概述
一谈到高并发的优化方案,往往能想到模块水平拆分、数据库读写分离、分库分表,加缓存、加mq等,这些都是从系统架构上解决。单模块作为系统的组成单元,其性能好坏也能很大的影响整体性能,本文从单模块下读多写少的场景出发,探讨其解决方案,以其更好的实现高并发。
不同的业务场景,读和写的频率各有侧重,有两种常见的业务场景:
- 读多写少:典型场景如广告检索端、白名单更新维护、loadbalancer
- 读少写多:典型场景如qps统计
本文针对读多写少(也称一写多读)场景下遇到的问题进行分析,并探讨一种合适的解决方案。
分析
读多写少的场景,服务大部分情况下都是处于读,而且要求读的耗时不能太长,一般是毫秒或者更低的级别;更新的频率就不是那么频繁,如几秒钟更新一次。通过简单的加互斥锁,腾出一片临界区,往往能到达预期的效果,保证数据更新正确。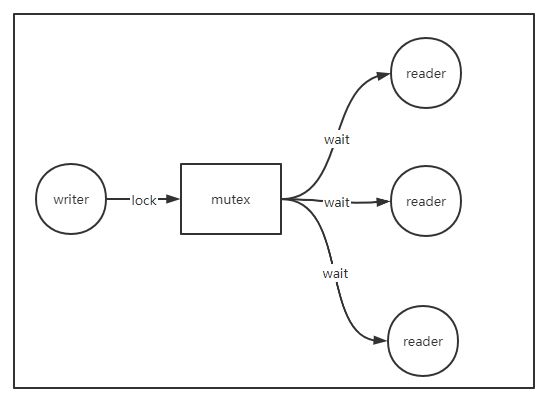
但是,只要加了锁,就会带来竞争,即使加的是读写锁,虽然读之间不互斥,但写一样会影响读,而且读写同时争夺锁的时候,锁优先分配给写(读写锁的特性)。例如,写的时候,要求所有的读请求阻塞住,等到写线程或协程释放锁之后才能读。如果写的临界区耗时比较大,则所有的读请求都会受影响,从监控图上看,这时候会有一根很尖的耗时毛刺,所有的读请求都在队列中等待处理,如果在下个更新周期来之前,服务能处理完这些读请求,可能情况没那么糟糕。但极端情况下,如果下个更新周期来了,读请求还没处理完,就会形成一个恶性循环,不断的有读请求在队列中等待,最终导致队列被挤满,服务出现假死,情况再恶劣一点的话,上游服务发现某个节点假死后,由于负载均衡策略,一般会重试请求其他节点,这时候其他节点的压力跟着增加了,最终导致整个系统出现雪崩。
因此,加锁在高并发场景下要尽量避免,如果避免不了,需要让锁的粒度尽量小,接近无锁(lock-free)更好,简单的对一大片临界区加锁,在高并发场景下不是一种合适的解决方案
双缓冲
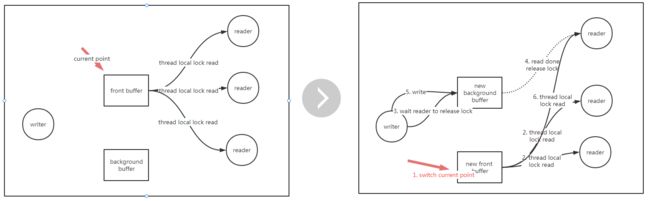
有一种数据结构叫双缓冲,其这种数据结构很常见,例如显示屏的显示原理,显示屏显示的当前帧,下一帧已经在后台的buffer准备好,等时间周期一到,就直接替换前台帧,这样能做到无卡顿的刷新,其实现的指导思想是空间换时间,这种数据结构的工作原理如下:
- 数据分为前台和后台
- 所有读线程读前台数据,不用加锁,通过一个指针来指向当前读的前台数据
- 只有一个线程负责更新,更新的时候,先准备好后台数据,接着直接切指针,这之后所有新进来的读请求都看到了新的前台数据
- 有部分读还落在老的前台那里处理,因为更新还不算完成,也就不能退出写线程,写线程需要等待所有落在老前台的线程读完成后,才能退出,在退出之前,顺便再更新一遍老前台数据(也就当前的新后台),可以保证前后台数据一致,这点在做增量更新的时候有用
工程实现上需要攻克的难点
- 写线程要怎么知道所有的读线程在老前台中的读完成了呢?
一种做法是让各个读线程都维护一把锁,读的时候锁住,这时候不会影响其他线程的读,但会影响写,读完后释放锁(某些时候可能会有通知写线程的开销,但由于写的频率很低,所以这点开销还能接受),写线程只需要确认锁有没有释放了,确认完了后马上释放,确认这个动作非常快(小于25ns,1s=1000ms=1000000us=1000000000ns),读线程几乎不会感觉到锁的存在。 - 每个线程都有一把自己的锁,需要用全局的map来做线程id和锁的映射吗?
不需要,而且这样做全局map就要加全局锁了,又回到了刚开始分析中遇到的问题了。其实,每个线程可以有私有存储(thread local storage,简称TLS),如果是协程,就对应这协程的TLS(但对于go语言,官方是不支持TLS的,想实现类似功能,要么就想办法获取到TLS,要么就不要基于协程锁,而是用全局锁,但尽量让锁粒度小,本文主要针对C++语言,暂时不深入讨论其他语言的实现)。这样每个读线程锁的是自己的锁,不会影响到其他的读线程,锁的目的仅仅是为了保证读优先。
对于线程私有存储,可以使用pthread_key_create, pthread_setspecific,pthread_getspecific系列函数
核心代码实现
读
template <typename T, typename TLS>
int DoublyBufferedData::Read(
typename DoublyBufferedData::ScopedPtr* ptr) { // ScopedPtr析构的时候,会释放锁 Wrapper* w = static_cast(pthread_getspecific(_wrapper_key)); //非首次读,获取pthread local lock if (BAIDU_LIKELY(w != NULL)) { w->BeginRead(); // 锁住 ptr->_data = UnsafeRead(); ptr->_w = w; return 0; } w = AddWrapper(); if (BAIDU_LIKELY(w != NULL)) { const int rc = pthread_setspecific(_wrapper_key, w); // 首次读,设置pthread local lock if (rc == 0) { w->BeginRead(); ptr->_data = UnsafeRead(); ptr->_w = w; return 0; } } return -1; } 写
template
template Fn>
size_t DoublyBufferedData<T, TLS>::Modify(Fn& fn) { BAIDU_SCOPED_LOCK(_modify_mutex); // 加锁,保证只有一个写 int bg_index = !_index.load(butil::memory_order_relaxed); // 指向后台buffer const size_t ret = fn(_data[bg_index]); // 修改后台buffer if (!ret) { return 0; } // 切指针 _index.store(bg_index, butil::memory_order_release); bg_index = !bg_index; // 等所有读老前台的线程读结束 { BAIDU_SCOPED_LOCK(_wrappers_mutex); for (size_t i = 0; i < _wrappers.size(); ++i) { _wrappers[i]->WaitReadDone(); } } // 确认没有读了,直接修改新后台数据,对其新前台 const size_t ret2 = fn(_data[bg_index]); return ret2; } 完整实现请参考brpc的DoublyBufferData
扩展实现
基于计数器的实现
基于计数器,用atomic,保证原子性,读进入临界区,计数器+1,退出-1,写判断计数器为0则切换(但在计数器为0和切换中间,不能保证没有新的读进来,这时候也要锁),而且计数器是全局锁。这种方案C++也可以采取,只是计数器毕竟也是全局锁,性能会差那么一丢丢。即使用智能指针shared_ptr,也会面临切换之前计数器有变成非0的问题。之所以用计数器,而不用TLS,是因为有些语言,如golang,不支持TLS,对比TLS版本和计数器版本,TLS性能更优,因为没有抢计数器的互斥问题,大概耗费700ns,很多吗?抢计数器本身很快,性能没测试过,可以试试。
golang中sync.Map的实现
也是基于计数器,只是计数器是为了让读前台缓存失效的概率不要太高,有抑制和收敛的作用,实现了读的无锁,少部分情况下,前台缓存读不到数据的时候,会去读后台缓存,这时候也要加锁,同时计数器+1。计数器数值达到一定程度(超过后台缓存的元素个数),就执行切换
是否适用于读少写多的场景
不合适,双缓冲优先保证读的性能,写多读少的场景需要优先保证写的性能。
相关文献
brpc对于双buffer的描述:https://www.bookstack.cn/read/incubator-brpc/3c7745da34a1418b.md#DoublyBufferedData
go实现的双buffer(但读是互斥的,性能先对较差):http://blog.codeg.cn/2016/01/27/double-buffering/
双buffer的三种实现方案:https://juejin.cn/post/6844904130989801479
一写多读:https://blog.csdn.net/lqt641/article/details/55058137
高并发下的系统设计:https://www.cnblogs.com/flame540/p/12817529.html
基于shared_ptr的实现,原理也是计数器,但感觉还是有缺陷:https://www.cnblogs.com/gaoxingnjiagoutansuo/p/15773361.html#4998436
转 https://www.cnblogs.com/longbozhan/p/15780194.html