Peeking into the Future: Predicting Future Person Activities and Locations in Videos 翻译
Peeking into the Future: Predicting Future Person Activities and Locations in Videos
原文链接:https://arxiv.org/pdf/1902.03748.pdf
中文版翻译,如有错误,请指正
abstract
解密人类的想法来预测他们未来的路径/轨迹在很多应用中是非常重要的。基于这种想法,这篇文章结合未来的活动研究了如何预测一个行人的未来路径。我们提出了一个端到端的,使用有关人类丰富视觉特征信息并结合环境交互的多任务学习系统。为了简化训练,该网络通过预测活动发生的未来位置这一辅助任务来学习。实验结果表明我们的实验结果是最好的,胜过目前两个公开的未来轨迹预测基准。此外,我们的理论在预测未来路径之外,还可以用来产生有意义的未来行为预测。该结果首次提供了路径和活动联合建模有利于未来路径预测的经验证据。
1. Introduction
随着深度学习的发展,系统现在能够分析视频中前所未有的大量丰富的视觉信息,从而避免事故和实现智能个性化服务。未来人的路径/轨迹预测问题越来越受到计算机视觉界的关注[1,7,13]。它已经被视作计算机视觉理解的重要基石,因为使用过去的视觉信息来预测未来的行为在很多领域有非常广泛的作用,比如自动驾驶领域,有社会意识的机器人研究领域[19]等等。
人类在公共空间中穿行时,脑子里往往有特定的目的,从简单的进入房间,到更复杂的把东西放进车里的行为,如是种种。 尝试着思考 <图 1> 中右上角的人,他可能采取不同的路径,这取决于他的意图。举个例再来说,他可能沿着绿色的道路把货物运送过去,或者沿着黄色的道路把货物放在车上。受此启发,本文有兴趣在视频中结合这样的意图来建模未来的路径。我们根据NIST提供的预定义的29项活动(如“装在货物”、“搬运目标”)来建模意图。<图表 4> 中展示了与此有关的全部列表

< 图1 > 目的是联合预测一个人的未来路径和行为,绿线和黄线代表的是两种未来可能的轨迹和两种可能的行为(分别写在绿色和黄色的框中),比如说,绿色的框中写着:未来的行为是–货物转移;同样的,黄色的框中写到:未来行为–货物装载
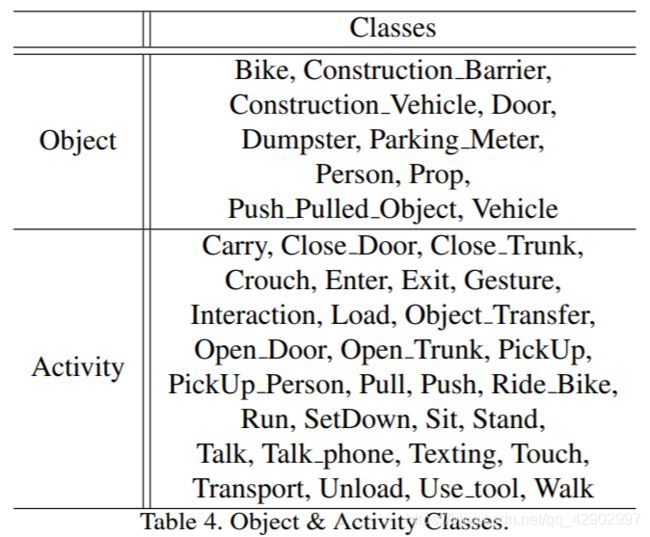
< 图表4 > 未来目标 / 行为的分类
联合预测的模型有如下两个好处。
第一个是:将活动与路径一起学习,有助于未来的路径预测。通过直觉,人类能够通过他人的肢体语言来预测他们是要过马路还是继续沿路行走。在理解了这些行为之后,人类可以做出更好的预测。比如在 < 图1 > 中,那个人拿着一个盒子,同时,左下角的那个人正在向那个人挥手;基于常识,我们可能会同意这个人会选择绿色的路而不是黄色的路。
第二个是:该模型考虑了视频中丰富的语义环境,提高了对未来路径和未来活动的理解能力这增加了自动视频分析的功能,如实时事故报警、自动驾驶汽车和智能机器人辅助;它也可能有安全应用,如预测行人在交通路口的移动,或者是道路机器人可以帮助人们把货物运送到后备箱。
请注意,我们的技术主要用于预测未来的几秒钟,不应该用于非常规活动
为了这个目的,我们提出了一个叫做“ next ” 的模型, 它具有预测模块,可以同时学习未来路径和行为。由于预测未来的活动是具有挑战性的,我们介绍了两种新技术来解决这个问题:
第一个:与目前那些只把人看作空间中一个点的方法[13, 1, 7, 26, 21,31]不同,我们通过丰富的语义特征来对人进行编码。这些语义特征包括视觉外观、身体动作和与周围环境的互动,我们如此考虑的动机是人类通过类似的视觉线索来进行预测。
第二个:其次,为了便于训练,我们引入了未来活动预测的辅助任务,即活动位置预测。在辅助任务中,我们设计了一个离散网格,我们称之为曼哈顿网格作为系统的位置预测目标。实验表明,该辅助任务提高了未来路径预测的准确性。
据我们所知,我们的工作是第一次在视频中联合未来路径和活动预测;更重要的是,我们首次演示并证明了这种联合建模方法可以大大提高未来的路径预测的效果。我们在两个baseline上对我们的模型进行了实证验证:ETH&UCY[23, 16] 以及 ActEV/VIRAT[22, 3]实验结果表明,我们的方法优于最先进的baseline,实现了两个共同benchmarks上的最佳结果,并对未来的活动产生了额外的预测。总之,本文的贡献有三方面:
i)我们在视频中进行了联合未来路径和活动预测的初步研究(pilot study) 我们是第一个从经验上证明这种联合学习的好处的
ii) 我们提出了一个包含新技术的多任务学习框架来解决联合未来路径和活动预测的挑战
iii) 我们的模型在两个公共benchmarks上达到了已知所有方法的最佳性能。ablation studies验证了所提出的子模块的贡献。
2. related work
使用person-person的模型进行轨迹预测 (person-person models for trajectory prediction)
person-person的轨迹预测模型试图预测人们(主要是行人)未来的轨迹。大量的工作来学习如何通过考虑人在拥挤场景[32, 34]中的社会互动和行为来预测人的路径。Zou [36]等人通过模仿决策过程来学习人类在群体中的行为;Social-LSTM[1] 增加了社交池(social pooling)来模拟附近的行人轨迹模式;Social-GAN[7] 通过增加了Social-LSTM 上的对抗性训练来提高效果。与以往的研究不同,我们用丰富的视觉特征来代表和描述一个人而不是简单地将人看作场景中的一个点。与此同时,我们使用几何相关(geometric relation) 来精确模拟人与场景的交互(person-scene interaction)和人与对象的关系(person-object relations),这在之前的研究中是从来没有使用过的。
使用person-scene模型进行轨迹预测 (person-scene models for trajectory prediction)
很多工作更加关注于学习物理场景所带来的影响,比如:人更倾向于走在人行道上而不是走在草坪上。Kitani[13] 等人采用反强化学习预测人体运动轨迹; Xie[31]等人将行人视为“粒子”,其运动动力学是在拉格朗日力学框架内建模的。Scene-LSTM [21]将静态场景划分为曼哈顿网格,利用LSTM预测行人位置;CAR-Net[12] 提出了一种基于场景语义CNN的注意网络来预测人的轨迹。SoPhie[26] 结合场景语义分割模型和生成式对抗网络(GAN)的深度神经网络特征,使用“注意(attention)”建模人的轨迹。与 [26]方法的不同之处在于,我们明确地在每个人周围的场景语义特征,以便模型可以直接从这些交互中学习。
使用人的视觉特征来进行轨迹预测(person visual features for trajectory prediction)
最近的一些研究试图利用个体的视觉特征来预测人的路径,而不是将其视为场景中的点。例如:Kooij[14] 等人通过观察行人的面部来建模他们的意识,并使用动态贝叶斯算法网络预测在dasho-cam 视频中人们是否会过马路。Yagi[33] 等人在第一人称视频中使用带有卷积神经网络的“关键点(keypoint)”特征来预测未来路径。与这些研究不同的是,我们考虑未来预测的丰富的视觉语义,包括人的行为和他们之间的互动。
活动预测/早期识别(activity prediction / early recognition)
利用递归神经网络(RNN)预测未来人类行为的研究已经有了很多成果。[20]和[2]文章中提出了不同的损失方式来鼓励LSTM尽早识别网络视频中的行为。Srivastava [29]等人利用无监督学习和LSTM来重建和预测视频表现;另一项工作是预测机器人视觉[15, 10]中的人类活动。我们的工作的不同之处在于,人的行为和人的交互建模都被用于联合活动和轨迹预测。
多个线索用于跟踪 / 群体(group activity)活动识别 (multiple cues for tracking / group activity recognition)
之前有研究将视频中的多个线索纳入跟踪[11, 25]和群体活动识别[5, 28, 27]中;我们的工作不同之处在于:丰富的视觉特征和“注意力机制”被用于联合人的路径和活动预测。同时,我们的工作利用新型活动定位预测(参见3.5节:activity prediction)来连接这两个任务
3. Approach
人类在空间中穿行时,脑子里往往有特定的目的。这些目的可以在很大程度上确定未来的轨道;这激发了我们联合研究“未来路径预测”与“人的意图”。在本文中,我们将意向建模为一组预定义的未来活动,如“散步”、“开门”、“谈话”等
问题公式化(problem formulation)
在[1, 7, 26]之后:
1.我们假设先对每个场景进行处理,得到所有人在不同时刻的空间坐标
2.根据坐标,我们可以自动提取它们的边界框。
3.我们的系统观察从时间1到Tobs所有人的边界框,如果有对象也是同样的处理(观察从时间1-Tobs的边界框);接下来,预测它们在时间Tobs+1到Tpred的位置(以xy坐标表示);同时,对处于Tpred时刻的未来活动标签的可能性进行预测。
3.1网络架构(network architecture)
< 图2 > 展示了 “ next ” 网络的整个网络架构
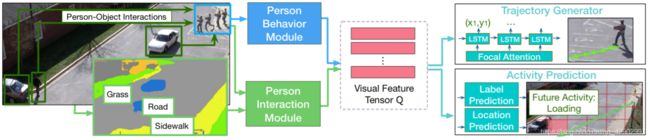
< 图2 > 模型概述。该模型利用人的行为模块和人的交互模块将丰富的视觉语义编码成一个特征张量。提出了一种新型的同时考虑人-景和人-物关系的交互模块,用于联合预测未来的活动和位置
不像大多数现有的研究[13, 1, 7, 26, 21, 31],我们的模型使用两个模块来编码关于每个人的行为以及与周围环境的交互作用的丰富视觉信息。综上所述,其主要组成部分如下:
人类行为模块(Person behavior module):
从人的行为序列中提取视觉信息
人类交互模块(Person interaction module):
观察人和周围环境之间的相互作用
轨迹产生模块(Trajectory generator):
利用有注意机制(focal attention)LSTM解码器[17],重点总结了编码的视觉特征,预测未来的发展轨迹
行为预测模块(Activity prediction):
利用丰富的视觉语义来预测人未来的活动标签。此外,我们将场景划分为一个多尺度的离散网格,我们称之为曼哈顿网格,以计算分类和回归来进行稳健的活动位置预测。在本节的其余部分,我们将详细介绍上述模块和学习目标。
3.2 人类行为模块(Person behavior module):
该模块对场景中每个人的视觉信息进行编码。相对于将一个人过于简化地描述为空间中的一个点,我们模拟了这个人的外貌和身体动作。为了模拟一个人外貌的变化,我们使用了一个预训练的对象检测模型 “RoIAlign”[8] 来提取每个人包围框(bounding box)中固定大小的CNN特征。通过 < 图3 >,可以看到,对于每一个场景中的人,我们沿着空间维度(spatial dimensions)对特征进行平均,并将它们输入到LSTM编码器中。 最后,我们得到 Tobs × d 的特征表示,d 是 LSTM 的隐藏尺寸(hidden size)。为了捕获身体运动,我们使用了一个在MSCOCO[6]数据集上训练的人物关键点检测模型(keypoint detection model)来提取人的关键点信息。在输入LSTM编码器之前,我们应用线性变换(linear transformation)来嵌入关键点的坐标。编码特征的尺寸(shape)是Tobs × d 这些外观和运动特征通常被广泛应用于各种研究中,因此不会引入对机器学习公平性的新问题。
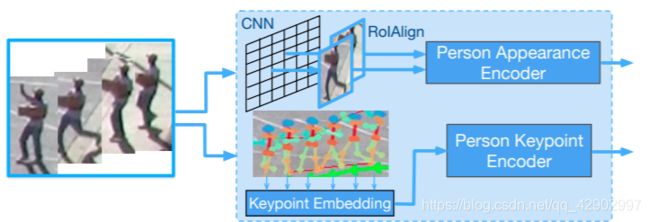
< 图3 > 展示了人类行为模块,这个模块里面包含了一系列与人类行为有关的帧。我们提取人的外貌特征和姿态特征来模拟一个人的行为变化。
3.3人与环境交互模块(person interaction module)
本模块研究人与环境的交互,即人-场景(person-scenes)、人-对象(person-objects)交互。
人与场景交互: 为了对人附近的场景进行编码,我们首先使用一个预先训练好的场景分割模型[4]来提取每个帧的像素级场景语义类。使用总共 Ns = 10 个常见的场景类,如道路,人行道等。场景语义特征为整数(类指标),尺寸为: Tobs × h × w, h , w 分别是空间分辨率。我们首先把整数张量转换成Ns二元掩膜(每个类一个掩膜)然后沿时间维度做平均。 这就产生了Ns实值掩膜,每个掩膜的大小为 h × w。我们在掩膜特征图(mask feature)上应用两个卷积层(convolutional layer), 步长(stride)为2,得到两个尺度的场景CNN 特征。
给定一个人的xy坐标,我们从卷积特征图中 汇集并融合 此人当前位置的场景特征,如 < 图4 > 底部所示,卷积特征的红色部分是人在当前时刻的离散化位置,特征的感受野在每个时刻都是即时的,即:这个模型所观察的人周围的空间窗口的大小,取决于哪一个比例(scale)是经过哪一个池(pool)以及卷积核(kernel size)的大小(the size of the spatial window around the person which the model looks at, depends on which scale is being pooled from and the convolution kernel size)。在我们的实验中,我们将scale设置为1,将kernel size设置为3 这意味着我们的模型在每个瞬间会观察人周围 3 × 3 的区域。一个人的人-场景(person-scene)表示是: R T o b s × C \mathbb R^{T_{obs}×C} RTobs×C, C C C 是卷积层中的通道数。我们将其输入到 LSTM 编码器中,以捕获时间信息并获得最终 R T o b s × d \mathbb R^{T_{obs}×d} RTobs×d 人员场景特性。
人与对象交互(person-objects): 不像以往的很多研究[1, 7]依赖于LSTM隐藏状态对附近的人进行建模,我们的模块明确地对场景中所有 对象/人的几何关系和对象类型进行建模。任意时刻,给定场景 {(xk, yk, wk, hk) | k∈ (1, K) } 中一个人 (xb, yb, wb, hb) 和 K 个其他对象 / 人 的观测框, 我们将几何关系编码到 G∈RK×4 中, 其中第 k 行等于:
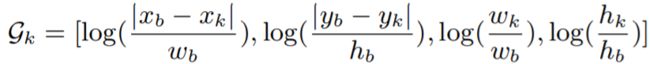 <公式1>
<公式1>
该编码根据几何距离和分式来计算几何关系,我们使用对数函数来反映我们的观察结果,即人类的轨迹更有可能受到附近物体或人的影响,这种编码方式已经被证明在目标检测中是有效的。对于对象类型,我们只需使用独热编码(one-hot encoding)来获得RK×No 维的特性,No 是对象类的总数;然后我们将当前的几何特征和对象类型特征嵌入 de 维向量中;然后将嵌入的特征输入LSTM编码器,得到最终 Tobs × d 维特征的。
如 < 图4 > 所示,人与物体(person-objects)特性可以捕获人与另一个人或者与车之间的距离(相对于他们自己的高度)。人景(person-scene)特征可以捕捉到一个人是否靠近人行道或草地。我们把这些信息输入到模型中,希望能学到一些东西,比如一个人在人行道上走的次数比在草地上走的次数要多,并且避免撞到汽车。
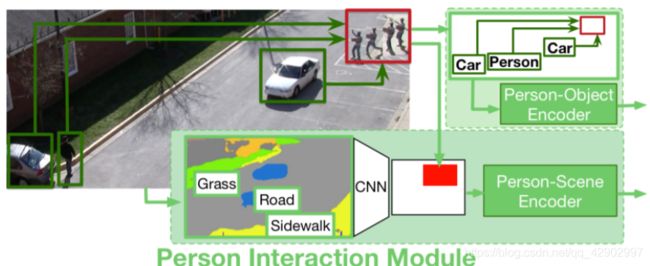
< 图4 > 给出了人机交互模块,包括人-场景(person-scenes)和人-对象(person-objects)建模。在人- 对象(person-objects)建模中,将人序列作为视频帧中的红框,提取人与其他对象在各时刻的空间关系。对于人-场景(person-scenes)建模,将围绕人的场景语义特征汇集到编码器中。参见3.3节
3.4 轨迹生成与焦点关注机制(trajectory generation with focal attention):
如前所述,上述四种类型的视觉特征,即外观(appearance)、身体(body movement)移动、人-场景(person-scene)和人物-对象(person-object),是由不同的LSTM编码器编码成相同的维度;另外,给定一个人最后时刻的轨迹输出,我们可以通过以下公式提取出轨迹嵌入:
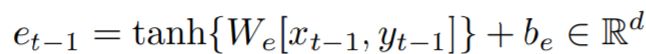 <公式2>
<公式2>
[xt−1,yt−1] 是时间 t−1 时刻的轨迹预测;be 和 We 是可学习的参数;然后我们将 et-1 嵌入到另一个LSTM编码器中,以获得轨迹;所有编码器的隐藏状态被压缩成一个名为Q的张量 Q∈RM×Tobs×d,M = 5 表示特征的总数, d 为LSTM的隐藏的大小。
在[7]之后,我们使用LSTM解码器来直接预测未来在xy坐标下的轨迹。使用"人的轨迹"的LSTM编码器的最后状态来初始化这个解码器的隐藏状态—the hidden state of the decoder is initialized using the last state of the person’s trajectory LSTM encoder. 在每一次瞬间,系统将根据解码器状态 ht=LSTM (ht−1 [et−1, q˜t ]) 和全连接层来计算xy的坐标。q˜t是一个重要的加注意的特征向量(important attended feature vector),被用来总结输入特征Q中的重要线索 为此,我们采取了有效的 添加注意(focal attention)[17] 的办法;提出了对一组图像进行多模态推理(multimodal inference)来从而进行可视化的问题回答。其关键思想是将多个特征投射到一个相关空间中(a space of correlation),使识别性特征(discriminative features)更容易被注意机制捕获。为此,我们在每一个时间点 t 计算一个相关矩阵St ∈ RM×Tobs 其中每个通道
![]()
是使用点积相似性度量的,: 是一个从该维度中提取所有元素的切片操作符。然后我们计算两个焦点注意矩阵:
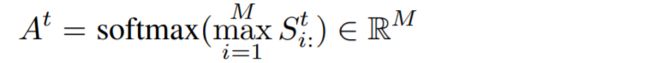 <公式3>
<公式3>
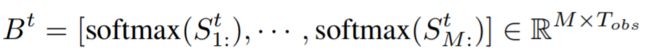 <公式4>
<公式4>
加注意的特征向量为:
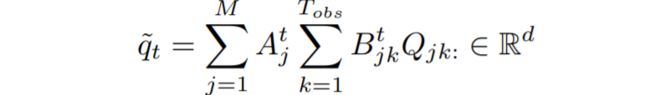 <公式5>
<公式5>
如图所示,焦点注意模型建立了不同特征之间的相关关系,并将它们归纳为一个加注意的特征向量。第四部分通过实验验证了该方法的有效性。
3.5行为预测(activity prediction):
由于轨迹产生模块每次产生一个定位,错误可能随着时间积累,从而导致最后的预测位置产生较大的偏差;使用错误的位置进行活动预测可能会导致较差的准确性。为了克服这个缺点,除了预测人未来的活动标签(future activity lable of the person),我们还引入了一个辅助任务,即活动位置预测(activity location prediction)。我们将在下文中描述这两个预测模块。
使用曼哈顿网格进行活动位置预测(Activity location prediction with the Manhattan Grid):
为了弥补轨迹生成(trajectory generation)和活动标签预测(activity lable prediciton)之间的差距,我们提出了一个活动位置预测模块(Activity location prediction )来预测人在未来活动中的最终位置。活动位置预测包括两个任务:位置分类(location classification)和位置回归(location regression)。
如 < 图5 > 所示,我们首先将视频帧划分为离散化的 h × w 网格,即Manhattan网格 ,学习正确划分网格块,同时从网格块的中心回归到实际位置。具体来说,分类任务的目标是: 预测最终位置坐标所在的正确网格块。对网格块进行分类后,回归任务的目标是: 预测网格块中心(图中的绿点)到最终位置坐标(绿箭头的末端)的偏差。添加回归任务的原因如下:
i) 与只提供区域范围相比,这种方法明显更加精准
ii) 这对于需要xy坐标定位来进行轨迹预测的系统来说是互补的
我们在不同尺寸的曼哈顿网格上重复这一过程,并使用不同的预测前端(prediction head)对它们进行建模;这些预测前端与模型的其余部分端对端进行训练。我们的想法部分受到了region proposal network[24] 网络的启发,我们的直觉是,与对象检测问题类似,我们需要以一种经济有效的方式使用多尺度特征进行精确定位。
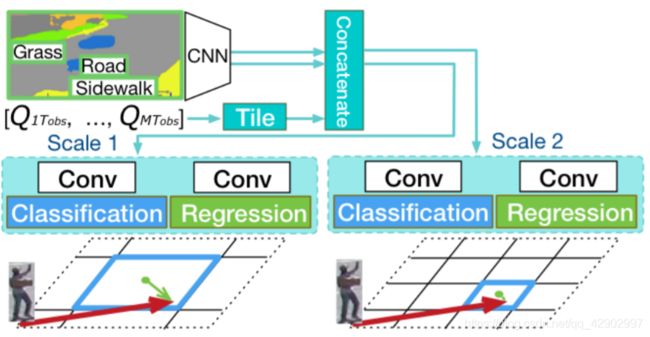
< 图5 > 基于多尺度曼哈顿网格的分类和回归的活动位置预测。参见3.5节。
如 < 图5 > 所示,我们首先将场景CNN特征(参见3.3节)与编码器的最后一个隐藏状态(参见3.4节)连接起来。为了兼容性,我们沿着高(height)和宽(width)的维度 平铺(tile) 了隐藏状态 Q:Tobs: 产生了一个 M × d × w · h的张量;w · h 是网格块的总数。隐藏状态包含了来自所有编码器的丰富信息,允许梯度从预测(prediction)编码器平滑地流向特征编码器(feature encoder)。
将 连接后的特征(concatenated) 分别输入两个独立的卷积层进行分类和回归。用于网格分类的卷积输出 clsgrid ∈ Rw·h×1
标志着每个网格块成为正确定位(correct destination)的概率。相比之下,网格回归的卷积输出 rggrid∈R w·h×2 表示最终目的地与每个网格块中心在xy坐标系下的偏差。rggrid的一行表示与网格块的差异,从 [xt−xci, yt−yci] 计算,其中 (xt, yt) 表示预测位置,(xci, yci) 是第 i 个网格块的中心。同样地,可以用类似的方法计算网格回归的ground truth。在训练过程中,只有正确的网格块接收梯度进行回归,最近的工作[21]也将网格用于位置预测。我们的模型的不同之处在于我们将网格位置与场景语义联系起来,并使用一个分类层和一个回归层来进行更可靠的预测。
活动标签预测(activity label prediction):
活动标签预测模块根据已编码的视觉观测序列,实时预测 Tpred 时刻的未来活动。我们使用联合的最后隐藏状态的编码器来计算未来活动 Na 的概率:
![]() <公式6>
<公式6>
Wa是一个可学习的权重。一个人未来的活动可以是多级的,例如一个人可以同时“行走”和“搬运”。
3.6. 训练(Training):
整个网络通过最小化一个多任务目标来进行端到端的训练。主要被使用在预测的未来轨迹和ground truth轨迹[21, 7, 26]之间的损失是常见的 L2 损失。从Tobs+1 到 Tpred 之间所有人员的损失之和为 Lxy。
第二种损失是行为预测分类和回归的损失(在3.5节中涉及)。
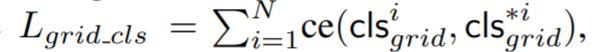
其中 cls*igrid 是 ground truth最终定位网格第 i 个训练轨迹的ID,同样地:
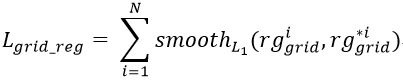
rg∗igrid 是 ground truth 与正确的网格中心的差异;这种损失是为了弥补轨迹生成任务和活动标签预测任务之间的差距。
第三种损失是为了 活动标签预测 而设计的损失,这里使用了交叉熵损失函数:
![]()
最后,综合损失的损失计算方法如下:
![]() <公式7>
<公式7>
我们在训练过程中为目标位置的预测部分引入一个平衡控制器λ = 0.1,以抵消他们可能存在的更高损失值的情况。
4.Experiments
我们在未来路径预测的两个常见benchmarks 上对所提出的 “next” 模型进行了评估: ETH[23] 和 UCY[16] 以及 ActEV / VIRAT[3, 22]。我们证明了我们的模型在这个具有挑战性的任务中比最先进的模型表现更好。源代码和模型将向公众开放。可以见:https://github.com/google/next-prediction
4.1ActEV/VIRAT
数据集和设置(Dataset & Setups)
ActEV/VIRAT[3]是NIST于2018年发布的用于视频活动检测研究的公共数据集(https://actev.nist.gov/),这个数据集是VIRAT[22]的改进版本,包含更多的视频和注释。它包括455个视频,每秒30帧,来自12个场景,总时长超过12个小时。大多数视频的分辨率都是1920x1080。我们使用官方训练集进行训练,并使用官方验证集进行测试。
以下[1, 7, 26],模型观察每个人3.2秒(8帧),预测未来4.8秒
(12帧)人的轨迹,我们将视频采样到2.5帧每秒,并使用 [7] 中发布的代码提取人的轨迹。因为我们没有单应性矩阵(homographic matrix),所以我们使用轨迹坐标的像素值,就像在[33] 中所做的那样。
评价指标(Evaluation Metrics)
根据此前工作[1, 7, 26],我们使用两个误差指标来预测人的轨迹:
i) 平均位移误差(ADE):ground truth 坐标与预测坐标在整个时间段的平均欧式距离。
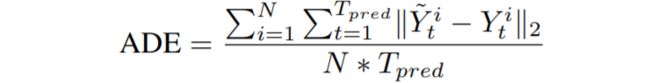 <公式8>
<公式8>
ii) 最终位移误差(FDE):在最终预测时间瞬时Tpred,预测点与ground truth point 之间的欧氏距离。
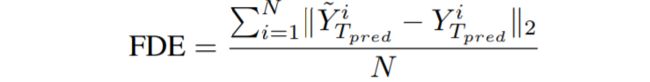 <公式9>
<公式9>
在数据集ActEV / VIRAT上,误差测量实在像素空间中,但是在ETC和UCY中,误差测量以meter(米)为单位;对于未来的活动预测,我们使用平均精度(mAP)。
baseline方法:
我们将我们的方法与两个简单的baseline方法和两个最近的方法进行比较: Linear: 是一个单层模型,它使用一个基于前一个输入点的线性回归器来预测下一个坐标;LSTM: 是一个简单的LSTM编译码器模型,只输入坐标;Social LSTM[1]: [1] 我们训练 Social LSTM 模型来直接预测轨迹坐标而不是使用高斯参数;SGAN[7]:[7]我们训练了两个模型变量(PV&V)论文中详细使用了Social-GAN[7]发布的代码(https://github.com/agrimgupta92/sgan/)
除了在测试时使用单个模型外,Gupta 等人[7] 每帧使用20个模型输出,并选择最好的预测来计算最终的性能。根据实践,我们使用随机初始化训练了20个相同的模型,并报告了评估结果,这些结果在 < 表1 > 中标记为“20个输出”
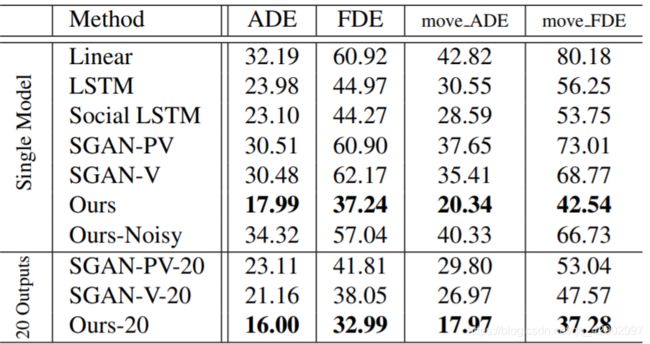
< 表 1 > 与ActEV / VIRAT验证集上的 baseline 方法进行比较。上面的部分使用的是单个模型输出。底部的部分使用20个输出。数字表示错误,因此越低越好。
实现细节(implementation details)
我们对编码器和解码器都使用LSTM单元。嵌入尺寸 de 设置为128,编码器和解码器的隐藏尺寸 d 均为256。在观察期间(从时间 1 到 Tobs )使用人(person)和对象(objects)的ground truth边界框。对于人物关键点(keypoints)特征,我们使用来自[6]的预训练的姿态估计器为每个ground truth人物框提取17个关节。对于人的 外貌特征,我们利用预先训练好的目标检测模型FPN[18]从人的包围框bounding box中提取外貌特征。将场景语义分割特征调整为 (64,36) ,场景卷积层的核大小(kernel size)设置为3、步长(stride)为2,通道尺寸(channel dimension)为64。我们将所有视频的大小调整为1920x1080,并使用两中不同尺寸的网格,32 x18 和16 x 9。如果没有另外说明,激活函数是tanh,我们不使用任何标准化。训练的时候,我们使用 Adadelta 优化器[35],初始学习率 (learning rate) 为0.1,dropout 的值为0.3。我们设置梯度剪裁(gradient clipping)为10 和权重衰减(weight decay)为0.0001。对于Social LSTM,邻域设置为256像素,如[33]所示。所有baseline使用与我们的模型相同的嵌入尺寸和隐藏尺寸(LSTM);因此,所有的编解码器模型都具有相同数量的参数,我们用于 baseline 的其他超参数遵循[7]中的设定。
主要成果(main results)
< 表1 > 列出了测试误差,上半部分是单个模型输出的误差,下半部分是20个模型输出的最佳结果;“ADE” 和 "FDE"这两列列总结了所有轨迹上的误差,最后两列进一步详细描述了移动活动的子集轨迹:(“走”,“跑”,“骑自行车”等行为)。我们可以在第7行看到单个模型运行20次的平均性能。ADE度量的标准偏差为0.043。完整的数字可以在补充材料中找到。正如我们所看到的,我们的方法在预测运动轨迹方面优于其他方法;例如,我们的模型在“move_FDE”指标上比Social-LSTM和Social-GAN高出10个百分点。结果表明了该模型的有效性及其在未来轨迹预测中的顶尖表现。此外,作为迈向实际应用的一步,我们使用观测期间的目标检测和跟踪的含噪(noisy output)输出来训练我们的模型。为了进行评估,按照[30]进行正常训操作之后,对于每一个轨迹,我们假设时刻 1 的时候人边界框的位置接近groud truth的位置,然后我们使用从时间 1 到 Tobs 的跟踪输入和其他视觉特性来评估模型预测,如**< 表1 >**中 “Ours-Noisy” 所示。
定性分析(qualitative analysis)
我们在 < 图6 > 中可视化并比较我们的模型输出和基线。在每个图中,黄色的轨迹是可观察的每个人的序列,绿色的轨迹是ground truth的未来轨迹;预测的轨迹显示在蓝色的热图中。为了更好地可视化我们的方法预测的未来活动,我们在预测轨迹的末端为每个预测的活动绘制人物的关键点模板。如我们所见,我们的方法为每个人输出更精确的轨迹,尤其是图中右边的两个人,他们正准备加速他们的行动,我们的方法也能够预测大多数活动的正确性,除了一个(步行与跑步)。我们的模型成功预测了车附近人的“搬运”活动和静止轨迹,如 < 图6 c > 所示,SGAN预测了几种不同方向的运动轨迹。
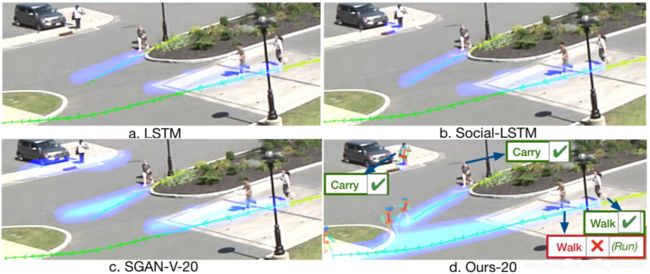
< 图6 > (彩色效果更好) 我们的方法和基线的定性比较。黄色轨迹为可观测轨迹,绿色轨迹为预测期内的ground truth 轨迹。预测显示为蓝色热图。我们的模型还通过预测了未来的活动并通过人物关键点的模板显现出来,这部分在原文中有详细描述
我们进一步对我们的模型预测进行了定性分析:
i) 成功案例:在 < 图7(a) > 和 < 图7(b) > 中,轨迹预测和未来活动预测都是正确的。
ii) 不完美案例:在 < 图7 c > 中,虽然轨迹预测大部分是正确的,但我们的模型预测的是:人应该走过去打开车门,因为根据观察这个人朝着车的一侧走过去。
iii) 失败案例:在 < 图7(d) > 中,我们的模型没有捕捉到两人之间微妙的互动,并预测他们会分道扬镳,而实际上他们停下来并互相交谈。
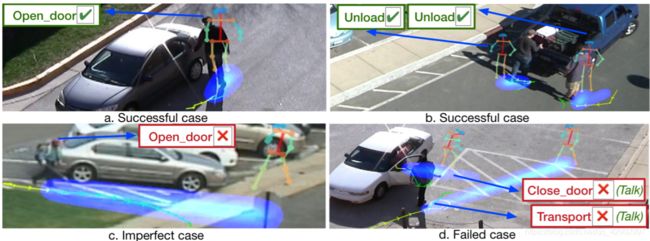
< 图7 > (彩色效果更好) 定性分析我们的模型。
4.2 消融模型(Ablation Model)
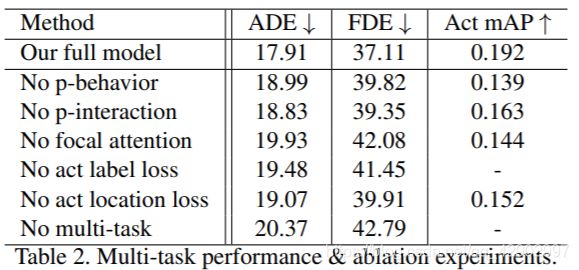
< 表2 > 多任务性能 & 消融实验
注明: 消融研究通常指的是去除模型或算法的某些“特征”,并观察这些特征如何影响性能(An ablation study typically refers to removing some “feature” of the model or algorithm, and seeing how that affects performance.)
在 < 表2 > 中,我们通过一系列消融实验(ablation experiments)系统地评价了我们的方法,其中“ADE”和“FDE”表示误差所以他们的值越低越好。“Act”是29项活动中活动标签预测的平均平均精度(mAP),越高越好。
功能丰富的视觉特征(efficacy of rich visual features)
我们通过分别研究了人的行为和人的互动的对于特征的贡献。如 < 表2 > 前三行所示,这两个特征对轨迹预测都很重要,而人的行为特征对活动预测更为重要 < 表7 > 显示了各个特征的消融情况
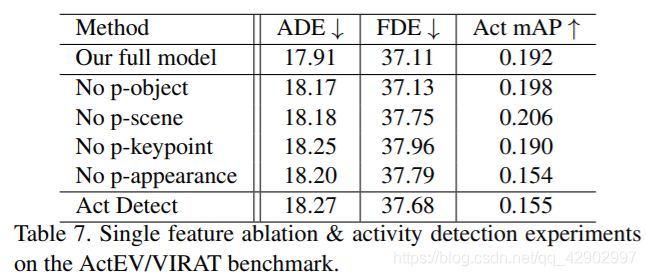
< 表7 > 在ActEV/VIRAT baseline 上进行单特征消融和行为检测实验。
注意机制的影响(effect of focal attention)
在 < 表2 > 的第4行,我们将 <公式5> 中的焦点注意替换为所有编码器的最后隐藏状态的简单平均值。结果,轨迹和活动预测都受到了伤害。
多任务学习的影响(Impact of multi-task learning)
在 **< 表2 >**的最后三行,我们去掉了用于预测活动标签或活动位置或同时用于两者的多重任务,以查看多任务学习的影响。实验结果表明了该方法的优越性。
4.3 ETH & UCY
数据集(Dataset)
ETH[23]和UCY[16]是常用的人体轨迹预测基准数据集[1,7,21,26]。与以前的工作一样[1,7,21,26],我们通过对两个数据集进行平均来得出性能。我们使用与[7]中详细介绍的相同的数据处理方法和设置。这个benchmark 包括五个场景的视频:ETH、HOTEL、UNIV、ZARA1和ZARA2。我们使用了单场景数据分割(Leave-one-scene-out data split),并在5组数据上对我们的模型进行了评估。我们遵循与前一节相同的测试场景和 baseline,我们还引用了来自[26]的最新成果。由于 1 个视频不能下载,我们在UNIV 上使用了一个更小测试集的,在每一个训练分裂处设置一个更小的训练集。其他 4 个测试子数据集与[7]中的相同,因此这些数据更具有可比性。
由于没有行为标注(activity annotation),我们在模型中没有使用行为标签预测模块(activity label prediction module)。由于注释对于每个人来说只是一个点,并且每个视频中的人尺度变化不大,所以我们对每个视频的点进行固定大小的扩展,得到用于特征池(feature pooling)的人的边界框注释;我们不使用任何其他边界框。我们不使用任何附加的注释来与 baseline 进行比较,以确保一个公平的比较。
实现细节(Implementation Details)
我们不使用人员关键点特征(person keypoint feature)。但我们使用“最后位置损失(Final location loss)” 和 “轨迹L2损失(trajectory L2 loss)”。
与[26]不同,我们没有利用任何数据扩充。我们用adadelta优化器训练我们的模型40个epoch。其他超参数与 4.1节 相同
结果与分析(Results & Analysis)

< 表3 > 不同方法在ETH (第3列和第4列)和UCY数据集(第5列到第7列)上的比较。*由于1个视频无法下载,我们在UNIV上使用了一个更小的测试集。
实验结果如 **< 表3 >**所示。我们的模型在两个评估中都优于其他方法,其中我们获得了ETH上已发表的最好的单个模型性能和ETH & UCYbaseline 上的平均最佳性能。如表所示,我们的模型在HOTEL和ZARA2上的表现要好得多。在这两个场景中,每一时刻的平均移动分别为0.18 (HOTEL)和0.22(ZARA2),远低于其他场景: 0.389 (ZARA1), 0.460(ETH), 0.258(UNIV)。回头再看,在训练中使用单场景数据分割(leave-one-scene-out data split)。结果表明,其他方法有更大概率对大幅度运动轨迹过度拟合,例如 Social-GAN[7] 在预测未来轨迹时经常“超拟合”。相比之下,我们的方法使用注意力来寻找“正确”的视觉信号,并在HOTEL和ZARA2数据集的小运动轨迹上显示出更好的性能,同时在大运动轨迹上仍然具有竞争力。
5.Conclusion
在本文中,我们提出了一种新的神经网络模型来同时预测人类的轨迹和未来的活动。我们首先通过丰富的视觉特征对人进行编码,捕捉人的行为和与周围环境的互动。然后我们增加了一个辅助任务,预测活动地点,以方便联合训练过程,我们将得到的模型称为“Next”。我们展示了我们的模型同时在流行的与大规模视频baseline上对人的轨迹预测的有效性。此外,我们定量和定性地证明了我们的“Next”模型成功地预测了有意义的未来活动。
我们的研究目标是在机器人或自动驾驶等应用中促进人类安全,我们在公共benchmark ActEV上进行了实验,其主要目的是通过流媒体视频(https://actev.nist.gov/1B-Evaluation)中的自动活动检测来支持公共安全和交通监控管理。我们的方法工作在NIST提供的预定义的30个活动集上,比如“装载货物”、“运输物体”。完整列表见 < 表4 > 。我们的系统可能无法工作超出这些预定义的活动。
未来对活动和路径预测的研究可能涉及隐私、安全和公平等伦理问题,在应用于现实世界之前应该仔细考虑。我们预测轨迹和活动的方法还没有在不同人群中测试过。因此,在将模型用于可能对人产生不同影响的情况之前,对这些问题进行进一步评估是很重要的。
References
[1] A. Alahi, K. Goel, V. Ramanathan, A. Robicquet, L. Fei-Fei, and S. Savarese. Social lstm: Human trajectory prediction in crowded spaces. In CVPR, 2016. 1, 2, 3, 4, 6, 8
[2] M. S. Aliakbarian, F. Saleh, M. Salzmann, B. Fernando, L. Petersson, and L. Andersson. Encouraging lstms to anticipate actions very early. 2017. 2
[3] G. Awad, A. Butt, K. Curtis, J. Fiscus, A. Godil, A. F. Smeaton, Y. Graham, W. Kraaij, G. Qunot, J. Magalhaes, D. Semedo, and S. Blasi. Trecvid 2018: Benchmarking video activity detection, video captioning and matching, video storytelling linking and video search. In TRECVID, 2018. 2, 6
[4] L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV, 2018. 3
[5] W. Choi and S. Savarese. Understanding collective activitiesof people from videos. IEEE transactions on pattern analysis and machine intelligence, 36(6):1242–1257, 2014. 2
[6] H.-S. Fang, S. Xie, Y.-W. Tai, and C. Lu. RMPE: Regional multi-person pose estimation. In ICCV, 2017. 3, 6
[7] A. Gupta, J. Johnson, S. Savarese, Li Fei-Fei, and A. Alahi. Social gan: Socially acceptable trajectories with generative adversarial networks. In CVPR, 2018. 1, 2, 3, 4, 5, 6, 8, 9, 12
[8] K. He, G. Gkioxari, P. Dollar, and R. Girshick. Mask r-cnn. In ICCV, 2017. 3
[9] H. Hu, J. Gu, Z. Zhang, J. Dai, and Y. Wei. Relation networks for object detection. In CVPR, 2018. 4
[10] A. Jain, H. S. Koppula, B. Raghavan, S. Soh, and A. Saxena. Car that knows before you do: Anticipating maneuvers via learning temporal driving models. In CVPR, 2015. 2
[11] A. Jain, A. R. Zamir, S. Savarese, and A. Saxena. Structural-rnn: Deep learning on spatio-temporal graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5308–5317, 2016. 2
[12] N. Jaipuria, G. Habibi, and J. P. How. A transferable pedestrian motion prediction model for intersections with different geometries. arXiv preprint arXiv:1806.09444, 2018. 2
[13] K. M. Kitani, B. D. Ziebart, J. A. Bagnell, and M. Hebert. Activity forecasting. In ECCV, 2012. 1, 2, 3
[14] J. F. P. Kooij, N. Schneider, F. Flohr, and D. M. Gavrila. Context-based pedestrian path prediction. In ECCV, 2014. 2
[15] H. S. Koppula and A. Saxena. Anticipating human activities using object affordances for reactive robotic response. IEEE transactions on pattern analysis and machine intelligence, 38(1):14–29, 2016. 2
[16] A. Lerner, Y. Chrysanthou, and D. Lischinski. Crowds by example. In Computer Graphics Forum, pages 655–664. Wiley Online Library, 2007. 2, 6, 8
[17] J. Liang, L. Jiang, L. Cao, L.-J. Li, and A. Hauptmann. Focal visual-text attention for visual question answering. In CVPR, 2018. 3, 4
[18] T.-Y. Lin, P. Dollar, R. B. Girshick, K. He, B. Hariha-ran, and S. J. Belongie. Feature pyramid networks for object detection. In CVPR, 2017. 6
[19] M. Luber, J. A. Stork, G. D. Tipaldi, and K. O. Arras. People tracking with human motion predictions from social forces. In ICRA, 2010. 1
[20] S. Ma, L. Sigal, and S. Sclaroff. Learning activity progression in lstms for activity detection and early detection. In CVPR, 2016. 2
[21] H. Manh and G. Alaghband. Scene-lstm: A model for human trajectory prediction. arXiv preprint arXiv:1808.04018, 2018. 2, 3, 5, 8
[22] S. Oh, A. Hoogs, A. Perera, N. Cuntoor, C.-C. Chen, J. T. Lee, S. Mukherjee, J. Aggarwal, H. Lee, L. Davis, et al. A large-scale benchmark dataset for event recognition in surveillance video. In CVPR, 2011. 2, 6
[23] S. Pellegrini, A. Ess, and L. Van Gool. Improving data association by joint modeling of pedestrian trajectories and groupings. In ECCV, 2012. 2, 6, 8
[24] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In NIPS, 2015. 5
[25] A. Sadeghian, A. Alahi, and S. Savarese. Tracking the untrackable: Learning to track multiple cues with long-term dependencies. In Proceedings of the IEEE International Conference on Computer Vision, pages 300–311, 2017. 2
[26] A. Sadeghian, V. Kosaraju, A. Sadeghian, N. Hirose, and S. Savarese. Sophie: An attentive gan for predicting paths compliant to social and physical constraints. arXiv preprint arXiv:1806.01482, 2018. 2, 3, 5, 6, 8, 12
[27] T. Shu, S. Todorovic, and S.-C. Zhu. Cern: confidence-energy recurrent network for group activity recognition. In IEEE Conference on Computer Vision and Pattern Recognition, volume 2, 2017. 2
[28] T. Shu, D. Xie, B. Rothrock, S. Todorovic, and S. Chun Zhu. Joint inference of groups, events and human roles in aerial videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4576–4584, 2015. 2
[29] N. Srivastava, E. Mansimov, and R. Salakhudinov. Unsupervised learning of video representations using lstms. In ICML, 2015. 2
[30] Y. Wu, J. Lim, and M.-H. Yang. Object tracking benchmark. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37(9):1834–1848, 2015. 7
[31] D. Xie, T. Shu, S. Todorovic, and S.-C. Zhu. Learning and inferring dark matter and predicting human intents and trajectories in videos. IEEE transactions on pattern analysis and machine intelligence, 40(7):1639–1652, 2018. 2, 3
[32] Y. Xu, Z. Piao, and S. Gao. Encoding crowd interaction with deep neural network for pedestrian trajectory prediction. In CVPR, 2018. 2
[33] T. Yagi, K. Mangalam, R. Yonetani, and Y. Sato. Future person localization in first-person videos. In CVPR, 2018. 2, 6
[34] S. Yi, H. Li, and X. Wang. Pedestrian behavior understanding and prediction with deep neural networks. In ECCV, 2016. 2
[35] M. D. Zeiler. Adadelta: an adaptive learning rate method. arXiv preprint arXiv:1212.5701, 2012. 6
[36] H. Zou, H. Su, S. Song, and J. Zhu. Understanding human behaviors in crowds by imitating the decisionmaking process. arXiv preprint arXiv:1801.08391, 2018. 2