python数据处理与分析(汇总)
python结构化数据 数据处理与分析
- 导语
-
- 我们所面临的数据
- 1.读取数据
- 2.审视数据
-
- 2.1 整体
- 2.2 局部(单行、列,多行、列)
- 3.数据类型,字段更改
-
- 3.1 字符类(object)处理
- 3.2 时间数据(datetime)处理
- 3.3 数据类型(float,int)处理
- 3.4 分类数据(category)处理
- 3.5 colums,index改变
- 4.缺失值处理
-
- 4.1 查看缺失值情况
- 4.2 删除缺失值
- 4.3 填充缺失值 - 简单填充
- 4.4 填充缺失值 - 随机森林回归填充
-
- python实例
- 5.重复值
- 6.异常值
-
- 6.1 业务的异常值
- 6.2 异常检测算法
- 7.根据业务需求,选择一些数据
- 8.数据抽样
- 9.数据转化
-
- 9.1 归一化
- 9.2 标准化
- 9.3 正则化
- 9.4 LabelEncoder
- 9.5 OneHotEncoder
- 10.数据分组、排序、透视
- 11.map、apply、applymap处理数据技巧
-
- 11.1 处理Series(处理一列、一行数据情况)
- 11.2 处理DataFrame(处理多列、多行或整个数据情况)
导语
在机器学习深度学习项目中,视频,图片,文本,语音,结构化数据
本文基于大量kaggle结构化数据的项目,总结一些,在做机器学习模型时,遇到结构化数据时,如何观察数据情况,如何处理数据,如何对数据进行分析的正确流程和细节
目的是:掌握在数据训练模型之前,给模型一个最好的数据。
我们所面临的数据
在status上数据被定义为面板数据(Panel data),其中面板数据,也分成时间序列数据(Time series data)和截面数据(Cross-sectional data)
x轴为时间,y轴为columns(特征),z轴对应每一行的数据
实际上数据就成为了一个三维的数据透视表,但在实际机器学习数据处理中,我们用到的都是二维的数据,截面数据(Cross-sectional data)。
1.读取数据
实例数据处理,使用kaggle的Titanic数据集进行操作。
dataset
data=pd.read_csv('train.csv')
2.审视数据
2.1 整体
data.head():查看数据集前5行

data.tail():查看数据集倒数5行

data.shape:查看数据集维度

data.dtypes:查看数据集数据类型

data.info():查看数据集基本信息

data.columns:查看数据集列名

data.describe():查看数据集的统计信息

data.isna().sum():查看数据集每一列有无空值
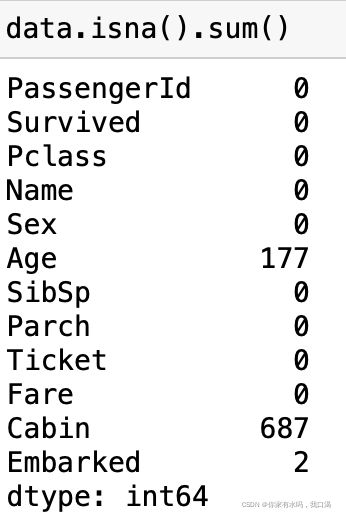
我们只需要用data.info(),data.head(),data.describe(),data.isna().sum()就行,
我们数据 无非就是,int float类(数字)和object类的 (字符、时间)
审视数据的核心目的是:观察各数据字段的数据类型,分清楚连续型数据、分类型数据和时间型数据,看下数据有无缺失的部分。
2.2 局部(单行、列,多行、列)
data.Age、data[‘Age’]:筛选指定列

data.Age.unique():查看列去重下的唯一值

data[‘Age’].value_counts(dropna =False):查看列各值的个数,True为包含,值为空的,False为不包含

data.iloc[4]、data.iloc[0:4]:筛选指定行

data.iloc[:,0:4]、data.iloc[[0,2,4].[3,4]]:筛选指定行,指定列,逗号前是行,后是列

data.sort_values(by=[‘Age’,ascending=True]):按照某一列的值从小到大排序。True为为从小到大,False为从大到小

通过词云,观察字符类的数据的计数:
from wordcloud import WordCloud
cloud = WordCloud(width=1440,height=1080).generate(" ".join(data.Name.astype(str)))
plt.figure(figsize=(8,8))
plt.imshow(cloud)
plt.axis('off')

3.数据类型,字段更改
3.1 字符类(object)处理
在机器学习的特征选择的时候,往往有一些离散的特征不好计算,我们需要用些数值来替换这些字符串。
例如这里的数据集中的Sex,只有二种离散特征 male、female
data.loc[data[‘Sex’]==‘male’,‘Sex’]=0:用指定数值替换来指定字符,
比如,将性别中male替换为0,female替换为1。

注意dtype还是原来的object,如果有需要,就需要转换类型。
data[‘Cabin’]=data[‘Cabin’].str.extract(’(\d+)’):提取指定列字符串中的数值,这里就涉及很多正则表达式了,提取不同的结果。

data[‘Ticket’]=data[‘Ticket’].str.split(’/’,expand=True)[0]:根据不同字符来分割一列数据,选择前面还是后面的数据,这里的字符是‘/’
data[‘Ticket’]=data[‘Ticket’].str.replace(’.’,’’):替换某一字符

3.2 时间数据(datetime)处理
有时候也会需要时间类的数据如何处理,时间类的数据类型也是object
data[‘date’]=pd.date_range(‘2022-01-01’,‘2023-01-01’,freq=‘M’):生成一定时间范围的数据

data[‘date’]=pd.to_datetime(data[‘date’],format=’%Y%m’):设置时间数据为指定的format格式
3.3 数据类型(float,int)处理
data[‘Age’]=data[‘Age’].astype(np.int64):更改数据类型
3.4 分类数据(category)处理

data=pd.get_dummies(data):

3.5 colums,index改变
data.rename(columns={‘Fare’:‘Price’,‘Sex’:‘Gender’}): 选择性更改列名
涉及索引变化的我们用下面这个数据来举例;


data.set_index(data[‘column’]).sort_index() : 将某个字段设为索引,可接受列表参数,即设置多个索引,并按索引大小排序

data.reset_index(drop=True) :还原索引,并将索引新设置为0,1,2…

4.缺失值处理
4.1 查看缺失值情况
缺失查看有二种,一种是isna,isnull 都可以的
data.isna().sum()
data.isna().sum().sum()
data[‘Age’].isnull().value_counts()

4.2 删除缺失值
针对离散类分类数据,通常是填充不了的,只能删除,只有连续类数值数据,适合填充
data.dropna(how = ‘all’):传入这个参数后将只丢弃全为缺失值的那些行
data.dropna(axis = 1):丢弃有缺失值的列(一般不会这么做,这样会删掉一个特征)
data.dropna(axis=1,how=“all”):丢弃全为缺失值的那些列
data.dropna(axis=0,subset = [“Age”, “Sex”]):丢弃‘Age’和‘Sex’这两列中有缺失值的行
4.3 填充缺失值 - 简单填充
像属性类的数据,年龄,身高这些数据,只能简单填充。
df.fillna(0):单独的值来填充缺失值,例如0
df.fillna(method=‘bfill’,axis=‘columns’):使用缺失值后面的有效值来从后往前填充,对于DataFrame来说,需要指定axis,未指定情况下按照rows方向填充
df.fillna(method=‘ffill’,axis=‘rows’):使用缺失值前面的有效值来从前往后填充,对于DataFrame来说,需要指定axis
mode=data.column.mode()
data[‘column’].fillna(value=mode[0],inplace=True):使用列均值或者中位数填充
4.4 填充缺失值 - 随机森林回归填充
像连续类数据,是可以由于其他特征数据影响产生的数据,比如天气质量指数,是由于其他特征降雨量,二氧化碳值共同影响的,就可以使用算法来填充。
随机森林回归原理:
任何回归都是从特征矩阵中学习,然后求解连续型标签y的过程,之所以能够实现这个过程,是因为回归算法认为,特征矩阵和标签之前存在着某种联系。实际上,标签和特征是可以相互转换的。
python实例
df=pd.DataFrame({'height':[1.56,1.52,1.78,1.67,1.90,1.84],
'age':[23,20,16,18,45,24],
'weight':[120,150,105,90,169,110],
"BMI":[3.9,4.0,4.4,np.nan,np.nan,np.nan]})

from sklearn.ensemble import RandomForestRegressor
df_x=df.drop(['BMI'],axis=1)
df_y=df.loc[:,'BMI']
y_train=df_y[df_y.notnull()]
y_test=df_y[df_y.isnull()]
x_train=df_x.iloc[y_train.index]
x_test=df_x.iloc[y_test.index]
rfc=RandomForestRegressor(n_estimators=100)
rfc=rfc.fit(x_train,y_train)
y_predict=rfc.predict(x_test)
df_y[df_y.isnull()]=y_predict
df

5.重复值
data[data.duplicated(subset=[“columns”], keep=‘first’)]:查找指定列存在的重复数据
data.drop_duplicates(subset=[“columns”], keep=‘first’, inplace=False):删除指定列重复的数据
6.异常值
通常我们面对的异常值都是连续性数据或者离散性数据,因此在处理异常值,可以先通过画图来大致观察一下,是否存在异常值。
1.处理只有两个连续变量的联合分布,可以通过关系图来展示,比如:1.散点图,2.线图
散点图 - 离散性数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
tips=sns.load_dataset("tips")
tips

ax = sns.scatterplot(x="total_bill",y='tip',data=tips)

像有红色这样的点,就能够从肉眼明显发现异常值。
线图 - 连续性数据
fmri = sns.load_dataset('fmri')
ax = sns.lineplot(x='timepoint',y='signal',data=fmri)

像出现红色线这样,突然峰值的点,就能够从肉眼明显发现异常值。
2.处理多维的可以通过画箱线图来观察
ax = sns.boxplot(x='tip',data=tips,whis=np.inf)
ax = sns.swarmplot(x='tip',data=tips,color='c')

6.1 业务的异常值
这个根据业务要求选择一些异常值
6.2 异常检测算法

还有一种处理时间序列异常值的算法,可以利用Prophet库的算法实现.
7.根据业务需求,选择一些数据
data.query(‘Age >20 and Age < 40 and Price >10’):多条件选择数据

d.query(‘lnum
8.数据抽样
其实我们在训练模型的过程,都会经常进行数据采样,为了就是让我们的模型可以更好的去学习数据的特征,从而让效果更佳。但这是比较浅层的理解,更本质上,数据采样就是对随机现象的模拟,根据给定的概率分布从而模拟一个随机事件。另一说法就是用少量的样本点去近似一个总体分布,并刻画总体分布中的不确定性。
因为我们在现实生活中,大多数数据都是庞大的,所以总体分布可能就包含了无数多的样本点,模型是无法对这些海量的数据进行直接建模的(至少目前而言),而且从效率上也不推荐。
因此,我们一般会从总体样本中抽取出一个子集来近似总体分布,这个子集被称为“训练集”,然后模型训练的目的就是最小化训练集上的损失函数,训练完成后,需要另一个数据集来评估模型,也被称为“测试集”。
采样的一些高级用法,比如对样本进行多次重采样,来估计统计量的偏差与方法,也可以对目标信息保留不变的情况下,不断改变样本的分布来适应模型训练与学习(经典的应用如解决样本不均衡的问题)。
9.数据转化
9.1 归一化

data['Norm_Age']=data.Age.transform(lambda x : (x-x.min())/(x.max()-x.min()))
或
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
data['Norm_Age']=min_max_scaler.fit_transform(data.Age)
9.2 标准化

data['Z_Age']=data.Age.transform(lambda x : (x-x.mean())/x.std())
或
from sklearn import preprocessing
Z_scaler = preprocessing.StandardScaler()
data['Z_Age']=Z_scaler.fit_transform(data.Age)
9.3 正则化
from sklearn import preprocessing
normlizer = preprocessing.Normalizer(copy=True,norm='l2')
data['norm_Age']=normalizer.fit_transform(data.Age)
9.4 LabelEncoder
LabelEncoder 将一列文本数据转化成数值
import pandas as pd
ds=pd.DataFrame({'color':['red','blue','red','yellow']})

from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
label_pclass=le.fit_transform(data)
data['color']=label_pclass

9.5 OneHotEncoder
OneHotEncoder将每一个类可能取值的特征变换为二进制特征向量,每一类的特征向量只有一个地方是1,其余位置都是0
from sklearn.preprocessing import OneHotEncoder
one=OneHotEncoder()
onecolor=one.fit_transform(ds)
onecolor.toarray()

但是不建议只用OneHotEncoder,因为需要把转化的数据赋给元数据,有更好的方法get_dummies函数
ds=ds.join(pd.get_dummies(ds.color))

10.数据分组、排序、透视
data.sort_values(‘Age’,ascending=False):按列Age降序排列数据,False为降序,True为升序

data.sort_values([col1,col2],ascending=[True,False]):先按列col1升序排列,后按col2降序排列数据
data.groupby(‘Pclass’):返回⼀个按列Pclass进⾏分组的Groupby对象

这里返回的只是一串信息,需要如下使用才可以查看到分组后的情况
data.groupby('Pclass')
list(group)

data=data[['Pclass','Age','Price']]
data.groupby(“Pclass”).agg(‘mean’):按Pclass分组,对Pclass之外的列根据Pclass不同组,求mean值,agg可以接受列表参数,agg([len,np.mean])

data.groupby(‘Pclass’)[‘Age’].agg(np.mean):返回按列col1进⾏分组后,列col2的均值

还有一种分组方式就是画数据透视表
data.pivot_table(index=‘Pclass’,values=[‘Age’,‘Price’],aggfunc={‘Age’:np.mean,‘Price’:np.mean}):创建⼀个按列Pclass进⾏分组,计算Age的均值和Price的均值数据透视表

data.groupby(‘Pclass’)[‘Age’].transform(np.mean):与agg不同的地方在于,用transform,分组后,不会把重复的聚合成一个,而是保留所有数据,下图可以直观的看出transform与agg的不同之处。

11.map、apply、applymap处理数据技巧
11.1 处理Series(处理一列、一行数据情况)
map
boolean=[True,False]
gender=["男","女"]
color=["white","black","yellow"]
data=pd.DataFrame({
"height":np.random.randint(150,190,100),
"weight":np.random.randint(40,90,100),
"smoker":[boolean[x] for x in np.random.randint(0,2,100)],
"gender":[gender[x] for x in np.random.randint(0,2,100)],
"age":np.random.randint(15,90,100),
"color":[color[x] for x in np.random.randint(0,len(color),100)]})

data[“gender”] = data[“gender”].map({“男”:1, “女”:0}):使用map映射成其他值,类似于labelencoder
#使用字典进行映射
data["gender"] = data["gender"].map({"男":1, "女":0})
也可以使用map映射函数
#使用函数
def gender_map(x):
gender = 1 if x == "男" else 0
return gender
#注意这里传入的是函数名,不带括号
data["gender"] = data["gender"].map(gender_map)

apply
def apply_age(x,bias):
return x+bias
#以元组的方式传入额外的参数
data["age"] = data["age"].apply(apply_age,args=(-3,))

11.2 处理DataFrame(处理多列、多行或整个数据情况)

apply
# 沿着0轴求和
data[["height","weight","age"]].apply(np.sum, axis=0)

# 沿着0轴取对数
data[["height","weight","age"]].apply(np.log, axis=0)

applymap
df = pd.DataFrame(
{
"A":np.random.randn(5),
"B":np.random.randn(5),
"C":np.random.randn(5),
"D":np.random.randn(5),
"E":np.random.randn(5),
}
)

df.applymap(lambda x:"%.2f" % x)
