本文主要介绍了SpringBoot+Redis布隆过滤器防恶意流量击穿缓存,具体如下:
什么是恶意流量穿透
假设我们的Redis里存有一组用户的注册email,以email作为Key存在,同时它对应着DB里的User表的部分字段。
一般来说,一个合理的请求过来我们会先在Redis里判断这个用户是否是会员,因为从缓存里读数据返回快。如果这个会员在缓存中不存在那么我们会去DB中查询一下。
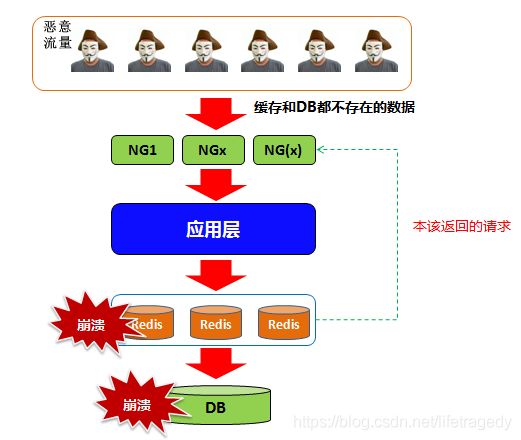
现在试想,有千万个不同IP的请求(不要以为没有,我们就在2018年和2019年碰到了,因为攻击的成本很低)带着Redis里根本不存在的key来访问你的网站,这时我们来设想一下:
- 请求到达Web服务器;
- 请求派发到应用层->微服务层;
- 请求去Redis捞数据,Redis内不存在这个Key;
- 于是请求到达DB层,在DB建立connection后进行一次查询
千万乃至上亿的DB连接请求,先不说Redis是否撑的住DB也会被瞬间打爆。这就是“Redis穿透”又被称为“缓存击穿”,它会打爆你的缓存或者是连DB一起打爆进而引起一系列的“雪崩效应”。
怎么防
那就是使用布隆过滤器,可以把所有的user表里的关键查询字段放于Redis的bloom过滤器内。有人会说,这不疯了,我有4000万会员?so what!
你把4000会员放在Redis里是比较夸张,有些网站有8000万、1亿会员呢?因此我没让你直接放在Redis里,而是放在布隆过滤器内!
布隆过滤器内不是直接把key,value这样放进去的,它存放的内容是这么一个样的:
BloomFilter是一种空间效率的概率型数据结构,由Burton Howard Bloom 1970年提出的。通常用来判断一个元素是否在集合中。具有极高的空间效率,但是会带来假阳性(False positive)的错误。
False positive&&False negatives
由于BloomFiter牺牲了一定的准确率换取空间效率。所以带来了False positive的问题。
False positive
BloomFilter在判断一个元素在集合中的时候,会出现一定的错误率,这个错误率称为False positive的。通常缩写为fpp。
False negatives
BloomFilter判断一个元素不在集合中的时候的错误率。 BloomFilter判断该元素不在集合中,则该元素一定不再集合中。故False negatives概率为0。
BloomFilter使用长度为m bit的字节数组,使用k个hash函数,增加一个元素: 通过k次hash将元素映射到字节数组中k个位置中,并设置对应位置的字节为1。
查询元素是否存在: 将元素k次hash得到k个位置,如果对应k个位置的bit是1则认为存在,反之则认为不存在。
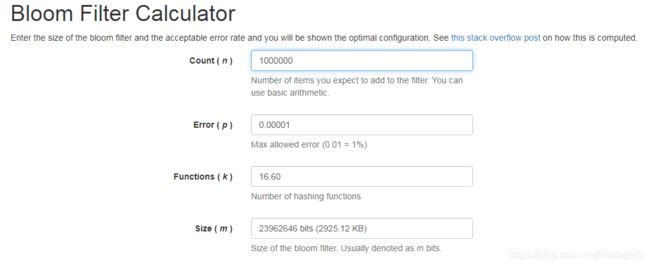
由于它里面存的都是bit,因此这个数据量会很小很小,小到什么样的程度呢?在写本博客时我插了100万条email信息进入Redis的bloom filter也只占用了3Mb不到。
Bloom Filter会有几比较关键的值,根据这个值你是大致可以算出放多少条数据然后它的误伤率在多少时会占用多少系统资源的。这个算法有一个网址:https://krisives.github.io/bloom-calculator/,我们放入100万条数据,假设误伤率在0.001%,看,它自动得出Redis需要申请的系统内存资源是多少?
那么怎么解决这个误伤率呢?很简单的,当有误伤时业务或者是运营会来报误伤率,这时你只要添加一个小白名单就是了,相对于100万条数据来说,1000个白名单不是问题。并且bloom filter的返回速度超块,80-100毫秒内即返回调用端该Key存在或者是不存了。
布隆过滤器的另一个用武场景
假设我用python爬虫爬了4亿条url,需要去重?
看,布隆过滤器就是用于这个场景的。
下面就开始我们的Redis BloomFilter之旅。
给Redis安装Bloom Filter
Redis从4.0才开始支持bloom filter,因此本例中我们使用的是Redis5.4。
Redis的bloom filter下载地址在这:https://github.com/RedisLabsModules/redisbloom.git
git clone https://github.com/RedisLabsModules/redisbloom.git cd redisbloom make # 编译
让Redis启动时可以加载bloom filter有两种方式:
手工加载式:
redis-server --loadmodule ./redisbloom/rebloom.so
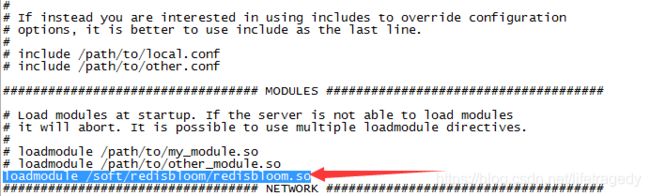
每次启动自加载:
编辑Redis的redis.conf文件,加入:
loadmodule /soft/redisbloom/redisbloom.so
Like this:
在Redis里使用Bloom Filter
基本指令:
bf.reserve {key} {error_rate} {size}
127.0.0.1:6379> bf.reserve userid 0.01 100000 OK
上面这条命令就是:创建一个空的布隆过滤器,并设置一个期望的错误率和初始大小。{error_rate}过滤器的错误率在0-1之间,如果要设置0.1%,则应该是0.001。该数值越接近0,内存消耗越大,对cpu利用率越高。
bf.add {key} {item}
127.0.0.1:6379> bf.add userid '181920' (integer) 1
上面这条命令就是:往过滤器中添加元素。如果key不存在,过滤器会自动创建。
bf.exists {key} {item}
127.0.0.1:6379> bf.exists userid '101310299' (integer) 1
上面这条命令就是:判断指定key的value是否在bloomfilter里存在。存在:返回1,不存在:返回0。
结合SpringBoot使用
网上很多写的都是要么是直接使用jedis来操作的,或者是java里execute一个外部进程来调用Redis的bloom filter指令的。很多都是调不通或者helloworld一个级别的,是根本无法上生产级别应用的。
笔者给出的代码保障读者完全可用!
笔者不是数学家,因此就借用了google的guava包来实现了核心算法,核心代码如下:
BloomFilterHelper.java
package org.sky.platform.util; import com.google.common.base.Preconditions; import com.google.common.hash.Funnel; import com.google.common.hash.Hashing; public class BloomFilterHelper{ private int numHashFunctions; private int bitSize; private Funnel funnel; public BloomFilterHelper(Funnel funnel, int expectedInsertions, double fpp) { Preconditions.checkArgument(funnel != null, "funnel不能为空"); this.funnel = funnel; bitSize = optimalNumOfBits(expectedInsertions, fpp); numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize); } int[] murmurHashOffset(T value) { int[] offset = new int[numHashFunctions]; long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong(); int hash1 = (int) hash64; int hash2 = (int) (hash64 >>> 32); for (int i = 1; i <= numHashFunctions; i++) { int nextHash = hash1 + i * hash2; if (nextHash < 0) { nextHash = ~nextHash; } offset[i - 1] = nextHash % bitSize; } return offset; } /** * 计算bit数组的长度 */ private int optimalNumOfBits(long n, double p) { if (p == 0) { p = Double.MIN_VALUE; } return (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2))); } /** * 计算hash方法执行次数 */ private int optimalNumOfHashFunctions(long n, long m) { return Math.max(1, (int) Math.round((double) m / n * Math.log(2))); } }
下面放出全工程解说,我已经将源码上传到了我的git上了,确保读者可用,源码地址在这:https://github.com/mkyuangithub/mkyuangithub.git

搭建spring boot工程
项目Redis配置
我们在redis-practice工程里建立一个application.properties文件,内容如下:
spring.redis.database=0 spring.redis.host=192.168.56.101 spring.redis.port=6379 spring.redis.password=111111 spring.redis.pool.max-active=10 spring.redis.pool.max-wait=-1 spring.redis.pool.max-idle=10 spring.redis.pool.min-idle=0 spring.redis.timeout=1000
以上这个是demo环境的配置。
我们此处依旧使用的是在前一篇springboot+nacos+dubbo实现异常统一管理中的xxx-project->sky-common->nacos-parent的依赖结构。
在redis-practice工程的org.sky.config包中放入redis的springboot配置
RedisConfig.java
package org.sky.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.*;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
@EnableCaching
public class RedisConfig extends CachingConfigurerSupport {
/**
* 选择redis作为默认缓存工具
*
* @param redisTemplate
* @return
*/
@Bean
public CacheManager cacheManager(RedisTemplate redisTemplate) {
RedisCacheManager rcm = new RedisCacheManager(redisTemplate);
return rcm;
}
/**
* retemplate相关配置
*
* @param factory
* @return
*/
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory factory) {
RedisTemplate template = new RedisTemplate<>();
// 配置连接工厂
template.setConnectionFactory(factory);
// 使用Jackson2JsonRedisSerializer来序列化和反序列化redis的value值(默认使用JDK的序列化方式)
Jackson2JsonRedisSerializer jacksonSeial = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
// 指定要序列化的域,field,get和set,以及修饰符范围,ANY是都有包括private和public
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
// 指定序列化输入的类型,类必须是非final修饰的,final修饰的类,比如String,Integer等会跑出异常
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jacksonSeial.setObjectMapper(om);
// 值采用json序列化
template.setValueSerializer(jacksonSeial);
// 使用StringRedisSerializer来序列化和反序列化redis的key值
template.setKeySerializer(new StringRedisSerializer());
// 设置hash key 和value序列化模式
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(jacksonSeial);
template.afterPropertiesSet();
return template;
}
/**
* 对hash类型的数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public HashOperations hashOperations(RedisTemplate redisTemplate) {
return redisTemplate.opsForHash();
}
/**
* 对redis字符串类型数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public ValueOperations valueOperations(RedisTemplate redisTemplate) {
return redisTemplate.opsForValue();
}
/**
* 对链表类型的数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public ListOperations listOperations(RedisTemplate redisTemplate) {
return redisTemplate.opsForList();
}
/**
* 对无序集合类型的数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public SetOperations setOperations(RedisTemplate redisTemplate) {
return redisTemplate.opsForSet();
}
/**
* 对有序集合类型的数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public ZSetOperations zSetOperations(RedisTemplate redisTemplate) {
return redisTemplate.opsForZSet();
}
}
这个配置除实现了springboot自动发现redis在application.properties中的配置外我们还添加了不少redis基本的数据结构的操作的封装。
我们为此还要再封装一套Redis Util小组件,它们位于sky-common工程中
RedisUtil.java
package org.sky.platform.util;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.Collection;
import java.util.Date;
import java.util.Set;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.google.common.base.Preconditions;
import org.springframework.data.redis.core.RedisTemplate;
@Component
public class RedisUtil {
@Autowired
private RedisTemplate redisTemplate;
/**
* 默认过期时长,单位:秒
*/
public static final long DEFAULT_EXPIRE = 60 * 60 * 24;
/**
* 不设置过期时长
*/
public static final long NOT_EXPIRE = -1;
public boolean existsKey(String key) {
return redisTemplate.hasKey(key);
}
/**
* 重名名key,如果newKey已经存在,则newKey的原值被覆盖
*
* @param oldKey
* @param newKey
*/
public void renameKey(String oldKey, String newKey) {
redisTemplate.rename(oldKey, newKey);
}
/**
* newKey不存在时才重命名
*
* @param oldKey
* @param newKey
* @return 修改成功返回true
*/
public boolean renameKeyNotExist(String oldKey, String newKey) {
return redisTemplate.renameIfAbsent(oldKey, newKey);
}
/**
* 删除key
*
* @param key
*/
public void deleteKey(String key) {
redisTemplate.delete(key);
}
/**
* 删除多个key
*
* @param keys
*/
public void deleteKey(String... keys) {
Set kSet = Stream.of(keys).map(k -> k).collect(Collectors.toSet());
redisTemplate.delete(kSet);
}
/**
* 删除Key的集合
*
* @param keys
*/
public void deleteKey(Collection keys) {
Set kSet = keys.stream().map(k -> k).collect(Collectors.toSet());
redisTemplate.delete(kSet);
}
/**
* 设置key的生命周期
*
* @param key
* @param time
* @param timeUnit
*/
public void expireKey(String key, long time, TimeUnit timeUnit) {
redisTemplate.expire(key, time, timeUnit);
}
/**
* 指定key在指定的日期过期
*
* @param key
* @param date
*/
public void expireKeyAt(String key, Date date) {
redisTemplate.expireAt(key, date);
}
/**
* 查询key的生命周期
*
* @param key
* @param timeUnit
* @return
*/
public long getKeyExpire(String key, TimeUnit timeUnit) {
return redisTemplate.getExpire(key, timeUnit);
}
/**
* 将key设置为永久有效
*
* @param key
*/
public void persistKey(String key) {
redisTemplate.persist(key);
}
/**
* 根据给定的布隆过滤器添加值
*/
public void addByBloomFilter(BloomFilterHelper bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
redisTemplate.opsForValue().setBit(key, i, true);
}
}
/**
* 根据给定的布隆过滤器判断值是否存在
*/
public boolean includeByBloomFilter(BloomFilterHelper bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
if (!redisTemplate.opsForValue().getBit(key, i)) {
return false;
}
}
return true;
}
}
RedisKeyUtil.java
package org.sky.platform.util;
public class RedisKeyUtil {
/**
* redis的key 形式为: 表名:主键名:主键值:列名
*
* @param tableName 表名
* @param majorKey 主键名
* @param majorKeyValue 主键值
* @param column 列名
* @return
*/
public static String getKeyWithColumn(String tableName, String majorKey, String majorKeyValue, String column) {
StringBuffer buffer = new StringBuffer();
buffer.append(tableName).append(":");
buffer.append(majorKey).append(":");
buffer.append(majorKeyValue).append(":");
buffer.append(column);
return buffer.toString();
}
/**
* redis的key 形式为: 表名:主键名:主键值
*
* @param tableName 表名
* @param majorKey 主键名
* @param majorKeyValue 主键值
* @return
*/
public static String getKey(String tableName, String majorKey, String majorKeyValue) {
StringBuffer buffer = new StringBuffer();
buffer.append(tableName).append(":");
buffer.append(majorKey).append(":");
buffer.append(majorKeyValue).append(":");
return buffer.toString();
}
}
然后就是制作 redis里如何使用BloomFilter的BloomFilterHelper.java了,它也位于sky-common文件夹,源码如上已经贴了,因此此处就不再作重复。
最后我们在sky-common里放置一个UserVO用于演示
UserVO.java
package org.sky.vo;
import java.io.Serializable;
public class UserVO implements Serializable {
private String name;
private String address;
private Integer age;
private String email = "";
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
下面给出我们所有gitrepo里依赖的nacos-parent的pom.xml文件内容,此次我们增加了对于“spring-boot-starter-data-redis”,它跟着我们的全局springboot版本走:

parent工程的pom.xml
4.0.0 org.sky.demo nacos-parent 0.0.1-SNAPSHOT pom Demo project for Spring Boot Dubbo Nacos 1.8 1.5.15.RELEASE 2.7.3 4.0.1 2.8.0 1.1.20 27.0.1-jre 1.2.59 2.7.3 1.1.4 5.1.46 3.4.2 1.8.13 0.0.1-SNAPSHOT 1.8.14-RELEASE 0.0.1-SNAPSHOT ${java.version} ${java.version} 3.8.1 3.2.3 3.1.2 UTF-8 UTF-8 org.springframework.boot spring-boot-starter-web ${spring-boot.version} org.springframework.boot spring-boot-dependencies ${spring-boot.version} pom import org.apache.dubbo dubbo-spring-boot-starter ${dubbo.version} org.slf4j slf4j-log4j12 org.apache.dubbo dubbo ${dubbo.version} org.apache.curator curator-framework ${curator-framework.version} org.apache.curator curator-recipes ${curator-recipes.version} mysql mysql-connector-java ${mysql-connector-java.version} com.alibaba druid ${druid.version} com.lmax disruptor ${disruptor.version} com.google.guava guava ${guava.version} com.alibaba fastjson ${fastjson.version} org.apache.dubbo dubbo-registry-nacos ${dubbo-registry-nacos.version} com.alibaba.nacos nacos-client ${nacos-client.version} org.aspectj aspectjweaver ${aspectj.version} org.springframework.boot spring-boot-starter-data-redis ${spring-boot.version} org.apache.maven.plugins maven-compiler-plugin ${compiler.plugin.version} ${java.version} ${java.version} org.apache.maven.plugins maven-war-plugin ${war.plugin.version} org.apache.maven.plugins maven-jar-plugin ${jar.plugin.version}
sky-common中pom.xml文件
4.0.0 org.sky.demo skycommon 0.0.1-SNAPSHOT org.sky.demo nacos-parent 0.0.1-SNAPSHOT org.apache.curator curator-framework org.apache.curator curator-recipes org.springframework.boot spring-boot-starter-test test org.spockframework spock-core test org.spockframework spock-spring org.springframework.boot spring-boot-configuration-processor true org.springframework.boot spring-boot-starter-log4j2 org.springframework.boot spring-boot-starter-web org.springframework.boot spring-boot-starter-logging org.aspectj aspectjweaver com.lmax disruptor redis.clients jedis com.google.guava guava com.alibaba fastjson org.springframework.boot spring-boot-starter-data-redis
到此,我们的springboot+redis基本框架、util类、bloomfilter组件搭建完毕,接下来我们重点说我们的demo工程
Demo工程:redis-practice说明
pom.xml文件,它依赖于nacos-parent同时还引用了sky-common
4.0.0 org.sky.demo redis-practice 0.0.1-SNAPSHOT Demo Redis Advanced Features org.sky.demo nacos-parent 0.0.1-SNAPSHOT org.springframework.boot spring-boot-starter-jdbc org.springframework.boot spring-boot-starter-logging org.apache.dubbo dubbo org.apache.curator curator-framework org.apache.curator curator-recipes mysql mysql-connector-java com.alibaba druid org.springframework.boot spring-boot-starter-test test org.spockframework spock-core test org.spockframework spock-spring org.springframework.boot spring-boot-configuration-processor true org.springframework.boot spring-boot-starter-data-redis org.springframework.boot spring-boot-starter-log4j2 org.springframework.boot spring-boot-starter-web org.springframework.boot spring-boot-starter-logging org.springframework.boot spring-boot-starter-tomcat org.aspectj aspectjweaver com.lmax disruptor redis.clients jedis com.google.guava guava com.alibaba fastjson org.sky.demo skycommon ${skycommon.version} org.springframework.boot spring-boot-starter-data-redis src/main/java src/test/java org.springframework.boot spring-boot-maven-plugin src/main/resources src/main/webapp META-INF/resources **/** src/main/resources true application.properties application-${profileActive}.properties
用于启动的Application.java
package org.sky;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@EnableTransactionManagement
@ComponentScan(basePackages = { "org.sky" })
@EnableAutoConfiguration
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
然后我们制作了一个controller名为UserController,该controller里有两个方法:
- public ResponseEntity
addUser(@RequestBody String params),该方法用于接受来自外部的api post然后把一条email地址塞入redis的bloomfilter中; - public ResponseEntity
findEmailInBloom(@RequestBody String params),该方法用于接受来自外部的api post然后去redis的bloomfilter中验证是否外部输入的user信息中的email地址在上百万的email记录中存在;
以此来完成验证塞入redis的bloom filter中上百万条记录占用了多少内存以及使用bloom filter查询一条记录有多快。
UserController.java
package org.sky.controller;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
import javax.annotation.Resource;
import org.sky.platform.util.BloomFilterHelper;
import org.sky.platform.util.RedisUtil;
import org.sky.vo.UserVO;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.google.common.base.Charsets;
import com.google.common.hash.Funnel;
@RestController
@RequestMapping("user")
public class UserController extends BaseController {
@Resource
private RedisTemplate redisTemplate;
@Resource
private RedisUtil redisUtil;
@PostMapping(value = "/addEmailToBloom", produces = "application/json")
public ResponseEntity addUser(@RequestBody String params) {
ResponseEntity response = null;
String returnResultStr;
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON_UTF8);
Map result = new HashMap<>();
try {
JSONObject requestJsonObj = JSON.parseObject(params);
UserVO inputUser = getUserFromJson(requestJsonObj);
BloomFilterHelper myBloomFilterHelper = new BloomFilterHelper<>((Funnel) (from,
into) -> into.putString(from, Charsets.UTF_8).putString(from, Charsets.UTF_8), 1500000, 0.00001);
redisUtil.addByBloomFilter(myBloomFilterHelper, "email_existed_bloom", inputUser.getEmail());
result.put("code", HttpStatus.OK.value());
result.put("message", "add into bloomFilter successfully");
result.put("email", inputUser.getEmail());
returnResultStr = JSON.toJSONString(result);
logger.info("returnResultStr======>" + returnResultStr);
response = new ResponseEntity<>(returnResultStr, headers, HttpStatus.OK);
} catch (Exception e) {
logger.error("add a new product with error: " + e.getMessage(), e);
result.put("message", "add a new product with error: " + e.getMessage());
returnResultStr = JSON.toJSONString(result);
response = new ResponseEntity<>(returnResultStr, headers, HttpStatus.INTERNAL_SERVER_ERROR);
}
return response;
}
@PostMapping(value = "/checkEmailInBloom", produces = "application/json")
public ResponseEntity findEmailInBloom(@RequestBody String params) {
ResponseEntity response = null;
String returnResultStr;
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON_UTF8);
Map result = new HashMap<>();
try {
JSONObject requestJsonObj = JSON.parseObject(params);
UserVO inputUser = getUserFromJson(requestJsonObj);
BloomFilterHelper myBloomFilterHelper = new BloomFilterHelper<>((Funnel) (from,
into) -> into.putString(from, Charsets.UTF_8).putString(from, Charsets.UTF_8), 1500000, 0.00001);
boolean answer = redisUtil.includeByBloomFilter(myBloomFilterHelper, "email_existed_bloom",
inputUser.getEmail());
logger.info("answer=====" + answer);
result.put("code", HttpStatus.OK.value());
result.put("email", inputUser.getEmail());
result.put("exist", answer);
returnResultStr = JSON.toJSONString(result);
logger.info("returnResultStr======>" + returnResultStr);
response = new ResponseEntity<>(returnResultStr, headers, HttpStatus.OK);
} catch (Exception e) {
logger.error("add a new product with error: " + e.getMessage(), e);
result.put("message", "add a new product with error: " + e.getMessage());
returnResultStr = JSON.toJSONString(result);
response = new ResponseEntity<>(returnResultStr, headers, HttpStatus.INTERNAL_SERVER_ERROR);
}
return response;
}
private UserVO getUserFromJson(JSONObject requestObj) {
String userName = requestObj.getString("username");
String userAddress = requestObj.getString("address");
String userEmail = requestObj.getString("email");
int userAge = requestObj.getInteger("age");
UserVO u = new UserVO();
u.setName(userName);
u.setAge(userAge);
u.setEmail(userEmail);
u.setAddress(userAddress);
return u;
}
}
注意UserController中的BloomFilterHelper的用法,我在Redis的bloomfilter里申明了可以用于存放150万数据的空间。如果存和的数据大于了你预先申请的空间怎么办?那么它会增加“误伤率”。
下面我们把这个项目运行起来看看效果吧。
运行redis-practice工程
运行起来后

我们可以使用postman先来做个小实验

我们使用"、addEmailToBloom"往redis bloom filter里插入了一个“[email protected]”的email。
接下来我们会使用“/checkEmailInBloom”来验证这个email地址是否存在
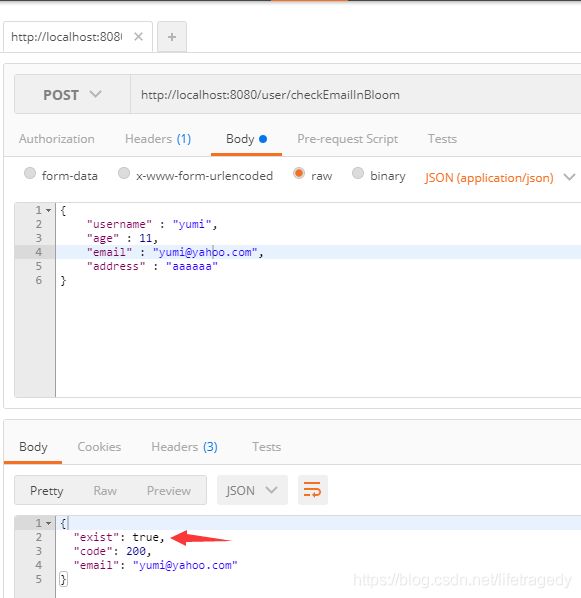
我们使用redisclient连接上我们的redis查看,这个值确实也是插入进了bloom filter了。
使用压测工具喂120万条数据进入Redis Bloomfilter看实际效果
接下来,我们用jmeter对着“/addEmailToBloom”喂上个120万左右数据进去,然后我们再来看bloom filter在120万email按照布隆算 法喂进去后我们的系统是如何表现的。
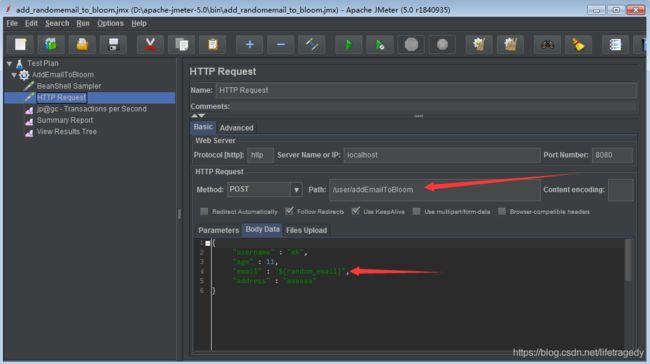
我这边使用的是apache-jmeter5.0,为了偷懒,我用了apache-jmeter里的_RandomString函数来动态创造16位字符长度的email。这边用户名、地址信息都是恒定,就是email是每次不一样,都是一串16位的随机字符+“@163.com”。
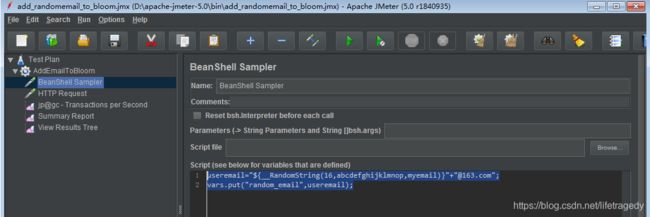
jmeter中BeanShell产生16位字符随机组成email的函数
useremail="${__RandomString(16,abcdefghijklmnop,myemail)}"+"@163.com";
vars.put("random_email",useremail);
jmeter测试计划设置成了75个线程,连续运行30分钟(实践上笔者运行了3个30分钟,因为是demo环境,30分钟每次插大概40万条数据进去吧)

jmeter post请求
然后我们使用jmeter命令行来运行这个测试计划:
jmeter -n -t add_randomemail_to_bloom.jmx -l add_email_to_bloom\report\03-result.csv -j add_email_to_bloom\logs\03-log.log -e -o add_email_to_bloom\html_report_3
它代表:
- -t 指定jmeter执行计划文件所在路径;
- -l 生成report的目录,这个目录如果不存在则创建 ,必须是一个空目录;
- -j 生成log的目录,这个目录如果不存在则创建 ,必须是一个空目录;
- -e 生成html报告,它配合着-o参数一起使用;
- -o 生成html报告所在的路径,这个目录如果不存在则创建 ,必须是一个空目录;
回车后它就开始运行了

一直执行到这个过程全部结束,跳出command命令符为止。
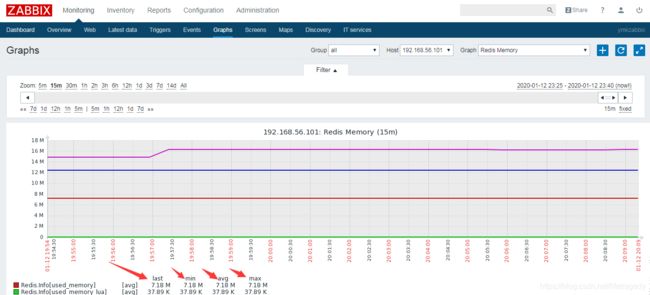
我们查看我们用-e -o生成的jmeter html报告,前面说过了,我一共运行了3次,第一次是10分钟70059条数据 ,第二次是30分钟40多万条数据 ,第三次是45他钟70多万条数据。我共计插入了1,200,790条email。



而这120万数据总计在redis中占用内存不超过8mb,见下面demo环境的zabbix录制的记录
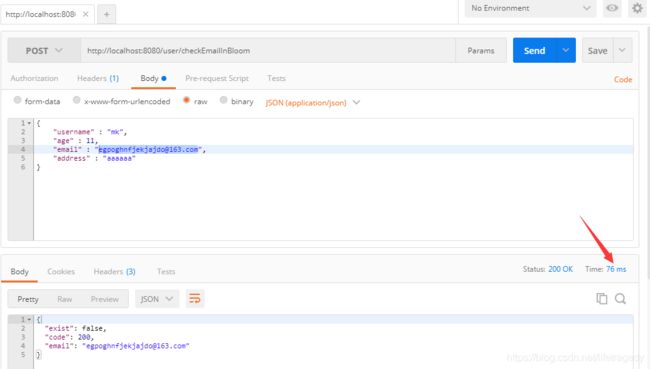
120万条数据插进去后,我们接着从我们的log4j的输出中随便找一条logger.info住的email如:[email protected]来看一下,redis bloomfilter找到这条记录的表现如何,76ms,我运行了多次,平均在80ms左右:
通过上面这么一个实例,大家可以看到把email以hash后并以bit的形式存入bloomfilter后,它占用的内存是多么的小,而查询效率又是多么的高。
往往在生产上,我们经常会把上千万或者是上亿的记录"load"进bloomfilter,然后拿它去做“防击穿”或者是去重的动作。
只要bloomfilter中不存在的key直接返回客户端false,配合着nginx的动态扩充、cdn、waf、接口层的缓存,整个网站抗6位数乃至7位数的并发其实是件非常简单的事。
到此这篇关于SpringBoot+Redis布隆过滤器防恶意流量击穿缓存的文章就介绍到这了,更多相关SpringBoot防恶意流量击穿缓存内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!