响。可以看出,batch的增加可以提高训练效果,但过高会降低训练效果,最好的是batch = 20,第一次训练就有0.6的mAP,且能收敛在一个较高mAP的位置。
- 图2.3.2中,显示了不同batch对耗时的影响。可以看出,batch的增加可以加快效率,但过高反而会降低效率。
- 因此就letter数据集而言,batch取20左右能在性能与效率上达到一个不错的平衡。
| 图2.3.1:step=0.5, layer=[200], sigmoid_h=10时,batch的变化对两百次训练的影响 | 图2.3.2:batch = [1, 2, 4, 10, 20, 50, 100, 200, 500, 1000, 2000, 5000, 10000, 16000]时的耗时变化 |
|---|---|
| [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fo7pZSvO-1627092643626)(https://i.loli.net/2021/06/17/9UzAvogKlYCknfE.png)] | [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9Gynq6hU-1627092643627)(https://i.loli.net/2021/06/18/BcHkrqQEyAuixSt.png)] |
神经元个数对训练的影响
- 从图2.4.1中可以看出,训练效果随着神经元个数的增加而增加。
- 从图2.4.2中可以看出,训练耗时随着神经元个数的增加而增加。
| 图2.4.1:step=0.5, batch=100, sigmoid_h=10时,神经元个数的变化对两百次训练的影响 | 图2.4.2:神经元个数 = [10, 20, 50, 100, 200, 500, 1000]时的耗时变化 |
|---|---|
| [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9uWlloXP-1627092643627)(https://i.loli.net/2021/06/17/gvCNwMKham3xX8r.png)] | [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CIxAEp1N-1627092643628)(https://i.loli.net/2021/06/18/2YThlftVBo1x9gP.png)] |
神经层层数对训练的影响
- 这里的测试例子不太好,神经层层数的增加会让耗时增加很多,而我的电脑为了跑测试已经三四天没关了,如果想跑出效果它会好累的。
| 图2.5.1:step=0.5, batch=100, sigmoid_h=10时,神经层层数的变化对两百次训练的影响 | 图2.5.2:每层神经元等于两百时,神经层层数 = [1, 2, 3, 4]时的耗时变化 |
|---|---|
| [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-43GRUVHz-1627092643629)(https://i.loli.net/2021/06/18/EnrLlN1i4e8SXCt.png)] | [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ijQgAsab-1627092643629)(https://i.loli.net/2021/06/18/3bCEzyYQwTi8dIt.png)] |
学习率与激活函数放缩量对训练的影响
- 从图2.6.1可以看出,学习率的提高能加快学习效率,且从表2.2.1可以看出,在训练次数足够多的情况下,学习率在0.5的时候能获得一个不错的训练效果。
- 学习率的变化对耗时影响不大,因此这不放图了。
- 从图2.7.1可以看出,训练效果随着sigmoid_h的增加,先增加后减少,最好的参数为sigmoid_h = 10。
- sigmoid_h变化的耗时方面,时高时低,没有规律,只是在一个范围内波动。
| 图2.6.1:layer=[100], batch=100, sigmoid_h=10时,学习率的变化对训练的影响 | 图2.6.2:layer=[100], batch=100, step=0.5时,sigmoid_h的变化对训练的影响 |
|---|---|
| [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9HbLc84k-1627092643630)(https://i.loli.net/2021/06/18/WJFSiebnuGwrED2.png)] | 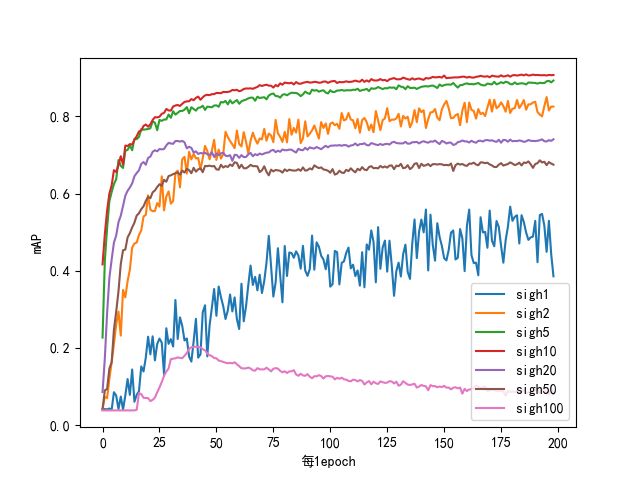 |
总结
- 根据上面的测试可知,就letter数据集而言:
- layer越复杂,性能越好,但耗时更多
- sigmoid_h、batch、step不应太高,也不应太低。
- 根据上面的测试,选用了上面较好的参数进行继续了测试,对不同参数下训练20次的效果如图2.7.1。
- 可以看出,layer = [500], sigmoid_h = 10, batch = 20, step = 0.5的效果较好,且速度更快,而batch=5虽然更快点,但速度比batch=20时的会慢不少。
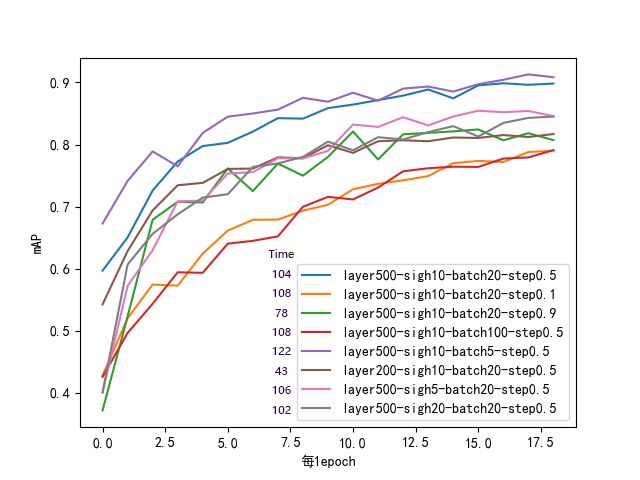
实现功能
- BP-ANN(误差后向传递人工神经网络)的训练,测试,预测功能。
- 自定义神经层的层数及各层神经元数量。
- 两个激活函数:sigmoid、tanh。且可轻松扩展。
- 两个损失函数:softmax、MSE。且可轻松扩展。
- 一次训练多个数据,且可按数目/比例自定义数目。
- 日志功能。
- 提供mAP变化曲线图,且可自定义绘制区域,支持多参数效果绘制于同一张图片。
- 可基于中断/结束的模型继续训练。
- 保存两个模型,最好mAP的模型与最后一次训练的模型。
- 多参数调节:变化步长,输出路径,激活函数形状,输出级别等14个参数可供调节。
难点及解决
算法正确性检测
- 问题描述:
- 判断算法是否能正常计算。
- 解决方式:
- 定义简单训练集进行训练,如定义一个两类,两特征的两个数据:
- [‘A’, 10, 1]
[‘B’, 1, 10]
- 实现效果:
- 只需简单神经层及少量训练次数即可训练成果,并简化了中间变量维度。
矩阵运算验证
- 问题描述:
- 矩阵运算经常出现维度不符合的报错。
- 解决方式:
- 先确定目标的维度,然后再确定两个矩阵应该的维度,与算法中实际的维度进行对比。
- 实现效果:
- 避免了很多矩阵的错误运算。
梯度计算问题
- 问题描述:
- 只能对一个类别拟合,当出现多个类别时,几乎没有效果。
- 产生原因:
- 梯度计算过程理解错误。
- 参考的书上,没有考虑到偏置,并且下标打错了,这是其一。
- 对网上讲解的式子,下标也不是很明白,错误理解了计算方式,这是其二。
- 解决方式:
- 最开始是设定一个自适应的训练方式,根据权重变化幅度来决定是否继续训练,但后来因为是算法本身过程就计算错了,因此删掉了这个功能。
- 加入了偏置,并改正了计算方式。
- 实现效果:
- 能正常拟合出假定的数据集。
效率慢
- 问题描述:
- 当数据集为16个特征,26个类别,共16000个数据时,一次训练需要8秒钟。
- 产生原因:
- 因梯度计算理解不透彻,部分能用矩阵运算的使用了for循环处理。
- 对训练数据一个个训练,没有分批训练。
- 解决方式:
- 将所有由for实现的矩阵运算改为numpy提供的矩阵运算。
- 实现效果:
- 每批平均训练时间从8000ms降低至40ms。
- 值得一提的是,测试耗时反而比训练耗时多,因为找类别和归纳类别用的方式有点土,我的python基础还不太行。
无法拟合真实数据集
-
问题描述:
- 对假设的数据集有不错的效果,但对真实数据集训练时,总是会出现各类预测概率相同。
- 并且权重变化从输出层向输入层越来越小,仅第二层就有大多数误差为0。
- 最重要的是,跑了几十万epoch也没跑出任何优化。
-
产生原因:
- 正则化错误,sigmoid处理后进入了饱和区,值都趋近为1,因此误差极小。
- 参考的文章是这么说的,但正则化是损失函数相关的,不是激活函数相关的。不过根据文章的解释倒是立刻就解决了这个问题。
-
解决方式:
-
将sigmoid激活函数在横轴上进行了放缩,如下式的sigh改为100,就能正常训练了。
-
1 1 + e − X − s i g x s i g h \frac{1}{1+e^{ -\frac{ X-sigx }{ sigh } }} 1+e−sighX−sigx1
-
值得一提的是,后来我把sigh设为1,也能训练,但sigh的值大一点训练效果会快一点。
-
-
实现效果:
- 成功实现对真实数据集的拟合。
- 不过,后来我将sigh改为1,也能正常拟合。
- 成功实现对真实数据集的拟合。
BP-ANN代码
import numpy as np
import time
import os
import pickle
import matplotlib.pyplot as plt
class ANN:
def __init__(self, X=None, Y=None, step=0.5, layer=[100], batch=2000,
activate='sigmoid', sigmoid_x=0.0, sigmoid_h=1, tanh_h=1,
loss='softmax',
show=3, quiet_epoch=1, output_path=None, new_graph=False):
"""
:param layer: 神经层,值为一维整型列表。
[3, 5]表示第一层3个神经元,第二层5个神经元。
!!不要修改已训练好的模型的神经层。
"""
self.__output_path = None
self.set_parameter(X=X, Y=Y, step=step, batch=batch,
activate=activate, sigmoid_x=sigmoid_x, sigmoid_h=sigmoid_h, tanh_h=tanh_h,
loss=loss,
show=show, quiet_epoch=quiet_epoch, output_path=output_path, new_graph=new_graph)
self.__data_initialize()
self.__set_layer(layer)
self.__tmp_initialize()
self.__weight_initialize()
self.__train_epoch = 0
self.__activate_output = []
def contact_me(self):
"""
联系方式。
:return:
"""
contact_me = """
------------------------------------------------------
- https://mwhls.top/2592.html -
- Wang more information? Click my blog link above! -
- -
- I want to write these in Chinese, -
- but it hard to align. -
------------------------------------------------------
"""
print(contact_me)
def __tmp_initialize(self):
"""
临时变量初始化。
:return: NULL
"""
self.__tmp_sum = 0
self.__tmp_last_sum = 0
self.__best_mAP = 0
self.__mAP_epoch = []
def set_parameter(self, X=None, Y=None, step=None, batch=None,
activate=None, sigmoid_x=None, sigmoid_h=None, tanh_h=None,
loss=None,
show=None, quiet_epoch=None, output_path=None, new_graph=None):
"""
参数设置。
:param X: 数据集特征列表,m个数据,每个数据n个特征,为m*n矩阵。
:param Y: 数据集类别列表,m个数据,每个数据1个类别,为1*m矩阵。
:param step: 变化步长,值域(0, 1],值为浮点型。
:param batch: 每次训练时参与处理的数据数量,值为非负实数。
当batch>1时,为训练个数。如200个数据,batch为10,则对数据集的一次训练中,训练20批,每批10个数据。
当batch∈(0,1]时,为训练比例。如200个数据,batch为0.5,则一次训练100个。
当batch==1时,一批训练一个。
:param activate: 激活函数,值为字符串。
现在实现了sigmoid和tanh激活函数,
值为'sigmoid'时,选用sigmoid函数,并用sigmoid_x与sigmoid_h调节函数形状。
值为'tanh'时,选用tanh函数,并用tanh_h调节函数形状。
:param sigmoid_x: 横轴偏移量,值为任意实数。
为标准sigmoid函数中,对x进行 (x+sigmoid_x)/sigmoid_h 操作。
:param sigmoid_h: 横轴放缩量,值为任意非零实数。
为标准sigmoid函数中,对x进行 (x+sigmoid_x)/sigmoid_h 操作。
:param tanh_h: 横轴放缩量,值为非零实数。
为标准tanh函数中,对x进行 x/tanh_h 操作。
:param loss: 损失函数,值为字符串。
现在实现了mse和softmax损失函数。
值为'mse'时,选用mse函数。
值为'softmax'时,选用softmax函数。
:param show: 显示级别,根据show值确定哪些将在训练过程中展示。
0:仅在训练结束后显示结果。
1:显示训练次数及时间
2: 显示mAP,各类平均准确度
3:显示correct,各类正确度
4: 显示测试结果。
:param quiet_epoch: 设置静默次数,值为正整数。
每经过quiet_epoch次训练,启用一次测试以计算mAP。
因为测试比较占时间,所以如果训练次数比较长,推荐这个值高一点。
:param output_path: 输出目录,值为任何可做文件夹名称的字符串。
默认为当前时间戳的文件夹。
:param new_graph: 是否仅根据当前训练结果绘制mAP图像。值为True或False。
:return:
"""
self.set_data(X, Y)
if new_graph is True:
self.__mAP_epoch = []
self.__train_epoch = 0
self.set_show(show)
self.set_step(step)
self.set_batch(batch)
self.set_loss(loss)
self.set_activate(activate=activate, sigmoid_h=sigmoid_h, sigmoid_x=sigmoid_x, tanh_h=tanh_h)
self.set_output_path(output_path)
self.set_quiet_epoch(quiet_epoch)
def set_show(self, show):
"""
设置显示级别。
:param show:
:return:
"""
if show is not None:
self.show = show
def set_batch(self, batch):
"""
设置每批训练数量。
:param batch: 一批训练使用的数量,batch==0时表示一次训练一个样本,(0, 1]表示按数据集百分比训练,(1, inf)表示训练个数
:return: NULL
"""
if batch is not None:
if batch == 0:
self.__batch = 1
elif batch > 1:
self.__batch = round(batch)
elif batch <= 1:
self.__batch = round((self.__data_num * batch))
def set_quiet_epoch(self, quiet_epoch):
"""
设置静默次数,每经过quiet_epoch次训练,启用一次测试,计算mAP。
因为测试比较占时间,所以如果训练次数比较长,推荐这个值高一点。
:param quiet_epoch: 整型。
:return:
"""
if quiet_epoch is not None:
self.__quiet_epoch = quiet_epoch
def set_show(self, show):
"""
显示级别:
0:仅在训练结束后显示结果。
1:显示训练次数及时间
2: 显示mAP,各类平均准确度
3:显示correct,各类正确度
4: 显示测试结果。
:param show:
:return:
"""
if show is not None:
self.show = show
def set_data(self, X, Y):
"""
设置数据集,并初始化数据集
:param X: 数据集特征列表,m个数据,每个数据n个特征,为m*n矩阵。
:param Y: 数据集类别列表,m个数据,每个数据1个类别,为1*m矩阵。
:return:
"""
if X is not None:
self.__X = np.array(X)
# 特征数
self.__feature_num = len(self.__X[0])
# 数据集个数
self.__data_num = len(self.__X)
if Y is not None:
self.__Y = np.array(Y)
def set_step(self, step):
"""
设置变化步长。
:param step: 步长,值域(0,1]。
:return:
"""
if step is not None:
self.__step = step
def set_activate(self, activate=None, sigmoid_x=0, sigmoid_h=1, tanh_h=1):
"""
设置激活函数。
:param activate: 激活函数名
:param sigmoid_x: sigmoid横轴偏移量。
:param sigmoid_h: sigmoid横轴放缩量。
:param tanh_h: tanh横轴放缩量。
:return:
"""
if activate is not None:
self.__activate_method = activate
if sigmoid_x is not None:
self.__sigmoid_x = sigmoid_x
if sigmoid_h is not None:
self.__sigmoid_h = sigmoid_h
if tanh_h is not None:
self.__tanh_h = tanh_h
def __set_layer(self, layer):
"""
神经层设置及初始化。
:param layer: [10, 15]表示两层隐含层,第一层有10个神经元节点,第二层有15个神经元节点。
:return: NULL
"""
if layer is not None:
self.__layer = layer
self.__layer_output = []
self.__layer_initialize()
def set_loss(self, loss):
"""
设置损失函数。
:param loss: 损失函数方法。
:return: NULL
"""
if loss is not None:
self.__loss_method = loss
def set_output_path(self, output_path=None):
"""
设置输出目录
:param output_path: 输出目录文件夹名称。
:return:
"""
if output_path is None and self.__output_path is None:
output_path = round(time.time())
self.__output_path = os.path.join('./output/' + str(output_path) + '/')
elif output_path is not None:
self.__output_path = os.path.join('./output/' + str(output_path) + '/')
def __update_parameter(self):
"""
参数更新。
:return: NULL
"""
self.__parameter = ""
self.__parameter += "\n__train_epoch\t\t" + str(self.__train_epoch)
self.__parameter += "\n__feature_num\t\t" + str(self.__feature_num)
self.__parameter += "\n__class_dictionary\t" + str(self.__class_dictionary)
self.__parameter += "\n__class_dictionary_key\t" + str(self.__class_dictionary_key)
self.__parameter += "\n__class_dictionary_num\t" + str(self.__class_dictionary_num)
self.__parameter += "\n__class_num\t\t" + str(self.__class_num)
self.__parameter += "\n__class\n" + str(self.__class).replace('\n', '\t')
self.__parameter += "\n__layer\t\t\t\t" + str(self.__layer)
self.__parameter += "\n__weight\t\n" + str(self.__weight).replace('\n', '\t')
self.__parameter += "\n__weight_b\t\n" + str(self.__weight_b).replace('\n', '\t')
self.__parameter += "\n__step\t\t\t\t" + str(self.__step)
self.__parameter += "\n__activate_method\t\t\t\t" + str(self.__activate_method)
if self.__activate_method == 'sigmoid':
self.__parameter += "\n__sigmoid_x\t\t\t\t" + str(self.__sigmoid_x)
self.__parameter += "\n__sigmoid_h\t\t\t\t" + str(self.__sigmoid_h)
elif self.__activate_method == 'tanh':
self.__parameter += "\n__tanh_h\t\t\t\t" + str(self.__tanh_h)
self.__parameter += "\n__loss_method\t\t\t\t" + str(self.__loss_method)
self.__parameter += "\n__batch\t\t\t\t" + str(self.__batch)
self.__parameter += "\n"
def show_parameter(self):
"""
当前参数显示。
:return: NULL
"""
self.__update_parameter()
print(self.__parameter)
def __data_initialize(self):
"""
数据集初始化。
:return: NULL
"""
# 类别初始化
# 类别:序号 字典,
self.__class_dictionary = {}
# 类别:数目占比 字典
self.__class_dictionary_num = {}
# 类别个数
self.__class_num = 0
for clas in set(self.__Y):
self.__class_num += 1
self.__class_dictionary[clas] = self.__class_num
self.__class_dictionary_num[clas] = np.sum(self.__Y == clas) / self.__data_num
# 类别矩阵,one-hot编码,0.1为非该类,0.9为该类。
self.__class = np.array([[0.1]*self.__class_num] * self.__data_num)
for pos in range(self.__data_num):
clas = self.__class_dictionary[self.__Y[pos]]
self.__class[pos][clas-1] = 0.9
# 序号:类别 字典,为 类别:序号 字典的反向字典。
self.__class_dictionary_key = dict((v,k) for k,v in self.__class_dictionary.items())
def __layer_initialize(self):
"""
神经层节点、层数初始化。
:return:
"""
# 插入特征个数至神经层首位
self.__layer = np.insert(self.__layer, 0, self.__feature_num)
# 插入类别个数至神经层末尾
self.__layer = np.append(self.__layer, self.__class_num)
def __weight_initialize(self):
"""
权重初始化。
:return:
"""
# 权重
self.__weight = []
# 偏置
self.__weight_b = np.random.random_sample([1, len(self.__layer)-1])
for pos in range(len(self.__layer)-1):
tmp = np.random.random_sample([self.__layer[pos]+1, self.__layer[pos+1]])
self.__weight.append(tmp)
def __weight_sum(self, layer, matrix1, matrix2):
"""
前向传播权重求和。
:param layer: 待处理层
:param matrix1: 输入矩阵
:param matrix2: 权重矩阵
:return: NULL
"""
matrix1 = np.c_[matrix1, np.ones(len(matrix1))]
matrix2[len(matrix2)-1] = np.array([self.__weight_b[0][layer]])
matmul = np.matmul(matrix1, matrix2)
if len(self.__layer_output) <= layer:
self.__layer_output.append(matmul)
else:
self.__layer_output[layer] = matmul
def __activate_choose(self, layer):
"""
根据激活方法对layer层实施激活函数。
:param layer: 神经层
:return:
"""
method = self.__activate_method
if method == 'sigmoid':
self.__activate_sigmoid(layer)
elif method == 'tanh':
self.__activate_tanh(layer)
def __activate_tanh(self, layer):
"""
使用tanh激活函数。
:param layer: 神经层
:return:
"""
if len(self.__activate_output) <= layer:
self.__activate_output.append(self.__layer_output[layer].copy())
else:
self.__activate_output[layer] = self.__layer_output[layer].copy()
exp_x = np.exp(self.__activate_output[layer])
exp_x_n = np.exp(-self.__activate_output[layer])
self.__activate_output[layer] = (exp_x - exp_x_n) / (exp_x + exp_x_n)
def __activate_sigmoid(self, layer):
"""
使用sigmoid激活函数。
:param layer: 神经层
:return:
"""
if len(self.__activate_output) <= layer:
self.__activate_output.append(self.__layer_output[layer].copy())
else:
self.__activate_output[layer] = self.__layer_output[layer].copy()
self.__activate_output[layer] = 1.0 / (1.0 + np.exp(-(self.__activate_output[layer] - self.__sigmoid_x) / self.__sigmoid_h))
def __loss_choose(self, start, end):
"""
根据损失方法实施损失函数
:param start: 数据集起始位置
:param end: 数据集终止位置
:return: NULL
"""
method = self.__loss_method
if method == 'mse':
self.__loss_MSE(start, end)
elif method == 'softmax':
self.__loss_softmax(start, end)
def __loss_MSE(self, start, end):
"""
实施loss损失函数
:param start: 数据集起始位置
:param end: 数据集终止位置
:return: NULL
"""
self.__loss = self.__activate_output.copy()
for layer in range(len(self.__loss)-1, -1, -1):
tmp_y = self.__activate_output[layer]
tmp_1 = np.ones([len(tmp_y), len(tmp_y[0])])
self.__loss[layer] = np.multiply(tmp_y, np.subtract(tmp_1, tmp_y))
if layer == len(self.__loss)-1:
tmp_d = np.subtract(self.__class[start:end], tmp_y)
self.__loss[layer] = np.multiply(self.__loss[layer], tmp_d)
else:
tmp_sum = np.matmul(self.__loss[layer+1], self.__weight[layer+1].T)
tmp_sum = np.delete(tmp_sum, -1, axis=1)
self.__loss[layer] = np.multiply(self.__loss[layer], tmp_sum)
def __loss_softmax(self, start, end):
"""
实施softmax损失函数
:param start: 数据集起始位置
:param end: 数据集终止位置
:return: NULL
"""
self.__loss = self.__activate_output.copy()
for layer in range(len(self.__loss)-1, -1, -1):
if layer == len(self.__loss)-1:
tmp_y = self.__activate_output[layer]
tmp_d = self.__class[start:end]
self.__loss[layer] = np.subtract(tmp_d, tmp_y)
else:
tmp_y = self.__activate_output[layer]
tmp_1 = np.ones([len(tmp_y), len(tmp_y[0])])
self.__loss[layer] = np.multiply(tmp_y, np.subtract(tmp_1, tmp_y))
tmp_sum = np.matmul(self.__loss[layer+1], self.__weight[layer+1].T)
tmp_sum = np.delete(tmp_sum, -1, axis=1)
self.__loss[layer] = np.multiply(self.__loss[layer], tmp_sum)
def __back_propagation(self, start, end):
"""
后向传播。
:param start: 数据集起始位置
:param end: 数据集终止位置
:return: NULL
"""
# 计算各层梯度
self.__loss_choose(start, end)
for layer in range(len(self.__loss)):
if layer == 0:
input = self.__X[start:end]
else:
input = self.__activate_output[layer-1]
# 输入端input
input = np.c_[input, np.ones([input.shape[0]])]
# 损失梯度
loss = self.__loss[layer]
# 变化幅度
influence = self.__step / (end-start)
# 权重更新
tmp = np.matmul(input.T, loss) * influence
self.__weight[layer] = np.add(self.__weight[layer], tmp)
# 偏置更新
tmp = np.sum(self.__loss[layer]) * influence
self.__weight_b[0][layer - 1] += tmp
self.__weight[layer][len(self.__weight[layer])-1] = np.array([self.__weight_b[0][layer]])
def __train_multi(self, start, end):
'''
训练训练集X[start:end]的数据。
:param start: 数据集开始位置
:param end: 数据集结束位置
:return:
'''
# 首层权重求和
self.__weight_sum(0, self.__X[start:end], self.__weight[0])
# 首层激活函数处理
self.__activate_choose(0)
# 非首层权重求和及激活函数处理
for layer in range(1, self.__layer.shape[0]-1):
self.__weight_sum(layer, self.__activate_output[layer-1], self.__weight[layer])
self.__activate_choose(layer)
# 后向传播
self.__back_propagation(start, end)
def __data_shuffle(self):
"""
数据集打乱。
参考:https://blog.csdn.net/Song_Lynn/article/details/82817647
:return:
"""
shuffle = np.random.permutation(self.__X.shape[0])
self.__X = self.__X[shuffle, :]
self.__Y = self.__Y[shuffle]
self.__class = self.__class[shuffle]
def train(self, epoch=0, X=None, Y=None, step=None, batch=None,
activate=None, sigmoid_x=None, sigmoid_h=None, tanh_h=None, loss=None,
show=None, quiet_epoch=None, output_path=None, new_graph=None, label=''):
"""
训练。
"""
# 参数设置。
self.set_parameter(X=X, Y=Y, step=step, batch=batch,
activate=activate, sigmoid_x=sigmoid_x, sigmoid_h=sigmoid_h, tanh_h=tanh_h,
loss=loss,
show=show, quiet_epoch=quiet_epoch, output_path=output_path, new_graph=new_graph)
# 训练起始时间戳。
start_time = time.time()
# 开始训练
while self.__train_epoch < epoch:
# 当前epoch开始时间
epoch_start_time = time.time()
# 数据集处理初始位置
start = 0
# 数据集打乱
self.__data_shuffle()
while start < self.__data_num:
# 数据集处理结束位置
end = start + self.__batch
# 结束位置超过数据集大小,降低至数据集大小
if end > self.__data_num:
end = self.__data_num
# 训练数据集中start至end位置的样本。
self.__train_multi(start, end)
# 下一次起始位置
start = end
# 已训练次数增加
self.__train_epoch += 1
# 若度过静默期则进行测试,以获取当前模型mAP。
if self.__train_epoch / self.__quiet_epoch == self.__train_epoch // self.__quiet_epoch:
self.test(self.__X, self.__Y, True)
# 当前epoch训练时间
epoch_pass_time = round((time.time() - epoch_start_time) * 1000)
# 保存最新模型
self.__save_model('last.pkl')
# 耗时显示
if self.show > 0:
print('\nepoch ' + str(self.__train_epoch) + ':\truntime: ', epoch_pass_time, end='')
# 保存日志
self.__save_log('\nepoch ' + str(self.__train_epoch) + ': process time:' + str(epoch_pass_time))
# 训练总耗时
pass_time = round(time.time() - start_time)
# 训练日志保存
self.__save_log('Total process time: ' + str(pass_time) + 's\n')
self.__save_log('')
self.__save_log('Best mAP: ' + str(self.__best_mAP))
self.__update_parameter()
self.__save_log(self.__parameter)
# 绘制mAP变化图
self.draw_mAP(label=label)
# 训练结果输出
print("\n--------------Train done-----------------")
print('\tTotal process time:', pass_time)
print('\tBest mAP:', self.__best_mAP)
print('\tsave log to', self.__output_path)
print('-----------------------------------------')
def __predict_multi(self, x, show=False):
"""
预测。
:param x: 特征列表,m个数据,每个数据n个特征,为m*n矩阵。
:param show: 是否显示预测结果。
:return: 预测类别列表,1*m矩阵。
"""
self.__weight_sum(0, x, self.__weight[0])
self.__activate_sigmoid(0)
for layer in range(1, len(self.__layer) - 1):
self.__weight_sum(layer, self.__activate_output[layer - 1], self.__weight[layer])
self.__activate_sigmoid(layer)
predict_result = []
for output in self.__activate_output[-1]:
output = list(output)
tmp = self.__class_dictionary_key[output.index(max(output))+1]
predict_result.append(tmp)
if self.show > 3 or show:
print(predict_result)
print('')
return predict_result
def __accurate(self, predict_class, actual_class, save_log=False):
"""
计算mAP。
:param predict_class: 预测类
:param actual_class: 实际类
:param save_log: 是否存储日志
:return: mAP值
"""
# 正确个数
right = 0
# 各类正确比例。
correct = {key:0 for key in self.__class_dictionary.keys()}
# 各类正确个数/总正确计算
for pos in range(len(predict_class)):
if predict_class[pos] == actual_class[pos]:
correct[predict_class[pos]] += 1
right += 1
# 转换为各类总数
for key in correct.keys():
correct[key] = correct[key] / (np.sum(actual_class == key))
# mAP计算
mAP = right / len(actual_class)
# 加入历代mAP
self.__mAP_epoch.append(mAP)
# 显示结果
if self.show > 1:
print('\t mAP:', mAP, end=' ')
if self.show > 2:
print('\t correct:', correct, end='')
# 保存日志
if save_log:
log = '\tmAP:' + str(mAP)
log = log + '\tcorrect' + str(correct)
self.__save_log(log)
return mAP
def test(self, x, y, from_train=False):
"""
测试。
:param x: 特征列表,m个数据,每个数据n个特征,为m*n矩阵。
:param y: 特征类别,m个数据,每个数据1个类别,为1*m矩阵。
:return:
"""
# 根据特征预测
predict = np.array(self.__predict_multi(x))
# 类
y = np.array(y)
# 预测的mAP。
mAP = self.__accurate(predict, y, from_train)
# 判断测试性能
if mAP > self.__best_mAP and from_train:
self.__best_mAP = mAP
self.__save_model('best.pkl')
def predict(self, x, show=True):
"""
预测。
:param x: 特征列表,m个数据,每个数据n个特征,为m*n矩阵。
:param show: 是否显示预测结果
:return:
"""
self.__predict_multi(x, show)
def __save_log(self, log, name='log'):
"""
保存日志。
:param log: 待保存信息。
:param name: 待保存文件名。
:return:
"""
if not os.path.exists(self.__output_path):
os.makedirs(self.__output_path)
name = name+'.log'
log_path = os.path.join(self.__output_path, name)
with open(log_path, 'a+') as f:
f.write(log)
def __save_model(self, model_name):
"""
保存模型.
:param model_name: 待保存模型名称。
:return:
"""
if not os.path.exists(self.__output_path):
os.makedirs(self.__output_path)
log_path = os.path.join(self.__output_path, model_name)
with open(log_path, 'wb+') as f:
pickle.dump(self, f)
def draw_mAP(self, start=0, end=-1, name='mAP', label=''):
"""
绘制mAP图片。
:param start: 绘制起始位置。
:param end: 绘制终止位置。
:param name: 保存文件名。
:return:
"""
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x = self.__mAP_epoch[start:end]
plt.plot(x, label=label)
plt.ylabel('mAP')
plt.xlabel(('每' + str(self.__quiet_epoch) + 'epoch'))
plt.legend()
plt.savefig((os.path.join(self.__output_path + str(name) +'.png')))
def get_history_mAP(self):
"""
返回历史mAP值。
:return:
"""
return self.__mAP_epoch